AI原生应用领域思维树:赋能企业发展
在当今数字化时代,人工智能技术发展迅猛,AI原生应用正逐渐成为推动企业创新和发展的关键力量。本文的目的是深入剖析AI原生应用领域思维树这一概念,探讨其如何为企业发展赋能。范围涵盖了AI原生应用的核心概念、相关算法原理、实际应用场景、开发实践以及未来发展趋势等方面。本文将首先介绍相关的术语和核心概念,通过有趣的故事引入主题,详细解释AI原生应用、思维树等核心概念及其相互关系,并给出原理示意图和流程图
AI原生应用领域思维树:赋能企业发展
关键词:AI原生应用、思维树、企业发展、赋能、应用领域
摘要:本文围绕AI原生应用领域思维树展开,深入探讨其如何赋能企业发展。首先介绍了相关背景知识,接着解释了AI原生应用、思维树等核心概念以及它们之间的关系,阐述了核心算法原理与具体操作步骤,分析了相关数学模型和公式。通过项目实战案例,详细展示了如何在实际中运用。还探讨了AI原生应用在不同场景的实际应用,推荐了相关工具和资源,最后对未来发展趋势与挑战进行了展望。帮助读者全面了解AI原生应用领域思维树,以及其对企业发展的重要作用。
背景介绍
目的和范围
在当今数字化时代,人工智能技术发展迅猛,AI原生应用正逐渐成为推动企业创新和发展的关键力量。本文的目的是深入剖析AI原生应用领域思维树这一概念,探讨其如何为企业发展赋能。范围涵盖了AI原生应用的核心概念、相关算法原理、实际应用场景、开发实践以及未来发展趋势等方面。
预期读者
本文适合对人工智能、企业数字化转型感兴趣的人士,包括企业管理者、技术开发者、创业者以及对新兴技术有探索欲望的爱好者。
文档结构概述
本文将首先介绍相关的术语和核心概念,通过有趣的故事引入主题,详细解释AI原生应用、思维树等核心概念及其相互关系,并给出原理示意图和流程图。接着阐述核心算法原理和具体操作步骤,分析数学模型和公式。然后通过项目实战案例,展示代码实现和详细解读。之后探讨实际应用场景,推荐相关工具和资源。最后对未来发展趋势与挑战进行分析,总结全文并提出思考题。
术语表
核心术语定义
- AI原生应用:指从设计之初就以人工智能技术为核心驱动力,充分利用人工智能的各种能力(如机器学习、深度学习、自然语言处理等)来构建和实现的应用程序。
- 思维树:一种结构化的思考方式,将复杂的问题或概念分解为多个层次和分支,形成类似树状的结构,帮助人们更清晰地理解和分析问题。
相关概念解释
- 机器学习:是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。它专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
- 深度学习:是机器学习的一个分支领域,它是一种基于对数据进行表征学习的方法。深度学习通过构建具有很多层的神经网络模型,自动从大量数据中学习复杂的模式和特征。
缩略词列表
- AI:Artificial Intelligence,人工智能
- ML:Machine Learning,机器学习
- DL:Deep Learning,深度学习
核心概念与联系
故事引入
从前,有一个小镇,小镇上的居民们经营着各种各样的生意。有一家杂货店,老板一直为货物的管理和销售发愁。传统的管理方式让他很难准确地知道哪些货物畅销,哪些货物容易积压。后来,一位聪明的年轻人带来了一种神奇的工具。这个工具就像一个超级大脑,它可以分析顾客的购买记录、市场的趋势等各种信息。有了这个工具,老板就像有了一个得力的助手,他能够提前预测哪些货物会受欢迎,合理安排进货量,还能根据不同顾客的喜好推荐商品。这个神奇的工具就是AI原生应用,而帮助老板理清各种信息和决策的思考方式就像是思维树。
核心概念解释(像给小学生讲故事一样)
