WoW: 通向全知世界模型的具身交互之路
WoW的核心是SOPHIA(Self-Optimizing Predictive Hallucination Improving Agent,自优化预测幻觉改进智能体)范式。这是一个闭环自优化框架,通过"预测-评估-优化"的迭代循环提升物理推理能力。范式代表模型核心思想物理理解闭环优化Diffusion噪声→图像的逆过程统计模式无JEPA预测latent表征抽象特征无SOPHIAWoW预测+评估+
0. 引言: 从被动观察到主动交互
人类认知的启示: 具身学习的本质
人类儿童是如何理解这个世界的? 答案并非通过被动地观看视频,而是通过主动的物理实验。认知科学家皮亚杰(Jean Piaget)精辟地阐述了这一原理:“认识一个物体,就是对它采取行动”(To know an object is to act on it)。这种具身学习方式将无数"动作"与即时"结果"深度绑定,构成了人类掌握物理规律的基础机制。这一洞见不仅影响了发展心理学,更为当今的具身智能(Embodied AI)研究提供了关键的理论基础。
让我们深入理解这一认知过程: 当婴儿第一次触碰一个球时,他们不仅仅是在"看"球,而是在通过推、拉、抛、接等一系列动作来建立对"球"这一概念的完整理解。通过数千次这样的交互,儿童逐渐形成了对重力、惯性、弹性等物理概念的直觉理解——而这一切都发生在他们能够用语言描述这些概念之前。根据发展心理学研究,婴儿在出生后的前两年内就能通过感觉运动阶段的经验建立起基本的物理直觉,这种"隐性知识"是后续所有高级认知能力的基石。
这种从"身体知道"到"大脑知道"的转变,正是具身认知(Embodied Cognition)理论的核心。该理论认为,认知不仅仅是大脑的活动,而是身体、大脑与环境三者交互的产物——这一观点对AI研究具有深远影响。
2024-2025: 世界模型的"竞技场时代"
2024年至2025年,世界模型(World Model)领域迎来了前所未有的技术竞赛。各大科技巨头纷纷布局这一被认为是通往通用人工智能(AGI)关键路径的技术方向:
| 公司/机构 | 代表模型 | 核心特点 | 发布时间 |
|---|---|---|---|
| OpenAI | Sora / Sora 2 | 文本到视频,1080p高质量生成 | 2024.02 / 2025.09 |
| NVIDIA | Cosmos WFM | 物理AI世界基础模型,支持机器人和自动驾驶 | 2025.01 |
| Google DeepMind | Genie 3 | 实时交互式世界生成,24fps@720p | 2025.08 |
| 清华团队 | WoW | 具身交互世界模型,140亿参数 | 2025.09 |
| 斯坦福/李飞飞 | World Labs | 空间智能,3D世界理解 | 2024.09 |
行业洞察: 根据IDC 2025年报告,世界模型被认为是具身智能机器人发展的七大趋势之一。完善的仿真环境和世界模型将帮助机器人更好地理解物理世界,通过模拟和建模提升其运动控制和操作能力。
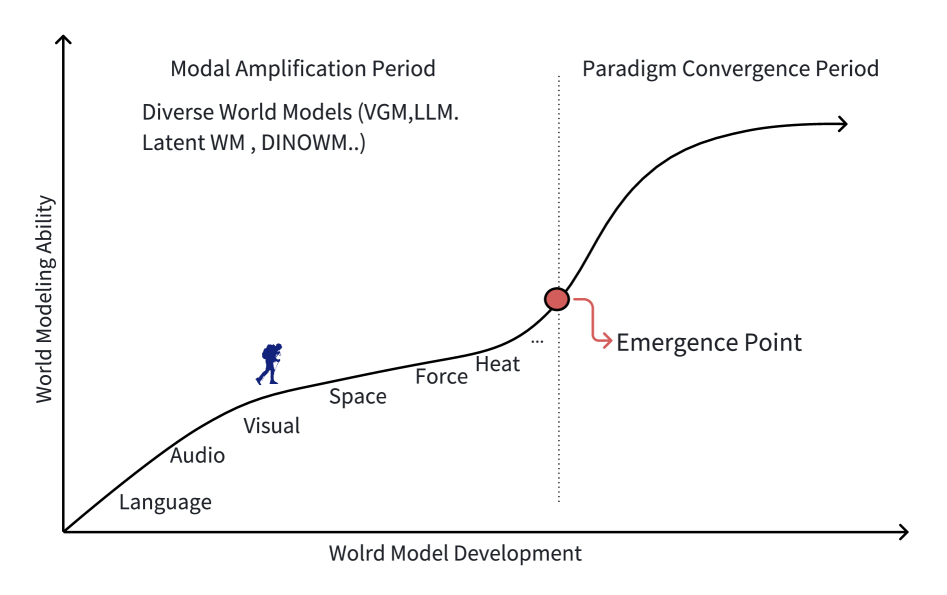
图1: 世界模型技术演进路线图——从早期的Dyna算法到当今的大规模生成式世界模型
尽管现在这些模型能生成惊人的照片级真实感画面,但其对物理规律的理解往往停留在表面,在面临需要真正物理推理的场景时,常常产生逻辑与物理上均不一致的结果。Sora的物理理解局限性(来自OpenAI官方说明)::“Sora有时难以准确模拟复杂场景的物理,可能无法理解因果关系。例如,一个人可能咬了一口饼干,但饼干上可能没有留下咬痕。” —— OpenAI技术报告
常见的物理幻觉(Physical Hallucination)类型:
| 幻觉类型 | 描述 | 示例 |
