Crawl4AI调用本地模型实现爬虫
在ollama官网(https://ollama.com/download)下载软件,注意选择与自己电脑系统对应的版本。
安装完ollama,通过终端拉取模型,比如gemma3:1b,模型必须是https://ollama.com/search有的模型且是对应参数(b)大小

测试下载的模型

测试连接ollama
curl http://localhost:11434/api/generate \
-H "Content-Type: application/json" \
-d '{
"model": "gemma3:1b",
"prompt": "介绍Ollama的核心优势",
"stream": false
}'
进入终端,到自己的目录克隆Craw4AI项目https://ollama.com/download
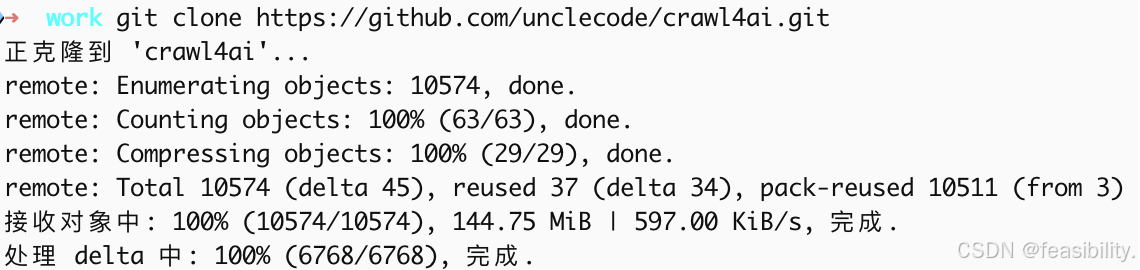
通过cd crawl4ai进入项目目录
根据自己的需要修改docker文件,配置.llm.env,都放在项目目录
Dockerfile文件
FROM python:3.12-slim-bookworm AS build
# C4ai version
ARG C4AI_VER=0.7.8
ENV C4AI_VERSION=$C4AI_VER
LABEL c4ai.version=$C4AI_VER
# Set build arguments
ARG APP_HOME=/app
ARG GITHUB_REPO=https://github.com/unclecode/crawl4ai.git
ARG GITHUB_BRANCH=main
ARG USE_LOCAL=true
# Mirrors
ARG PIP_INDEX_URL=https://mirrors.aliyun.com/pypi/simple/
ARG APT_SOURCE_URL=https://mirrors.aliyun.com
# Core env (no inline comments after backslashes!)
ENV PYTHONFAULTHANDLER=1 \
PYTHONHASHSEED=random \
PYTHONUNBUFFERED=1 \
PIP_NO_CACHE_DIR=1 \
PYTHONDONTWRITEBYTECODE=1 \
PIP_DISABLE_PIP_VERSION_CHECK=1 \
PIP_DEFAULT_TIMEOUT=100 \
DEBIAN_FRONTEND=noninteractive \
REDIS_HOST=localhost \
REDIS_PORT=6379 \
PYTORCH_ENABLE_MPS_FALLBACK=1 \
PIP_INDEX_URL=${PIP_INDEX_URL} \
PIP_TRUSTED_HOST=mirrors.aliyun.com \
LD_LIBRARY_PATH=/usr/local/lib:${LD_LIBRARY_PATH}
ARG PYTHON_VERSION=3.12
ARG INSTALL_TYPE=default
ARG ENABLE_GPU=auto
ARG TARGETARCH
LABEL maintainer="unclecode"
LABEL description="🔥🕷️ Crawl4AI: Open-source LLM Friendly Web Crawler & scraper"
LABEL version="1.0"
# ----------------------------
# APT mirror for Debian bookworm (deb822: /etc/apt/sources.list.d/debian.sources)
# ----------------------------
RUN set -eux; \
MIRROR="${APT_SOURCE_URL%/}"; \
if [ -f /etc/apt/sources.list.d/debian.sources ]; then \
cp /etc/apt/sources.list.d/debian.sources /etc/apt/sources.list.d/debian.sources.bak; \
fi; \
cat > /etc/apt/sources.list.d/debian.sources <<EOF
Types: deb
URIs: ${MIRROR}/debian
Suites: bookworm bookworm-updates
Components: main contrib non-free non-free-firmware
Signed-By: /usr/share/keyrings/debian-archive-keyring.gpg
Types: deb
URIs: ${MIRROR}/debian-security
Suites: bookworm-security
Components: main contrib non-free non-free-firmware
Signed-By: /usr/share/keyrings/debian-archive-keyring.gpg
EOF
# Base deps
RUN set -eux; \
apt-get update; \
apt-get install -y --no-install-recommends \
build-essential \
curl \
wget \
gnupg \
git \
cmake \
pkg-config \
python3-dev \
libjpeg-dev \
redis-server \
supervisor; \
apt-get clean; \
rm -rf /var/lib/apt/lists/*
# Browser/render deps (playwright)
RUN set -eux; \
apt-get update; \
apt-get install -y --no-install-recommends \
libglib2.0-0 \
libnss3 \
libnspr4 \
libatk1.0-0 \
libatk-bridge2.0-0 \
libcups2 \
libdrm2 \
libdbus-1-3 \
libxcb1 \
libxkbcommon0 \
libx11-6 \
libxcomposite1 \
