YOLO-Master 震撼来袭 | 用 MoE 让 YOLO 家族 Great Again!
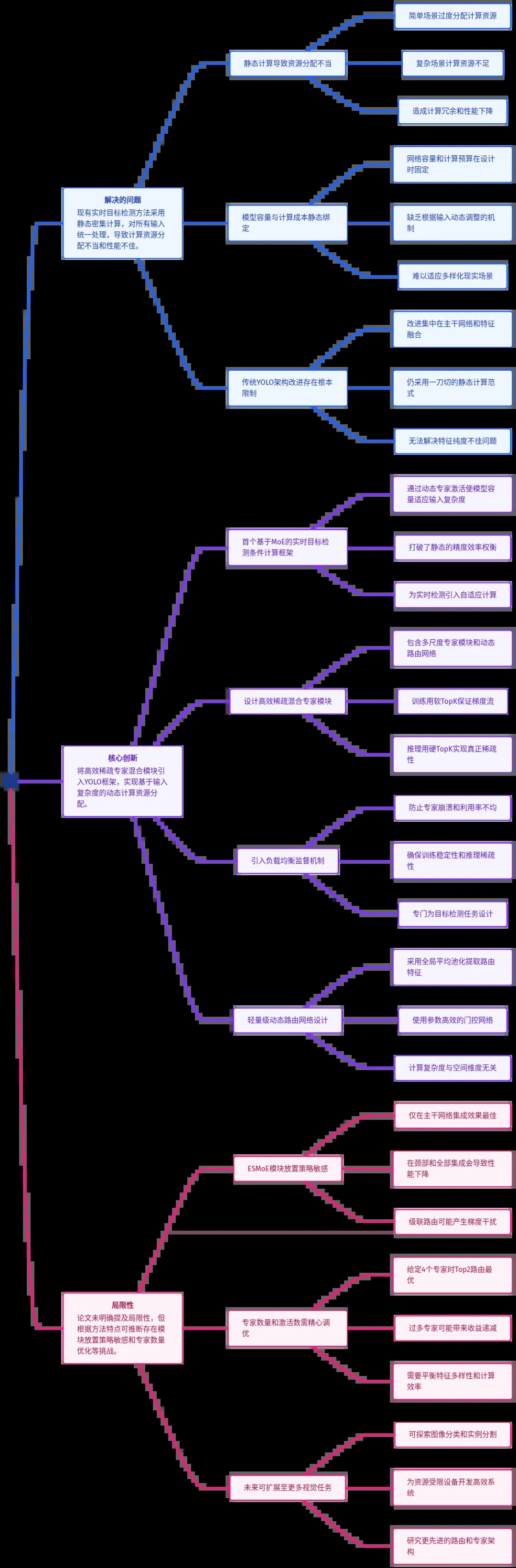
YOLO-Master通过动态计算机制革新实时目标检测,解决了传统YOLO模型静态计算的效率问题。其核心创新ES-MoE模块能根据场景复杂度智能分配计算资源:轻量级路由网络选择最相关的少数专家处理输入,其余专家保持休眠。实验表明,该方法在MSCOCO等数据集上实现精度提升(最高+2.1%)的同时降低延迟17.8%,且适用于分类、分割等任务。关键设计包括:将动态模块前置到Backbone、Top-2
你是否还在为YOLO模型“一视同仁”的计算方式而苦恼?简单场景浪费算力,复杂场景又力不从心。一个拥挤的十字路口和一片空旷的田野,凭什么消耗同样的计算资源?今天,一项名为YOLO-Master的技术,正通过给模型装上“动态大脑”,从根本上改写实时目标检测的游戏规则。

为什么你的YOLO模型总在“浪费算力”?
