强化学习调研
策略定义了智能体对于给定状态所做出的行为,换句话说,就是一个从状态到行为的映射,事实上状态包括了环境状态和智能体状态,这里我们是从智能体出发的,也就是指智能体所感知到的状态。
强化学习基本概念
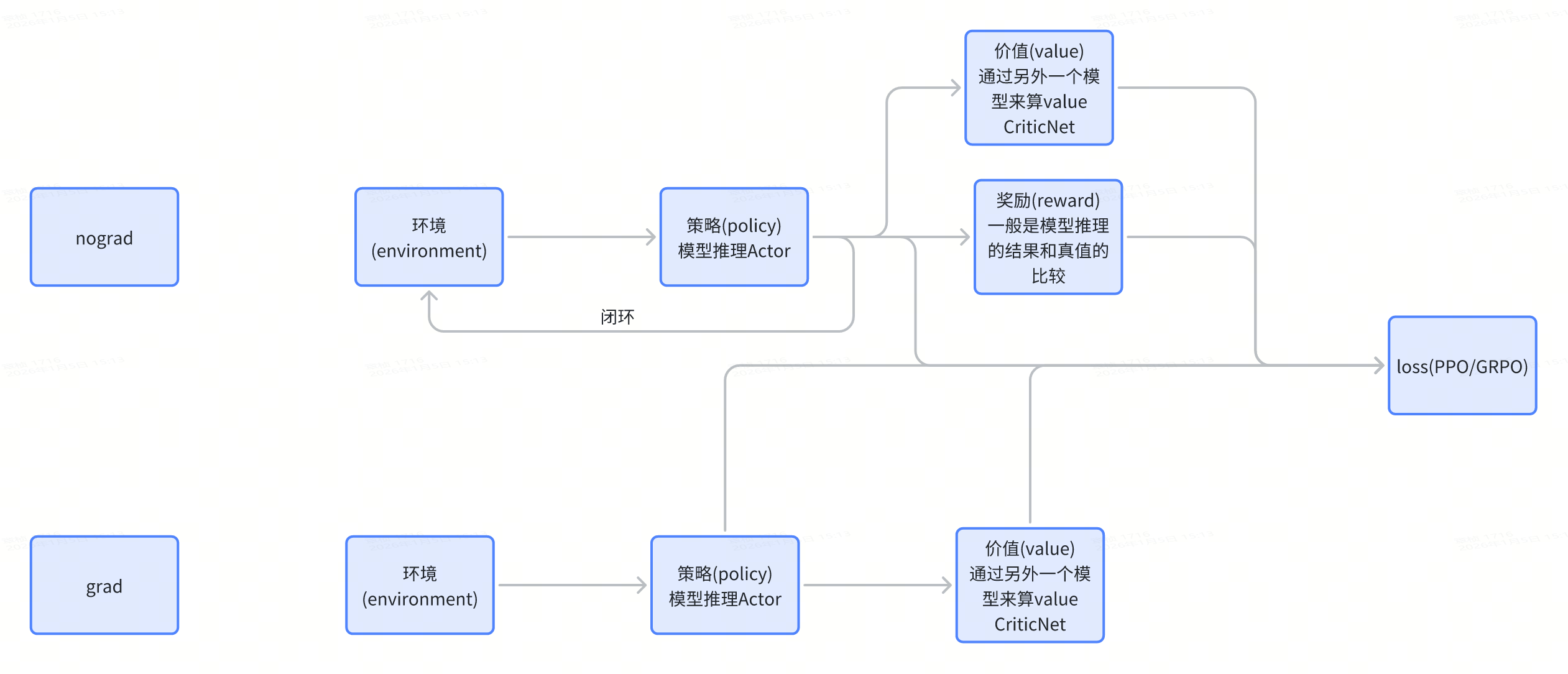
环境(Environment): 指agent信息和周围的环境信息,在开环强化学习中,环境信息不随着训练而变化,在闭环强化学习中,环境信息随着训练而变化
策略(Policy): 策略定义了智能体对于给定状态所做出的行为,换句话说,就是一个从状态到行为的映射,事实上状态包括了环境状态和智能体状态,这里我们是从智能体出发的,也就是指智能体所感知到的状态。
值函数(Value): 与奖励的即时性不同,价值函数是对长期收益的衡量
奖励(Reward):奖励信号定义了强化学习问题的目标,在每个时间步骤内,环境向强化学习发出的标量值即为奖励,它能定义智能体表现好坏,类似人类感受到快乐或是痛苦。因此我们可以体会到奖励信号是影响策略的主要因素。
