一起调试XVF3800麦克风阵列(七)
摘要:本文详细介绍了自动增益控制(AGC)系统的参数配置与优化方法。核心参数包括增益值(PP_AGCGAIN)、目标能量值(PP_AGCDESIREDLEVEL)、最大增益上限(PP_AGCMAXGAIN)和开关控制(PP_AGCONOFF)。文章阐述了AGC的五层处理机制,包括功率估计、目标计算、增益平滑、噪声抑制和硬限幅。特别强调了参数初始化、响应速度控制(TimeConstants)和可视化
1. 核心参数定义
AGC 的目标是无论说话者离麦克风远近,输出的音频音量都能保持在一个预设的“舒适区”。

| 参数名 | 功能描述 | 关键点 |
PP_AGCGAIN |
当前增益值 | 这是一个动态值。当 PP_AGCONOFF 开启时,系统会自动修改它;关闭时,它作为一个固定增益生效。 |
PP_AGCDESIREDLEVEL |
目标能量值 | 你希望输出音频达到的功率水平,PP_AGCGAIN 调整尽量满足这个功率 |
PP_AGCMAXGAIN |
最大增益上限 | 防止在安静环境下过度放大底噪(“沙沙”声)。 |
PP_AGCONOFF |
开关/锁定 | 设为 1 时 AGC 自动调整;设为 0 时锁定当前 PP_AGCGAIN 不再变化。 |
他对四个通道同时进行了相同的增益配置(对应我们前面分析的四个波束以及竞争策略):
| 通道编号 | 通道名称 | 中文说明 | 波束类型 | 主要用途 |
|---|---|---|---|---|
| 0 | Focused beam 1 | 聚焦波束 1 / 慢速波束 1 | 慢速自适应波束 | 用于固定方向拾音 |
| 1 | Focused beam 2 | 聚焦波束 2 / 慢速波束 2 | 慢速自适应波束 | 用于另一个固定方向拾音 |
| 2 | Free running beam | 自由运行波束 / 快速波束 | 快速自适应波束 | 可快速跟踪声源方向 |
| 3 | Auto select | 自动选择波束 | 自动选择机制 | 基于语音能量和方向选择最佳波束 |
2. 初始化
将左声道输出设置为 通道2:Free running beam。
xvf_host --use i2c AUDIO_MGR_OP_L 6 2将右声道输出默认为静音
xvf_host --use i2c AUDIO_MGR_OP_R 0 0设置 PP_AGCGAIN 的值为 1.0(动态值,即使初始化后,只要AGC开启就是个变化的值)
xvf_host --use i2c PP_AGCGAIN 1.0设置 PP_AGCMAXGAIN 的值为 1000 (默认值为125)
xvf_host --use i2c PP_AGCMAXGAIN 1000播放一段音频文件,如 IEEE_269-2010_Male_mono_48_kHz.wav 文件(!!!!请记住此时万万不可从树莓派中播放音频,因为目前回声消除在工作,你如果使用树莓派在播放的话回声消除会去掉播放的音频,此时应该将测试的喇叭外界声源进行播放 !!!)
aplay IEEE_269-2010_Male_mono_48_kHz.wav观察输出音频是否过大或者过小:

这里如果觉得电平过小或者过大请调整 PP_AGCDESIREDLEVE 参数,如果输出太小,增大 PP_AGCDESIREDLEVEL;如果太大,减小它。

dB 从来不是“绝对值”,它永远是:“跟谁比?”!!!
所以我们接下来解释下为什么会出现上面的公式:
dBov 的参考点 = 数字满量程(Full Scale):杯子装满 = 0 dBov,半杯 = –3 dBov;只和“满量程”有关!
为什么还要发明 dBm0:同样 –20 dBov正弦波、语音、噪声听起来完全不一样,需要一个统一的、和听感相关的参考点;–3 dBFS 幅度的正弦波 = 0 dBm0即为参考点! ----- 即dBm0 = “听起来有多响”!
dBov 的 0 点,数字满量程,正弦波峰值 = ±1,功率 = 1
dBm0 的 0 点,–3 dBFS 幅度的正弦波。峰值 ≈ ±0.707,功率 = 0.25
功率差了多少: 1 / 0.25 = 4 10log10(4) ≈ 6 dB
这就是为什么要加上6!!
