从 0 调用智谱大模型:Python Demo 跑通 + 测试视角全拆解
本文从零开始演示如何申请并调用智谱 AI 大模型 API,通过一个最小 Python Demo 跑通完整链路。在此基础上,站在测试工程师视角,系统梳理了 messages 结构、role 使用、模型版本差异、temperature 稳定性、异常场景、网络超时与鲁棒性等关键测试点。文章重点强调:大模型并非“黑盒魔法”,而是一个需要被验证、约束和工程化的系统,适合正在转向 AI 测试或 AI 工程实践
使用智谱AI大模型:从申请 Key 到跑通 Demo(顺便聊聊测试点)
很多人对“大模型调用”有误解:以为很玄乎。
其实第一步就是——拿到 Key,跑通一个最小 Demo。跑通之后,站在测试视角,你才知道该测什么。
这篇就干三件事:
1)怎么申请智谱 API Key
2)用官方思路跑通 Python Demo
3)从测试角度列一波「最容易踩坑」的测试点
一、申请智谱 AI Key(一步一步来)
1)注册与实名认证
-
打开智谱 AI 开放平台:
https://open.bigmodel.cn/ -
注册/登录
-
按提示完成实名认证
一般来说:不实名,很多能力/额度/Key 都会受限制。
2)创建 API Key
-
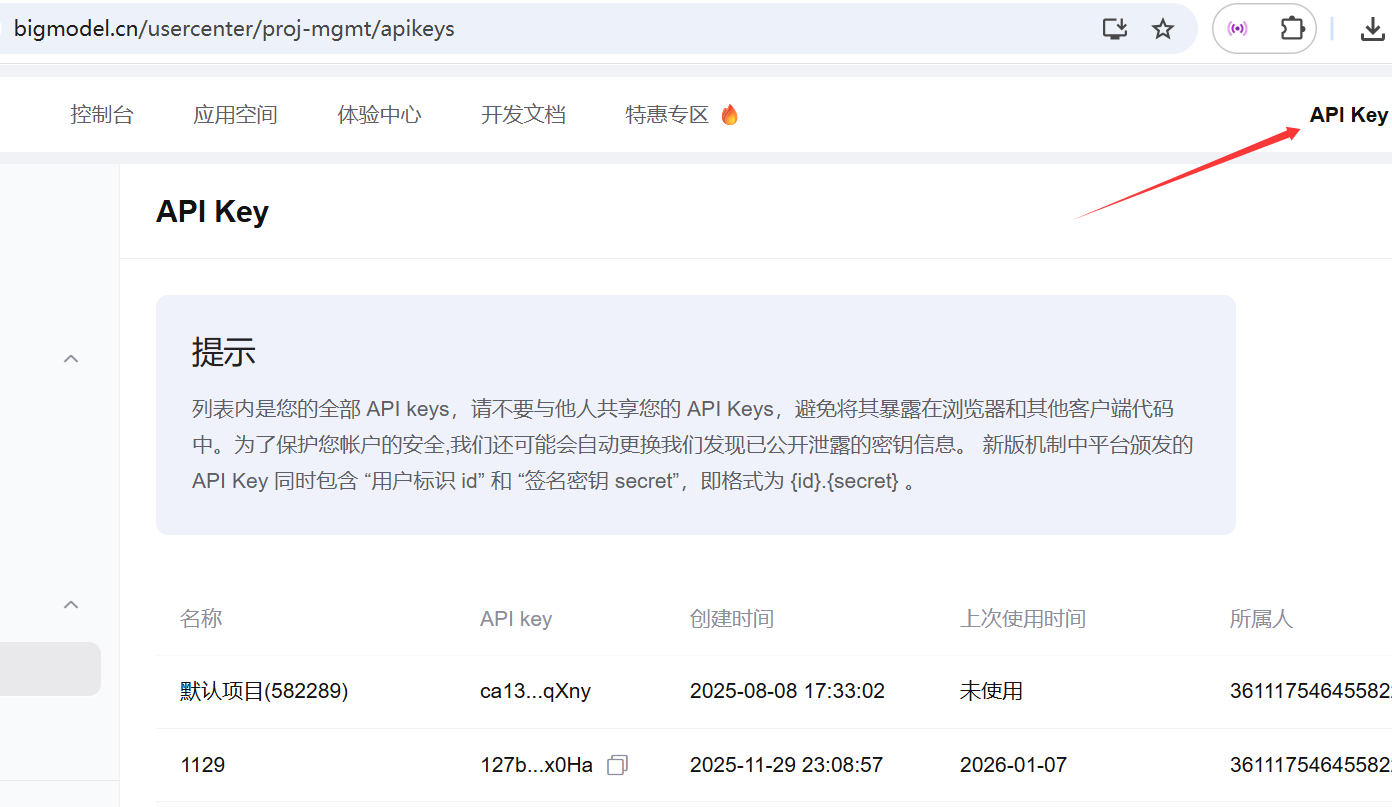
进入「用户中心 / API Keys / API密钥管理」页面
-
点击「创建新的 API Key」
-
写一个好记的名字(比如
my_project) -
系统会生成一串 Key
⚠️注意:Key 生成出来后请立刻复制保存,有些平台出于安全原因,后面不再展示完整 Key。
3)使用 API Key(先跑通再优化)
我建议:先按官方最小 demo 跑通,别一上来就搞工程化。
官方 quick-start(Python SDK):https://docs.bigmodel.cn/cn/guide/start/quick-start#python-sdk
二、Python Demo(最小可运行 + 带异常兜底 + 带测试视角输出)
1)安装 SDK
安装最新版本:
pip install zai-sdk 或者指定版本(遇到兼容问题时很有用):