- 核心概念一:AI原生应用
AI原生应用就像一个超级智能小助手。想象一下,你有一个小伙伴,他超级聪明,能记住很多很多的事情,还能快速地分析各种情况。比如,你让他帮你整理书架,他会先看看你有哪些书,按照不同的类别,像故事书、科普书、漫画书等,把它们分类放好。AI原生应用也是这样,它从一开始设计的时候,就利用人工智能的本领,能处理和分析大量的数据,帮我们解决各种复杂的问题,就像那个帮你整理书架的小伙伴一样。 - 核心概念二:思维树
思维树就像一棵大树。大树有一个树干,然后从树干上长出很多树枝,每个树枝又会分出更小的树枝。假如你要计划一次旅行,树干就是这次旅行这个大目标。从树干上长出的树枝可能是目的地的选择、出行的方式、住宿的安排等。每个树枝再细分,比如目的地选择这个树枝,又可以分出不同的城市作为小树枝。这样一步一步地把一个大问题分解成很多小问题,就像大树的结构一样,这就是思维树。 - 核心概念三:企业发展
企业发展就像一棵小树苗慢慢长成大树的过程。小树苗需要阳光、水分和养分才能长大,企业也需要各种资源和条件才能发展壮大。比如,企业需要有好的产品,就像小树苗需要有健康的树干和树叶;需要有优秀的员工,就像小树苗需要有强壮的根系;还需要有合适的市场和客户,就像小树苗需要有合适的生长环境。
核心概念之间的关系(用小学生能理解的比喻)
- 概念一和概念二的关系:AI原生应用和思维树的关系
AI原生应用和思维树就像一对好朋友,一起合作完成任务。思维树就像一张地图,它把一个大问题分成很多小问题,告诉AI原生应用从哪里开始工作。而AI原生应用就像一个小探险家,它按照思维树画的地图,一个一个地去探索和解决小问题。比如,在上面提到的杂货店例子中,思维树把货物管理和销售这个大问题分成了货物分类、销售预测、顾客推荐等小问题,AI原生应用就根据这些小问题去分析数据,找到解决办法。 - 概念二和概念三的关系:思维树和企业发展的关系
思维树就像企业发展的指南针。企业在发展的过程中会遇到很多问题,就像在茫茫大海中航行的船只。思维树可以帮助企业把大的发展目标分解成很多小目标,就像在大海中确定了一个个的小岛屿作为航行的目标。这样企业就知道一步一步该怎么做,朝着这些小目标前进,最终实现大的发展目标。 - 概念一和概念三的关系:AI原生应用和企业发展的关系
AI原生应用就像企业发展的加速器。企业就像一辆汽车,AI原生应用就像给汽车加了一个超级发动机。它可以帮助企业更好地了解市场和客户,优化产品和服务,提高运营效率。比如,通过AI原生应用分析客户的需求,企业可以开发出更符合客户心意的产品,从而吸引更多的客户,让企业发展得更快。
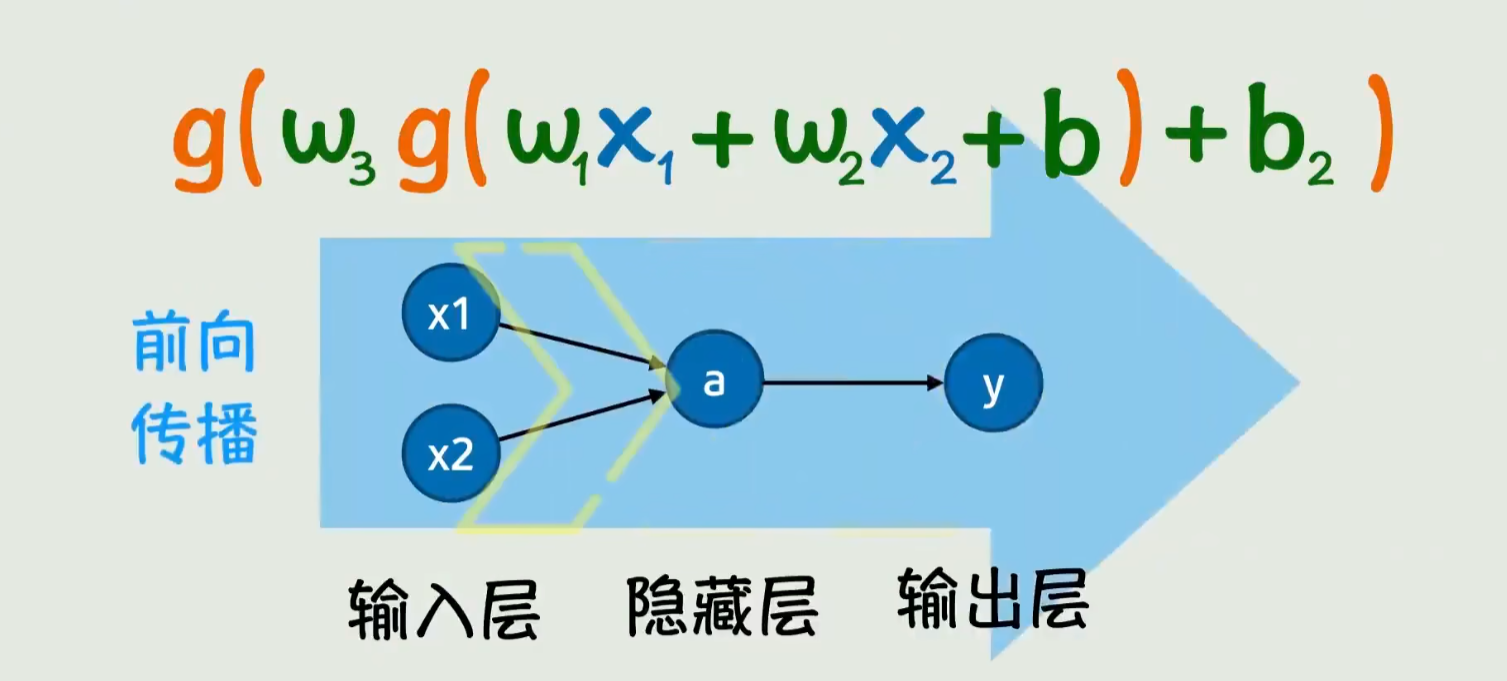
核心概念原理和架构的文本示意图
AI原生应用以人工智能技术为核心,通过对大量数据的收集、处理和分析,利用机器学习和深度学习等算法模型,实现各种智能功能。思维树则是将复杂的问题或目标进行层次化和结构化分解,形成多个子问题和子目标。在企业发展中,AI原生应用利用思维树的结构,针对不同层次和分支的问题进行分析和处理,为企业提供决策支持和解决方案。
Mermaid 流程图
核心算法原理 & 具体操作步骤
核心算法原理
在AI原生应用中,常用的算法包括机器学习算法和深度学习算法。以决策树算法为例,它是一种基于树结构进行决策的算法。决策树算法的基本思想是根据数据的特征属性,将数据集不断地进行划分,直到每个划分中的数据属于同一类别或者满足一定的条件。
具体操作步骤
以下是使用Python和Scikit-learn库实现简单决策树分类的代码示例:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建决策树分类器