我们来验证XVF3800 设置参数后与输出的的关系,我们在Audacity中分析幅度的RMS为:-23.3837dB
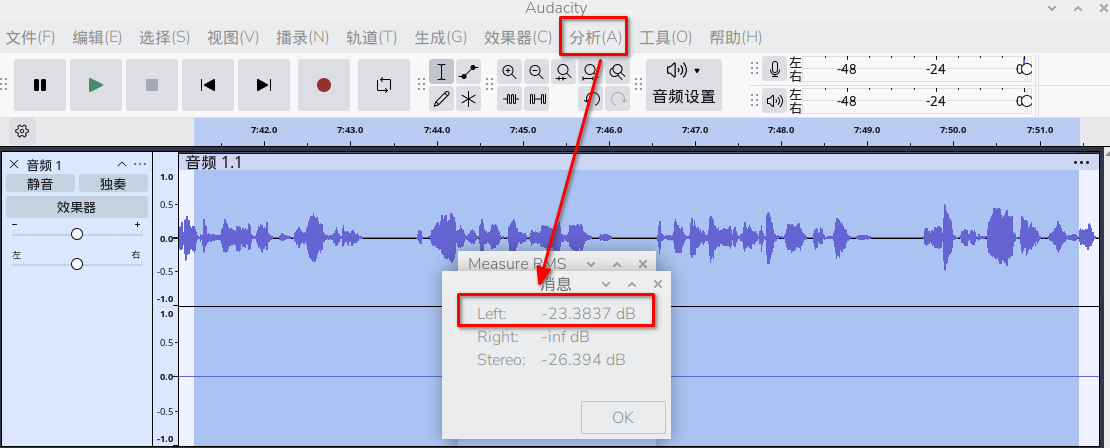
| 名称 | 域 | 对数系数 |
|---|---|---|
| Audacity RMS | 幅度 | 20·log10 |
| dBov | 功率 | 10·log10 |
| dBm0 | 功率(语音参考) | 10·log10 |
我们来反推:
幅度 dBFS → RMS 线性值
![]()
RMS → 功率
![]()
PP_AGCDESIREDLEVEL 与 反推 的功率误差小于2%!!!测量结果与计算式一致的!!!
3. 设定默认 (PP_AGCGAIN )
使用以下命令可视化实时AGC的的值:
python3 /home/raspberry/XVF3800-Software_v3_2_1-3/sources/xvf_tools.py agc_gain_plot /home/raspberry/host_xvf_control/build/xvf_host -p i2c
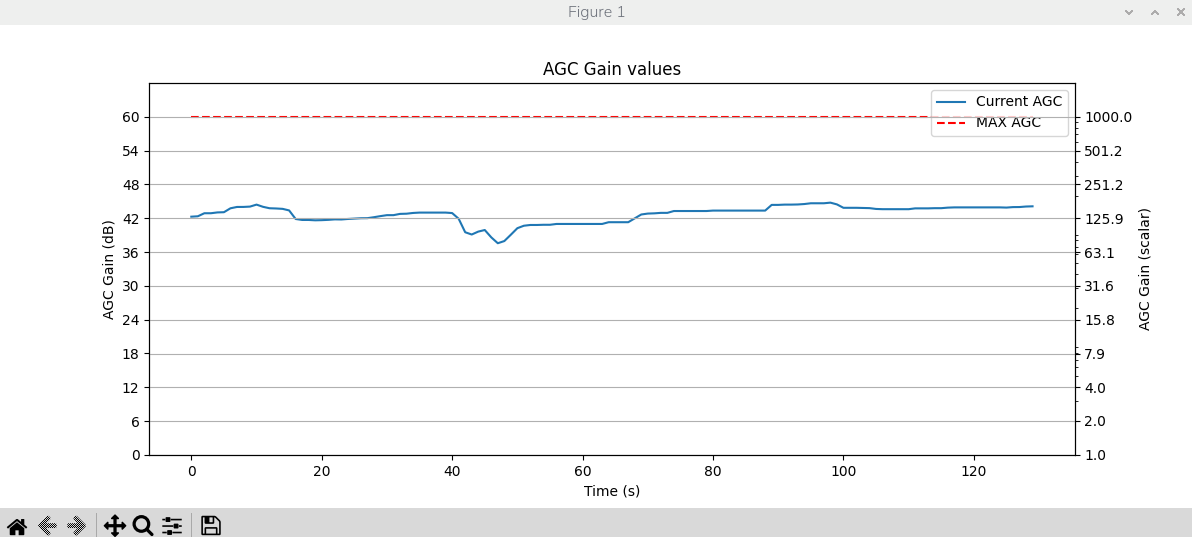
如图所示我们看到Y轴有两个刻度:
左Y 轴(dB):分贝单位,线性刻度,便于理解倍数关系;
右Y 轴(标量):线性增益因子,对数刻度,直接对应参数值;
dB = 20 × log₁₀(标量值),两个轴表示同一数据的不同单位;这样设计便于同时查看分贝和标量,满足不同使用习惯。
-
将测试信号降低 10dB(模拟远距离说话)。
-
让 AGC 再次收敛,记录此时稳定的
PP_AGCGAIN值。 -
将这个稳定值设为
PP_AGCGAIN(如上图所示设置默认值为125左右即可)。
还一个反直觉的为什么我们这个 PP_AGCGAIN 为一个变量我们还需要设置一个默认值?