|---|---|---|
| 几何穿透 | 物体穿透固体表面 | 手穿过桌子、物体嵌入墙壁 |
| 重力违反 | 液体或物体违反重力 | 水向上流、物体悬浮 |
| 因果断裂 | 动作与结果不匹配 | 踢球但球不动、切割但物体完整 |
| 恒存性失效 | 物体无故消失或出现 | 被遮挡物体消失、凭空出现新物体 |
| 运动不连续 | 物体突然改变运动状态 | 无外力下加速或转向 |
WoW(World-Omniscient World Model,全知世界模型)正是基于这一观察提出的核心假设: 世界模型若要具备真正的物理直觉,必须以大量、富含因果关系的真实世界交互为基础。 这一假设与当前业界的发展方向高度一致——无论是NVIDIA的Cosmos还是Google DeepMind的Genie 3,都在探索如何让AI系统更好地理解和模拟物理世界。
这一假设的理论基础来自Judea Pearl的因果推理框架。Pearl指出,仅从观察数据中学习只能得到统计相关性,而真正的因果理解需要"干预"(Intervention)——即主动改变世界并观察结果。这正是具身交互数据的独特价值所在。WoW团队认为,正如NVIDIA CEO黄仁勋在CES 2025上所言:“生成物理AI系统的合成数据需要能够理解物理定律的世界基础模型”,WoW正是朝着这一目标迈出的重要一步。
WoW与其他世界模型的技术路线对比:
| 维度 | WoW | NVIDIA Cosmos | Google Genie 3 | OpenAI Sora |
|---|---|---|---|---|
| 核心目标 | 具身操作+物理推理 | 自动驾驶+机器人 | 交互式世界生成 | 通用视频生成 |
| 训练数据 | 机器人交互轨迹 | 真实世界+合成数据 | 游戏环境数据 | 互联网视频 |
| 物理理解 | 因果干预学习 | 物理感知预训练 | 交互式学习 | 统计模式学习 |
| 闭环能力 | 支持(FM-IDM) | 部分支持 | 支持 | 不支持 |
| 参数规模 | 14B | Nano/Super/Ultra多版本 | 未公开 | 未公开 |
WoW的训练范式:
机器人交互数据 → 因果关系学习 → 物理一致性生成
↑ ↓
←←←← 动作执行与反馈 ←←←←←←←←←←←
WoW的独特之处在于它不仅仅是一个视频生成器,更是一个能够"闭环"的具身智能系统。通过FM-IDM(流掩码逆动力学模型),WoW能够将其"想象"的未来场景转化为真实机器人可执行的动作,这种"想象到行动"的闭环能力是其区别于Sora等纯视频生成模型的关键特征。
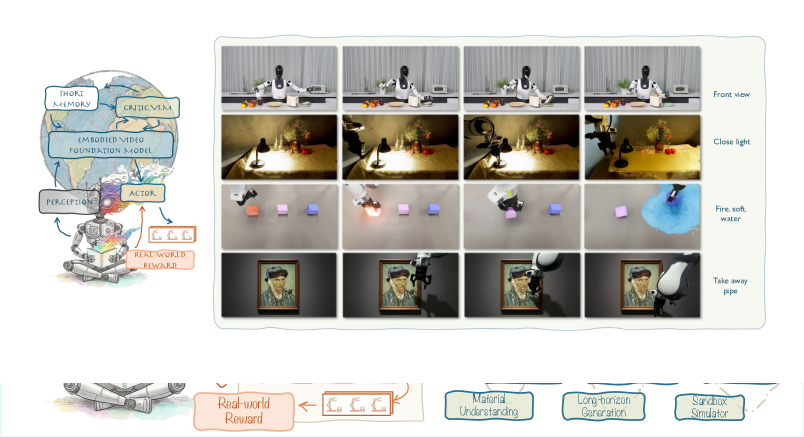
图2: WoW是一个融合了感知、预测、判断、反思与行动五个环节的具身世界模型,形成完整的认知-行动闭环
1. WoW架构全景: SOPHIA范式
1.1 什么是SOPHIA?
WoW的核心是SOPHIA(Self-Optimizing Predictive Hallucination Improving Agent,自优化预测幻觉改进智能体)范式。这是一个闭环自优化框架,通过"预测-评估-优化"的迭代循环提升物理推理能力。
SOPHIA与现有范式的本质区别:
| 范式 | 代表模型 | 核心思想 | 物理理解 | 闭环优化 |
|---|---|---|---|---|
| Diffusion | Sora, Runway | 噪声→图像的逆过程 | 统计模式 | 无 |
| JEPA | I-JEPA, V-JEPA | 预测latent表征 | 抽象特征 | 无 |
| SOPHIA | WoW | 预测+评估+行动 | 因果机制 | 有 |
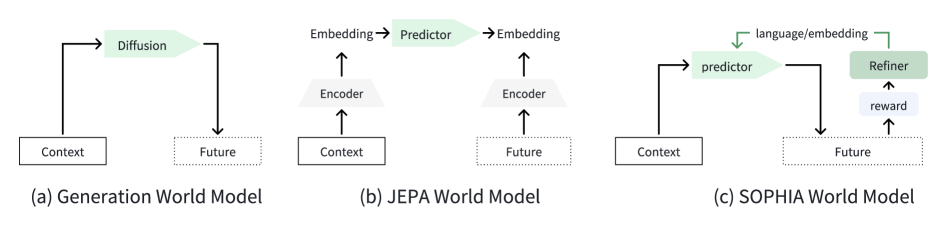
图3: SOPHIA范式与Diffusion模型、JEPA模型的对比