clf = DecisionTreeClassifier()
# 训练模型
clf.fit(X_train, y_train)
# 预测
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
在上述代码中,首先加载了鸢尾花数据集,然后将数据集划分为训练集和测试集。接着创建了一个决策树分类器,并使用训练集对模型进行训练。最后使用测试集进行预测,并计算预测的准确率。
数学模型和公式 & 详细讲解 & 举例说明
决策树算法的数学模型和公式
决策树算法中常用的一个指标是信息增益,信息增益用于衡量特征对分类的重要性。信息增益的计算公式为:
IG(S,A)=H(S)−∑v∈Values(A)∣Sv∣∣S∣H(Sv)IG(S,A)=H(S)-\sum_{v\in Values(A)}\frac{|S_v|}{|S|}H(S_v)IG(S,A)=H(S)−v∈Values(A)∑∣S∣∣Sv∣H(Sv)
其中,IG(S,A)IG(S,A)IG(S,A) 表示特征 AAA 相对于数据集 SSS 的信息增益,H(S)H(S)H(S) 表示数据集 SSS 的信息熵,Values(A)Values(A)Values(A) 表示特征 AAA 的所有可能取值,SvS_vSv 表示特征 AAA 取值为 vvv 时的子集。
信息熵的计算公式为:
H(S)=−∑i=1npilog2piH(S)=-\sum_{i=1}^{n}p_i\log_2p_iH(S)=−i=1∑npilog2pi
其中,pip_ipi 表示数据集 SSS 中第 iii 类样本的比例。
详细讲解
信息熵表示数据集的混乱程度,信息熵越大,数据集越混乱。信息增益表示使用某个特征进行划分后,数据集的混乱程度降低的程度。决策树算法在选择划分特征时,会选择信息增益最大的特征进行划分。
举例说明
假设有一个数据集 SSS,包含 10 个样本,其中 6 个样本属于类别 1,4 个样本属于类别 2。则数据集 SSS 的信息熵为:
H(S)=−610log2610−410log2410≈0.971H(S)=-\frac{6}{10}\log_2\frac{6}{10}-\frac{4}{10}\log_2\frac{4}{10}\approx 0.971H(S)=−106log2106−104log2104≈0.971
假设现在有一个特征 AAA,它有两个取值 A1A_1A1 和 A2A_2A2。在特征 AAA 取值为 A1A_1A1 的子集中,有 4 个样本,其中 3 个属于类别 1,1 个属于类别 2;在特征 AAA 取值为 A2A_2A2 的子集中,有 6 个样本,其中 3 个属于类别 1,3 个属于类别 2。则特征 AAA 相对于数据集 SSS 的信息增益为:
IG(S,A)=H(S)−(410H(SA1)+610H(SA2))IG(S,A)=H(S)-\left(\frac{4}{10}H(S_{A_1})+\frac{6}{10}H(S_{A_2})\right)IG(S,A)=H(S)−(104H(SA1)+106H(SA2))
其中,H(SA1)=−34log234−14log214≈0.811H(S_{A_1})=-\frac{3}{4}\log_2\frac{3}{4}-\frac{1}{4}\log_2\frac{1}{4}\approx 0.811H(SA1)=−43log243−41log241≈0.811,H(SA2)=−36log236−36log236=1H(S_{A_2})=-\frac{3}{6}\log_2\frac{3}{6}-\frac{3}{6}\log_2\frac{3}{6}=1H(SA2)=−63log263−63log263=1。
