5 分钟上手 N8N:搭建你的第一个AI应用
n8n一个高人气的AI+流程自动化工具,轻松实现一个知识问答平台
n8n是一款开源且具备AI能力的工作流自动化平台。它凭借直观的拖拽式图形界面,为用户提供了零代码或低代码的业务流程开发体验。
目前,n8n 在全球开发者社区拥有极高的人气,GitHub Star 数已突破 16.6 万。作为对比,字节跳动旗下的热门工具 Coze (扣子)目前约为 1.93 万 Star(虽然 Star 数不代表产品能力的全部,但也足以印证 n8n 的火爆程度)。有的人甚至将其誉为 “2026 年最值得学习的 AI 自动化神器”。
n8n 凭什么这么火?拆解开来,其实就赢在两点:
首先,它精准化解了“AI 的随性”与“流程的严格”之间的矛盾。Coze 和 Dify 的目标是帮你捏一个 AI 智能体,但 n8n 的定位是**“万物皆可流”**。 现在大家发现,AI 虽好,但它偶尔会“一本正经地胡说八道”,这在追求零差错的企业流程里是大忌。n8n 聪明在它不强求全盘 AI 化——你需要严谨时,它就是高效的自动化工具;你需要智能时,它又能秒变 AI 开发平台。这种“可盐可甜”的特质,让它比纯 AI 平台更落地。
其次,是它“拿来即用”的恐怖生态。官方 500 多个节点几乎涵盖了你能想到的所有工具。虽然原生节点偏向国外应用,但国内的开发者们非常给力,自发贡献了大量适配,如:飞书、小红书等本土产品的插件。这种“全球资源 + 本土血脉”的结合,让 n8n 成了目前门槛最低、天花板最高的自动化神器。
下面就基于RAG方式创建一个企业知识问答系统,来快速上手n8n
