AI大模型企业级落地实践指南(核心聚焦RAG技术)
核心依赖向量数据库的检索算法与Embedding模型的语义表征能力,需通过优化Embedding模型(如跨语言场景选用text-embedding-ada-002)、调整检索策略提升召回率。整合企业原始文档(Word、PDF、Excel等格式),按“语料预处理→数据切片→Embedding嵌入→向量存储”的流程构建私有知识库。模型选择:数据量较少:低纬度 数据量过多(百万、千万数据):高纬度---
一、核心问题:大模型接入企业能否直接落地?
1.1 本地部署与模型选择
- 主流可选模型:DeepSeek V3、R1(671B参数)、Qwen1.5B等
- 模型优化手段:蒸馏(模型压缩技术,核心是知识迁移,降低部署成本)
- 关键结论:直接使用互联网公开数据训练的通用模型无法满足企业需求,存在幻觉、效果差等问题,需结合企业私有数据进行定制化改造
1.2 企业落地的核心前提:数据先行
传统业务是“先业务后数据”,而AI模型落地是“先数据后模型”。通用大模型依赖互联网公开知识训练,缺乏企业核心业务数据支撑,因此必须构建企业私有数据体系,核心要求是本地私有化部署,确保数据不外泄。
二、企业级落地核心方案:三大技术路径
2.1 路径一:RAG(企业AI助手)—— 最成熟的落地方式
2.1.1 RAG核心价值与核心要求
- 核心价值:通过连接企业私有知识库,让大模型具备业务专属认知能力
- 核心要求:模型本地私有化部署 + 企业核心私有知识库构建
2.1.2 RAG完整工作流程
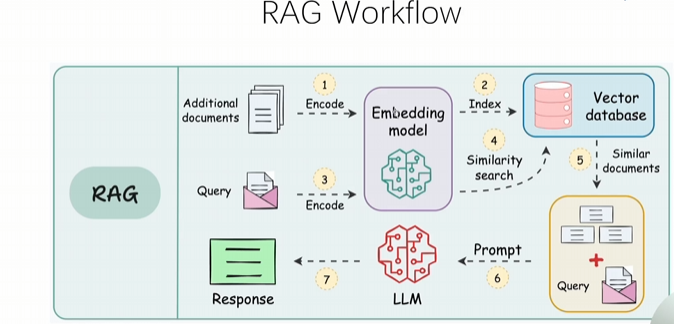
用户提问 → Embedding模型(问题向量转换) → Vector DB(向量数据库检索) → 获取相关文档/答案作为上下文 → 构建Prompt → LLM模型推理 → 生成响应反馈给用户
2.1.3 RAG工程化落地:两大核心环节
环节一:构建索引库(离线处理)
- 语料库准备:企业原始数据进行清洗、去重等预处理
- 数据切片:将长文本切分为语义完整的小片段(核心难题之一)
- Embedding模型嵌入:将切片后的文本转换为向量表示
- Vector Store存储:将向量数据存入向量数据库,建立索引
环节二:构建RAG检索(在线服务)
- 问题向量化:用户提问通过Embedding模型转换为向量
- 向量检索:在向量数据库中检索语义相似度最高的向量
- Prompt构建:将检索到的原始文档与用户问题整合为Prompt
- 内容生成:LLM根据Prompt生成精准响应
2.2 路径二:Fine Tuning(SFT)—— 定制专业模型
2.2.1 核心目标
基于企业专属数据,训练符合业务场景的专业模型,提升特定任务精度
2.2.2 模型选择
优先选择Qwen1.5B-7B参数区间的模型,平衡效果与部署成本
2.2.3 三种微调方式对比
- 全量微调:对基座模型所有权重进行梯度更新,企业场景基本不涉及(易出现幻觉、成本极高)
- 增量微调:适用于分类等简单任务,仅更新部分增量参数
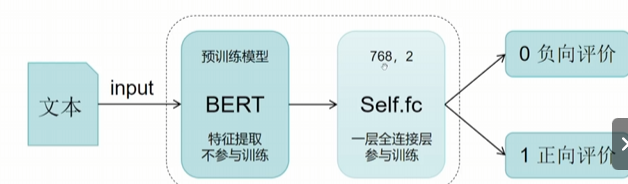
- 局部微调:核心推荐方式,抽取模型中AB两个低秩矩阵进行微调,仅更新部分参数,让模型聚焦学习企业数据/特定领域知识
2.2.4 微调停止判断标准
观察模型Loss值收敛并趋于平缓后,停止训练并进行测试评估
2.2.5 典型应用场景
题库系统、法律咨询、医疗诊断等对专业性要求极高的领域
2.3 路径三:AI调用数据库——连接业务数据层
2.3.1 核心工具与方案
- LlamaIndex:封装了成熟的数据库调用方式,降低开发门槛
- NL2SQL:通过自然语言生成SQL语句,Hugging Face可下载现成Prompt模板
2.3.2 落地关键技术
- Agent + Function Calling:采用LangGraph框架,实现Agent调用后端API接口的能力
- 后置处理机制:若生成结果不符合预期,触发Agent重新生成
2.3.3 现状说明
NL2SQL目前落地效果仍存在较大挑战,需结合业务场景优化Prompt与模型
三、RAG核心技术深度解析
3.1 为什么RAG如此火爆?