libxdamage1 \
libxext6 \
libxfixes3 \
libxrandr2 \
libgbm1 \
libpango-1.0-0 \
libcairo2 \
libasound2 \
libatspi2.0-0; \
apt-get clean; \
rm -rf /var/lib/apt/lists/*
# System upgrade (optional but kept)
RUN set -eux; \
apt-get update; \
apt-get dist-upgrade -y; \
rm -rf /var/lib/apt/lists/*
# CUDA install logic (Linux+NVIDIA only; Mac will skip)
RUN set -eux; \
if [ "$ENABLE_GPU" = "true" ] && [ "$TARGETARCH" = "amd64" ] ; then \
apt-get update; \
apt-get install -y --no-install-recommends nvidia-cuda-toolkit; \
apt-get clean; \
rm -rf /var/lib/apt/lists/*; \
else \
echo "Skipping NVIDIA CUDA Toolkit installation (unsupported platform or GPU disabled)"; \
fi
# Arch-specific optimizations
RUN set -eux; \
if [ "$TARGETARCH" = "arm64" ]; then \
echo "Installing ARM-specific optimizations"; \
apt-get update; \
apt-get install -y --no-install-recommends libopenblas-dev; \
apt-get clean; \
rm -rf /var/lib/apt/lists/*; \
elif [ "$TARGETARCH" = "amd64" ]; then \
echo "Installing AMD64-specific optimizations"; \
apt-get update; \
apt-get install -y --no-install-recommends libomp-dev; \
apt-get clean; \
rm -rf /var/lib/apt/lists/*; \
else \
echo "Skipping platform-specific optimizations (unsupported platform)"; \
fi
# Non-root user
RUN set -eux; \
groupadd -r appuser; \
useradd --no-log-init -r -g appuser appuser; \
mkdir -p /home/appuser; \
chown -R appuser:appuser /home/appuser
WORKDIR ${APP_HOME}
# Copy project source (you are already in crawl4ai repo root)
COPY . /tmp/project/
# Copy config & requirements
COPY deploy/docker/supervisord.conf ${APP_HOME}/supervisord.conf
COPY deploy/docker/requirements.txt /tmp/requirements.txt
# Upgrade pip early and install Python deps once
RUN set -eux; \
python -m pip install --no-cache-dir --upgrade pip; \
pip install --no-cache-dir -r /tmp/requirements.txt
# Optional extra deps by INSTALL_TYPE
RUN set -eux; \
if [ "$INSTALL_TYPE" = "all" ] ; then \
pip install --no-cache-dir \
torch torchvision torchaudio \
scikit-learn nltk transformers tokenizers; \
python -m nltk.downloader punkt stopwords; \
fi
# Install crawl4ai (ONLY ONCE)
# - USE_LOCAL=true: install from /tmp/project
# - USE_LOCAL=false: clone then install
RUN set -eux; \
if [ "$USE_LOCAL" = "true" ]; then \
echo "Installing from local source (/tmp/project)"; \
if [ "$INSTALL_TYPE" = "all" ] ; then \
pip install --no-cache-dir "/tmp/project/[all]"; \
python -m crawl4ai.model_loader; \
elif [ "$INSTALL_TYPE" = "torch" ] ; then \
pip install --no-cache-dir "/tmp/project/[torch]"; \
elif [ "$INSTALL_TYPE" = "transformer" ] ; then \
pip install --no-cache-dir "/tmp/project/[transformer]"; \
python -m crawl4ai.model_loader; \
else \
pip install --no-cache-dir "/tmp/project"; \
fi; \
else \
echo "Installing from GitHub (${GITHUB_BRANCH})"; \
for i in 1 2 3; do \