n8n 主要有两种使用方式:一种是云托管(Cloud),注册后享受 14 天免费试用,14天后起步价约 24 欧元/月(约合人民币 180 元左右),这是最简便、适合快速上手验证的方式,试用期满还可通过更换邮箱继续体验;另一种是独立部署,需要自行准备运行环境和负责运维(普通笔记本即可运行),可以永久免费使用,只需遵循 [fair-code](https://faircode.io/) 开源协议,即支持免费商用,但禁止通过分发其核心能力来牟利。后续我将专门撰文讲解如何进行独立部署,感兴趣的朋友请保持关注!
第一步,准备api key,准备大模型和向量化的api key,已有则可以跳过这一步
创建一个私有知识问答平台(RAG),需要两个外部的AI能力:一,是向量(Embedding)的能力,负责将文字转化成向量,向量是AI能识别的语言,用户提的问题和知识相关的文档都需要转化成向量;二,是LLM性能力,对用户问题检索出来的答案进行总结形成答案。
向量化模型,常见的向量模型text-embedding-v4、bge、acge_text_embedding。为了方便,本案例中选阿里的text-embedding-v4的api的方式使用,注册/登录阿里云>>百炼平台,账号充值充>>百炼平台>>右上角的费用>>充值汇款(可以先充5元,最少可以充0.01元),拷贝api key>>百炼平台>>左侧密钥管理中可以找到api key。向量模型也可以独立部署,普通电脑就可以,感兴趣的可以参看后续的N8N独立部署的文章,请关注。
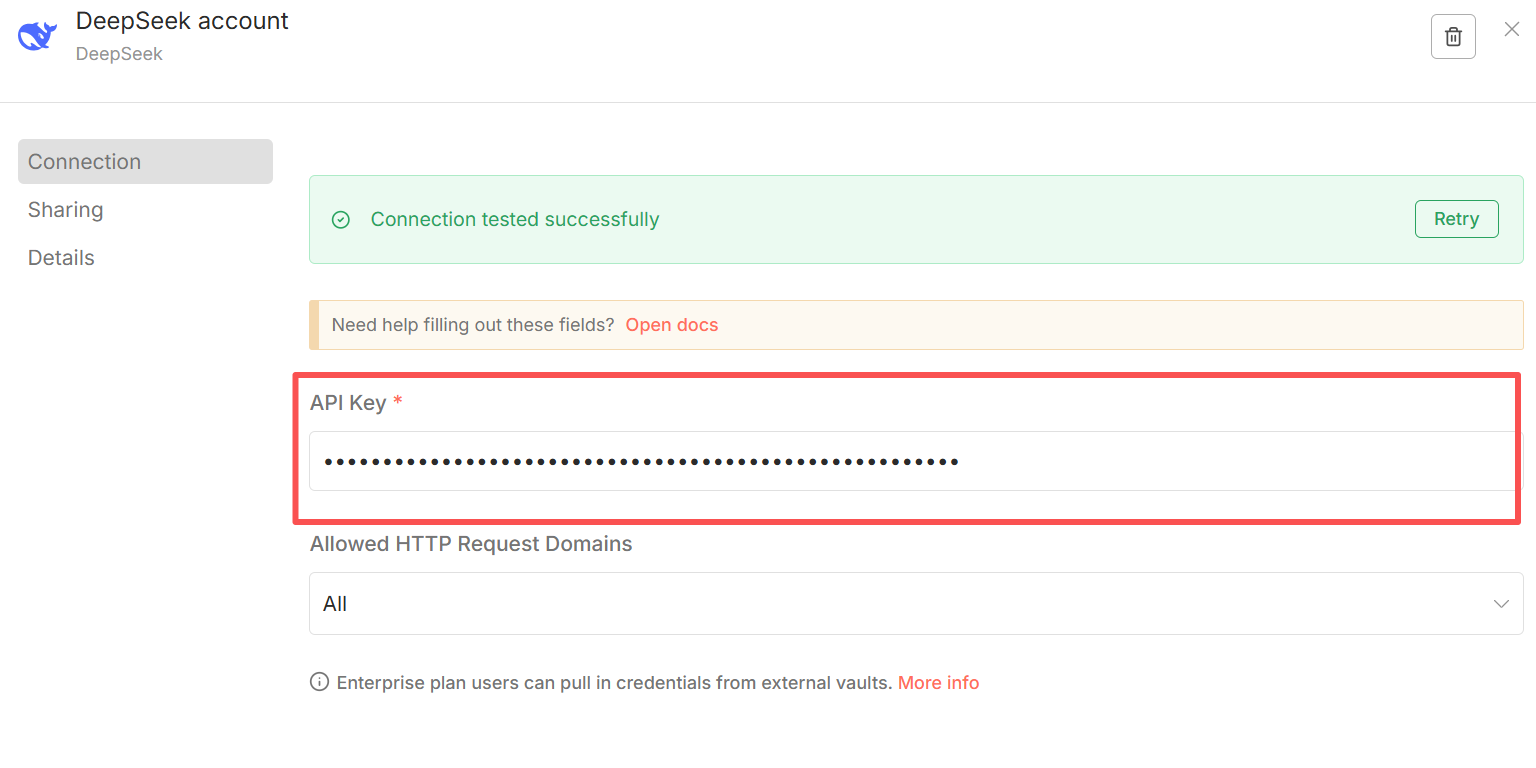