IG(S,A)=0.971−(410×0.811+610×1)≈0.134IG(S,A)=0.971-\left(\frac{4}{10}\times 0.811+\frac{6}{10}\times 1\right)\approx 0.134IG(S,A)=0.971−(104×0.811+106×1)≈0.134
项目实战:代码实际案例和详细解释说明
开发环境搭建
- 安装Python:从Python官方网站(https://www.python.org/downloads/)下载并安装Python 3.x版本。
- 安装必要的库:使用pip命令安装Scikit-learn、Pandas、Numpy等库。
pip install scikit-learn pandas numpy
源代码详细实现和代码解读
以下是一个使用AI原生应用进行客户分类的项目案例。假设我们有一个客户数据集,包含客户的年龄、性别、购买金额等信息,我们要根据这些信息将客户分为不同的类别。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 加载数据集
data = pd.read_csv('customer_data.csv')
# 提取特征和标签
X = data.drop('category', axis=1)
y = data['category']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建决策树分类器
clf = DecisionTreeClassifier()
# 训练模型
clf.fit(X_train, y_train)
# 预测
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
代码解读:
- 数据加载:使用Pandas库的
read_csv函数加载客户数据集。 - 特征和标签提取:将数据集中的
category列作为标签,其余列作为特征。 - 数据集划分:使用
train_test_split函数将数据集划分为训练集和测试集。 - 模型创建和训练:创建决策树分类器,并使用训练集对模型进行训练。
- 预测和评估:使用测试集进行预测,并计算预测的准确率。
代码解读与分析
通过上述代码,我们可以看到如何使用决策树算法对客户进行分类。决策树算法可以自动从数据中学习特征和标签之间的关系,从而实现分类任务。在实际应用中,我们可以根据不同的业务需求选择不同的算法和模型,以达到更好的效果。
实际应用场景
市场营销
在市场营销中,AI原生应用可以利用思维树的方式,将市场细分、客户定位、营销活动策划等问题进行分解。通过分析客户的行为数据、偏好数据等,AI原生应用可以实现精准营销。例如,根据客户的购买历史和浏览记录,为客户推荐个性化的产品和服务,提高营销效果和客户满意度。
供应链管理
在供应链管理中,思维树可以将采购、生产、物流等环节进行分解。AI原生应用可以对供应链中的数据进行实时监测和分析,预测需求变化,优化库存管理,提高供应链的效率和灵活性。例如,通过分析销售数据和市场趋势,提前预测产品的需求,合理安排生产和采购计划。
客户服务
在客户服务中,思维树可以将客户问题分类、问题解决流程等进行分解。AI原生应用可以利用自然语言处理技术,实现智能客服。例如,通过分析客户的问题描述,自动识别问题类型,并提供相应的解决方案,提高客户服务的效率和质量。
工具和资源推荐
开发工具
- Jupyter Notebook:一个交互式的开发环境,适合进行数据探索、模型训练和代码演示。
- PyCharm:一款专业的Python集成开发环境,提供了丰富的代码编辑、调试和项目管理功能。