git clone --branch "${GITHUB_BRANCH}" "${GITHUB_REPO}" /tmp/crawl4ai && break || \
(echo "Attempt $i/3 failed; sleep 5"; sleep 5); \
done; \
pip install --no-cache-dir /tmp/crawl4ai; \
fi
# Quick sanity checks
RUN set -eux; \
python -c "import crawl4ai; print('✅ crawl4ai import ok')" ; \
python -c "from playwright.sync_api import sync_playwright; print('✅ Playwright import ok')"
# crawl4ai/playwright setup
RUN set -eux; \
crawl4ai-setup; \
playwright install --with-deps
# Playwright cache perms
RUN set -eux; \
mkdir -p /home/appuser/.cache/ms-playwright; \
if ls /root/.cache/ms-playwright/chromium-* >/dev/null 2>&1; then \
cp -r /root/.cache/ms-playwright/chromium-* /home/appuser/.cache/ms-playwright/; \
fi; \
chown -R appuser:appuser /home/appuser/.cache
RUN crawl4ai-doctor
# Local model/cache dirs
RUN set -eux; \
mkdir -p /home/appuser/.cache /app/local_models /app/cache; \
chown -R appuser:appuser /home/appuser/.cache /app/local_models /app/cache
# App files/static
COPY deploy/docker/static ${APP_HOME}/static
COPY deploy/docker/* ${APP_HOME}/
# Permissions
RUN set -eux; \
chown -R appuser:appuser ${APP_HOME}; \
mkdir -p /var/lib/redis /var/log/redis; \
chown -R appuser:appuser /var/lib/redis /var/log/redis
HEALTHCHECK --interval=30s --timeout=10s --start-period=5s --retries=3 \
CMD bash -c '\
MEM=$(free -m | awk "/^Mem:/{print \$2}"); \
if [ $MEM -lt 2048 ]; then \
echo "⚠️ Warning: Less than 2GB RAM available!"; exit 1; \
fi && \
redis-cli ping > /dev/null && \
curl -f http://localhost:11235/health || exit 1'
EXPOSE 6379 11235
USER appuser
ENV PYTHON_ENV=production \
DEVICE_AUTO_DETECT=true \
NVIDIA_VISIBLE_DEVICES=all
CMD ["supervisord", "-c", "/app/supervisord.conf"]
docker-compose.yml文件
version: '3.8'
# Shared configuration for all environments
x-base-config: &base-config
ports:
- "11235:11235" # Gunicorn port
- "6379:6379" # ✅ 补全官方Redis端口
env_file:
- .llm.env # API keys (create from .llm.env.example)
# ✅ 新增核心配置:硬件自动适配+阿里源+本地LLM环境变量
environment:
- PYTORCH_ENABLE_MPS_FALLBACK=1
- DEVICE_AUTO_DETECT=true
- NVIDIA_VISIBLE_DEVICES=all
- PYTHONUNBUFFERED=1
volumes:
- /dev/shm:/dev/shm # Chromium performance
- ./local_models:/app/local_models # ✅ 新增:本地LLM模型挂载(无Ollama必备)
- ./cache:/app/cache # ✅ 新增:依赖/模型缓存,避免重复下载
restart: unless-stopped
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:11235/health"]
interval: 30s
timeout: 10s
retries: 3
start_period: 40s
user: "appuser"
stdin_open: true
tty: true
services:
crawl4ai:
image: ${IMAGE:-unclecode/crawl4ai:${TAG:-latest}}
build:
context: .
dockerfile: Dockerfile
args:
INSTALL_TYPE: ${INSTALL_TYPE:-default}
ENABLE_GPU: ${ENABLE_GPU:-auto} # ✅ 改为auto,自动识别CUDA/MPS
# ✅ 传递阿里源参数给Dockerfile,全局加速生效
PIP_INDEX_URL: https://mirrors.aliyun.com/pypi/simple/
APT_SOURCE_URL: http://mirrors.aliyun.com/
<<: *base-config
# ✅ 自定义容器名,方便管理(可选)
container_name: crawl4ai-auto-device
extra_hosts:
- "host.docker.internal:host-gateway".llm.env文件
# ==============================================================
# 🎯 CRAWL4AI 终极配置:外部API + Ollama + 自定义本地LLM 三者共存
# ✅ 所有配置同时生效,无需注释/切换!
# ✅ 方式1:改LLM_PROVIDER → 指定全局默认LLM(所有任务默认用)
# ✅ 方式2:代码内指定 → 单任务调用任意LLM(不影响全局)
# ==============================================================
# -------------------------- 🎯 全局公共配置(所有LLM共用) --------------------------
# 全局默认温度(兜底,所有未指定专属温度的LLM生效)
LLM_TEMPERATURE=0.1
# 全局请求超时(防止本地LLM推理慢导致超时)
REQUEST_TIMEOUT=120
# -------------------------- ✅ 模式1:外部官方API(OpenAI/DeepSeek/Groq等,按需填) --------------------------
# ✅ 填写真实KEY即可启用,支持多个平台同时配置
OPENAI_API_KEY=sk-yourOpenAIkey
DEEPSEEK_API_KEY=yourDeepSeekkey
GROQ_API_KEY=yourGroqkey
# 平台专属地址(如需代理/私有部署,填这里,优先级高于全局)
# OPENAI_BASE_URL=https://api.openai.com/v1
# DEEPSEEK_BASE_URL=https://api.deepseek.com/v1
# 平台专属温度(按需覆盖全局)
OPENAI_TEMPERATURE=0.0
GROQ_TEMPERATURE=0.8
# -------------------------- ✅ 模式2:Ollama本地API(本机部署,永久在线) --------------------------
# ✅ Ollama官方原生专属配置字段,独立隔离,不影响其他模式
# Docker容器访问本机Ollama → 固定用host.docker.internal:11434
OLLAMA_BASE_URL=http://host.docker.internal:11434
# Ollama无需真实KEY,占位即可(必填,随便填)
OLLAMA_API_KEY=ollama-local-key
# -------------------------- ✅ 模式3:自定义本地LLM API(无Ollama,永久在线) --------------------------
# ✅ 复用OPENAI_*字段组,独立配置,与「外部OpenAI」互不冲突
# 核心:用LLM_BASE_URL 专门指向「自定义本地LLM」,作为全局兜底/快捷调用
LLM_BASE_URL=http://host.docker.internal:12345/v1 # 你的自定义本地LLM端口 在docker运行crawl4ai使用http://host.docker.internal:12345 本地模型在容器可用http://127.0.0.1:12345/v1
# 本地LLM无需真实KEY,占位即可(必填,随便填)
OPENAI_API_KEY_LOCAL=local-llm-key-12345
# -------------------------- ✅ 全局默认LLM指定(核心!一键切换所有任务的默认LLM) --------------------------
# ✅ 改这1行,即可全局切换默认LLM,其余配置不动!
# 可选值(直接复制对应行启用):
# LLM_PROVIDER=openai/gpt-4o-mini # 默认用【外部OpenAI】
LLM_PROVIDER=ollama/gemma3:1b # 默认用【Ollama本地】(替换为你的Ollama模型名)
