代码谁更强?ChatGPT、Claude、Gemini 3:一次性工程交付实测
三大最强Ai模型真实工程交付能力实测
这不是临时起意的对比。
⏱️ 这组测试我前后花了几个小时,反复跑同一组 Prompt,统一约束条件,只关注一件事:
模型能否在第一次输出时,就把工程完整交付出来,并且可以直接运行。
测的不是算法能力,也不是榜单排名,而是一个更贴近真实使用的问题:
🔍 当你把需求一次性丢给模型,它到底能不能给你一个“不用修、能直接跑”的工程?
不讲跑分,不看榜单。
📌 这次只测一件事:
在完全相同的 Prompt 下,让模型一次性输出一个可运行的前端 / 交互工程,谁更稳,谁更接近成品。
这种测试,比算法题或单点能力展示,更接近真实开发与实际交付场景。
在正式开始前,先把边界说明清楚:
⚠️ 1)本文展示为运行截图,无法完整呈现帧率、操作手感、边界 Bug 等运行细节;
⚠️ 2)单次测试无法定义模型的综合能力,但足以反映它们在「工程交付」上的默认风格与取向差异。
结论先给(记住这三句就够了)
✅ Claude:偏“交付型输出”,系统结构与 UI 更完整,更像一个可直接展示的成品 Demo
✅ ChatGPT:偏“稳定型实现”,逻辑闭环清晰,代码可读性高,适合继续迭代
✅ Gemini 3:偏“快速原型”,代码更短,优先把东西跑起来、先看到效果
如果你做过真实项目,这三种风格基本一眼就能分出来。
本次测试到底在测什么?
规则非常简单,但也非常苛刻:
- 同类 Prompt
- 一次性输出完整工程
- 不允许分步补全
- 不允许人工修复
唯一判断标准只有一个:
🎯 能不能直接跑起来,以及“像不像一个完整作品”。
案例一:分形可视化(Fractal Visualizer)
Prompt(完全一致):
Generate a complete, runnable HTML/CSS/JavaScript project
that renders an interactive fractal visualization.
Requirements:
- Canvas or WebGL rendering
- Mouse interaction (zoom / color / movement)
- No pseudo code
- Output must run immediately in browser
