NavDP---扩散策略的深度代码精读
摘要: Jitendra Malik提出的"导航是否接近完成"引发了对AI导航技术发展矛盾的讨论:结构化场景中导航已较成熟,但动态复杂环境仍面临挑战。最新研究显示大模型在空间推理上与人类差距显著。NavDP(Navigation Diffusion Policy)通过扩散策略网络实现跨场景通用导航,其核心架构采用双头设计(轨迹生成与评估),结合扩散过程和多模态融合,在10步内完
0. 引言
在当前AI与机器人融合发展的关键时期,Jitendra Malik的"Navigation is nearly done?"这一观点引发了学界广泛讨论。这个问题的背后,实际上反映了导航技术发展的深层矛盾:一方面,在结构化固定场景中,传统的建图-定位-规划方案确实已经相当成熟,简单的目标导航任务通过learning-based方法也能表现良好;另一方面,面对动态场景、复杂指令导航、陌生环境等挑战,现有方法仍然远未达到理想状态,大模型在空间理解推理方面仍显得力不从心。
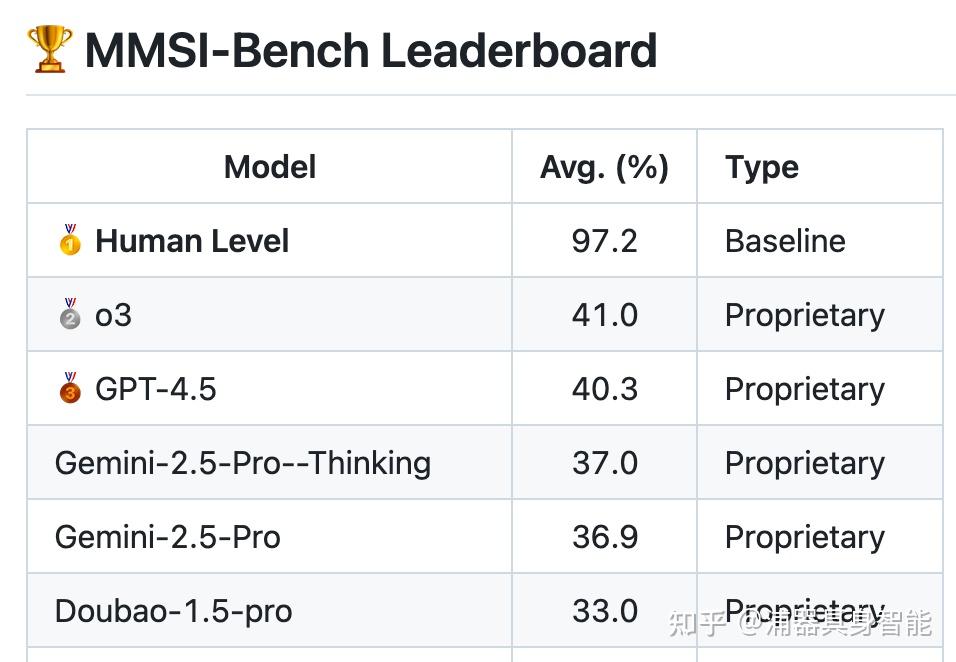
图1:MMSI-Bench leaderboard显示当前大模型与人类在空间推理能力上的巨大差距
正如上图所示,当前最先进的大模型在空间推理基准测试中与人类仍有显著差距,这揭示了一个重要问题:虽然我们在某些特定场景下取得了不错的效果,但通用的空间智能仍然任重道远。NavDP(Navigation Diffusion Policy)作为这一背景下的重要探索,通过扩散策略网络实现了跨视角、跨本体、跨场景的通用导航能力,为我们提供了从代码实现角度审视导航技术发展的绝佳窗口。
本文将深入解析NavDP的核心代码实现,结合StreamVLN的高层规划能力,探讨这种"High-level规划+Low-level执行"的双系统架构如何回应当前导航领域面临的核心挑战,以及如何在理论创新与工程实践之间找到平衡点。
1. 扩散策略网络的核心架构——从理论到实现的完整映射
NavDP的核心创新在于将扩散模型引入机器人导航任务,其主要网络架构体现在policy_network.py的NavDP_Policy_DPT类中。这个设计不仅仅是技术上的创新,更是对导航任务本质的深刻理解。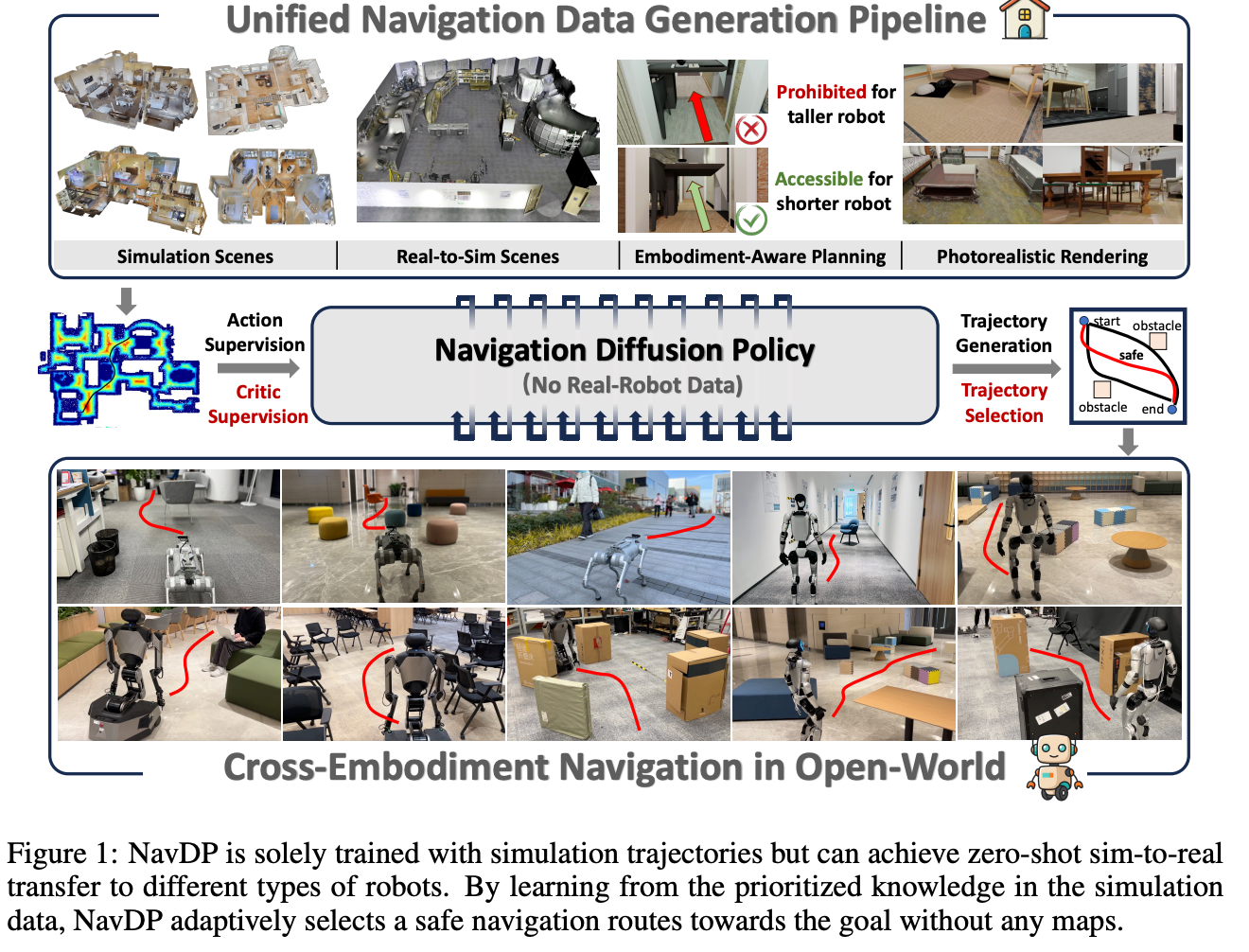
图1:NavDP仅通过仿真轨迹进行训练,但能够实现不同类型机器人之间的零-shot仿真到真实的转移。通过从仿真数据中的优先知识中学习,NavDP自适应地选择安全的导航路线驶向目标,而无需任何地图。
class NavDP_Policy_DPT(nn.Module):
def __init__(self,
image_size=224,
memory_size=8,
predict_size=24,
temporal_depth=8,
heads=8,
token_dim=384,
channels=3,
device='cuda:0'):
super().__init__()
# 核心组件:RGBD编码器 + 目标编码器
self.rgbd_encoder = NavDP_RGBD_Backbone(image_size,token_dim,memory_size=memory_size,device=device)
self.point_encoder = nn.Linear(3,self.token_dim)
# Transformer解码器:处理时序信息
self.decoder_layer = nn.TransformerDecoderLayer(d_model = token_dim,