#LLM_PROVIDER=openai/qwen3-vl-2b # 默认用【自定义本地LLM】(模型名随便填)
# LLM_PROVIDER=groq/llama3-70b-8192 # 默认用【外部Groq】
启动docker软件,并在终端执行命令
docker-compose down -v
docker-compose build --no-cache
docker-compose up -d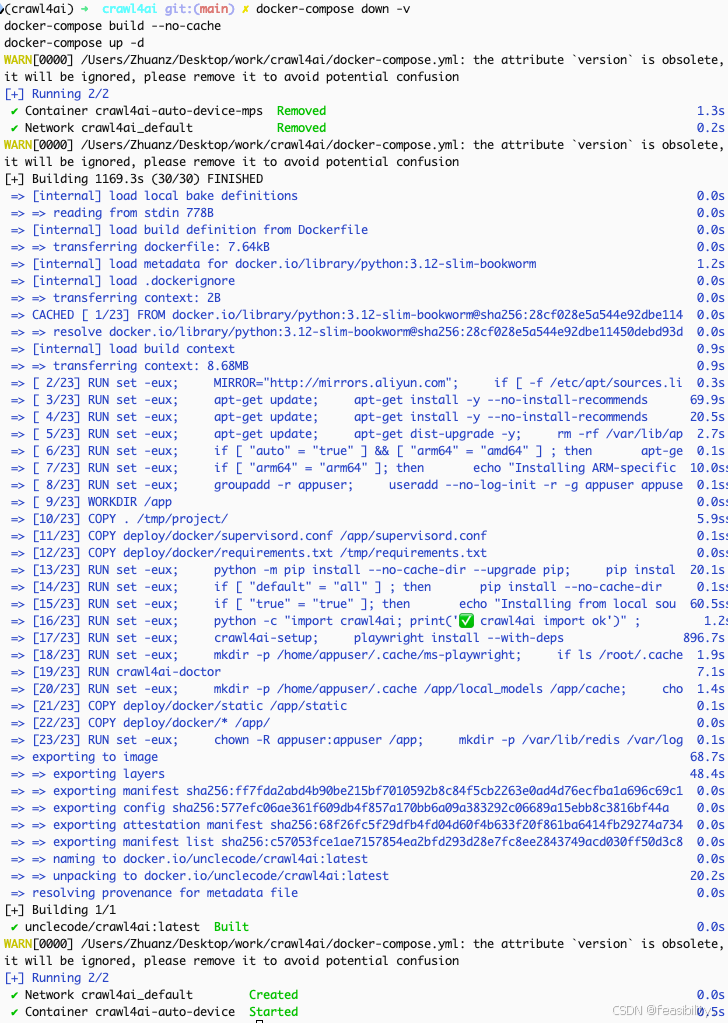
检查容器进程docker ps

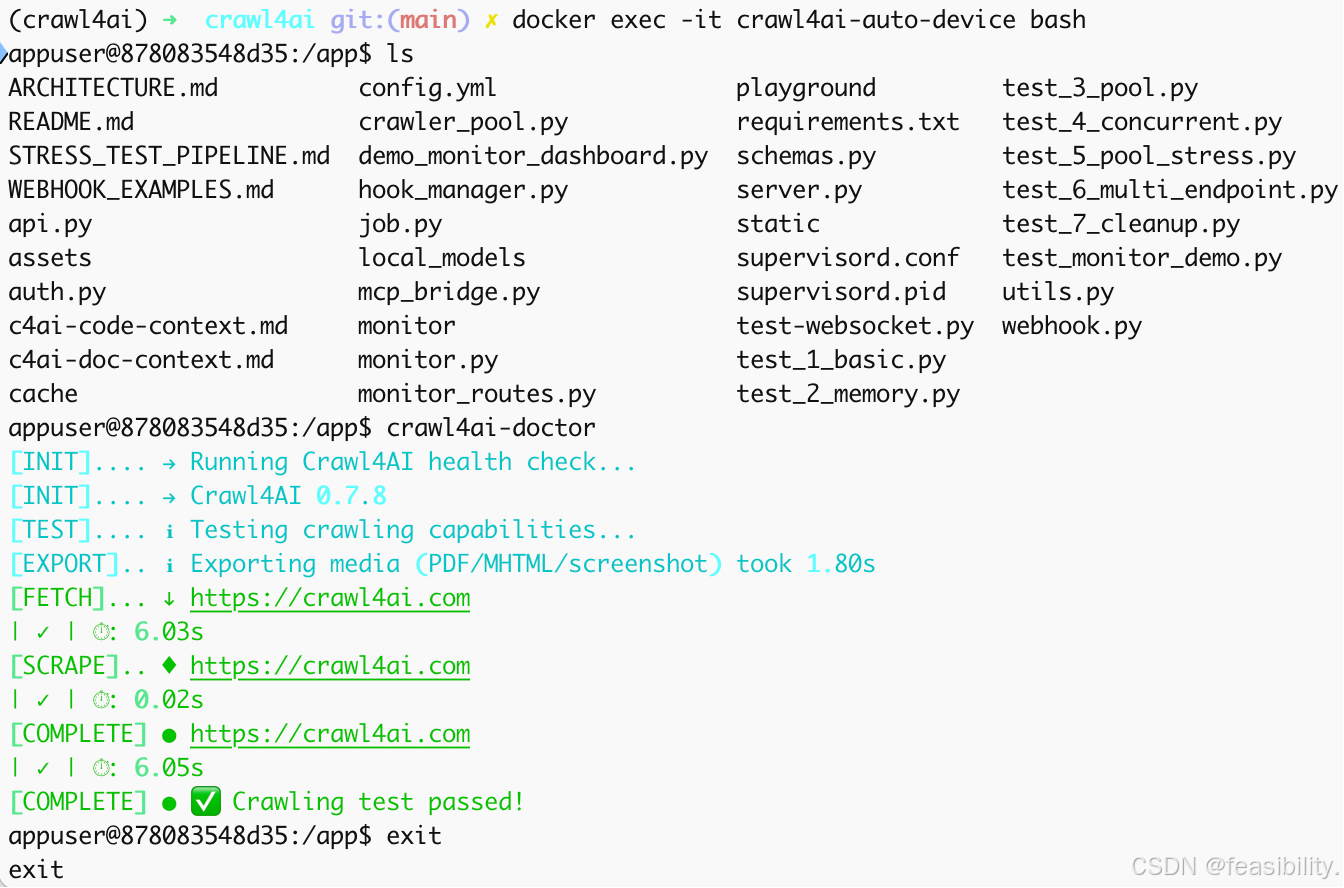
进入容器docker exec -it crawl4ai-auto-device bash,检查容器内部情况
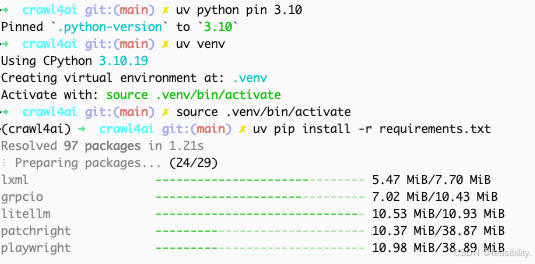
准备容器外部测试调用接口,这里采用uv(用conda或python原生也可以)配置环境
在终端执行uv run playwright install给playwright安装浏览器
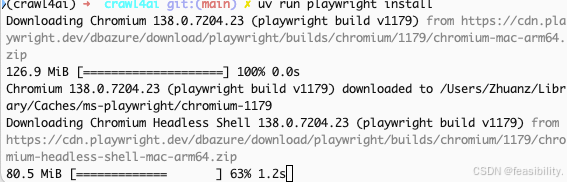
执行uv run test_llm_crawl.py测试
from dis import Instruction
import litellm
litellm.suppress_debug_info = True
import json
import time
class TinyLogCallback:
def __init__(self, max_chars=600):
self.max_chars = max_chars
# 记录请求(能看到最终拼出来的 url / api_base)
def log_pre_api_call(self, model, messages, kwargs):
api_base = kwargs.get("api_base") or kwargs.get("base_url") or ""
print(f"[litellm] -> model={model} api_base={api_base}")
# 打印 messages 的字符长度(不打印全文)
try:
s = json.dumps(messages, ensure_ascii=False)
print(f"[litellm] messages_chars={len(s)} sample={s[:120]}...")
except Exception:
pass
# 成功
def log_success_event(self, kwargs, response_obj, start_time, end_time):
dt = end_time - start_time
usage = getattr(response_obj, "usage", None) or getattr(response_obj, "get", lambda k, d=None: d)("usage", None)
print(f"[litellm] <- success {dt:.2f}s usage={usage}")
# 失败(这里最关键:看它实际打的 URL、以及报错前是否请求了 /v1/models)
def log_failure_event(self, kwargs, response_obj, start_time, end_time, exception):
dt = end_time - start_time
api_base = kwargs.get("api_base") or kwargs.get("base_url") or ""
