【源码】2025年花了一年,只做了一个模型的一个应用;像是老匠人凿石头,一行一行地敲AI代码;Python Text Classifaction分类
是一种专为大语言模型(LLM)和生成式 AI 模型设计的二进制文件格式模型体积过大(动辄几十 GB),普通设备难以运行;加载速度慢,无法快速启动推理;依赖复杂框架,跨平台兼容性差。我用AI写的代码让AI分析结果,写了一个AI文章希望你对python 的有点了解:一个理想的训练过程,就是一个正向的,你最终知道目的地,并且能够到,能去掉的这么一个目的地TextClassifcation 和 这个交叉X
AI的功能和每个人的个性,都是大不相同
以前一个朋友的手机总是一尘不染,
用了一年的手机像是新的机器一样

而个人的手机,
当时买过很多千元机,

不是要黑小米
红米RedNode你自己什么质量,你自己不清楚,消费者还不清楚么;
价格比小米低的没有小米质量好,质量好的肯定没有小米价格低;
(如果我那个朋友用小米,小心呵护,也是不会有什么质量问题
网络上每个人的吹捧
“道家”其实是被逼出来的,
- 核心主张"道法自然"(《道德经》二十五章),强调顺应自然规律而非人为干预
不干预的结果就是你说什么都行,社会没有一套标准准则,如果你在一个"理想“的大学内,是”理想“,正规,和传统都不够,是必须”理想“地人均教授,发展是正向的,向前的;教授平均线本身就高,而且什么是教授,能设定标准的就是教授,所以人均设定标准,但是。。。但是如果这套没有准则的准则,放大的整个社会,请问是可行么?
| 智能体 | |
| 上下文 | |
| Agent | |
| llm / uugf / |
llm===A large language model ; ugf=== utility generating function; gguf==GGML Universal File GGML==Gemma General Matrix Library//关键就一个字,general-通用 |
|
而Univeral 其实也有通用的意思 ---------------- 例如Unity 的 URP === Univeral Render Pipline 所以?? ggml ?? universal?? 而File 就更扯, ------------------ 你根本不需要关心什么是File,难道在程序世界内, 有什么不是File 的吗 所以你知道,我为什么要写这个“文档”了 --------------------- 为的就是不要100年后的人,看这些英文缩写,好像在考古甲骨文一样,是的,个人估计,当年甲骨文就是当年的媒体写下的; |
我问一个ai,什么是“uugf 模型”,他居然说

实际上,应该是gguf
GGUF(GGML Universal File) 是一种专为大语言模型(LLM)和生成式 AI 模型设计的二进制文件格式,核心目标是解决传统模型格式(如 PyTorch 的.bin、TensorFlow 的.pb)在本地部署时的三大痛点:
- 模型体积过大(动辄几十 GB),普通设备难以运行;
- 加载速度慢,无法快速启动推理;
- 依赖复杂框架,跨平台兼容性差。
中国有千年的文化,但是西方简写三个字的文化也别证明是可行的
科学上应该解释不了,为什么gguf 不会和uugf 混淆
这个文档也证明不了,为什么不混淆
但事实就是简写成3字,几乎就不会混淆(人类的认知在三位数以内,不过千)
4个字的gguf更不会混淆了
写一个简单代码,应该有手就能用
作者用i精尽量做简化和测试,应该直接运行的代码
如有环境问题,就留言吧,会尽量做修复
=========================================
#没有什么实际作用的代码(实际最后发现;多苟鱼)
import torch
import torch.nn as nn
# 假设一个简单分类模型
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Linear(28*28, 10)
def forward(self, x):
print("测试 forwad这个方法有被调用么")
x = x.view(x.size(0), -1)
logits = self.fc(x)
return logits
model = SimpleModel()
criterion = nn.CrossEntropyLoss()
# 模拟数据,拟 batch_size=3,5 个类别
images = torch.randn(32, 28*28)
labels = torch.randint(0, 10, (32,))
#logits = torch.randn(3, 5) # input: (N=3, C=5)
#labels = torch.tensor([1, 0, 4]) # target: (N=3,),值 ∈ {0,1,2,3,4}
# 前向传播
#当然你在这里前后打印,能看到forward()调用时间
logits = model(images)
#后打印能,能看到forward()调用时间
loss = criterion(logits, labels) # 注意:这里用 logits,不是 softmax 输出
print("Logits shape:", logits.shape) # [32, 10]
print("Loss:", loss.item())
#什么是:向前传播; (符号主义vs联结主义)
#什么是: CrossEntropyLoss(); 分类问题的损失函数(CrossEntropyLoss, BCELoss, Nllloss)
#forward()为什么能被调用? 向前传播
如果只看下面图可能看不懂,但是
x1,x2,a,和y 这一整块都是一个神经网络,而向前传播,只是说神经网络的内部是向前传播而已;
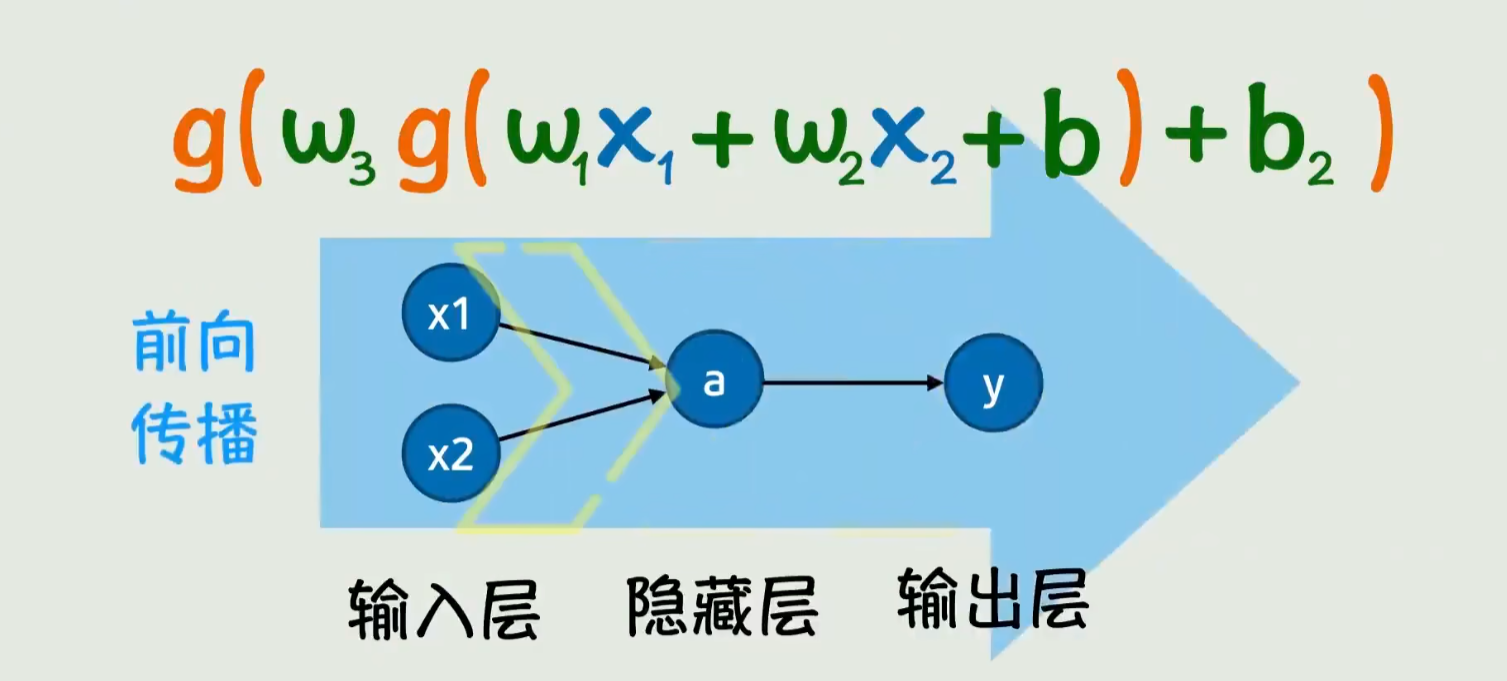
Torch的函数,直译是最不好的翻译,我说的
踏马的,和你翻译的商啊,火啊,XO交叉的没什么关系;;
这个函数重点在于Loss 了多少,公式右下
预测和实际到底差多少(损失),公式原理我也不知道