大语言模型,api key可以新选择使用阿里的qwen模型,上面申请的api key可以直接使用。但,这里边选择deep seek,因为n8n集成更好,并且比较便宜。登录deep seek官网>>选择API开放平台>>选择api keys>>创建API key(注意:创建时保存好!因为后续没有办法再查看这个key,只能新建),一样先充5元,做了20几次聊天的测验话费预估也就1元左右,这个和具体的token有关。
第二步,注册一个N8N账号,开启n8n之旅
登录网址:https://n8n.io/ ,注册账号需要邮箱认证,再简单填写几个问答问题就可以进入14天免费的使用期,界面如下:
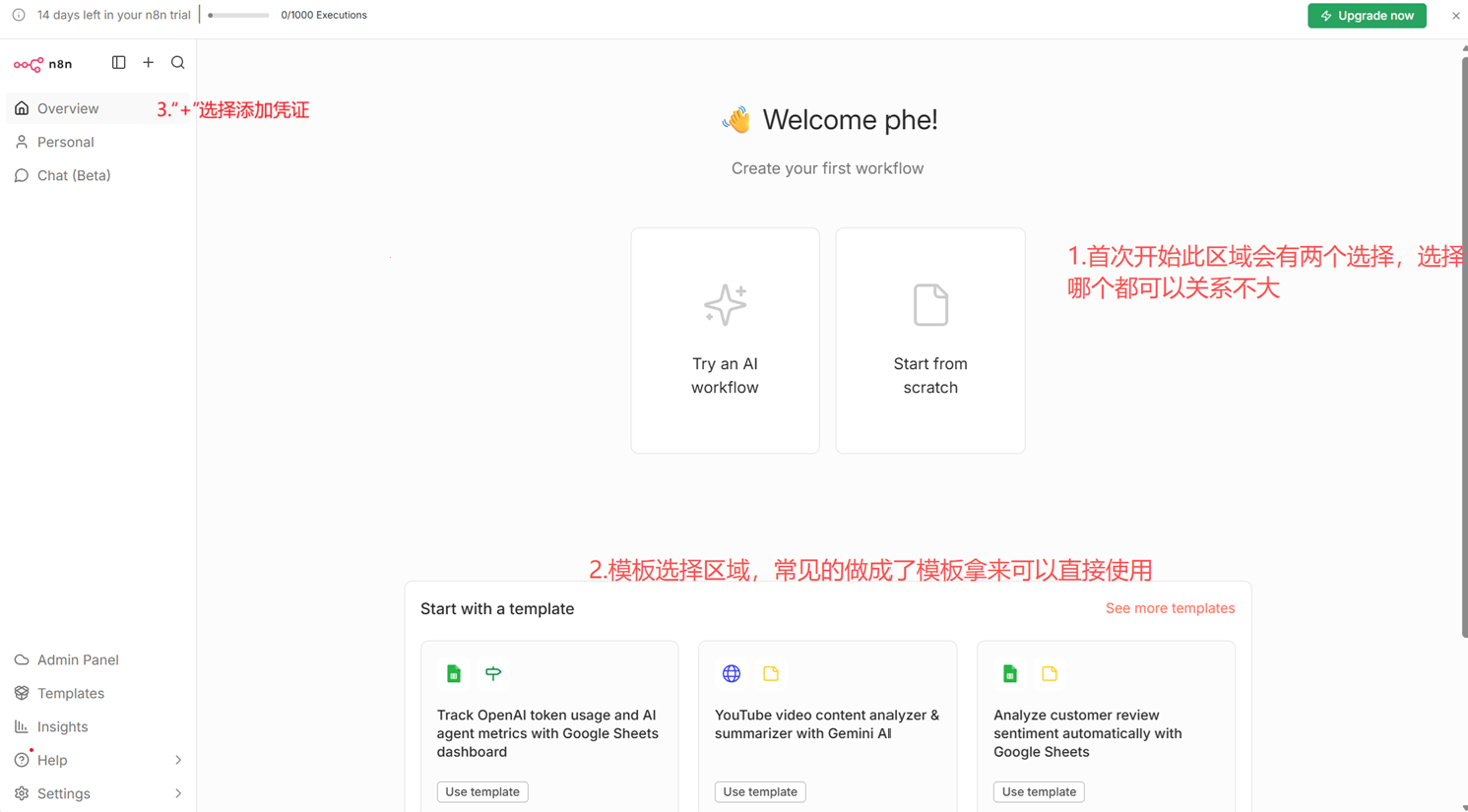
第三步,添加凭证(credential)
凭证是访问外部的应用和api的认证方式,我们需要将第一步准备的两个api key添加到n8n的凭证中。
左侧上部分“+”按钮>>Creadential>>personal(这里可以分为不同工程)>>进入下边的选择框
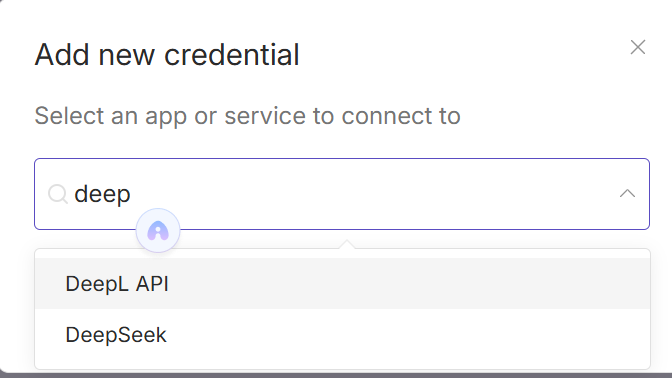
先添加deep-seek大模型的凭证,直接在上边弹出的对话框中选择deep seek,在下边的对话框中填上对应的api key即可
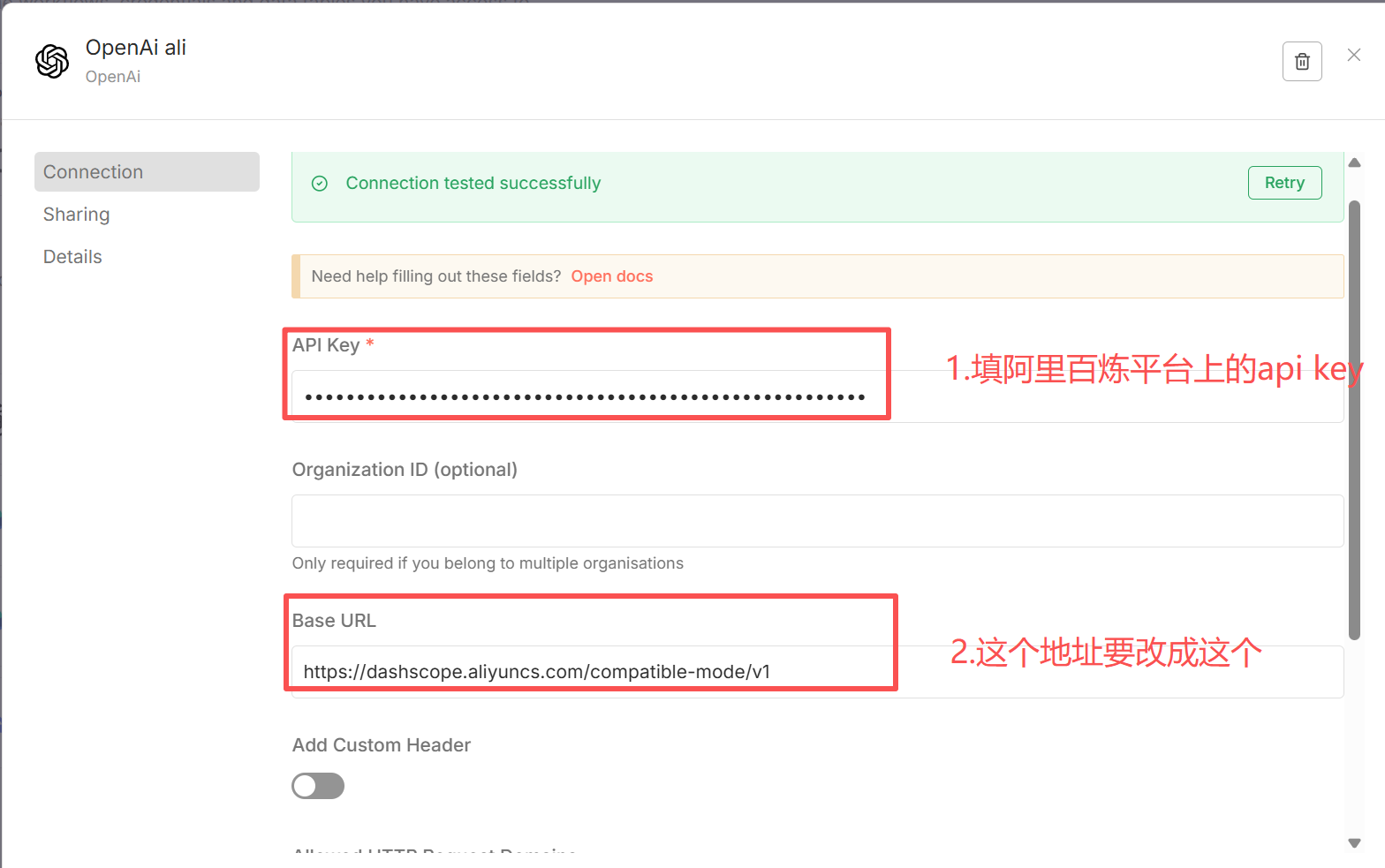
再添加阿里的text-embeding-v4的向量化认证,你会发现和deep seek不一样,在弹出对话框中没有办法选择阿里的产品,这是因为n8n官方默认没有集成阿里的产品,有两种解决:一种通过通用的header认证,不推荐;另一种将阿里的模型伪装成openAI(社区的统一做法),因为阿里的ai相关接口完全遵循openAi规范。在添加凭证的弹窗中选择OpenAi
