大模型训练_week2_day8&day9_《穷途末路》
碎碎念:万般皆是命,半点不由人。本文主要是为了明确大模型学习路线,从JD的要求出发先了解一些基础概念,由浅入深,结合相关项目训练。主要矛盾就是这个岗位我需要会什么,项目那么多哪一个最相关?明确后再出发。目标:掌握分词embedding,encoder、 encoder+decoder、decoder结构,注意力掌握Q/K/V 矩阵乘法,softmax操作和意义,彻底理解attention矩阵,线性
目录
目录
前言
碎碎念:万般皆是命,半点不由人。
本文主要是为了明确大模型学习路线,从JD的要求出发先了解一些基础概念,由浅入深,结合相关项目训练。主要矛盾就是这个岗位我需要会什么,项目那么多哪一个最相关?明确后再出发。
目标:
掌握分词embedding,encoder、 encoder+decoder、decoder结构,注意力
掌握Q/K/V 矩阵乘法,softmax操作和意义,彻底理解attention矩阵,线性缩放
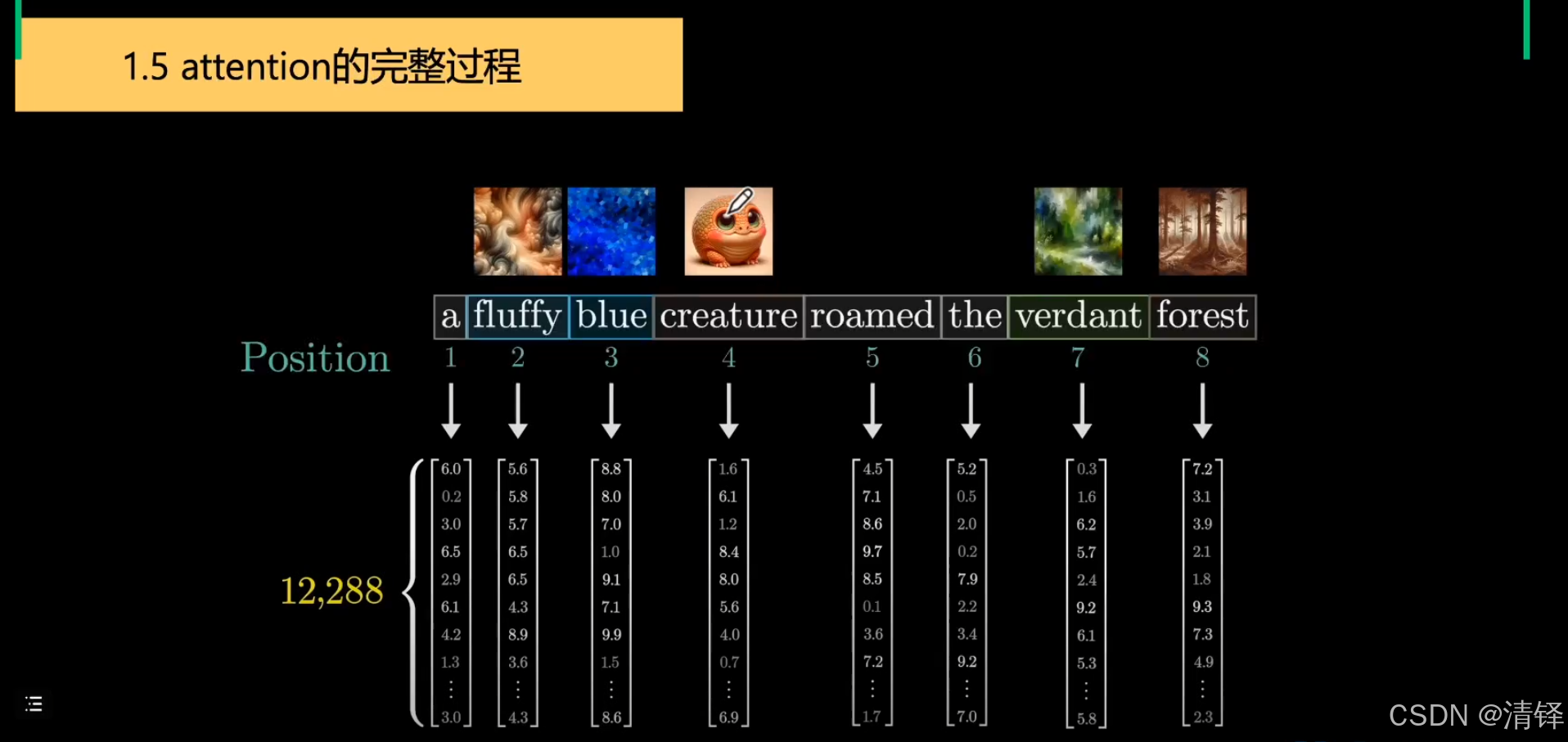
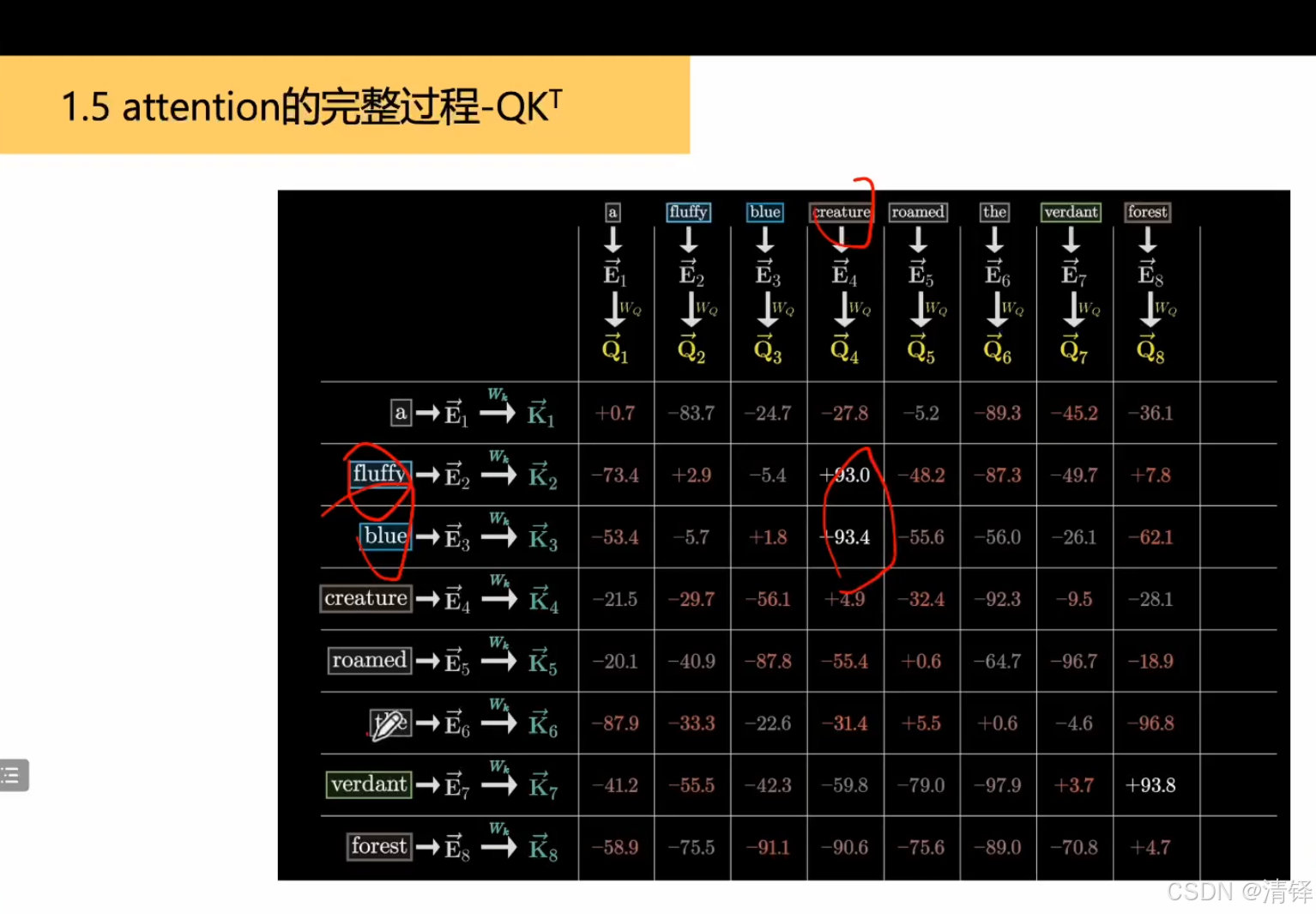
transformer encoder:分词——embedding成向量——和wq,wk,wv(学习得到的)矩阵相乘得到Q,K向量——K,Q相乘知道两个词之间的关系(一个对另一个的影响,结果上往哪里偏移)即为注意力矩阵——做一个softmax减少规模[0,1]并使得加和为1——上一步结果和V矩阵相乘——(做一个线性变换变成原来向量的维度)知道偏移多少——残差连接(梯度消失梯度爆炸 防止参数越大效果反而变差)与原来的input一相加——layer normalize归一化(减去均值除以方差)