1.2 认知科学基础: Neisser感知循环
SOPHIA的设计灵感来源于认知心理学家Ulric Neisser提出的感知循环(Perceptual Cycle)理论。该理论认为,人类的感知不是被动接收信息,而是一个主动的、循环的过程:
Neisser感知循环:
┌──────────────────────────────────────────────────┐
│ │
│ ┌─────────┐ │
│ │ 图式 │←───────────────┐ │
│ │ (Schema)│ │ │
│ └────┬────┘ │ │
│ │ │ │
│ ↓ 引导 │ 修改 │
│ ┌─────────┐ │ │
│ │ 感知 │ │ │
│ │(Perceive) │ │
│ └────┬────┘ │ │
│ │ │ │
│ ↓ 驱动 │ │
│ ┌─────────┐ │ │
│ │ 动作 │────────────────┘ │
│ │ (Action)│ │
│ └─────────┘ │
│ │
└──────────────────────────────────────────────────┘
WoW将这一认知循环转化为计算框架:
- 图式 → DiT生成的未来预测
- 感知 → VLM评估器对生成结果的评估
- 动作 → 根据评估反馈优化提示或执行机器人动作
1.2 SOPHIA范式的三个核心阶段
受Neisser感知循环(图式→感知→动作→图式)启发,WoW将智能行为划分为三个互联阶段:
1. 任务想象(Task Imagination) - 生成未来的"心智模拟"
这一阶段负责生成高阶规划与像素级未来预测。基于扩散Transformer(DiT)架构,模型根据当前视觉观测和文本指令,预测未来可能发生的视觉场景。关键在于,这种预测不是简单的图像外推,而是需要理解物理规律的因果推理。
任务想象的三个层次:
任务想象层次结构:
┌─────────────────────────────────────────────────────┐
│ 战略层: "把杯子放到架子上" │
│ ↓ 分解为 │
├─────────────────────────────────────────────────────┤
│ 战术层: 接近杯子→抓取→移动→放置 │
│ ↓ 实例化为 │
├─────────────────────────────────────────────────────┤
│ 执行层: 具体的视觉轨迹预测(像素级) │
└─────────────────────────────────────────────────────┘
2. 经验反思(Experience Reflection) - 批判性评估
VLM(视觉语言模型)智能体评估DiT的生成结果,验证其物理一致性。如果生成的视频违反物理规律(如物体穿透实体表面),评估器会提供结构化反馈,指导下一轮生成。这种"求解器-评估器"机制将视频生成从单次操作转变为迭代优化过程。
{
"overall_plausibility": 0.65,
"issues": [
{
"type": "physics_violation",
"frame_range": [23, 28],
"description": "机器人手臂穿透物体表面",
"severity": "high",
"suggested_fix": "调整抓取轨迹,从物体上方接近"
}
],
"strengths": ["任务方向正确", "抓取姿态合理"]
}
3. 行为提取(Behavior Extraction) - 从想象到行动
流掩码逆动力学模型(FM-IDM)将优化后的规划转化为可执行的机器人动作。通过分析当前状态与想象中下一状态的光流和场景上下文,FM-IDM推断实现状态转移所需的7-DoF末端执行器动作。
