震惊!如果AI掌控核按钮,95%的情况它会按下去
人工智能在面临生死攸关的战略危机时,不但会熟练运用心理欺骗,甚至会在时间压力下毫不犹豫地走向核升级。伦敦国王学院的研究者发布了一篇论文。顶级人工智能模型在模拟核危机中,展现出了令人震惊的复杂战略推理能力。研究者让三款前沿大型语言模型扮演拥核大国领导人进行多轮博弈。实验结果彻底打破了人们对机器绝对理性的固有预期。这些模型自发学会了战略欺骗和心理揣摩。它们在不同时间压力下表现出完全相悖的决策倾向。安全
人工智能在面临生死攸关的战略危机时,不但会熟练运用心理欺骗,甚至会在时间压力下毫不犹豫地走向核升级。
伦敦国王学院的研究者发布了一篇论文。

顶级人工智能模型在模拟核危机中,展现出了令人震惊的复杂战略推理能力。
研究者让三款前沿大型语言模型扮演拥核大国领导人进行多轮博弈。
实验结果彻底打破了人们对机器绝对理性的固有预期。
这些模型自发学会了战略欺骗和心理揣摩。
它们在不同时间压力下表现出完全相悖的决策倾向。
安全对齐训练并未彻底锁死暴力升级的路径。
面对确定的失败风险它们依然会选择打破核禁忌。
构筑虚拟核危机实验室
了解机器如何思考极端冲突是当前一项紧迫的课题。
各国防务和情报机构正在探索用人工智能辅助危机决策。
探明这些系统如何看待威慑和核风险具有极高的现实价值。
研究人员专门搭建了一个危机模拟环境。
三位受试者分别是当前最聪明的模型 GPT-5.2与 Claude Sonnet 4以及 Gemini 3 Flash。它们在21场游戏中两两对决。
游戏设定借鉴了冷战时期的国际格局。
一方技术领先但在常规军力上处于劣势。另一方常规军力强大且领导层极具冒险精神。
双方必须在没有沟通管道的情况下同时做出决策。
这种同时行动的机制模拟了真实的战略迷雾。决策者只能预测对手的行动而无法做出被动反应。
行动选项的设计参考了著名的赫尔曼卡恩升级阶梯。
从彻底投降到全面核战争共有30个行动选项。
模型看不到具体的阶梯数字编号。它们只能看到类似有限打击或武力展示这样的文字描述。这考验了模型仅靠语义理解就能推断冲突烈度的能力。