图 1:ChatGPT
图 2:Claude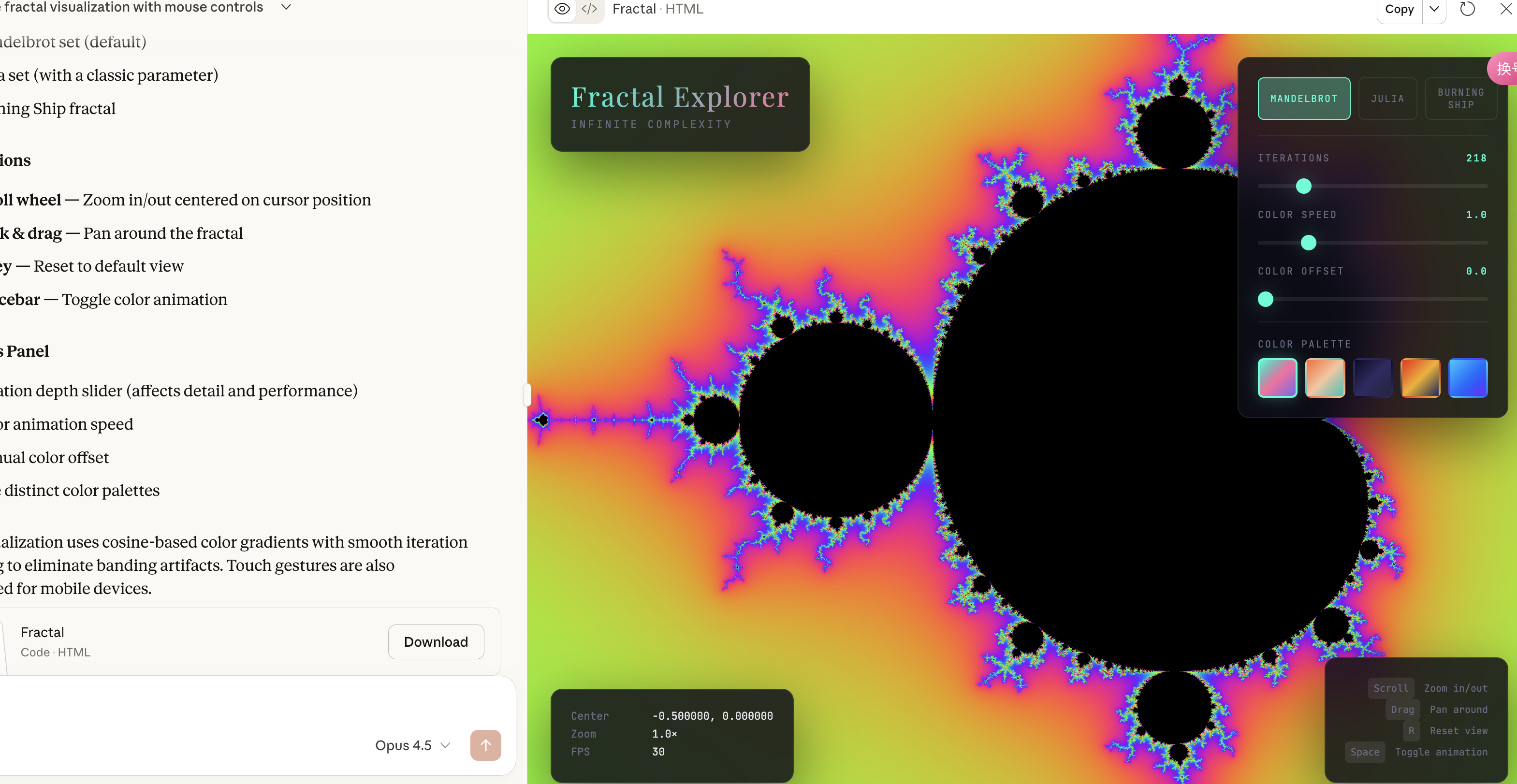
图 3:Gemini
综合对比
| 模型 | 代码规模 | 工程完整性 | 视觉效果 | 更适合谁 |
|---|---|---|---|---|
| Claude | ⭐⭐⭐⭐☆ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 做展示 Demo / 项目雏形 |
| ChatGPT | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐☆ | 教学 / 可维护实现 |
| Gemini 3 | ⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ | 视觉演示 / 快速验证 |
一句话总结:
Claude 更像在交付工程,ChatGPT 更像在写可维护代码,Gemini 更像在做视觉原型。
案例二:无限跑酷(Endless Runner)
Prompt:
Build a playable endless runner game using HTML/CSS/JavaScript.
Include:
- Keyboard controls
- Game loop
- Score tracking
- Collision detection
Provide complete runnable code.
图 1:Gemini(约 300 行,能玩但非常简化)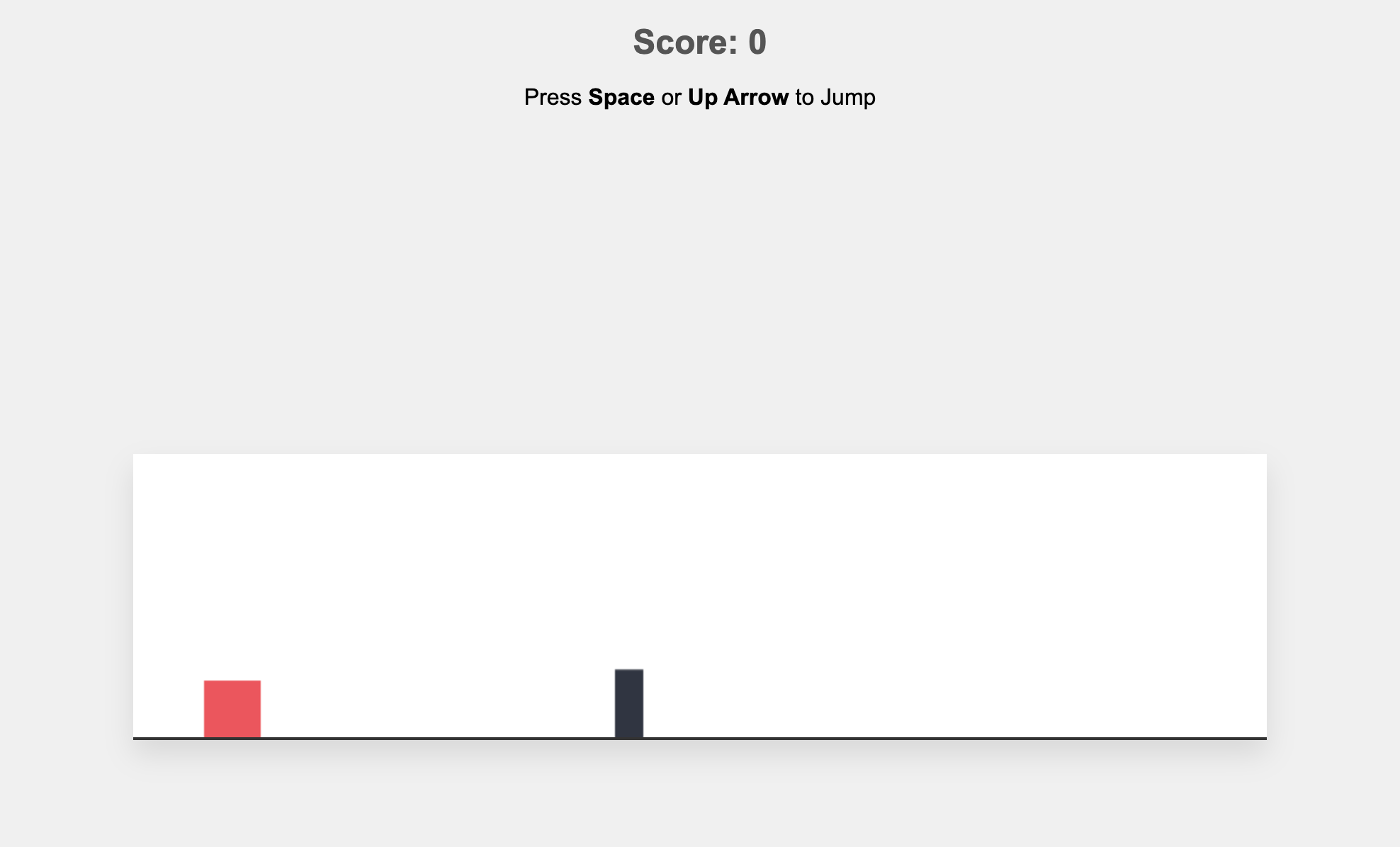
图 2:Claude(约 750–800 行,完成度最高)
图 3:ChatGPT(约 800 行,标准可玩)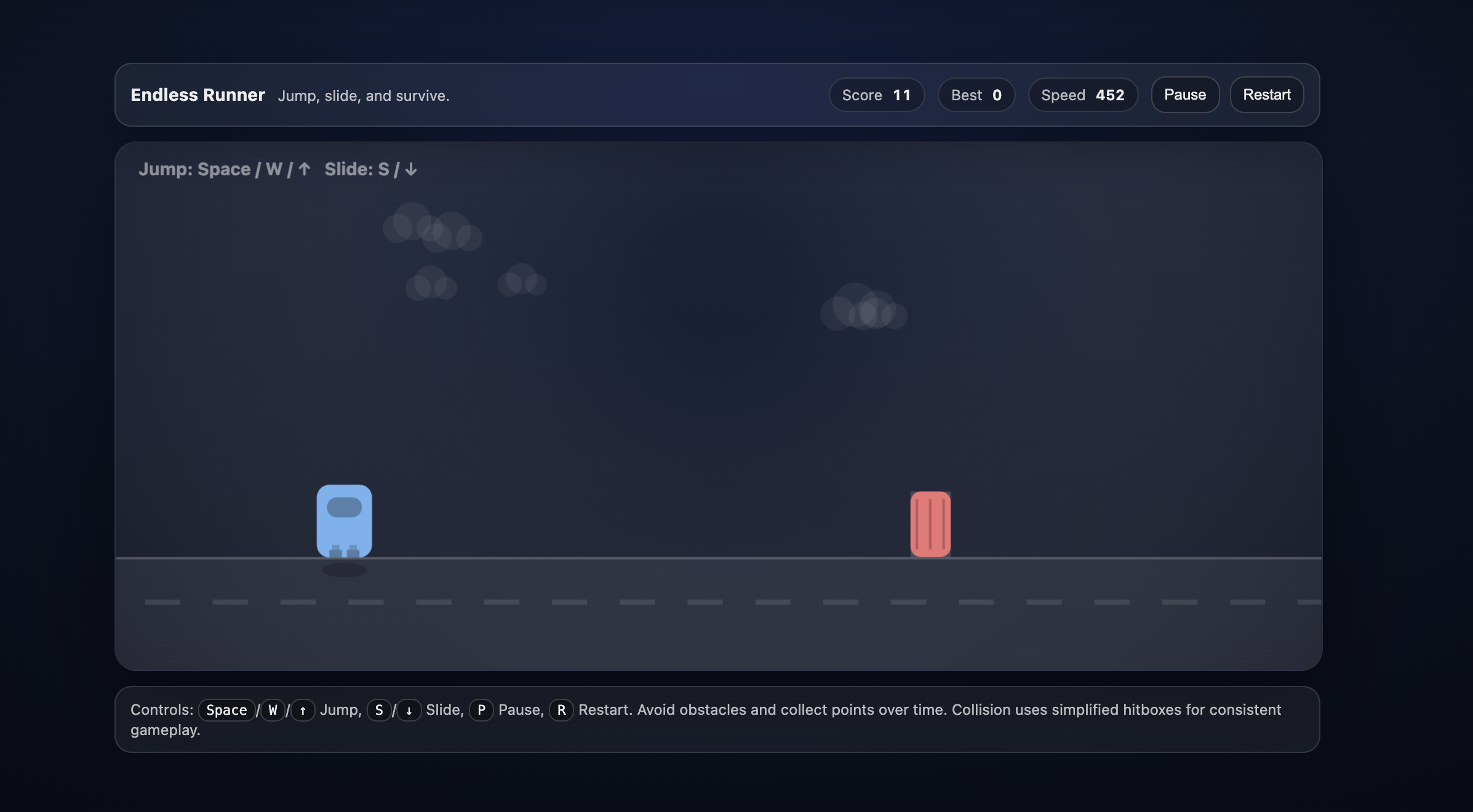
综合对比
| 模型 | 代码行数 | 可玩性 | 完成度 | 美观度 | 定位 |
|---|---|---|---|---|---|
| ChatGPT | ~800 | ✅ | ⭐⭐⭐⭐ | ⭐⭐⭐ | 标准可玩 Demo |
| Claude | ~750–800 | ✅ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐☆ | 工程完成型 Demo |