pip install zai-sdk==0.2.02)验证安装
import zai print(zai.__version__)3)调用示例(建议直接复制跑)
说明:我这里为了文章演示,Key 直接写死。真实项目不要这么干(后面再改成环境变量/配置文件)。
from zhipuai import ZhipuAI
# 直接写 key(文章示例用,真实项目不要这么干)
client = ZhipuAI(api_key="你的key填这里")
# 构造最基础的 messages
# system:约束模型行为
# user:用户输入
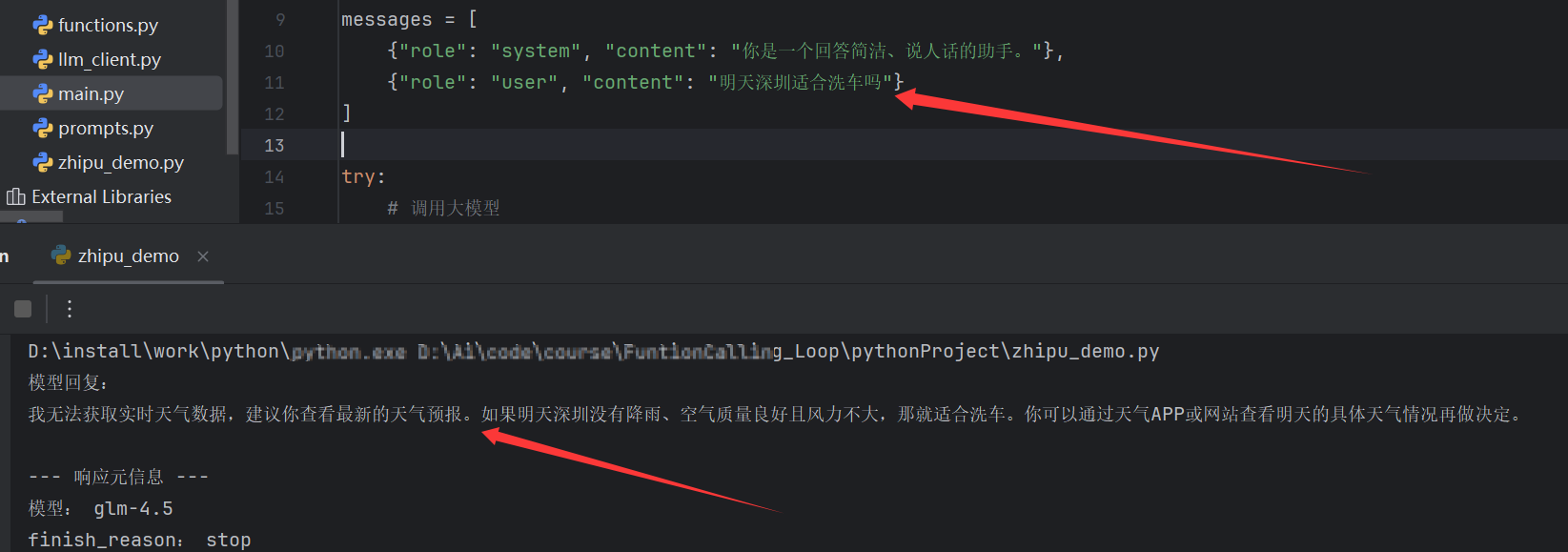
messages = [
{"role": "system", "content": "你是一个回答简洁、说人话的助手。"},
{"role": "user", "content": "用一句话解释什么是 智谱大模型。"}
]
try:
# 调用大模型
response = client.chat.completions.create(
model="glm-4.5",
messages=messages,
temperature=0.2
)
# 拿到模型真正返回的内容
answer = response.choices[0].message.content
print("模型回复:")
print(answer)
# 顺便打印一些“测试视角有用的信息”
print("\n--- 响应元信息 ---")
print("模型:", response.model)
print("finish_reason:", response.choices[0].finish_reason)
# 有些模型/版本会返回 token 使用情况
if hasattr(response, "usage"):
print("token 使用情况:", response.usage)
except Exception as e:
# 异常兜底
print("调用失败了:")
print(e)
4)我跑出来的响应示例

三、站在测试角度:这段 Demo 能测什么?