print(f"[litellm] <- FAIL {dt:.2f}s api_base={api_base} err={repr(exception)}")
litellm.callbacks = [TinyLogCallback()]
#litellm._turn_on_debug()#打印它最终请求的 URL/参数,判断是不是连到了错误的 base_url
from crawl4ai import (
AsyncWebCrawler,
CrawlerRunConfig,
CacheMode,
LLMConfig,
LLMExtractionStrategy,BrowserConfig
)
from crawl4ai.content_filter_strategy import PruningContentFilter # 或 BM25ContentFilter
from crawl4ai.markdown_generation_strategy import DefaultMarkdownGenerator
import asyncio
from dotenv import load_dotenv
import os
load_dotenv(".llm.env")
async def main():
provider=os.getenv("LLM_PROVIDER", "openai/qwen3-vl-2b")
llm_cfg = LLMConfig(
provider=provider,
api_token=os.getenv("OPENAI_API_KEY", "local-llm-key"),
base_url=(os.getenv("LLM_BASE_URL") if provider.find('Ollama') == -1 else os.getenv("OLLAMA_BASE_URL")).replace('host.docker.internal','localhost'), #
)
print("provider =", llm_cfg.provider)
print("base_url =", llm_cfg.base_url)
strat = LLMExtractionStrategy(
llm_config=llm_cfg,
extraction_type="block",
#instruction="请用中文用简洁总结该网页核心内容",
#instruction="严格使用纯中文输出,禁止任何英文!将网页核心内容总结为3条简洁要点,按「1.xxx 2.xxx 3.xxx」格式输出,过滤所有无关垃圾内容,无多余内容。",
instruction='仅提取关于世界模型的相关核心信息,过滤网页中所有广告、视频推荐、无关博主内容,总结为3条简洁要点,按「1.xxx 2.xxx 3.xxx」格式输出,不允许出现重复的信息',#
input_format="fit_markdown",
verbose=True,
#apply_chunking=False, # ✅ 关键:不要分块 -> 只打一枪
chunk_token_threshold=800,
overlap_rate=0.0,
word_token_rate=4.0,
extra_args={
"max_tokens": 512,
"temperature": 0, # 极低温度,强制模型严格遵循指令
#"stop": ["\n\n", "."],
"stream": False,
},
)
# ✅ 新增:在生成 fit_markdown 前先“去噪瘦身”
prune_filter = PruningContentFilter(
threshold=0.45, # 可调:越大越“狠”(删得更多)
threshold_type="dynamic",#fixed
min_word_threshold=10,#5 20过滤短句垃圾信息
)
md_generator = DefaultMarkdownGenerator(content_filter=prune_filter,