- 当前通用LLM的能力不足以直接落地生产级应用,存在语义偏差、知识滞后等问题
- RAG通过连接私有知识库,能快速提升模型在企业场景的精度、准确性,解决通用模型的痛点
3.2 RAG核心评估指标
精确率、准确率、召回率、F1值,其中召回率是检索环节的核心指标
3.3 RAG核心组件与作用
- 向量数据库:核心组件,负责基于向量对企业文档进行高效查询与召回
- 中间件:LangChain、LlamaIndex等,核心工作是实现文档的“恰当切分”与向量转换
- 生成模型(LLM):对检索到的文档进行推理、总结,生成符合用户需求的自然语言响应
3.4 两大核心难题与解决方案
难题1:文档切分(RAG第一大难点)
切分的必要性
向量表征的语义粒度难以控制,需通过切分平衡细节表征与语义完整性:
- 粒度过粗:一条向量对应大段文字,无法精准表征细节信息
- 粒度过细:一段文字对应大量向量,每个向量仅代表少数词语义,无法通过相似度找到有效数据
实用切分方案
- 普通文本:按长度切分,核心参数控制
- chunk_size:建议设置为1000字符
- chunk_overlap:重叠区域占比10%~20%,确保语义连贯性
-
- 缺点:始终不能保证检索出来的答案的完整性
- 比较负责的文本:医疗领域:构建知识图谱(成本非常大)
-
- 涉及到技术:命名实体识别、关系、
如何恰到好处的进行切分
NSP训练(微调训练)
基于BERT模型的NSP任务来继续微调
A与B直接的关系,若有关系则合并为一个
难题2:检索召回率(RAG第二大难点)
核心依赖向量数据库的检索算法与Embedding模型的语义表征能力,需通过优化Embedding模型(如跨语言场景选用text-embedding-ada-002)、调整检索策略提升召回率
3.5 文本向量化核心解析
向量化核心目的:实现语义召回,打破关键词匹配的局限——即使用户问题与文档无完全匹配的关键词,也能基于语义相似度返回最接近的答案
向量化范围:支持单字、短语、句子、段落、整篇文档等不同粒度的文本向量化
四、RAG项目实战:基于LlamaIndex构建企业级私有知识库
4.1 实战核心目标
掌握RAG工作原理与技术架构,实现企业级私有知识库的搭建、优化与落地
4.2 核心实施步骤
步骤1:项目环境搭建
配置Python环境,安装LlamaIndex、LangChain、Embedding模型依赖库、向量数据库客户端等
步骤2:开源模型本地部署
2.1 需部署的两类模型