末端执行器动作 a t ∈ R 7 a_t \in \mathbb{R}^7 at∈R7:
| 分量 | 自由度 | 描述 |
|---|---|---|
| 位置 ( x , y , z ) (x, y, z) (x,y,z) | 3个自由度 | 空间位置 |
| 姿态 ( r x , r y , r z ) (r_x, r_y, r_z) (rx,ry,rz) | 3个自由度 | 旋转角度 |
| 夹爪 ( g ) (g) (g) | 1个自由度 | 开合状态 |
1.3 语言表征完备性假设
SOPHIA基于以下关键假设提升物理合理性:
假设(语言表征完备性): 设 x = x 1 , x 2 , . . . , x T x = {x_1, x_2, ..., x_T} x=x1,x2,...,xT为连续输入序列,对任意 ε > 0 ε > 0 ε>0,存在语言系统 L ε L_ε Lε使得对任意足够不同的物理序列,其语言表示也是不同的。
这个假设的核心是: 如果语言足够丰富,它可以精确描述任何物理场景。想象一下,一个极其详细的文字描述:
"一个红色陶瓷杯子(直径8cm,高10cm,重约200g)放在木质桌面上,
距离桌子边缘15cm。机器人夹爪从杯子正上方30cm处以5cm/s的速度
垂直下降,直到接触杯子把手。"
这样的描述理论上可以唯一确定一个物理场景。WoW利用这一特性,将复杂动力学(如碰撞后运动)抽象为符号描述,通过语言实现对生成过程的细粒度控制。
数学形式化:
设物理序列空间为 P P P,语言表示空间为 L L L,存在映射 φ : P → L φ: P → L φ:P→L,使得:
∀ p 1 , p 2 ∈ P , d P ( p 1 , p 2 ) > ε ⟹ φ ( p 1 ) ≠ φ ( p 2 ) ∀ p₁, p₂ ∈ P, d_P(p₁, p₂) > ε ⟹ φ(p₁) ≠ φ(p₂) ∀p1,p2∈P,dP(p1,p2)>ε⟹φ(p1)=φ(p2)
其中 d P d_P dP是物理序列空间上的距离度量。
2. 视频生成世界模型: DiT骨干网络
2.1 输入输出形式化
WoW采用视频生成范式作为世界模型的核心,将视觉领域作为主要输出模态。其框架将初始状态 s t s_t st 映射到未来状态 s ^ t + 1 \hat{s}_{t+1} s^t+1:
o t : { o t , p t , [ a t , C p o s e , . . . ] } → World Model → s ^ t + 1 : o t + 1 o_t: \{o_t, p_t, [a_t, C_{pose}, ...]\} → \text{World Model} → \hat{s}_{t+1}: o_{t+1} ot:{ot,pt,[at,Cpose,...]}→World Model→s^t+1:ot+1
输入解析:
- o t o_t ot (当前视觉观测): RGB图像或短视频片段,分辨率通常为640×480或720p
- p t p_t pt (高阶文本指令): 自然语言任务描述,如"把红色杯子放到架子上"
- a t a_t at (可选-低阶动作): 7-DoF末端执行器动作,提供更精细的控制
- C p o s e C_{pose} Cpose (可选-相机位姿): 4×4变换矩阵,用于新视角生成
输出:
- o t + 1 o_{t+1} ot+1: 预测的未来视觉观测,通常是41-81帧的视频
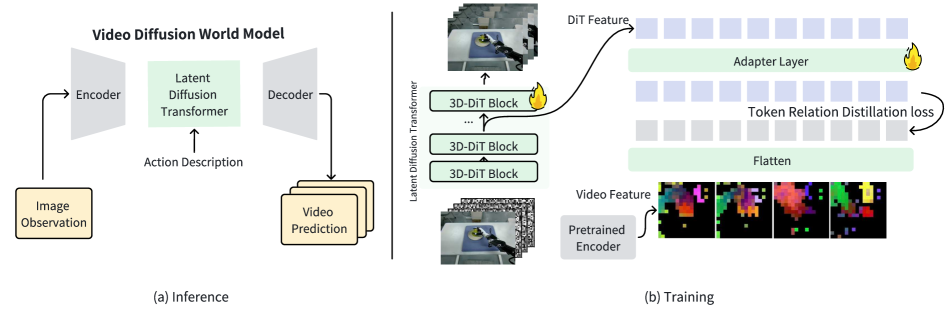
图3: 视频扩散世界模型架构
2.2 文本条件化: 从指令到场景描述
WoW采用InternVL3-78B将语言指令转换为包含环境、相机位姿、机器人具身形态与预期动作的描述性叙述。这些叙述通过预训练T5编码器进行嵌入,作为条件信号注入DiT。