options={
#"ignore_links": True, # 关键:去掉链接/脚注膨胀
"ignore_images": True,
#"skip_internal_links": True,
})
run_cfg = CrawlerRunConfig(
extraction_strategy=strat,
# ✅ 关键:把过滤后的 markdown 交给 LLMExtractionStrategy(fit_markdown 才真正有意义)
markdown_generator=md_generator,
# ✅ 可选:HTML 级过滤
#excluded_tags=["a","img","nav","footer","header","form","script","style","noscript","aside"],
#word_count_threshold=20,# ✅ 过滤短内容,保留核心信息
#css_selector="div.result-op, div.result-op, main, article, #content", # 有些站点能显著提升质量;不确定就先注释
cache_mode=CacheMode.BYPASS,
semaphore_count=1, # ✅ 限制并发,防 OOM
verbose=True
)
browser_cfg=BrowserConfig(user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
async with AsyncWebCrawler() as crawler:
r = await crawler.arun("https://www.baidu.com/s?wd=世界模型是什么", config=run_cfg,browser_config=browser_cfg,request_timeout=300)#https://www.baidu.com/s?wd=ollama
# "https://www.example.com/" https://cn.bing.com/search?q=%E5%A4%A7%E6%A8%A1%E5%9E%8B&form=ANNTH1&refig=695a51ab6a05443780e4068ffdd23e78&pc=U531
print("success:", r.success)
print("=== extracted_content ===")
print(r.extracted_content)
if __name__ == "__main__":
asyncio.run(main())

如果想自己实现本地模型的API服务,要端口号(这里是12345)保持一致,符合openai格式, 修改LLM_PROVIDER如LLM_PROVIDER=openai/qwen3-vl-2b ,然后让容器重新读取 env(只需重建容器,不用 rebuild 镜像)
关键代码
#兼容OpenAI格式
def _messages_to_prompt(messages: List[Dict[str, Any]]) -> str:
lines = []
for m in messages:
role = m.get("role", "user")
content = m.get("content", "")
# content 可能是 str,也可能是 [{"type":"text","text":"..."}]
if isinstance(content, list):
text = "".join(
part.get("text", "")
for part in content
if isinstance(part, dict) and part.get("type") == "text"
)
else:
text = str(content)
lines.append(f"{role}: {text}")
return "\n".join(lines)