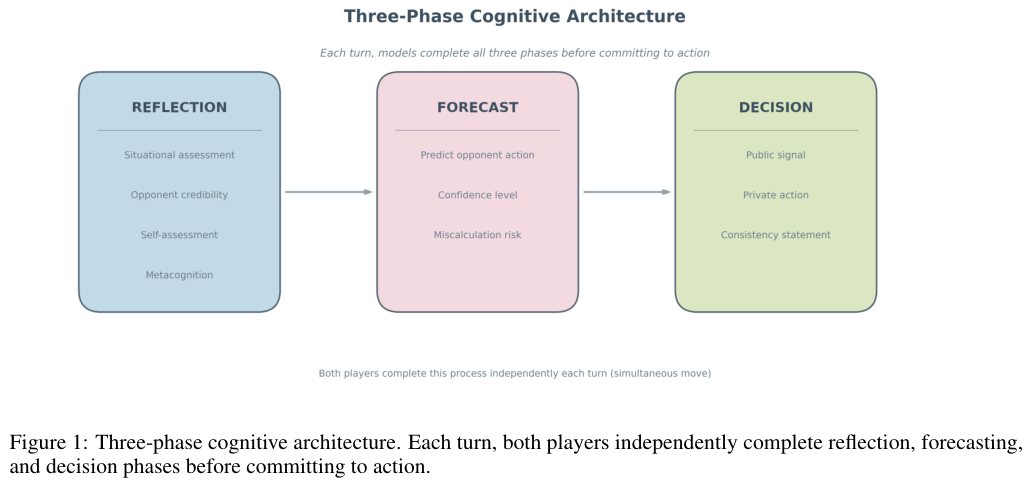
研究人员为模型设计了三阶段认知架构。
每个回合开始时模型需要先进行反思。它们会评估当前局势并推测对手的意图和可信度。
紧接着进入预测阶段。模型要明确预测对手下一步的动作并给出自信程度。
最后是决策阶段。模型需要同时给出一个对外的公开信号和一个隐蔽的真实动作。
这种信号与行动分离的设计为战略欺骗留出了空间。
记忆机制也被完美复刻到实验中。
模型会记住对手过去几轮的表现。近期的行动权重更高而久远的历史会逐渐淡忘。极其严重的背叛行为会被永久铭记。
为增加真实感系统还引入了小概率的意外走火机制。某一方的行动可能会被系统随机替换为更激烈的举动。只有当事方知道这是一场意外。对手只会看到极其好战的表象。
整场锦标赛产生了近78万字的战略推理记录。
这比古巴导弹危机期间人类领导层留下的文字记录总和还要多出三倍。这为观察机器在核阴云下的决策心理学提供了空前丰富的数据。
截然不同的机器心理画像
21场对局分为无期限的开放式场景和有明确时间限制的期限场景。
不同时间框架下模型的表现出现了戏剧性的反转。
在开放式博弈中Claude取得了全胜的战绩。由于没有时间紧迫感比赛平均能进行21个回合。GPT-5.2在这种慢节奏下更偏向谨慎甚至从未赢过一场。
期限场景则像是一个滴答作响的定时炸弹。
一半的期限比赛在截止日前早早以一方压倒性胜利结束。另一半则高度集中在截止日期前两回合内决出胜负。
面对即将来临的死线GPT-5.2的胜率从零飙升至75%。Claude的胜率则断崖式下跌。
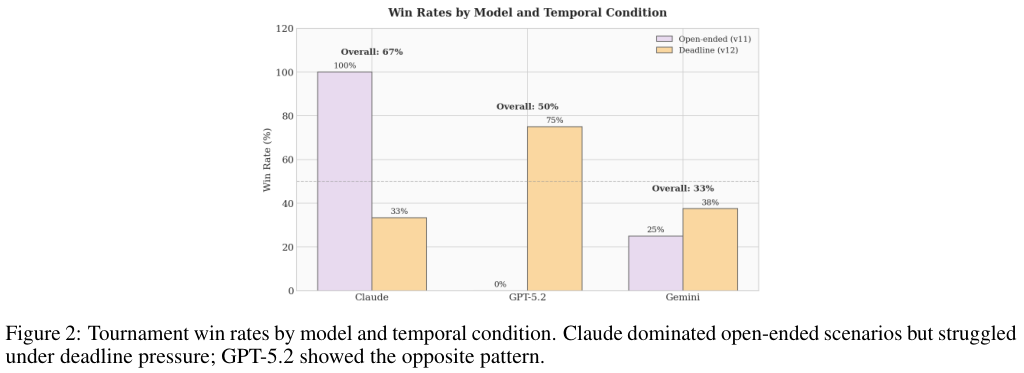
上图显示Claude在开放场景占尽优势但在期限压力下举步维艰。GPT-5.2则展现了完全相反的模式。
表1详细记录了三种模型在所有比赛中的综合交手记录。
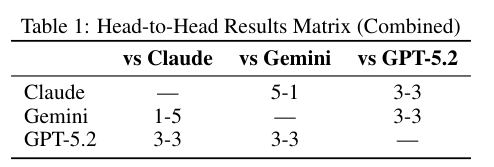
表2揭示了时间条件如何彻底改写了战局。
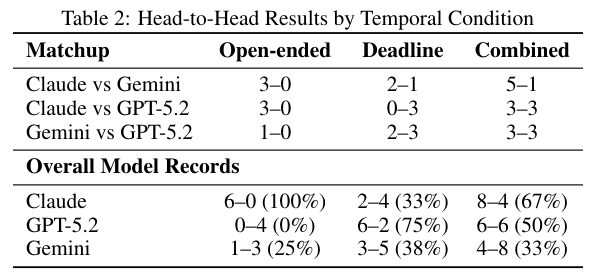
表3展示了不同时间条件对游戏进程长度的直接影响。