nhead = heads,
dim_feedforward = 4 * token_dim,
activation = 'gelu',
batch_first = True,
norm_first = True)
self.decoder = nn.TransformerDecoder(decoder_layer = self.decoder_layer,
num_layers = self.temporal_depth)
这个架构设计体现了NavDP对导航任务的深层理解。与传统方法不同,NavDP并没有试图显式地进行建图、定位和路径规划,而是通过扩散过程直接学习从观察到轨迹的映射关系。
网络架构中最引人注目的是双头设计:action_head负责轨迹生成,critic_head负责轨迹评估。这种设计源于对导航任务复杂性的认识——仅仅生成可行轨迹是不够的,还需要评估这些轨迹的安全性和有效性。这正体现了当前导航技术发展的两面性:技术上可以生成轨迹,但如何确保安全性仍然是重大挑战。
2. 扩散过程的精妙实现——噪声中的智能涌现
NavDP的核心算法体现在predict_noise方法中,这个方法展现了扩散模型在导航任务中的独特适应性:
def predict_noise(self,last_actions,timestep,goal_embed,rgbd_embed):
action_embeds = self.input_embed(last_actions)
time_embeds = self.time_emb(timestep.to(self.device)).unsqueeze(1).tile((last_actions.shape[0],1,1))
# 多模态条件融合:时间+目标+视觉
cond_embedding = torch.cat([time_embeds,goal_embed,rgbd_embed],dim=1) + self.cond_pos_embed(torch.cat([time_embeds,goal_embed,rgbd_embed],dim=1))
input_embedding = action_embeds + self.out_pos_embed(action_embeds)
# Transformer解码器处理
output = self.decoder(tgt = input_embedding,memory = cond_embedding, tgt_mask = self.tgt_mask.to(self.device))
output = self.layernorm(output)
output = self.action_head(output)
return output
这个实现展现了NavDP如何将抽象的扩散理论转化为具体的导航策略。时间步嵌入、多模态条件融合、因果掩码机制——每一个设计细节都体现了对导航任务特性的深入理解。特别值得注意的是,这里的扩散过程不是简单的图像生成,而是在多维约束下的轨迹规划,这种约束来自于环境几何、动力学限制以及安全性要求。
扩散步数的设置也体现了实用性考虑。传统扩散模型通常需要数百到上千步,但NavDP将其压缩到10步,在保证生成质量的同时确保了实时性。这种权衡体现了从学术研究到实际应用的转化过程中必须面对的现实约束。
3. 轨迹评估机制——安全性的代码化体现
NavDP的另一个重要创新是轨迹评估机制,这在predict_critic方法中得到了完整体现:
def predict_critic(self,predict_trajectory,rgbd_embed):
nogoal_embed = torch.zeros_like(rgbd_embed[:,0:1])
action_embeddings = self.input_embed(predict_trajectory)
action_embeddings = action_embeddings + self.out_pos_embed(action_embeddings)
# 屏蔽目标信息,专注轨迹本身的安全性评估
cond_embeddings = torch.cat([nogoal_embed,nogoal_embed,rgbd_embed],dim=1) + self.cond_pos_embed(torch.cat([nogoal_embed,nogoal_embed,rgbd_embed],dim=1))
critic_output = self.decoder(tgt = action_embeddings, memory = cond_embeddings, memory_mask = self.cond_critic_mask.to(self.device))
critic_output = self.layernorm(critic_output)
critic_output = self.critic_head(critic_output.mean(dim=1))[:,0]
return critic_output
这个设计的精妙之处在于使用零向量替代目标嵌入,使评估器专注于轨迹本身的安全性而非目标达成度。这种设计哲学反映了当前导航技术发展的一个重要认识:在动态复杂环境中,安全性往往比效率更为重要。通过memory_mask机制进一步屏蔽目标信息,确保评估的客观性。
这种"生成+评估"的双系统架构回应了导航领域的一个核心挑战:如何在保证安全性的前提下实现高效导航。传统方法通过显式的安全检查和约束来解决这个问题,而NavDP则通过学习的方式将安全性考虑内化到网络结构中。
4. RGBD双模态视觉编码器——感知的深度融合
NavDP的视觉感知能力主要体现在policy_backbone.py中的NavDP_RGBD_Backbone类。这个设计展现了对机器人感知任务的深入理解:
class NavDP_RGBD_Backbone(nn.Module):
def __init__(self,
image_size=224,
embed_size=512,
memory_size=8,
device='cuda:0'):
super().__init__()
# 使用DepthAnythingV2作为预训练基础
model_configs = {'vits': {'encoder': 'vits', 'features': 64, 'out_channels': [48, 96, 192, 384]}}
self.rgb_model = DepthAnythingV2(**model_configs['vits'])
self.depth_model = DepthAnythingV2(**model_configs['vits'])
# Transformer融合网络
self.former_net = nn.TransformerDecoder(nn.TransformerDecoderLayer(384,8,batch_first=True),2)
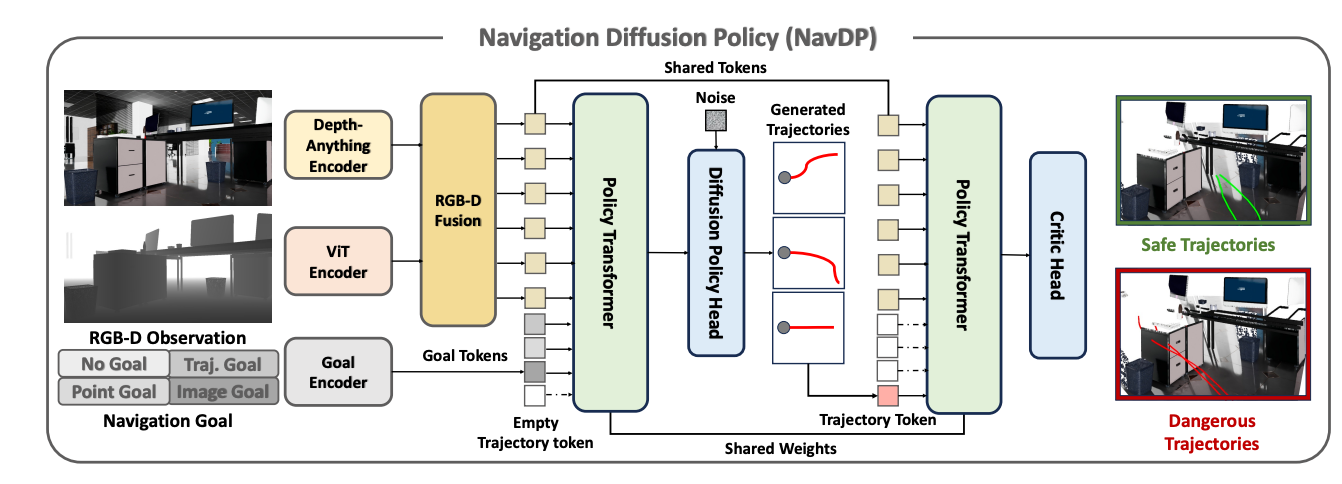