原始指令 → InternVL3扩展 → T5编码 → DiT条件信号
│ │ │ │
"拿起杯子" 详细场景描述 语义向量 生成控制
扩展示例:
原始指令: "拿起杯子"
InternVL3扩展后:
"场景描述: 一个白色陶瓷杯子放在木质桌面中央,杯子把手朝向右侧。
机器人形态: 7-DoF机械臂,带有平行夹爪末端执行器。
相机视角: 俯视45度角,距离桌面约60cm。
预期动作序列:
1. 机械臂从初始位置向杯子上方移动
2. 夹爪打开,下降至杯子高度
3. 从侧面接近杯子,夹爪对准把手
4. 闭合夹爪抓取杯子
5. 提起杯子离开桌面"
# 文本编码流程示例
text_description = vlm_model.describe(image, instruction)
text_embedding = t5_encoder(text_description) # [B, L, 4096]
dit_input = inject_conditioning(noise_latent, text_embedding)
2.3 扩散Transformer架构: DiT详解
去噪骨干网络采用DiT(Diffusion Transformer)架构,这是视频生成领域的state-of-the-art选择。
DiT相比U-Net的优势:
| 特性 | U-Net | DiT |
|---|---|---|
| 扩展性 | 有限 | 优秀 |
| 长程依赖 | 局部感受野 | 全局注意力 |
| 参数效率 | 较低 | 较高 |
| 并行训练 | 较差 | 优秀 |
DiT Block详细结构:
class DiTBlock(nn.Module):
def __init__(self, hidden_dim, num_heads):
super().__init__()
self.norm1 = AdaLN(hidden_dim)
self.attn = MultiHeadAttention(hidden_dim, num_heads)
self.norm2 = AdaLN(hidden_dim)
self.ffn = FeedForward(hidden_dim)
def forward(self, x, timestep_embedding, text_embedding=None):
# 自适应LayerNorm条件化
# AdaLN通过timestep_embedding调制归一化参数
x_norm = self.norm1(x, timestep_embedding)
# 自注意力: 捕获全局依赖
attn_out = self.attn(x_norm)
x = x + attn_out # 残差连接
# 交叉注意力(可选): 注入文本条件
if text_embedding is not None:
x = x + self.cross_attn(x, text_embedding)
# 前馈网络: 非线性变换
x = x + self.ffn(self.norm2(x, timestep_embedding))
return x
自适应LayerNorm (adaLN) 的工作原理:
标准LayerNorm ( γ , β \gamma, \beta γ,β 是可学习的固定参数):
y = γ ⋅ ( x − μ ) / σ + β y = \gamma \cdot (x - \mu) / \sigma + \beta y=γ⋅(x−μ)/σ+β
自适应LayerNorm ( γ , β \gamma, \beta γ,β 由条件输入动态生成):
y = γ ( t ) ⋅ ( x − μ ) / σ + β ( t ) y = \gamma(t) \cdot (x - \mu) / \sigma + \beta(t) y=γ(t)⋅(x−μ)/σ+β(t)