Base URL:https://dashscope.aliyuncs.com/compatible-mode/v1 (阿里api文档中提供)
所有的准备工作都做好了,回到主界面创建一个流程吧。
第四步,创建一支流程
左侧上部分“+”按钮>>work flow>>personal
如果首次创建流程且打开的overview页面,则会看到是第二步中的界面,有两个选择,如果选择“Try an AI workflow”就自动创建一个默认的AI工作流,这里为能更的理解n8n中节点和流程的概念,我们选择“start from scratch”模式,从零开始创建一个RAG。
选择后进入下边的流程编辑页面
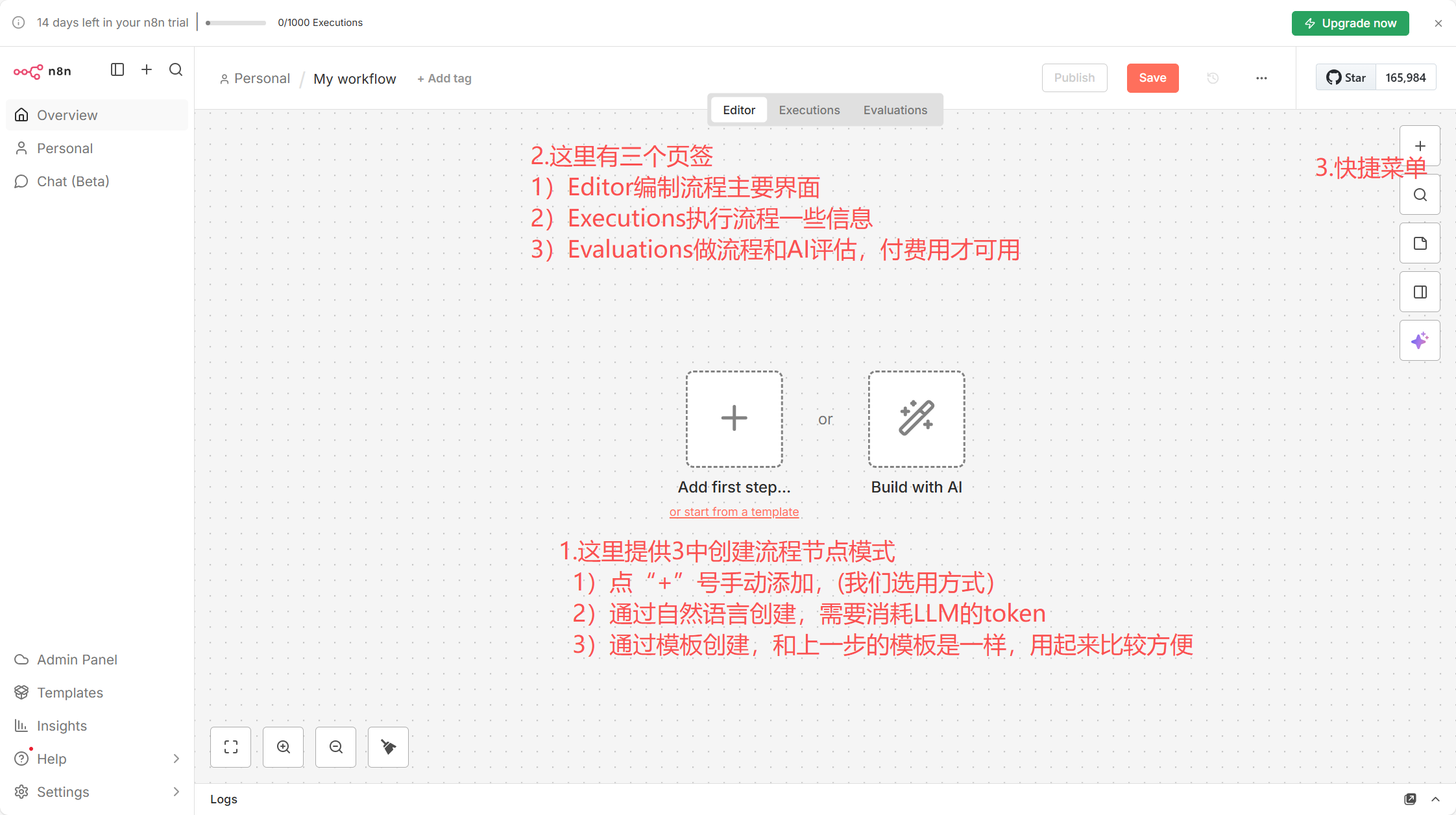
在上图选择中间“+”号和右上方的“+”,就可以不断向中心区域添加流程节点。下图就是创建的好的一个知识文档的流程(RAG),所有这些节点都是通过**右侧**的“+”号添加进来的,而连线是通过在两个节点间进行拖拉或者点击一个节点后边跟着的加号就可以选择一个节点(文章最后附有配置流程可以直接导入你的n8n中)。
先看图整体感受一下,下边文字会详细说明每个节点及其属性设置,比较简单。
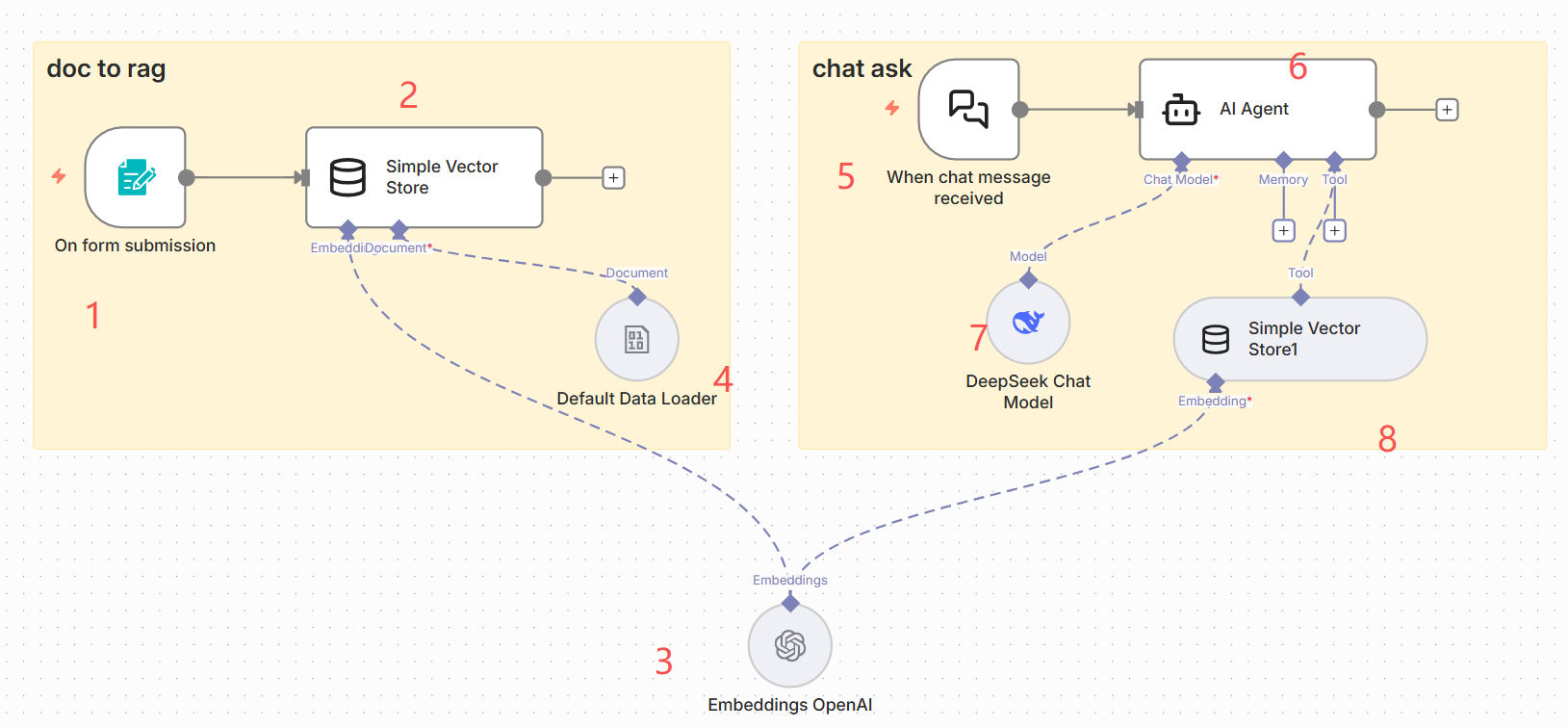
上图左边是将一个将文档转化为向量存起来的过程,右边是一个通过对话模式查询向量化后的文档并回答问题的过程。
- 节点1:表单触发节点(Form Trigger node)