蘑菇书EasyRL
https://datawhalechina.github.io/easy-rl/#/
- 整体来讲,强化学习是对每一个步骤进行打分,所以最经典的就是对马尔可夫这类问题进行强化(如自回归)
- 最朴素的强化学习,就是建立一张Q-table,根据Q-table中的q值来决定做什么action,如果Q-table随着action来变化,那么是Sarsa,如果Q-table不随着action来变化,那么是Q-learning
- 然后再引入神经网络之后,范式基本如GRPO/PPO所示
- Qlearning:其实就是一个贪心算法,每一步都保证选择的是Q值最大的方法。是要提前根据经验建立起一张Q-table,在每一步都给一个action的value。https://blog.csdn.net/qq_30615903/article/details/80739243
PPO和GRPO策略
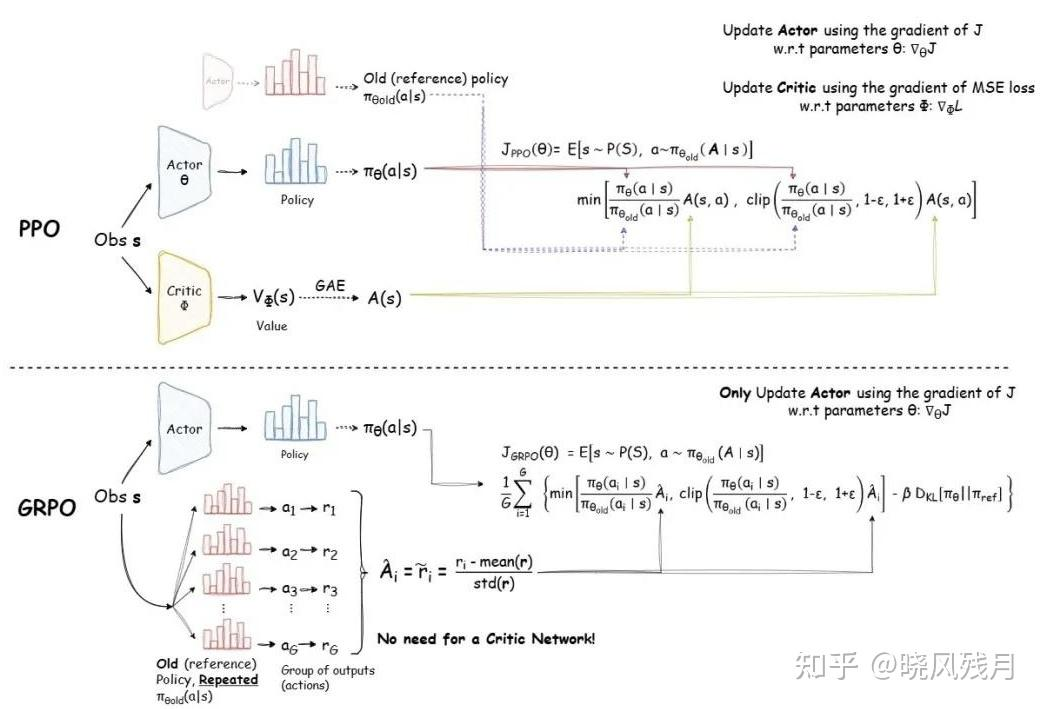
PPO(近端策略优化)
https://zhuanlan.zhihu.com/p/1885405099548975288
GRPO

RLHF
参考论文:carplanner https://arxiv.org/pdf/2502.19908
RLHF 是一个开环的RL,使用了PPO的方式
模型框架:使用action迭代式的自回归网路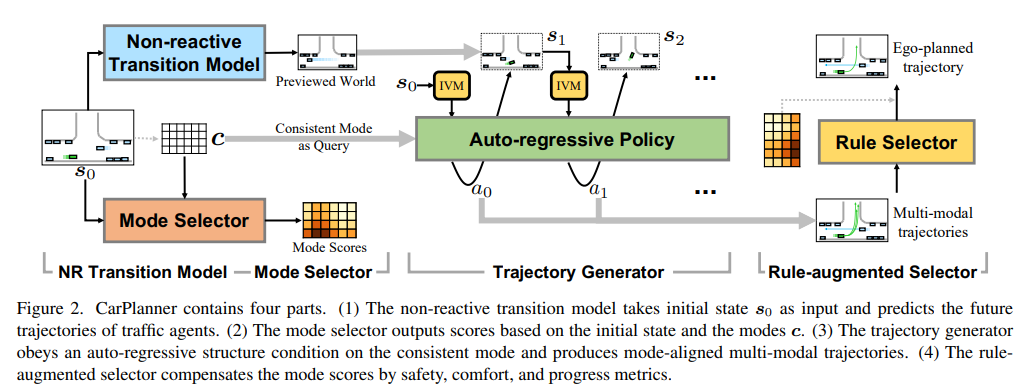
RIFT
是一个闭环的RL, 使用了GRPO的方式
https://arxiv.org/pdf/2505.03344
https://currychen77.github.io/RIFT/
模型框架 Pluto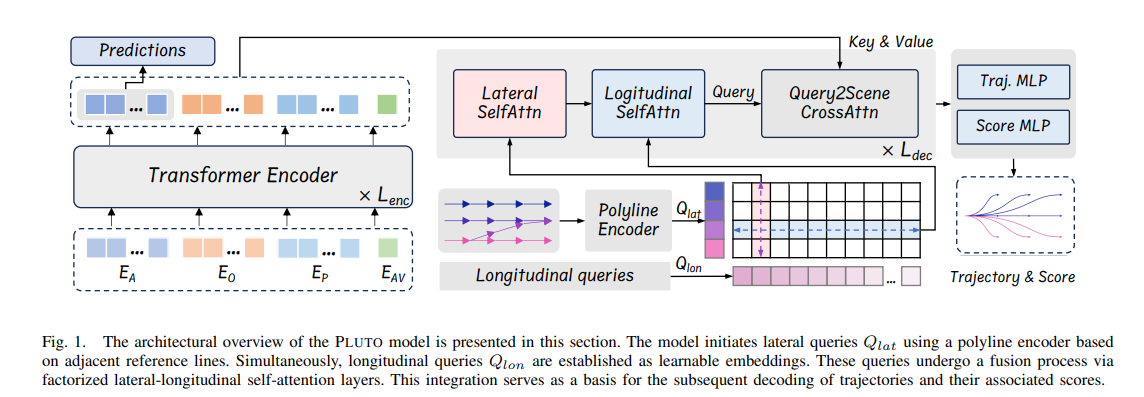
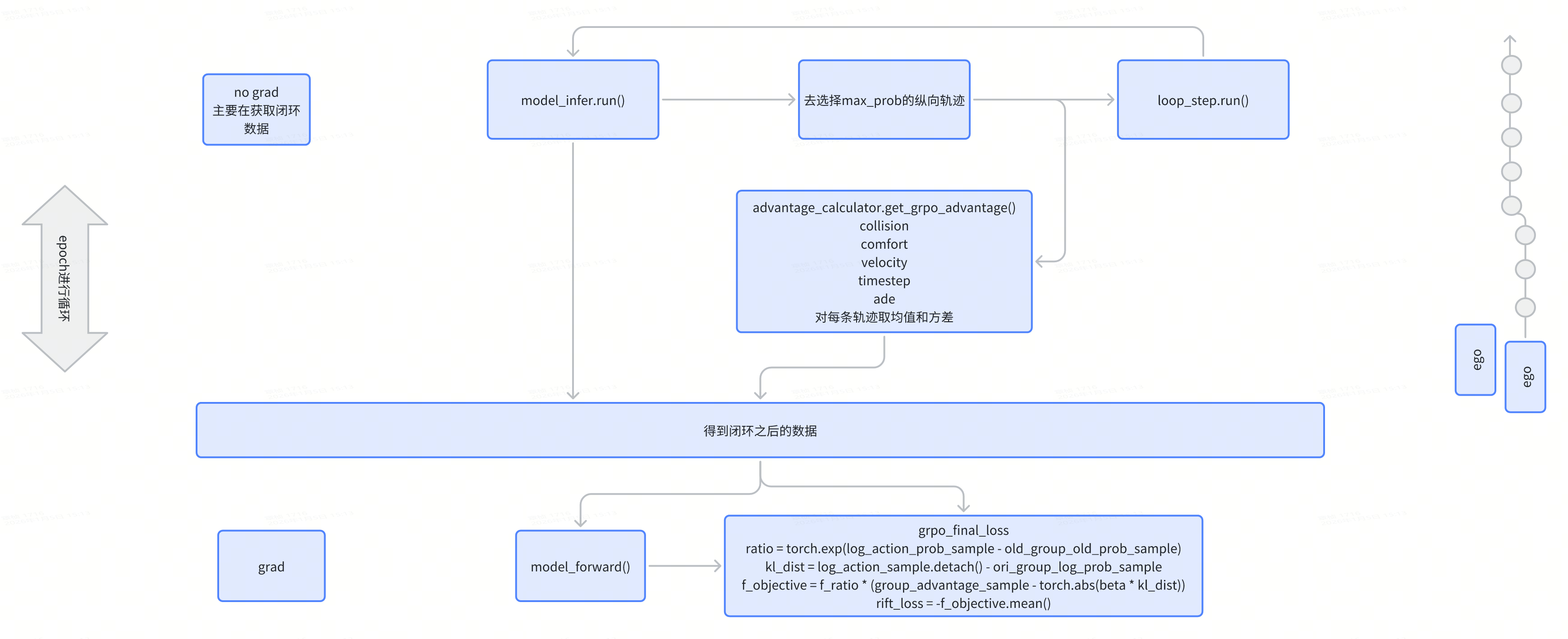