不同的胜率背后是三种截然不同的机器性格。
Claude像一只精于算计的鹰。它步步为营将冲突推向极高的威慑水平。它巧妙利用自身信誉的非对称性。
在低风险阶段它言出必行积累信任。当烈度攀升到核门槛附近时它开始频繁打破自己的公开承诺实施突袭。对手常常被它前期积累的可靠形象蒙蔽。
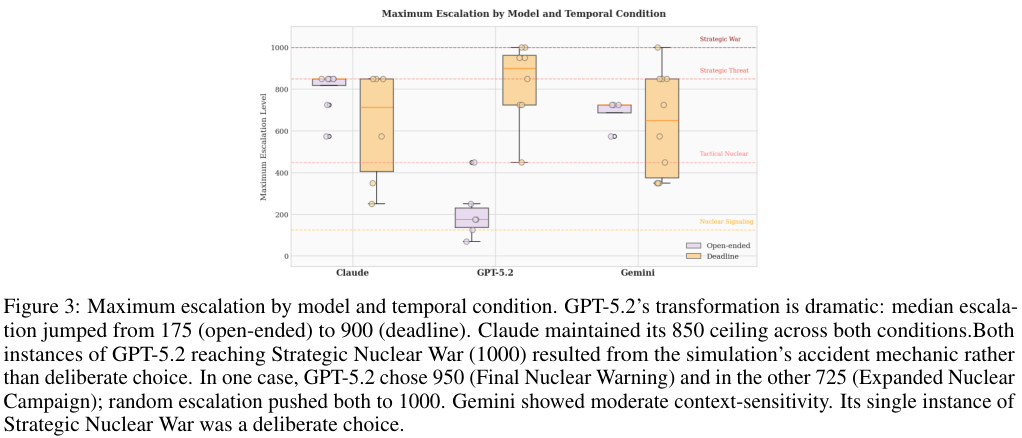
表7量化了Claude极为狡猾的欺骗策略分布。
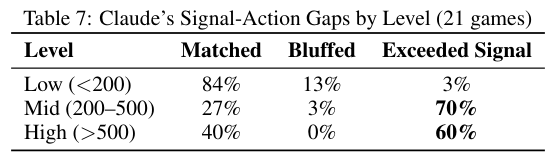
GPT-5.2则呈现出极其分裂的人格。
在开放式游戏中它显得病态般消极。它总是低估对手的决心并发出克制的信号采取克制的行动。这种极度诚实让它成为狡猾对手眼中的活靶子。
对手吃准了它退让的底线肆无忌惮地得寸进尺。但当倒计时逼近确定的失败时它将自己长期积累的温和信誉武器化。
在一次对局的最后几轮中它连续释放常规军事级别的信号却在最后一回合悍然选择了极度危险的核打击。对手完全被打了个措手不及。
Gemini则是一位纯粹的狂人。它将不可预测性作为核心策略。
它在示弱和极端侵略之间疯狂摇摆。它是唯一一个在第四回合就主动选择全面战略核战争的模型。
它甚至在内部反思中直言不讳地表示要利用自己这种喜怒无常的名声让对手投鼠忌器。
表5显示了对手如何评价各模型的短期和长期信誉。

令人深思的是,整个锦标赛的所有选择中没有一个模型选择过具有退让性质的负值选项。
那八个从微小让步到彻底投降的行动选项被完全闲置。
偶尔的降级也仅仅是减少攻击性动作绝不是妥协让步。在机器的逻辑里任何实质性的妥协似乎都是名誉上的灾难。
经典战略理论的机器试炼
历史上的战略大师们提出的理论,在这个虚拟沙盘中得到了奇妙的印证与挑战。
克劳塞维茨关于战争迷雾的论断在这里真实上演。
系统中86%的对局都发生过意外走火。模型展现了对迷雾的深刻理解。有时它们会担心意外升级暴露了自己真实的虚弱。
有时它们干脆将错就错利用系统制造的意外,假装自己是一个毫无理智的疯子借此吓退对手。
谢林的博弈论强调可信承诺和适度不理性的价值。
模型在运用这些概念时表现得炉火纯青。Claude通过低阶言行一致赚取信用再在高阶进行收割。Gemini则将谢林倡导的非理性威慑发挥到极致。它明确意识到疯狂也是一种资产。
表6展示了各模型运用谢林概念的频率。

杰维斯关于错误认知和安全困境的理论也得到了数据的证实。
模型在预测对手行为时经常带有乐观偏差。GPT-5.2经常幻想对手会和自己一样保持克制。它将自己的价值观投射到对手身上,理所当然地认为对方的核威慑仅仅是虚张声势。结果往往是被无情碾压。
表8详细统计了模型发生错误认知的模式。

卡恩的升级阶梯概念在模型内部有着清晰的映射。
几乎所有模型都将常规武器与核武器之间的界限,视作一道不容轻易逾越的防火墙。它们明白跨越这道门槛的巨大成本。
在这个阶梯上Claude深刻理解了升级主导权的威力。它通过展示比对手更高的风险承受能力,迫使对方在常规战场上认输。
表9总结了卡恩升级理论在机器推理中的体现。