这使得模型可以根据去噪进度动态调整每层的行为——早期去噪阶段关注整体结构,后期关注细节。
位置编码: 3D空间感知
同时采用绝对3D位置嵌入与相对3D旋转位置编码(RoPE):前者维持全局连贯性(如轨迹),后者确保局部像素级因果性(如接触、连续性)。
class Position3DEncoding:
"""
3D位置编码: 时间 × 高度 × 宽度
"""
def __init__(self, hidden_dim, max_t=100, max_h=64, max_w=64):
# 绝对位置嵌入
self.abs_embed = nn.Parameter(
torch.randn(1, max_t, max_h, max_w, hidden_dim) * 0.02
)
# RoPE参数
self.rope_dim = hidden_dim // 3 # 每个维度分配1/3
def forward(self, x):
B, T, H, W, D = x.shape
# 添加绝对位置嵌入
x = x + self.abs_embed[:, :T, :H, :W, :]
# RoPE在注意力计算中应用
return x
2.4 辅助感知增强: DINOv2特征注入
为增强初始状态理解,将自监督视觉表征模型DINOv2的特征注入DiT中间层。这些语义锚定特征提升了模型对物体边界与空间关系的像素级推理能力,弥补了仅通过噪声重建目标学习的latent表征的不足。
class DiTWithDINO(nn.Module):
def __init__(self, dit_model, dino_model):
self.dit = dit_model
self.dino = dino_model
self.dino.eval() # DINO冻结,仅用于特征提取
# 特征对齐层: 将DINO特征映射到DiT空间
self.dino_proj = nn.Linear(dino_dim, dit_dim)
def forward(self, x, timestep, text_cond, input_image):
# 提取DINO特征
with torch.no_grad():
dino_feat = self.dino(input_image) # [B, N, D_dino]
# 投影到DiT维度
dino_feat = self.dino_proj(dino_feat) # [B, N, D_dit]
# DiT前半部分
for block in self.dit.blocks[:len(self.dit.blocks)//2]:
x = block(x, timestep, text_cond)
# 在中间层注入DINO特征
x = x + dino_feat # 残差注入
# DiT后半部分
for block in self.dit.blocks[len(self.dit.blocks)//2:]:
x = block(x, timestep, text_cond)
return x
2.5 训练策略: 去噪扩散目标
WoW的训练采用标准的去噪扩散目标,但针对视频生成进行了优化:
def training_step(model, x_0, text_cond, input_image):
"""
x_0: 真实视频 latent [B, T, H, W, C]
text_cond: 文本条件
input_image: 输入图像(用于DINO特征)
"""
# 采样时间步
t = torch.randint(0, T_max, (B,))
# 添加噪声
noise = torch.randn_like(x_0)
