VGGT(Visual Geometry Grounded Transformer)分析
VGGT 的核心贡献在于打破了 “3D 重建依赖几何优化” 的传统范式,通过大模型 + 多任务联合训练,实现了 “快速、通用、高精度” 的 3D 属性推断。效率突破:秒级处理数百张图像,为实时 3D 重建(如自动驾驶、AR/VR)提供可能;易用性提升:无需手动设计多阶段流水线(如 SfM 的特征匹配→三角化→BA),直接端到端输出所有 3D 属性;生态赋能:预训练骨干可迁移至多种下游任务,为 3D
·
1. 核心定位与创新价值
1.1 核心目标
提出一种前馈式神经网络,从单张、多张甚至数百张场景图像中,直接推断所有关键 3D 属性(相机内参 / 外参、深度图、点云图、3D 点轨迹),无需依赖复杂的后处理优化(如 bundle adjustment),且推理速度控制在秒级。
1.2 核心创新
- 多任务统一建模:突破传统 3D 视觉模型 “单任务专用” 的局限,用一个共享 Transformer 骨干网络同时预测相机参数、深度、点云、轨迹等相互关联的 3D 属性,通过多任务联合训练提升整体精度。
- 极简 3D 归纳偏置:仅通过 “帧内注意力 + 全局注意力交替”(Alternating-Attention)引入少量结构约束,其余依赖海量 3D 标注数据学习,契合大模型 “数据驱动” 的设计思路。
- 高效推理能力:单前馈 pass 完成所有预测,无需迭代优化,处理 32 张图像仅需 0.6 秒(对比 DUSt3R 需 200 秒以上),且直接输出可用结果(无需后处理)。
- 强泛化与迁移性:预训练骨干可迁移至动态点跟踪、新视角合成等下游任务,显著提升基线模型性能。
2. 技术架构详解
2.1 整体流程
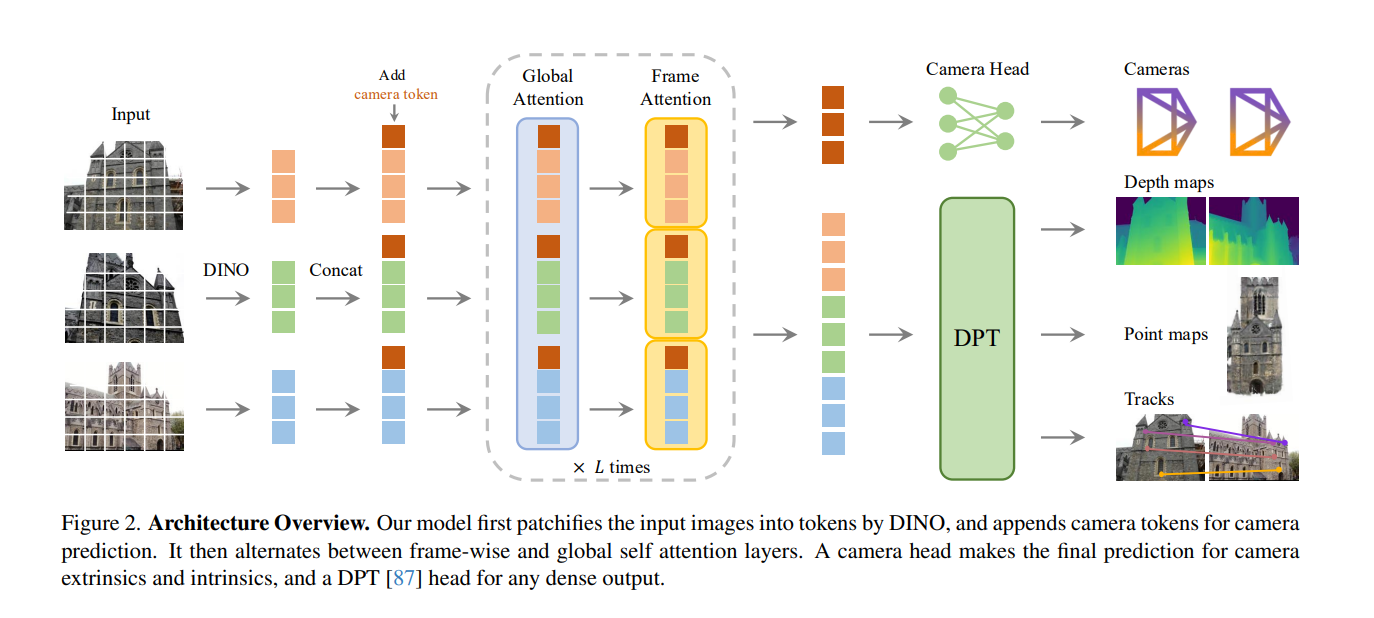
输入图像序列 → 图像分块与 Token 化(DINOv2)→ 交替注意力 Transformer 骨干 → 多任务预测头(相机 / 深度 / 点云 / 轨迹)→ 可选 BA 后处理(进一步提升精度)。
2.2 关键模块
(1)输入编码与 Token 设计
- 图像通过 DINOv2 进行分块(14×14 patch),转换为图像 Token,同时为每张图像附加相机 Token(用于相机参数预测)和寄存器 Token(区分首帧与其他帧)。
- 首帧的相机 / 寄存器 Token 采用特殊可学习参数,确保所有 3D 属性以首帧为世界坐标系基准。
(2)交替注意力机制(Alternating-Attention)
- 核心设计:交替执行 “帧内自注意力”(仅关注单张图像内的 Token,强化单图特征)和 “全局自注意力”(跨所有图像的 Token 交互,建模多视图关联)。
- 优势:平衡单图特征一致性与多图信息融合,避免纯全局注意力的高计算成本,且无需交叉注意力层,结构更简洁。
(3)预测头设计
- 相机头:基于相机 Token,通过 4 层自注意力 + 线性层预测相机参数(旋转四元数 q∈R⁴+ 平移向量 t∈R³+ 视场角 f∈R²)。
- 密集预测头(DPT):将图像 Token 还原为密集特征图,通过 3×3 卷积输出深度图、点云图,同时预测不确定性(用于损失函数加权)。
- 轨迹头:复用 DPT 输出的密集特征,结合 CoTracker2 架构实现跨帧点跟踪,支持无序图像输入。
(4)训练机制
- 多任务损失函数:L=Lcamera+Ldepth+Lpmap+λLtrack(λ=0.05),其中深度和点云损失引入不确定性加权和梯度损失,提升预测平滑性。
- 数据归一化:以首帧为基准,通过 3D 点平均欧式距离归一化相机平移、点云、深度,消除尺度歧义。
- 训练数据:融合 18 个数据集(Co3Dv2、BlendMVS、ScanNet 等),覆盖室内 / 室外、真实 / 合成场景,总计约 1.2B 参数,训练耗时 9 天(64 张 A100 GPU)。