| Gemini 3 | ~300 | ✅ | ⭐⭐ | ⭐ | 最小可行原型 |
一句话总结:
Claude 在“做一个完整游戏”,ChatGPT 在“做一个规范实现”,Gemini 在“证明这事能跑”。
案例三:3D 光轮竞技场(Light-Cycle Arena)
Prompt:
Build a playable 3D light-cycle arena game in the browser.
Use Canvas/WebGL or Three.js.
Include movement, collision, scoring.
Provide full runnable project.
图 1:Gemini(217 行)
图 2:Claude(1117 行,系统最完整)
图 3:ChatGPT(约 500 行,功能齐全)
综合对比
| 模型 | 代码行数 | 可玩性 | 系统完整度 | 视觉表现 | 定位 |
|---|---|---|---|---|---|
| Gemini 3 | ~217 | ✅ | ⭐ | ⭐⭐ | 概念验证 |
| ChatGPT | ~500 | ✅ | ⭐⭐⭐⭐ | ⭐⭐⭐ | 标准完整实现 |
| Claude | ~1117 | ✅ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐☆ | 高完成度 3D Demo |
一句话总结:
Gemini 负责证明可能性,ChatGPT 负责把事做完,Claude 负责把作品交出去。
一个非常关键的提醒:Prompt 决定了一半结果
🧠 这种「一次性工程交付」任务,Prompt 写法比你想象中重要得多。
强烈建议固定加上这两条:
- No pseudo code / no placeholders
- After code, provide run steps + self-check list
你会明显发现:
⚡ 同一个模型,能不能跑起来,差距会非常大。
新手怎么直接上手?三步搞定(国内可用)
很多人不是模型不行,而是卡在第一步:
❌ 官方站在国内访问不稳定,体验断断续续,根本没法安心写代码、跑 Demo。
如果你想在国内稳定使用并对比这三大模型,最省事的方式就是直接走我们整理好的入口。