在n8n中触发节点代表着一个流程开始的触发事件,我们的流程中有两个触发节点即节点1和节点2,因为一个知识文档过程就是2个过程把文档向量化存起来,一个相应用户问答过程。对于节点1我们选择的是一个表单的节点,这是为了演示方便,当然你也可以选择一个调度节点周期的将某些文档进行向量化。
因为要上传文件因此在节点1的form elements中element type 要选择File,field name 可以自定义这里为了方便就也写成file。
- 节点2:简单向量库节点(simple vector store)
这是n8n内嵌的一个简单的向量库,主要就是用来存放你向量化的文档,并对文档进行检索,你也可以选择任意一个你有的向量库。
添加节点>>搜索simple vector store>>add documents to vector 代表将文档进行向量存储
节点属性中memory key 名称和节点8保持一致就行,embedding batch size 代表文档切分块的大小,在高精度RAG这个切分块大小对召回率比较重要,这里按默认即可
- 节点3:向量化模型节点(Embeddings OpenAi)
第一步准备中的两个api key一个就是用到这里,这里之所以是Embedding OpenAI,是因为我们将阿里的凭证伪装成openAi,其实使用的是阿里的text-embedding-v4。
在节点属性配置中,链接凭证选择刚才添加的阿里凭证,模型的选择上需要额外注意的是下拉列表中并不能选择到text-embedding-v4,这个是阿里api的兼容问题,我们将选择框上边fixed切换成expression就可以手动填了,我们手动将名称“text-embedding-v4”填进去就可以(没有引号)