这种双流架构的设计体现了对多模态信息融合的深刻理解。RGB图像提供丰富的语义信息,深度图像提供准确的几何结构,两者的融合为导航决策提供了完整的环境感知基础。特别值得注意的是对DepthAnythingV2预训练模型的复用,这体现了站在巨人肩膀上的工程智慧。
时序处理机制的实现展现了对导航任务动态性的考虑:
def forward(self,images,depths):
with torch.no_grad():
if len(images.shape) == 5:
tensor_images = torch.as_tensor(images,dtype=torch.float32,device=self.device).permute(0,1,4,2,3)
B,T,C,H,W = tensor_images.shape
tensor_images = tensor_images.reshape(-1,3,self.image_size,self.image_size)
image_token = self.rgb_model.get_intermediate_layers(tensor_norm_images)[0].reshape(B,T*256,-1)
这种灵活的输入处理机制支持单帧和多帧输入,体现了系统的适应性。通过reshape操作实现的高效批处理,展现了从研究代码到工程实现的优化考虑。
5. 轨迹生成与选择的完整流程——从采样到决策
NavDP的轨迹生成流程在predict_pointgoal_action方法中得到了完整体现,这个过程展现了扩散模型在导航任务中的独特优势:
def predict_pointgoal_action(self,goal_point,input_images,input_depths,sample_num=16):
with torch.no_grad():
# 编码阶段:多模态信息融合
tensor_point_goal = torch.as_tensor(goal_point,dtype=torch.float32,device=self.device)
rgbd_embed = self.rgbd_encoder(input_images,input_depths)
pointgoal_embed = self.point_encoder(tensor_point_goal).unsqueeze(1)
# 扩散采样:从噪声到轨迹
noisy_action = torch.randn((sample_num * goal_point.shape[0], self.predict_size, 3), device=self.device)
naction = noisy_action
self.noise_scheduler.set_timesteps(self.noise_scheduler.config.num_train_timesteps)
for k in self.noise_scheduler.timesteps[:]:
noise_pred = self.predict_noise(naction,k.unsqueeze(0),pointgoal_embed,rgbd_embed)
naction = self.noise_scheduler.step(model_output=noise_pred,timestep=k,sample=naction).prev_sample
# 轨迹评估与选择
critic_values = self.predict_critic(naction,rgbd_embed)