3. 实验结果与性能优势
1. 核心任务性能(SOTA 水平)
| 任务 | 数据集 | 关键指标 | 性能表现(VGGT) | 对比基线(SOTA) | 推理速度 |
|---|---|---|---|---|---|
| 相机姿态估计 | RealEstate10K( unseen) | AUC@30 | 85.3(前馈)/93.5(+BA) | VGGSfM v2(78.9) | 0.2s/1.8s |
| 相机姿态估计 | CO3Dv2 | AUC@30 | 88.2(前馈)/91.8(+BA) | MASt3R(81.8) | 0.2s/1.8s |
| 多视图深度估计 | DTU | Overall(Chamfer 距离) | 0.382(无 GT 相机) | DUSt3R(1.741) | 0.2s |
| 点云重建 | ETH3D | Overall(Chamfer 距离) | 0.677(深度 + 相机融合) | MASt3R(0.826) | 0.2s |
| 双视图匹配 | ScanNet-1500 | AUC@20 | 73.4 | Roma(70.9) | 0.2s |
2. 关键优势验证
- 无需后处理的实用性:前馈模式下已超越依赖全局对齐(DUSt3R/MASt3R)或 BA(VGGSfM)的方法,且速度提升 10-1000 倍。
- 多任务协同增益: ablation 实验显示,同时训练相机、深度、轨迹任务时,点云重建精度(Overall=0.709)显著优于单任务训练(如仅训练深度 + 轨迹:0.834)。
- 交替注意力有效性:对比纯全局注意力(Overall=0.827)和交叉注意力(Overall=1.061),交替注意力在精度和效率上达到最优。
- 下游任务迁移:
- 动态点跟踪:替换 CoTracker2 骨干为 VGGT,TAPVid 数据集δavgvis从 78.9 提升至 84.0。
- 新视角合成:在 GSO 数据集上,无需输入相机参数,PSNR=30.41(对比 LVSM 的 31.71),且训练数据量仅为后者的 20%。
4. 局限性与未来方向
1. 现有局限
- 场景适配性:不支持鱼眼 / 全景图像,极端旋转场景下重建精度下降,无法处理大幅非刚性形变。
- 计算成本:处理 200 张图像时 GPU 内存占用达 40.6GB,需依赖多 GPU 并行(如 Tensor Parallelism)。
- 单视图重建:未专门优化,虽能输出结果,但精度低于专用单视图 3D 重建模型(如 DepthAnything)。
2. 未来方向
- 引入可微分 BA:在训练阶段集成 BA 优化,解决无 3D 标注数据的自监督训练问题(当前因训练速度下降 4 倍未采用)。
- 轻量化设计:通过稀疏注意力、模型压缩等方式降低内存占用,适配端侧设备。
- 场景扩展:针对非刚性形变、特殊相机类型(鱼眼)设计专用微调策略,扩展应用场景。
5. 总结与行业影响
VGGT 的核心贡献在于打破了 “3D 重建依赖几何优化” 的传统范式,通过大模型 + 多任务联合训练,实现了 “快速、通用、高精度” 的 3D 属性推断。其价值体现在:
- 效率突破:秒级处理数百张图像,为实时 3D 重建(如自动驾驶、AR/VR)提供可能;
- 易用性提升:无需手动设计多阶段流水线(如 SfM 的特征匹配→三角化→BA),直接端到端输出所有 3D 属性;
- 生态赋能:预训练骨干可迁移至多种下游任务,为 3D 视觉提供统一的特征提取基础,类似 CLIP 在 2D 视觉的作用。
该工作为后续大模型在 3D 视觉的应用奠定了重要基础,尤其在需要快速处理大规模图像序列的场景(如无人机测绘、数字孪生)具有极高的落地潜力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)