数据集
- Kaggle:一个数据科学竞赛平台,提供了大量的公开数据集,涵盖了各种领域。
- UCI Machine Learning Repository:一个经典的机器学习数据集仓库,包含了许多常用的数据集。
学习资源
- Coursera:提供了许多关于人工智能和机器学习的在线课程,由世界各地的知名大学和机构授课。
- TensorFlow官方文档:TensorFlow是一个广泛使用的深度学习框架,其官方文档提供了详细的教程和示例代码。
未来发展趋势与挑战
未来发展趋势
- 融合更多技术:AI原生应用将与物联网、区块链等技术进行深度融合,创造出更多创新的应用场景。例如,在智能家居领域,AI原生应用可以与物联网设备相结合,实现更加智能化的家居控制和管理。
- 行业定制化:不同行业对AI原生应用的需求将越来越多样化,未来将会出现更多针对特定行业的AI原生应用解决方案。例如,在医疗行业,AI原生应用可以用于疾病诊断、药物研发等领域。
- 自动化和智能化:AI原生应用将越来越自动化和智能化,能够自动完成更多的任务和决策。例如,在金融行业,AI原生应用可以自动进行风险评估和投资决策。
挑战
- 数据隐私和安全:随着AI原生应用的广泛应用,数据的隐私和安全问题将变得越来越重要。企业需要采取有效的措施来保护客户的数据安全,防止数据泄露和滥用。
- 人才短缺:目前,人工智能领域的专业人才仍然相对短缺,企业需要加大对人才的培养和引进力度,以满足AI原生应用发展的需求。
- 算法可解释性:一些复杂的人工智能算法(如深度学习算法)的可解释性较差,这在一些对决策要求较高的领域(如医疗、金融等)可能会受到限制。未来需要研究和开发更加可解释的算法。
总结:学到了什么?
核心概念回顾
- AI原生应用:是以人工智能技术为核心驱动力构建的应用程序,能利用各种人工智能能力解决复杂问题。
- 思维树:是一种结构化的思考方式,将复杂问题分解为多个层次和分支,帮助人们更好地理解和分析问题。
- 企业发展:企业需要各种资源和条件,朝着大目标不断前进,实现自身的成长和壮大。
概念关系回顾
- AI原生应用和思维树相互合作,思维树为AI原生应用提供解决问题的路径,AI原生应用按照思维树的指引进行数据处理和分析。
- 思维树为企业发展提供方向,帮助企业将大目标分解为小目标,逐步实现发展。
- AI原生应用是企业发展的加速器,能帮助企业优化产品和服务,提高运营效率。
思考题:动动小脑筋
- 思考题一:你能想到生活中还有哪些地方可以应用AI原生应用和思维树的方式来解决问题吗?
- 思考题二:如果你是一家企业的管理者,你会如何利用AI原生应用和思维树来推动企业的发展?
附录:常见问题与解答
问题一:AI原生应用和传统应用有什么区别?
答:AI原生应用从设计之初就以人工智能技术为核心,充分利用人工智能的能力来实现各种功能。而传统应用可能只是在部分环节使用了一些简单的算法,没有将人工智能作为核心驱动力。
问题二:思维树的构建有什么技巧吗?
答:构建思维树时,首先要明确问题或目标,然后从大到小、从粗到细地进行分解。可以根据问题的性质和特点,选择不同的划分维度,如时间、空间、类别等。同时,要确保每个分支和子分支之间相互独立且完全穷尽。
扩展阅读 & 参考资料
- 《人工智能:现代方法》
- 《Python机器学习实战》
- 《深度学习》
- 相关学术论文和研究报告
通过以上内容,我们全面了解了AI原生应用领域思维树以及其如何赋能企业发展。希望读者能够从中获得启发,将相关知识应用到实际工作和生活中。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献132条内容
已为社区贡献132条内容

所有评论(0)