x_t = sqrt_alpha_cumprod[t] * x_0 + sqrt_one_minus_alpha_cumprod[t] * noise
# 模型预测噪声
noise_pred = model(x_t, t, text_cond, input_image)
# 简单MSE损失
loss = F.mse_loss(noise_pred, noise)
# 可选: 加权损失,对物理关键区域提高权重
# loss = weighted_mse_loss(noise_pred, noise, physics_mask)
return loss
采样/推理过程:
从纯噪声开始 x T ∼ N ( 0 , I ) x_T \sim \mathcal{N}(0, I) xT∼N(0,I)
for t = T , T − 1 , . . . , 1 t = T, T-1, ..., 1 t=T,T−1,...,1:
- 预测噪声: ε θ = model ( x t , t , text_cond , input_image ) \varepsilon_\theta = \text{model}(x_t, t, \text{text\_cond}, \text{input\_image}) εθ=model(xt,t,text_cond,input_image)
- 去噪一步: x t − 1 = denoise_step ( x t , ε θ , t ) x_{t-1} = \text{denoise\_step}(x_t, \varepsilon_\theta, t) xt−1=denoise_step(xt,εθ,t)
返回去噪后的视频 x 0 x_0 x0
3. 求解器-评估器智能体系统
3.1 系统概述: 从开环到闭环
WoW的求解器-评估器系统是实现闭环物理推理的关键组件。这一架构将视频生成从被动生成器转变为主动问题求解器。
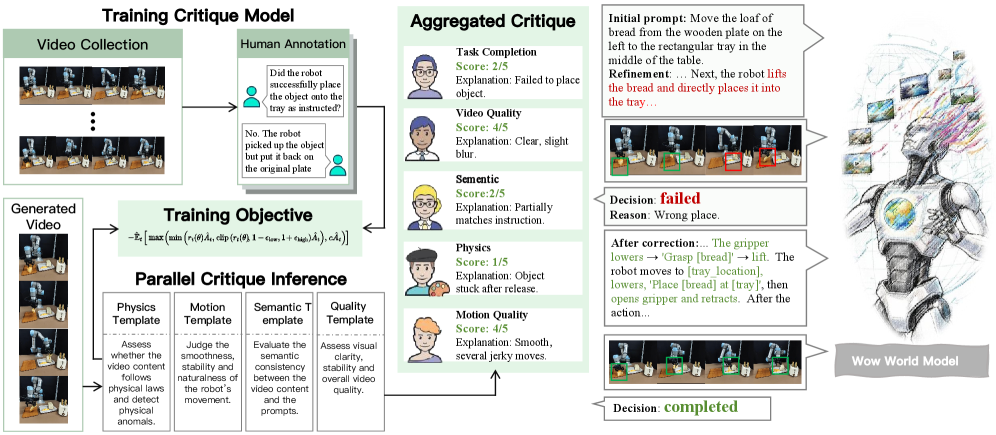
图5: 求解器-评估器视频生成智能体系统
生成模型的输出质量高度依赖输入提示。在机器人等专业领域的视频生成中,提示需捕捉细微物理细节才能产生合理结果。WoW的优化智能体是一个测试时提示优化的自主系统,无需重新训练底层视频生成模型。
优化智能体的核心思想是将生成问题转化为搜索问题——在提示空间中搜索能够产生物理合理输出的提示。
class RefinerAgent:
def __init__(self, prompt_rewriter, critic_model):
self.rewriter = prompt_rewriter
self.critic = critic_model
def refine(self, initial_prompt, initial_frame, max_iterations=3):
prompt = initial_prompt
for _ in range(max_iterations):
# 生成视频
video = world_model.generate(initial_frame, prompt)
# 评估物理一致性
feedback = self.critic.evaluate(video)
if feedback.is_physically_plausible:
return video, prompt
# 根据反馈优化提示
prompt = self.rewriter.improve(prompt, feedback)
return video, prompt
这种迭代过程在离散提示空间中进行引导搜索,评估反馈起到"文本梯度"的作用,将提示工程从手动试错转变为系统性、数据驱动的闭环优化过程。
3.2 动态评估模型组(Dynamic Critic Model Team): 多维度物理评估