- Embedding模型:负责文本向量化,跨语言场景可选用OpenAI的text-embedding-ada-002(需购买API Key,按token收费)
- 文本生成模型:优先选择Qwen2.5(国内应用最广版本),7B参数模型为核心选择
2.2 部署硬件要求
- Qwen2.5-7B模型(不量化):需24G以上GPU用于推理
- 企业级部署建议:4张24G显卡,模型默认通过deviceMap=auto实现多卡协同工作
2.3 模型下载渠道
Hugging Face、ModelScope(国内优先,如书生浦语IntelNLM模型)
步骤3:企业知识库创建
整合企业原始文档(Word、PDF、Excel等格式),按“语料预处理→数据切片→Embedding嵌入→向量存储”的流程构建私有知识库
五、AI大模型落地核心认知
- 解决方案为王:AI时代,核心竞争力是基于业务场景的解决方案设计能力,代码实现的重要性相对降低
- 数据安全第一:企业级落地必须坚持私有化部署,确保核心业务数据不外泄
- 精度不是100%可靠:当前AI模型精度最高在95-98%之间,必须对AI输出结果进行后置验证,尤其在高风险场景
六、企业级AI落地典型项目场景
- 企业AI助手:以Chat对话方式,为员工提供业务咨询、文档查询、流程指引等服务
- 业务垂直模型:通过SFT训练行业专属模型,如金融风控模型、医疗影像分析模型等
- 智能数据查询工具:基于NL2SQL+Agent,实现员工通过自然语言查询业务数据库的能力
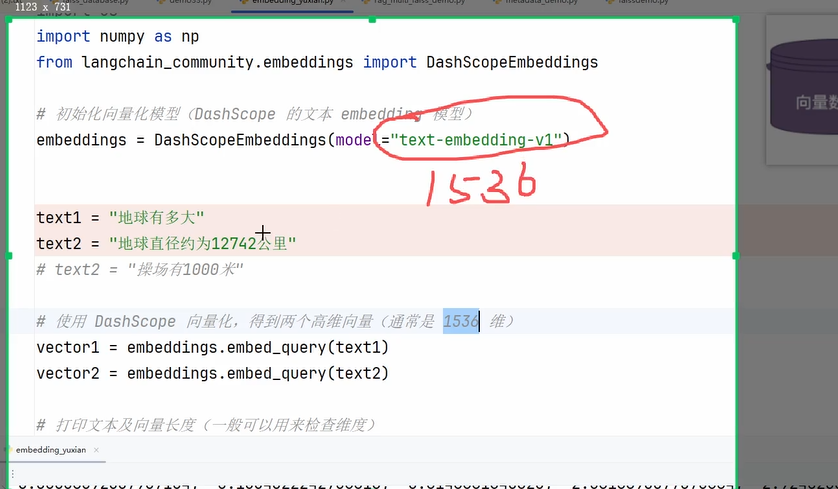
1、向量embedding?
数据--向量--存储
为什么使用向量存储 不用传统存储?-传统数据库不擅长模糊搜索(很难靠关键词匹配、遍历慢)
向量检索--计算语义相似度:余弦相似度、欧氏距离、点积
低纬度模型:只能表达基础语义
高纬度模型:表达基础语义基础上 还能进行上下文识别(更加细腻化)
模型选择:数据量较少:低纬度 数据量过多(百万、千万数据):高纬度---主要根据业务需求来,256-768不错
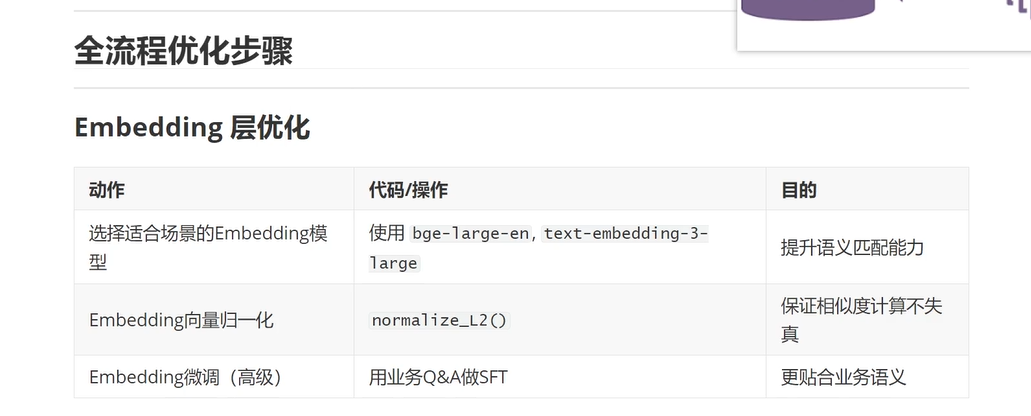
向量层优化↓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 31
31 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)