【AI课程领学】第六课 · Transformer(课时2) Transformer 经典结构:Encoder、Decoder、BERT、GPT、ViT(含代码)
【AI课程领学】第六课 · Transformer(课时2) Transformer 经典结构:Encoder、Decoder、BERT、GPT、ViT(含代码)
·
【AI课程领学】第六课 · Transformer(课时2) Transformer 经典结构:Encoder、Decoder、BERT、GPT、ViT(含代码)
【AI课程领学】第六课 · Transformer(课时2) Transformer 经典结构:Encoder、Decoder、BERT、GPT、ViT(含代码)
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可扫描博文下方二维码 “
学术会议小灵通”或参考学术信息专栏:https://ais.cn/u/mmmiUz
详细免费的AI课程可在这里获取→www.lab4ai.cn
前言
上一课我们掌握了组件,这一课把组件拼成“经典结构”。你会发现:
- 原始 Transformer 是 Encoder-Decoder(适合翻译、摘要)
- BERT 是 Encoder-only(适合理解、分类、抽取)
- GPT 是 Decoder-only(适合生成)
- ViT 把图像 patch 当 token,用几乎同样的结构做视觉任务
1. 原始 Transformer:Encoder-Decoder 架构
1.1 Encoder Block
每一层 Encoder 包含两部分:
- Multi-Head Self-Attention(全局建模输入序列内部关系)
- FFN(非线性映射)
结构(Pre-LN 表达):
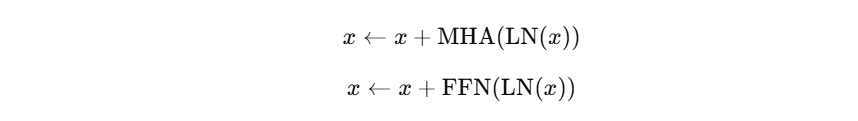
1.2 Decoder Block
Decoder 比 Encoder 多一个模块:
- Masked Self-Attention(只能看过去)
- Cross-Attention(Q 来自 decoder,K/V 来自 encoder 输出)
- FFN
Cross-Attention 的意义:在生成每个输出 token 时,动态关注输入序列的相关片段。
2. Encoder-only:BERT(理解模型)
BERT 只用 Encoder 堆叠:
- 训练目标:Masked Language Modeling(MLM)等自监督
- 用于:文本分类、序列标注、检索、特征抽取
- 推理时:经常取 [CLS] token 的表示做分类
关键点:BERT 的注意力是双向的(没有 causal mask)。
3. Decoder-only:GPT(生成模型)
GPT 只用 Decoder 堆叠,但通常没有 Cross-Attention(因为没有 encoder),只保留:
- Masked Self-Attention(causal mask)
- FFN
训练目标:自回归 next-token prediction: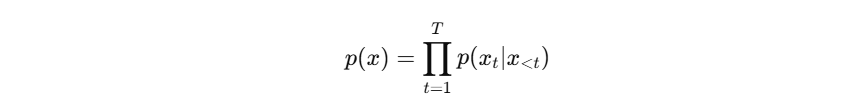
4. Vision Transformer(ViT):把图像当序列
ViT 的核心思想:
- 把图像切成 patch(比如 16×16)
- 每个 patch flatten → 线性投影到 d_model
- 加上位置编码与
[CLS]token - 堆叠 Transformer Encoder
- 用
[CLS]输出做分类
5. PyTorch:最小可复用 Transformer Encoder Block(Pre-LN)
- 下面给一个简洁但“工程可用”的 Encoder Block(可做 NLP 或时序特征建模):
import torch
import torch.nn as nn
import math
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff=4, dropout=0.1):
super().__init__()
self.net = nn.Sequential(
nn.Linear(d_model, d_model * d_ff),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(d_model * d_ff, d_model),
nn.Dropout(dropout),
)
def forward(self, x):
return self.net(x)
class TransformerEncoderBlock(nn.Module):
def __init__(self, d_model=128, num_heads=4, d_ff=4, dropout=0.1):
super().__init__()
self.ln1 = nn.LayerNorm(d_model)
self.ln2 = nn.LayerNorm(d_model)
self.attn = nn.MultiheadAttention(d_model, num_heads, dropout=dropout, batch_first=True)
self.ffn = FeedForward(d_model, d_ff=d_ff, dropout=dropout)
def forward(self, x, key_padding_mask=None):
# x: (B,T,D)
# key_padding_mask: (B,T), True 表示 padding 位置
h = self.ln1(x)
attn_out, _ = self.attn(h, h, h, key_padding_mask=key_padding_mask, need_weights=False)
x = x + attn_out
x = x + self.ffn(self.ln2(x))
return x
# quick test
x = torch.randn(2, 20, 128)
block = TransformerEncoderBlock(128, 4)
y = block(x)
print(y.shape)
6. 经典结构如何选:任务到结构的映射
- 分类/回归/表征学习:Encoder-only(BERT-like)
- 文本生成/序列生成/预测未来:Decoder-only(GPT-like,causal mask)
- 翻译/摘要/条件生成:Encoder-Decoder(Cross-Attention)
- 图像分类:ViT(Encoder-only)
- 长序列时间序列预测:可以用 Encoder-only + 预测头,或 Decoder-only 自回归
7. 小结与练习
你现在知道 Transformer 的三大“经典形态”:
- Encoder-Decoder(原始 Transformer)
- Encoder-only(BERT)
- Decoder-only(GPT)
练习
- 用
TransformerEncoderBlock堆叠 4 层,做一个序列分类(取平均池化或取第 0 个 token) - 给
key_padding_mask构造变长序列,验证 padding 位置是否被忽略 - 修改为 causal mask,变成 decoder-only block

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)