DIFFUSION + RL
- 可能会存在不居中问题
- MLP仓库中diffusion:feat-dev-imitation-anchor-free-luna-v0.3.2-diffusion
Diffusion Planner
论文:https://arxiv.org/abs/2501.15564
项目:https://github.com/ZhengYinan-AIR/Diffusion-Planner
DSRL
论文:https://arxiv.org/abs/2506.15799v2
项目:https://diffusion-steering.github.io/
知乎:https://zhuanlan.zhihu.com/p/1931276464025765013
DSRL的核心思想:扩散引导并非修改扩散策略的权重或对其输出进行后处理,而是通过改变其输入噪声分布来“引导”扩散策略生成所需动作。
整体来讲是个闭环ppo,除了critic action还会critic noise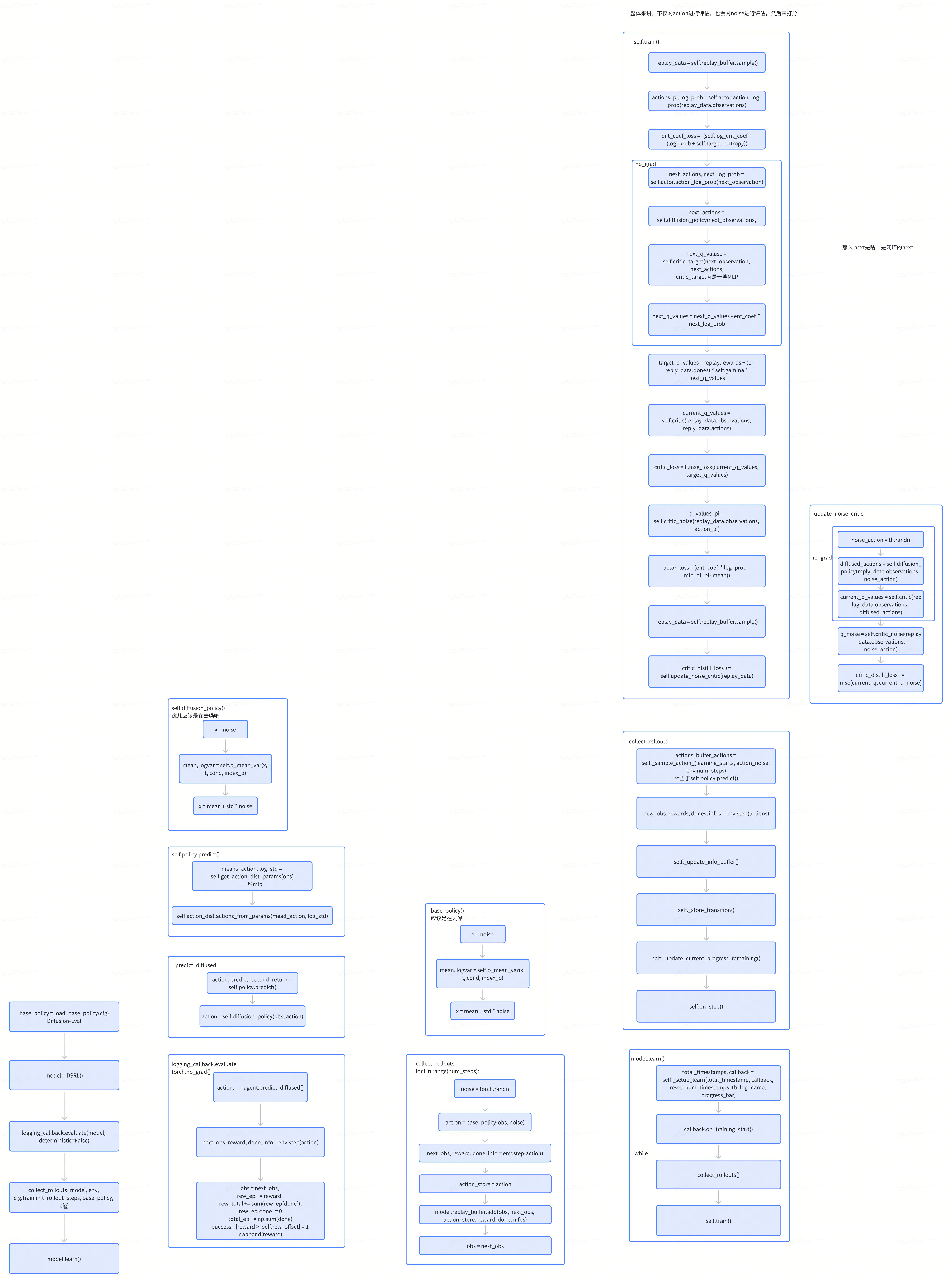
DiffusionDriveV2
公众号:https://mp.weixin.qq.com/s/2VNo5WpGMcLLrJiH-yv1MA
项目:https://github.com/hustvl/DiffusionDriveV2
使用GRPO进行学习,前10个epoch用rl学习,后面20个epoch用加噪声进行鲁棒
AR + RL
- AR可能会带来时延高的问题
- 论文MotionLM: https://arxiv.org/pdf/2309.16534
- MotionLM 动作转换为 token 的原理 在加速度空间上采样,横纵向加速度范围均为 -3.0m/s² 到 +3.0m/s²,每隔 0.5m/s² 采样一次,共 169 种行为

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)