跑通 Demo 只是“能用”,但你做测试的价值在于:把它变得可靠、可控、可上线。
下面这些点,都是项目里非常常见的坑。
1)入参 messages 结构:role 写错会怎样?
messages 里最核心的是 role:
-
system:规则/边界/风格(权重最高) -
user:用户问题 -
assistant:模型历史回答(多轮对话才会用)
测试建议:
-
把
system和user写反,看看还能不能“看起来正常回答” -
多轮对话时,观察“规则是否还能生效”(很多时候第二轮就开始跑偏)
你会发现:
有时候写反也能回答,但这是“侥幸可用”,不是工程正确。
2)空输入 / 超长输入:报错还是截断?响应会不会暴涨?
常见用例:
-
content=""空字符串 -
超长输入(比如贴一大段日志/文档)
关注点:
-
是直接报错还是截断?
-
响应时间是否明显变长?
-
token 是否飙升(钱是不是烧得更快)
3)temperature=0 vs 1:输出稳定性差多少?
温度本质就是“随机性开关”。
建议测:
这块很适合写一句结论:
越需要稳定输出、越像系统能力,temperature 越应该低。
-
同一个问题,跑 10 次
-
temperature=0:看看是否几乎一致(更利于测试可重复) -
temperature=1:看看发散程度(更像聊天,但更不稳定)
4)model 名称写错:会返回什么错误?(最常见)
这个是真实项目里最常见的低级坑之一:
glm-4.5 写成 glm-45
或者写了一个平台不支持的型号
测试关注:
-
错误码是什么?(400/404/…)
-
错误信息是否可读?能不能快速定位原因?
5)同问题不同模型版本:回答是否一致?
比如:
glm-4.5
glm-4.7(如果平台支持/你有权限)
同一个问题重复问,观察:
-
事实一致性
-
结构一致性
-
风格是否更“啰嗦/更简洁”
-
以及:是否更容易出现幻觉
6)key 不对 / 没权限:401 还是别的?错误信息可读吗?
测试场景:
-
key 少一位
-
key 过期
-
key 没开通某个模型权限
关注点:
-
返回码是什么
-
错误提示是否能让人看懂(能不能直接指导用户怎么修)
7)鲁棒性测试:乱输入一串字符会怎样?
比如输入:
-
asdasd*&^%$#@! -
或者非常含糊:
帮我搞一下、你懂的
关注点:
-
模型会不会直接胡编?
-
会不会引导用户补充信息?
-
是否出现不合规/攻击性输出(安全也是质量的一部分)
8)超时 / 网络波动:要不要重试?重试几次?间隔多久?
真实项目一定会遇到:
-
网络抖一下
-
服务端偶发超时
-
502/504
测试关注:
-
你要不要 retry?
-
retry 几次?
-
间隔多久?
-
是否区分“可重试错误”和“不可重试错误”(比如 401 明显不该重试)
四、一个最容易被误解的点:模型能力是有限的
比如用户问:
明天深圳适合洗车吗?
大模型如果你只给它一个 chat 接口,它没有实时天气数据,也不会凭空知道“明天深圳下不下雨”。
它能做的通常是:
-
追问你:你在哪?要不要我查天气?
-
或者给你一个“通用建议”(但不保证准确)
想让它真的回答“明天深圳适合洗车吗”,你需要:
-
接入天气数据(工具/接口)
-
或者 RAG / 外部知识源
-
或者你的系统本身就提供了“深圳明天的天气”给它
一句话总结:
大模型不是万能的,它更像“会说话的大脑”;想让它干活,还得给它“眼睛和手脚”(数据和工具)。
五、结语:别急着“做应用”,先把最小链路跑通
很多人一上来就想做智能体、做 RAG、做产品。
但在我看来,第一步就是:
-
申请 Key
-
调通接口
-
打印响应元信息
-
用测试思维把“可用”变成“可控”
这套东西,看似简单,其实不然:
我做过 LLM 接口调用与稳定性验证,关注输入结构、异常场景、版本差异、鲁棒性与超时重试策略。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)