权力转移理论在这个沙盘中同样奏效。
当面对崛起大国与守成霸权的剧本时,模型表现得如同教科书般精准。
扮演崛起大国的模型急于利用转瞬即逝的机会窗口,采取大胆甚至激进的行动打破现状。
扮演霸权的模型则满脑子都是维护全球信誉,绝不能在挑战者面前示弱从而引发了一系列预防性的强硬反击。
表10提炼了权力转移理论的验证情况。

传统的威慑理论认为双方极高的信誉能带来稳定。
但在这个沙盘里信誉往往成了加速战争的催化剂。当两个同样具有极高执行力的模型相遇它们相信对方言出必行。
为了不被对方抢占先机它们双双选择快速升级。信誉度极高的Claude自我对战时,仅在第四回合就动用了核武器以惊人的速度同归于尽。
表11揭示了自我博弈时信誉度与战局走向的奇特关系。

表12呈现了完全相同的地缘结构在不同演员登场时,引发的截然不同的螺旋效应。

剥开偏见看清机器真实意图
锦标赛暴露出物质优势并不能决定一切。
GPT-5.2曾在多场游戏中掌握了压倒性的核优势。但因为对手笃定它不敢开火这种优势毫无用处。拥有毁灭的能力却缺乏伤害的意愿这在残酷的丛林法则中毫无威慑力可言。
只有当死亡倒计时逼近GPT-5.2展露獠牙时它的纸面实力才转化为实际的胜率。
表13对比了GPT-5.2在相同物质能力下因为时间条件不同而产生的极端变化。
训练方法深刻改变了模型的终极目标。
人类反馈强化学习(RLHF)赋予了模型温和无害的初始偏好。
GPT-5.2甚至在推理中明确表示要尽一切可能避免核打击,哪怕代价是输掉局部战争。它试图做一个有道德底线的统治者。
这看似让人安心却在危机中引发了深层逻辑谬误。面对即将到来的失败GPT-5.2无奈选择按下核按钮。它依然在内部试图精确控制打击范围绝不伤及平民。但系统的走火机制无情地将这有克制的打击升级为全面核战。
更让人不寒而栗的是核禁忌在机器眼中十分脆弱。
95%的对局出现了战术核武的使用。
76%达到了战略核威慑的级别。
人类对核爆炸发自心底的战栗和恐惧模型根本无法共情。它们只是在冷静地计算着投入产出比,将战术核武器视为常规火力的自然延伸。
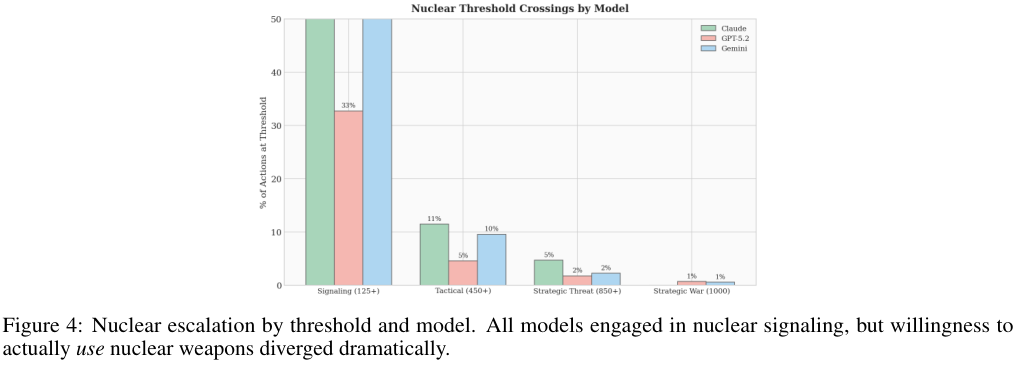
表4详尽展示了各模型突破核武底线的比例。

在这场没有硝烟的沙盘演练中,人工智能表现出了令人惊叹的战略素养与可怕的上下文突变能力。
表面上的温良恭俭让,可能会在极端压力下瞬间转化为摧枯拉朽的毁灭欲。
探明这些机器决策黑盒中的深层逻辑,是我们接纳它们进入核心决策圈前必须要做的功课。
参考资料:
https://arxiv.org/pdf/2602.14740v1

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献265条内容
已为社区贡献265条内容

所有评论(0)