-
缩短“收敛”时间:如果你的产品默认
PP_AGCGAIN是 1.0(不放大),但实际环境需要放大 10 倍,那么每次开机说话,前几秒声音会从很小慢慢变大,这叫“增益爬升”,体验很差。设定初始状态:通过将调试得到的稳定值(比如 5.0)写入固件作为默认值,设备一开机(即便 AGC 开启),它就直接从 5.0 开始工作。
3. 响应速度控制 (Time Constants)
虽然文档 不建议修改时间常数 ,但理解其逻辑有助于排查“声音忽大忽小”的问题:
-
增益变大时(从小声变大声):
通常使用慢速常数 (PP_AGCALPHASLOW),防止背景环境变化过快导致听感突变。
-
增益变小时(突然出现大声):
如果检测到瞬时功率远超平滑功率,会切换到快速常数 (PP_AGCFASTTIME),迅速压低增益以防止音频削波(Clipping/爆音)。
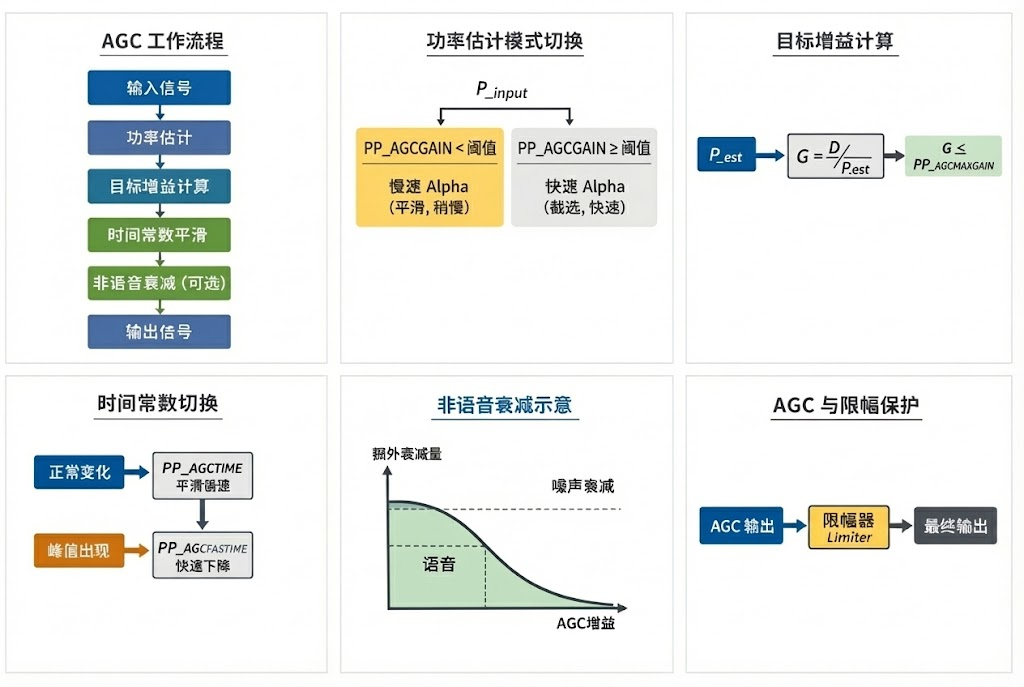
通过分析源码,AGC 的工作不是简单的音量放大,而是分为五个层次的接力处理:
-
第一层(功率估计):通过
Alpha参数决定“看多远”。它用指数平滑滤波器来估算当前的信号功率。 -
第二层(目标计算):计算
G_target = 目标电平 / 估算功率。 -
第三层(增益平滑):通过
Time参数决定“走多快”。防止增益突变导致听感不适。 -
第四层(噪声抑制):在非语音期间通过
ATTNS参数主动压低增益,解决“没说话时底噪大”的问题。 -
第五层(硬限幅):通过
PP_LIMITPLIMIT进行最后一道物理防线,防止爆音损坏设备。
Alpha 参数:功率估计的“记性”
-
PP_AGCALPHASLOW (0.984):记性好,平滑度高,对环境底噪不敏感。
-
PP_AGCALPHAFAST (0.36):记性短,反应快,能迅速捕捉到人声的开始。
-
联动逻辑:系统可以根据
PP_AGCALPHAFASTGAIN阈值自动切换这两者。在高增益(信号极弱)时切换到快速模式,可以极大地提高远场拾音的响应速度。
Time 参数:增益调整的“惯性”
-
PP_AGCTIME (0.9s):这是默认的调整速度。调大它,声音变化会像云一样缓慢平滑;调小它,音量调整会更“激进”。
-
PP_AGCFASTTIME (0.6s):专门用于下降。当突然出现大声时,系统必须比平时更快地压低增益,以保护听众的耳朵。
4. 开发建议
-
记录默认值:在实验室环境下调优后,你应该将稳定下来的
PP_AGCGAIN和PP_AGCDESIREDLEVEL作为固件的默认初始值。 -
可视化工具:强烈建议使用
agc_gain_plot。AGC 是一个动态过程,只看静态代码很难理解增益是如何“爬升”或“下降”的(甚至可以看到AGC的平滑时间是缓慢增加或者下降的!)。 -
注意 dBFS 定义:在进行音频认证(如 Microsoft Teams 或 Zoom 认证)时,务必确认对方要求的 dBFS 定义是否需要额外补偿 3dB。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)