(除了 CxxxLoss()本身的代码,调用这个代码的代码,请结合上面代码,最终的Pyhton print out 的内容的作用只有一个,如下:)
【核心作用:】把“可训练的张量”变成“可读/可用的数字”
PyTorch 的 loss 是一个带梯度信息的张量,用于反向传播。但人类和大多数系统不需要梯度,只需要知道“损失是多少”。
loss.item() 就是剥离所有计算图信息,只留下干净的数值,便于后续处理。
程序员/用户的【典型应用场景】
监控训练过程(最常见!),程序员需要知道模型是否在“学”,所以每轮打印 loss:
forward方法 in Pytorch
如果你想学一点Torch
一、GGUF 与其他模型格式的关键区别
| 格式 | 典型场景 | 体积 | 加载速度 | 依赖 | 本地部署友好度 |
|---|---|---|---|---|---|
| GGUF | 本地 CPU/GPU 推理 | 极小(量化后) | 极快(mmap) | 无(依赖 llama.cpp 等轻量库) | ★★★★★ |
| PyTorch(.bin/.pt) | 模型训练 / 微调 | 大(FP32/FP16) | 慢 | PyTorch+CUDA | ★★☆☆☆ |
| Safetensors | 安全的模型存储 | 中(无压缩) | 中 | 依赖 Safetensors 库 | ★★★☆☆ |
| GGML | 早期本地推理格式 | 小 | 中 | 部分框架已淘汰 |
二、Torch 代码 API
torch.nn.CrossEntropyLoss 的 前向传播方法(即调用 loss_fn(input, target) 时) 接收两个主要参数:
✅ 1. input(也常称为 logits)
- 类型:
Tensor - 形状:
(N, C)或(N, C, d1, d2, ..., dk)N:batch size(样本数量)C:类别数(number of classes)- 后面的维度用于像素级分类(如语义分割),例如
(N, C, H, W)
- 含义:模型未经过 softmax 的原始输出(即 logits),不要手动加 softmax!
- 数据类型:通常为
float32或float64
⚠️ 注意:
CrossEntropyLoss内部会自动对input做log_softmax,所以你必须传入原始 logits。
✅ 2. target
- 类型:
Tensor - 形状:
- 如果
input是(N, C),则target应为(N,),每个元素是 类别索引(0 到 C-1) - 如果
input是(N, C, H, W)(如分割任务),则target应为(N, H, W),每个位置是类别索引
- 如果
- 数据类型:必须是
long(即torch.int64)
❌ 常见错误:把 one-hot 编码当作 target 传入 —— 这是错的!
✅ 正确做法:target 是整数标签,不是 one-hot!
总结
我用AI写的代码
让AI分析
结果,写了一个AI文章

希望你对python 的Text Classifaction 有点了解:
一个理想的训练过程,就是一个正向的,你最终知道目的地,并且能够到,能去掉的这么一个目的地
TextClassifcation 和 这个交叉X损失,能让你判断,是否在前进,;

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)