- 节点4:数据加载节点(Default Data Loader)
节点1只是将数据上传到服务器上,并没有导入到向量库中,数据加载节点就是将文档先切后装入到向量库中。
节点属性的选择Type of Data 一定要选择Binary,因为读入的文档是二进制的形式。
再将上边节点1-4的连线上,一个文档转化为向量并存储起来的流程就配置完了。
- 节点5:聊天触发节点(chat trigger)
同节点1一样是一个触发节点,这个节点主要用于接收用户的一些请求消息。
- 节点6:AI agent节点(Ai agent)
通过此节点可以轻松配置一个智能体,在这个例子中节点属性只需要配置prompt(user message) 为“{{ $json.chatInput }}”,表示从聊天窗口获得用户输入数据方式,“{{$json}}”是n8n节点获取数据一种方式。
options属性中可以添加一些额外的消息,在这个例子中不用填写,主要是调优和设置智能体的一些属性,包括给智能体增加一些系统prompt(如:你给模型定义角色,让模型不要任意发挥等),控制智能体在react模式下反复迭代次数,这些高级功能先不管。
- 节点7:大模型节点(deep seek chatmodel)
n8n集成deep seek所以这里直接选择deep seek的节点就行,如果是阿里Qwen模型要用上边添加凭证时伪装成的openAi的模式。
在连接凭证(Credential to connect with)选择第一步准备阶段添加的deep seek凭证。模型选择deep seek chat 这个对应着deep seek v3 的通用大模型,做RAG用这个就够了。而deep seek reasoner是推理模型对应是deep seek的R1。
- 节点8:向量文档检索节点(simple vector store)
添加节点>>搜索simple vector store>>retrieve documents for ai agent as tool 代表检索文档向量并提供ai agent使用
第五步,验证流程,经过上边简单几步一个问答的RAG流程就配置好,下边就使用一下流程
运行流程,点击编辑区域中下部分的“Execute workflow”的橙色按钮,流程就启动起来了。
上传文档,打开节点1的属性中,可以看到一个url,这个是表单提交节点生成的上传文档的url,将这个url拷贝到浏览器地址中就能打开表单上传文档了,这里需要注意如果你采用docker 本地部署的话这个端口需要改成你的容器对外接口。选择一个内部的在网上找不到的文档验证,确实是根据文档内容回答的。
提问问题,在界面左下角的聊天窗口,输入你想问的问题,流程就能给出结果,这样一个可以作为智能问答的RAG助手就全部完成了,是不是非常简单。
附录:
1.文中的流程,可以直接导入到你的n8n中
n8n/rag.json at main · javaphe/n8n
2.后续还有两篇博客,一篇分享独立部署N8N和向量模型,一篇分享另外两个例子和一些高级功能,请关注

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 38
38 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)