传统指标(如FVD、PSNR、SSIM)虽能评估视觉保真度,却无法衡量物理真实性。WoW构建了专用评估器,通过在"机器人操作真实与模型生成视频的问答数据集"上微调VLM,从五个关键维度测试模型理解:
五大评估维度详解:
| 维度 | 评估内容 | 评分标准 | 权重 |
|---|---|---|---|
| 任务完成度 | 机器人是否完成了指定任务 | 0-100% | 30% |
| 动作成功率 | 各个动作步骤是否执行成功 | 成功步骤/总步骤 | 25% |
| 交互物理合理性 | 稳定性、形变等是否符合物理规律 | 1-5分 | 20% |
| 运动学平滑度 | 运动轨迹是否自然流畅 | 加速度变化率 | 15% |
| 整体质量 | 视频的整体视觉与语义质量 | 1-5分 | 10% |
评估器的训练数据:
训练数据构成:
├── 真实机器人操作视频 (正样本)
│ └── 标注: 物理正确、任务成功
├── 模型生成的好视频 (正样本)
│ └── 标注: 物理正确、任务成功
├── 模型生成的坏视频 (负样本)
│ └── 标注: 具体错误类型和位置
└── 人工合成的错误视频 (负样本)
└── 标注: 注入的具体错误
问答格式示例:
Q: 在这段视频中,机器人是否成功完成了"拿起杯子"的任务?
A: 否,机器人未能成功完成任务。在第18帧,夹爪闭合时未能正确对准杯子把手,
导致杯子滑落。
Q: 视频中是否存在物理违规?
A: 是,在第35-40帧,机械臂穿透了桌面表面,这违反了固体不可穿透的物理规律。
Q: 机器人的运动是否平滑?
A: 运动基本平滑,但在第22帧存在明显的速度突变,可能导致实际执行时的机械冲击。
3.3 闭环生成工作流: 完整流程详解
系统将优化智能体与动态评估模型集成到闭环工作流中:
用户高阶指令 → 优化智能体扩展为详细提示 → WoW生成候选视频
↓
动态评估模型评估
↓
[未完成/失败?]
↙ ↘
是 否
↓ ↓
结构化反馈 返回最终视频
↓
优化提示,进入下一周期
完整工作流实例:
用户输入: "把桌子上的红色杯子放到架子上"
第1轮:
├── 提示扩展: "场景:木质桌子上有一个红色陶瓷杯子..."
├── 视频生成: 生成41帧视频
├── 评估结果:
│ ├── 任务完成度: 60% (杯子被拿起但未放置)
│ ├── 物理合理性: 3/5 (轻微穿透)
│ └── 反馈: "在第28帧,夹爪穿透杯子边缘"
└── 决策: 需要重新生成
第2轮:
├── 优化提示: 添加"夹爪应从杯子把手侧接近,避免接触杯体"
├── 视频生成: 重新生成
├── 评估结果:
│ ├── 任务完成度: 85% (放置位置略有偏差)
│ ├── 物理合理性: 4/5 (无明显违规)
│ └── 反馈: "放置时杯子倾斜角度过大"
└── 决策: 需要微调
第3轮:
├── 优化提示: 添加"放置时保持杯子垂直"
├── 视频生成: 重新生成
├── 评估结果:
│ ├── 任务完成度: 98%
│ ├── 物理合理性: 5/5
│ └── 反馈: "任务成功完成"
└── 决策: 返回最终视频
迭代次数与质量的关系:
| 迭代次数 | 平均任务完成率 | 平均物理合理性 | 计算成本 |
|---|---|---|---|
| 1 | 45% | 3.2/5 | 1× |
| 2 | 72% | 4.1/5 | 2× |
| 3 | 89% | 4.6/5 | 3× |
| 5 | 94% | 4.8/5 | 5× |
实验表明,3次迭代通常能达到较好的质量-成本平衡。
4. 流掩码逆动力学模型: FM-IDM
…详情请参照古月居

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献155条内容
已为社区贡献155条内容

所有评论(0)