探究TOON的价值边界:比JSON更优的大模型友好数据格式?
TOON 并不是一个噱头,也不是 JSON 的替代品。它更像是一种为大模型输入定制的结构受限的数据表达 DSL。在特定场景下,使用 TOON 可能有奇效,它应该被视为一个工具选项,理解它的边界比盲目使用它或者拒绝它更重要。
目录
探究TOON的价值边界:比JSON更优的大模型友好数据格式?
作者:watermelo37
CSDN优质创作者、华为云云享专家、阿里云专家博主、腾讯云“创作之星”特邀作者、火山KOL、支付宝合作作者,全平台博客昵称watermelo37。
一个假装是giser的coder,做不只专注于业务逻辑的前端工程师,Java、Docker、Python、LLM均有涉猎。
---------------------------------------------------------------------
温柔地对待温柔的人,包容的三观就是最大的温柔。
---------------------------------------------------------------------

探究TOON的价值边界:比JSON更优的大模型友好数据格式?
最近 AI 圈子里出现了一个新概念:TOON。
官方对它的描述是这样的:一种简洁、易读的 JSON 数据模型编码,最大限度地减少令牌数量,使模型易于理解结构。它旨在作为现有 JSON 的可随插、无损表示,用于 LLM 输入 。它结合了 YAML 基于缩进的嵌套对象结构与 CSV 风格的表格布局,用于统一数组。TOON 的优势在于对象数组统一(每行多个字段,项目结构相同),实现类似 CSV 的紧凑性,同时增加了显式结构,帮助大型语言模型可靠解析和验证数据。
截至目前,TOON 在github上已经揽下21.5k+ star。一种比JSON更优秀的大模型友好数据格式真的诞生了?
在上一篇博文TOON:一种为大模型设计的JSON压缩型数据结构中,我们已经对 TOON 的结构和设计目标有了一个相对准确的认识。但任何一种数据格式的价值,都不取决于“它能做什么”,而取决于它在什么情况下值得被使用。这一篇将聚焦一个更现实的问题:TOON 的收益边界到底在哪里?

一、TOON 的适用边界
1、哪些情况不适用 TOON?
TOON 的优势建立在一个非常强的前提之上:同构性。官方在何时不该使用 TOON 上是这样描述的(表格结构指同构对象数组,即数组中每个对象的键名都一样,可以用表格表示):
- 深度嵌套或非统一结构:几乎没有表格结构的 JSON 数据,使用 TOON 没有明显的提升。建议使用 JSON -compact(即去除了所有不必要空白字符的 JSON 格式)
- 半均匀数组:只有不超过总数据量50%的表格数据,虽然 TOON 有提升,但如果已经依赖 JSON,建议继续使用 JSON。
- 纯表格数据:纯表格类型数据,使用 CSV 效果更佳。
- 延迟敏感应用:如果对端到端响应时间及其敏感,对 token 数量较不敏感,应该先进行基准测试再考虑是否使用 TOON,大模型处理紧凑 JSON 的速度可能更快。
2、通过数据对比直观感受 JSON 与 TOON 的差异

①官方数据
官方给出了这样的一组效率排名(每1000个代币的准确率):

该排名不包括 CSV,因为它只支持 209 题中的 109 题(仅为扁平表格数据)。虽然 CSV 对于简单的表格数据非常高效,但它无法表示其他格式处理的嵌套结构。
此外,还有一组各模型检索精度的排名,官方将以下数据作为大模型检索的依据:
- 表格(100 条员工记录):统一的对象,字段相同——最适合 TOON 的表格格式。
- 嵌套 (50 个电商订单):复杂的结构,包含嵌套的客户对象和商品数组。
- 分析 (60 天指标):带有日期和数值的时间序列数据。
- GitHub(100 个仓库):按星数排名的顶级 GitHub 仓库的真实世界数据。
- 事件日志 (75 个日志):半均匀数据,~50%为平坦日志,~50%为嵌套错误对象。
- 嵌套配置 (1 个配置):深度嵌套配置,表格资格极少。
生成了五类一共209个问题:
- 字段检索(33%):直接查找值或可直接从记录读取的值(包括布尔值和简单计数如数组长度)
- 聚合(30%):数据集层级总和平均值加上单一条件过滤器(计数、求和、最小/最大比较)
- 过滤(23%):需要复合逻辑(跨字段的 AND 约束)的多条件查询
- 结构意识(12%):测试格式原生结构可感知性(TOON 的[N] 计数和 {fields},CSV 的头行)
- 结构验证(2%):测试使用结构元数据检测不完整、截断或损坏数据的能力
最后得到的测试结果是这样的:

但就小瓜的经历而言,大模型的计数能力普遍较弱,TOON 在第一行就写明了一共有多少条数据条目,12%的结构意识题目确实不是给 TOON 开后门?但是 CSV 表现又不太好,由于没有完全公开数据集和测试集,对于这部分官方测评小瓜仍持保守态度。
②基于案例数据的 token 差异探索
官方提供的效率、检索准确度排名相对缥缈,但是 token 差异是我们确实能看得见摸得着的,我们利用 OpenAI 提供的 tokenizer 工具来统计一下 token 差异。
网址:https://platform.openai.com/tokenizer
测试数据:
// JSON
{
"context": {
"task": "Our favorite hikes together",
"location": "Boulder",
"season": "spring_2025"
},
"friends": ["ana", "luis", "sam"],
"hikes": [
{
"id": 1,
"name": "Blue Lake Trail",
"distanceKm": 7.5,
"elevationGain": 320,
"companion": "ana",
"wasSunny": true
},
{
"id": 2,
"name": "Ridge Overlook",
"distanceKm": 9.2,
"elevationGain": 540,
"companion": "luis",
"wasSunny": false
},
{
"id": 3,
"name": "Wildflower Loop",
"distanceKm": 5.1,
"elevationGain": 180,
"companion": "sam",
"wasSunny": true
}
]
}
// TOON
context:
task: Our favorite hikes together
location: Boulder
season: spring_2025
friends[3]: ana,luis,sam
hikes[3]{id,name,distanceKm,elevationGain,companion,wasSunny}:
1,Blue Lake Trail,7.5,320,ana,true
2,Ridge Overlook,9.2,540,luis,false
3,Wildflower Loop,5.1,180,sam,true其中 JSON 数据的 token 计数为 223:
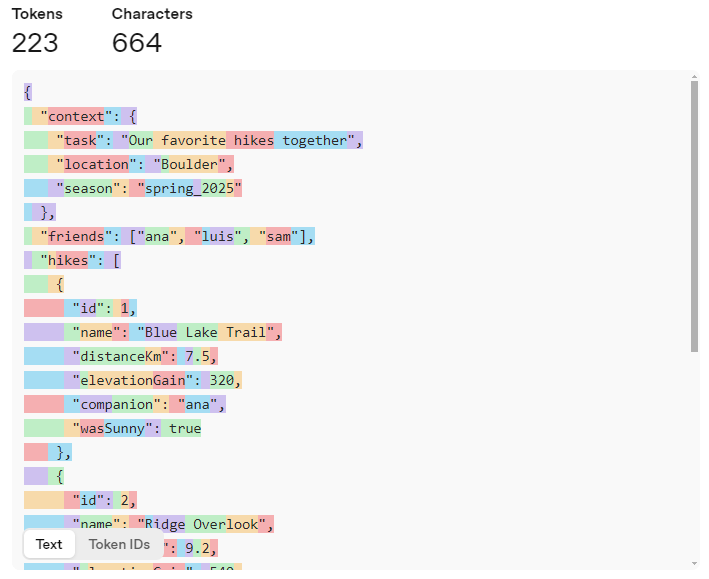
TOON 数据的 token 计数为 104:

基于这个对比,我们可以发现 JSON 中有大量的大括号、重复的键名消耗了额外的 token,但是在空格、换行上,TOON 比起 JSON 不一定能带来实际的提升。此外,关于 characters / tokens的比值,JSON 数据是 2.98,TOON 数据则是 2.75 。即优化 n% 的字符,也没办法减少 n% 的 token 消耗,说明 TOON 数据中每个 token 包含的字符数更少。
但总体说来,TOON 在表格结构中确实能大幅减少 JSON 数据中的冗余内容,一定程度上减少 token 的浪费。
二、TOON 真的是更好的大模型友好数据格式吗?
根据上述的介绍和探索,结合小瓜自己的理解来看。这里需要非常克制地给出结论,从设计目标看,TOON 确实减少了结构重复,明确了语义边界,有助于模型做模式识别,在适用情况下,确实节省了不少的 token ,但这并不意味着模型“天生更懂 TOON”,TOON 数据格式在效率和准确度上的提升仍需要更多的积淀和发展。
TOON 在数据格式变更上做出了一次尝试,这个角度并不是唯一解法。事实上,在很多真实场景中,减少输入数据本身,比更换数据格式收益更大。TOON 优化后 characters / tokens 的比值变小了也能佐证这一点。
三、结语
TOON github仓库:https://github.com/toon-format/toon
TOON 并不是一个噱头,也不是 JSON 的替代品。它更像是一种为大模型输入定制的结构受限的数据表达 DSL。在特定场景下,使用 TOON 可能有奇效,它应该被视为一个工具选项,理解它的边界比盲目使用它或者拒绝它更重要。
只有锻炼思维才能可持续地解决问题,只有思维才是真正值得学习和分享的核心要素。如果这篇博客能给您带来一点帮助,麻烦您点个赞支持一下,还可以收藏起来以备不时之需,有疑问和错误欢迎在评论区指出~
其他热门文章,请关注:
极致的灵活度满足工程美学:用Vue Flow绘制一个完美流程图
你真的会使用Vue3的onMounted钩子函数吗?Vue3中onMounted的用法详解
测评:这B班上的值不值?在不同城市过上同等生活水平到底需要多少钱?
通过array.filter()实现数组的数据筛选、数据清洗和链式调用
TreeSize:免费的磁盘清理与管理神器,解决C盘爆满的燃眉之急
通过Array.sort() 实现多字段排序、排序稳定性、随机排序洗牌算法、优化排序性能
高效工作流:用Mermaid绘制你的专属流程图;如何在Vue3中导入mermaid绘制流程图
通过MongoDB Atlas 实现语义搜索与 RAG——迈向AI的搜索机制
前端实战:基于Vue3与免费满血版DeepSeek实现无限滚动+懒加载+瀑布流模块及优化策略
深入理解 JavaScript 中的 Array.find() 方法:原理、性能优势与实用案例详解
el-table实现动态数据的实时排序,一篇文章讲清楚elementui的表格排序功能
JavaScript双问号操作符(??)详解,解决使用 || 时因类型转换带来的问题
内存泄漏——海量数据背后隐藏的项目生产环境崩溃风险!如何避免内存泄漏

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 27
27 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)