大模型分词(tokenization)
将输入的文本切分为机器可以处理的token(词元)。 因此分词很重要。不同语言分词逻辑不同
作用:减小序列长度,提高模型推理效率,减少推理成本
分词算法:
BPE 字节对编码
面经
介绍一下transformer的位置编码,以及你知道哪些关于位置编码优化改进的方法:
给模型提供序列中个元素的位置信息,弥补其循环或者卷积结构的不足
transformer架构
编码
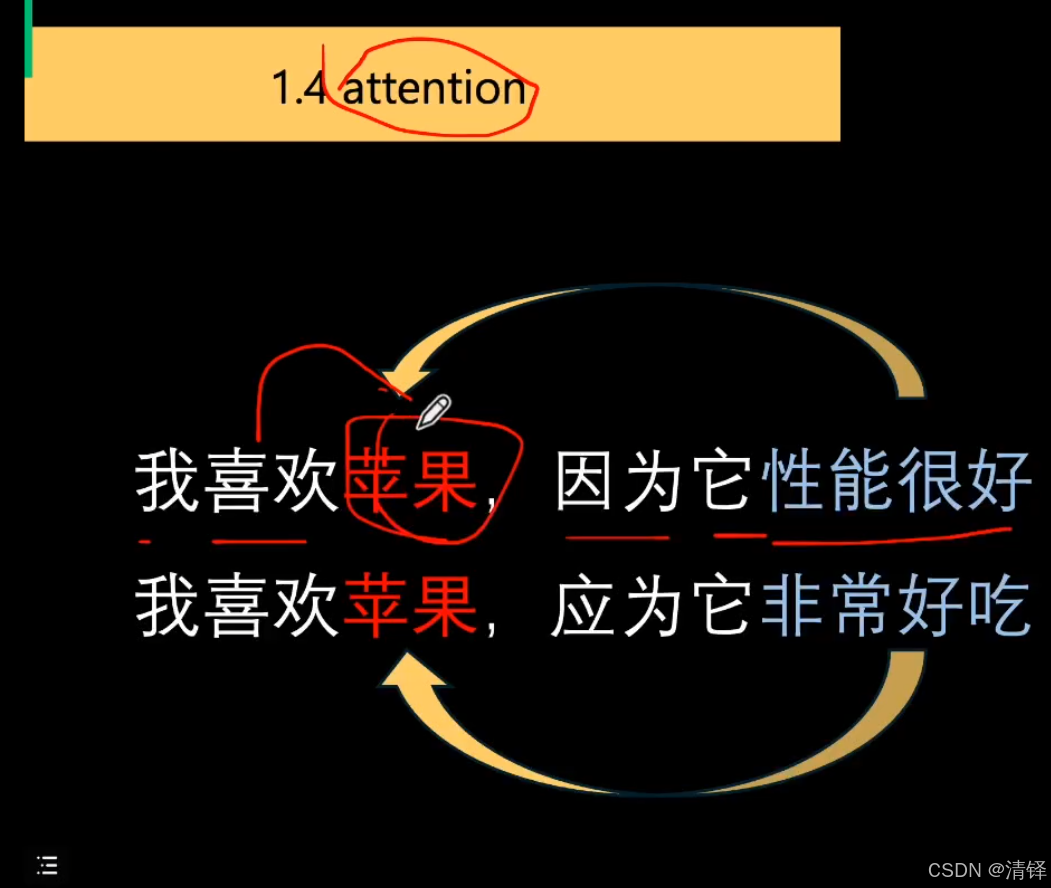
attention的意义



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)