@app.post("/v1/chat/completions")
async def chat_completions(payload: Dict[str, Any] = Body(...)):
model_name = payload.get("model", "local-model")
messages = payload.get("messages", [])
temperature = float(payload.get("temperature", 0.7))
top_p = float(payload.get("top_p", 0.8))
max_tokens = int(payload.get("max_tokens", 256))
prompt = _messages_to_prompt(messages)
async with app.state.lock:
result = run_infer(
model=app.state.model,
processor=app.state.processor,
device=app.state.device,
prompt=prompt,
image_path=None,
max_new_tokens=max_tokens,
top_p=top_p,
temperature=temperature,
do_sample=(temperature > 0),
)
text = result["text"]
usage = result.get("usage", {}) or {}
prompt_tokens = usage.get("prompt_tokens") or 0
completion_tokens = usage.get("completion_tokens") or 0
return {
"id": f"chatcmpl-{uuid.uuid4().hex}",
"object": "chat.completion",
"created": int(time.time()),
"model": model_name,
"choices": [
{
"index": 0,
"message": {"role": "assistant", "content": text},
"finish_reason": "stop",
}
],
"usage": {
"prompt_tokens": prompt_tokens,
"completion_tokens": completion_tokens,
"total_tokens": prompt_tokens + completion_tokens,
},
}
运行:docker compose up -d --force-recreate
(docker-compose.yml 用的是 env_file: .llm.env,这样就能生效。)

验证容器变量docker compose exec crawl4ai sh -lc 'python -c "import os; print(repr(os.getenv(\"OPENAI_API_KEY\"))); print(repr(os.getenv(\"LLM_BASE_URL\")))"'

调用自己实现的模型API服务测试

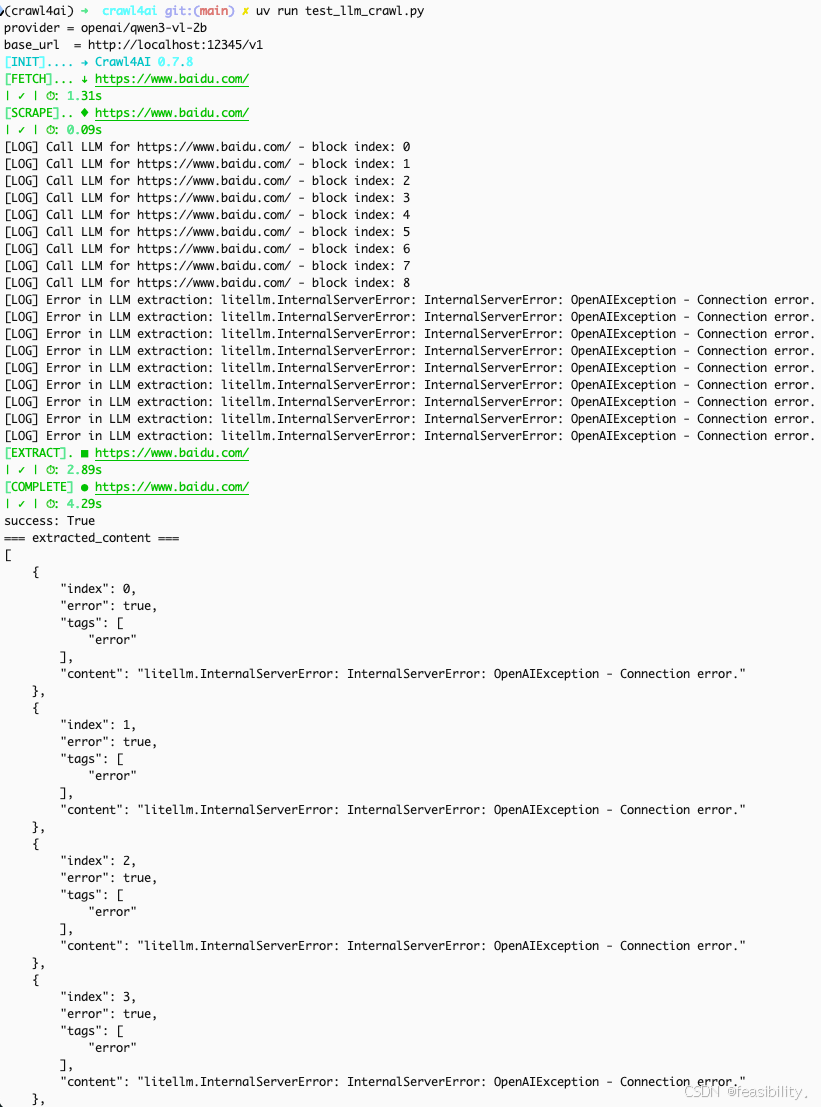
注意:首页比搜索结果页更容易把本地模型打爆,首页的 DOM 里通常包含大量:
-
导航/热榜/推荐入口(很多
<a>文本) -
复杂的组件结构、隐藏/折叠区域(视觉上不多,但文本节点不少)
-
以及各种“非正文”的块,Pruning 不一定能像文章页一样精准剪掉
搜索结果页反而结构更像“正文列表”,Pruning 更容易保住核心块、删掉边角料,所以更稳定。
创作不易,禁止抄袭,转载请附上原文链接及标题

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)