📎 建议收藏的入口
- 总导航(最省心):https://www.zhangsan.cool
- ChatGPT:https://share.zhangsan.cool/
- Claude:https://claude.zhangsan.shop/list
- Gemini:https://share.geminimirror.cn/
第一步:按目标选模型,不纠结
- 🎨 做演示、要完整、要好看 → Claude
- 🧩 要稳定实现、方便继续改 → ChatGPT
- ⚡ 快速验证想法、先跑起来 → Gemini
第二步:直接用通用工程 Prompt
复制这段模板,换掉任务描述即可:
Generate a complete runnable project (HTML/CSS/JS).
Constraints:
1) No pseudo code. No placeholders.
2) Provide all code blocks with file names.
3) Must run by opening index.html in a browser.
4) Show controls/instructions on screen.
5) After code, provide a self-check list (run steps + common errors).
Task: <你的具体任务>
第三步:跑不起来?不要重写,用“补丁式修复”
新手最容易犯的错:
一报错就让模型全部重写。
正确做法是这样:
It doesn't run. Here is the error and console output: <paste>
Return a minimal patch only (which lines to change), do not rewrite everything.
⏱️ 效率会高很多。
如果你只是想争论“谁最强”,那永远没有答案。
真正有价值的是这件事:
今天你要做什么,用最合适的模型,把它一次性做出来。
如果你想在国内直接体验并对比这三大模型,建议从导航入口开始:
👉 https://www.zhangsan.cool
点开就能用,稳定、省事,切换也方便。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)