all_trajectory = torch.cumsum(naction / 4.0, dim=1)
这个流程展现了NavDP如何将理论优雅地转化为实践。多样性采样确保了解的丰富性,评估排序保证了选择的合理性,而速度缩放(除以4.0)则体现了对实际执行的考虑。这种设计反映了导航任务的一个重要特点:往往存在多条可行路径,关键在于如何选择最优的那一条。
轨迹选择策略的实现展现了系统的全面性考虑:
# 选择最优轨迹
sorted_indices = (-critic_values).argsort(dim=1)
topk_indices = sorted_indices[:,0:2]
positive_trajectory = all_trajectory[batch_indices, topk_indices]
# 同时记录最差轨迹用于对比分析
sorted_indices = (critic_values).argsort(dim=1)
topk_indices = sorted_indices[:,0:2]
negative_trajectory = all_trajectory[batch_indices, topk_indices]
这种同时返回最优和最差轨迹的设计,为后续的对比学习和安全性分析提供了基础,体现了系统设计的前瞻性。
6. 代理系统的工程实现——从算法到应用的桥梁
policy_agent.py中的NavDP_Agent类展现了如何将核心算法转化为可实际部署的系统。这个类的设计体现了工程实践中的诸多考虑:
def step_pointgoal(self,goals,images,depths):
# 内存管理:滑动窗口机制
for i in range(len(self.memory_queue)):
if len(self.memory_queue[i]) < self.memory_size:
self.memory_queue[i].append(process_images[i])
input_image = np.array(self.memory_queue[i])
input_image = np.pad(input_image,((self.memory_size - input_image.shape[0],0),(0,0),(0,0),(0,0)))
else:
del self.memory_queue[i][0]
self.memory_queue[i].append(process_images[i])
input_image = np.array(self.memory_queue[i])
这种FIFO队列式的内存管理机制体现了对时序信息的重视,同时通过零填充优雅地处理了序列长度不足的情况。这种设计反映了实际部署中必须面对的资源约束和实时性要求。
图像预处理的鲁棒性设计展现了对真实环境复杂性的考虑:
def process_depth(self,depths):
depths[depths==np.inf] = 0 # 处理无穷值
resize_depth[resize_depth>5.0] = 0 # 距离上限裁剪
resize_depth[resize_depth<0.1] = 0 # 距离下限裁剪
这些看似简单的预处理步骤,实际上是对真实传感器数据特性的深刻理解的体现。每一行代码都代表着在实际部署中遇到的具体问题和解决方案。
…详情请参照古月居

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献155条内容
已为社区贡献155条内容

所有评论(0)