想象一下,你部署在自动驾驶汽车上的目标检测模型,正以每秒60帧的速度处理视频流。在空旷的高速公路上,画面里只有寥寥几辆汽车和远处的路牌——这明明是个“简单题”,但你的模型却动用了100%的计算单元,疯狂运转。
下一秒,车辆驶入繁华的市中心十字路口。行人、自行车、公交车、交通标志、红绿灯……数十个目标挤在同一个画面里,尺度各异、相互遮挡。这时,模型的计算资源却没有丝毫增加,依然在用处理“简单题”的算力,硬扛这个“地狱级难题”。结果可想而知:小目标漏检、遮挡目标误判、定位精度下降。
这就是当前所有类YOLO实时检测器面临的根本性困境:静态密集计算。
无论输入图像是简单还是复杂,模型都沿着完全相同的网络路径,激活完全相同数量的神经元。这种“一刀切”的设计,导致了双重低效:
-
简单场景过度计算:算力被白白浪费在无关紧要的特征上;
-
复杂场景资源不足:模型容量遇到瓶颈,性能无法突破。
更糟糕的是,这种静态性被固化在了模型架构中。从YOLOv1到最新的v13,每一次迭代都在优化网络结构、改进训练策略,但模型的总计算预算和容量在训练前就已固定。它就像一个只能以固定功率运行的引擎,无法根据路况自动调节。
但为什么99%的优化尝试都失败了?关键在于,我们一直在为这个“固定功率引擎”更换更好的零件,却从未想过给它装上一个能感知路况、动态调节的“智能油门”。
一张图看懂YOLO-Master的“动态大脑”
YOLO-Master的突破,就在于它不再使用“固定功率引擎”,而是为模型植入了一个实例条件自适应计算的“动态大脑”。其核心是一个名为高效稀疏专家混合(ES-MoE) 的模块,它能让模型根据当前输入图像的复杂度,智能地、动态地分配计算资源。
简单来说,ES-MoE模块内部有一群各有所长的“专家”(例如,有的擅长识别大物体,有的专精捕捉小目标)。面对每张输入图片,一个轻量级的“路由网络”会快速分析场景,然后只唤醒最相关的少数几位专家来工作,其他专家则保持“休眠”以节省算力。
为了帮你快速把握全局脉络,我们先看这张核心架构思维导图——
这张图揭示了YOLO-Master的智慧所在:将动态计算机制前置到特征提取的源头(Backbone),而非后期的特征融合阶段(Neck)。实验证明,这是性能提升的关键。接下来,我们逐层拆解这张图中的每个关键模块,看看这个“动态大脑”究竟是如何工作的。
互动思考:你认为动态计算机制应该放在网络的早期、中期还是晚期?为什么?欢迎在评论区留下你的初步想法!
ES-MoE模块如何实现“智能调度”
模块概览:从静态到动态的范式转变
传统的YOLO检测器,其Backbone和Neck中的每一个卷积块都是静态的、必须被执行的。YOLO-Master则在其中插入了ES-MoE模块来替代部分关键卷积块。
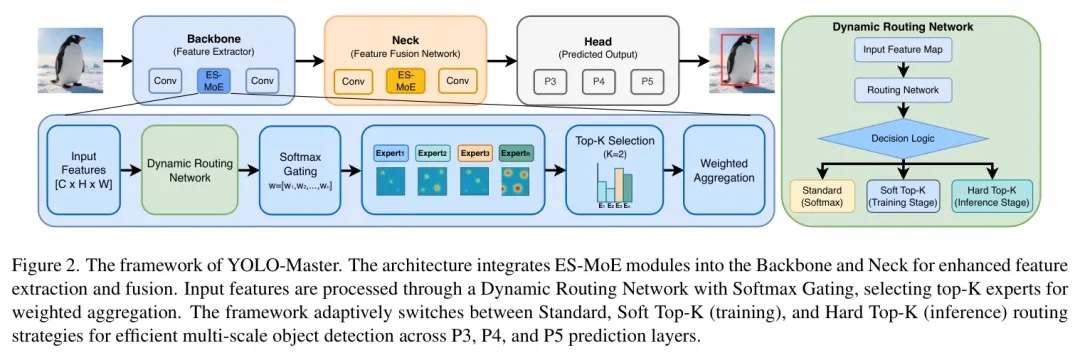
给定输入特征图 ,ES-MoE模块的工作流程可以概括为三步:
-
路由决策:轻量级路由网络分析 ,生成一个“专家能力评分榜”。
-
专家选择:根据评分,仅激活排名前 位的专家(, 为专家总数)。
-
结果聚合:将激活的专家们的输出,按其评分权重进行加权融合,得到增强后的特征 。
整个过程的核心公式清晰地描述了这一机制:
其中, 表示被选中的前 个专家的索引集合, 是路由网络为第 个专家分配的权重, 是用于稳定训练的归一化操作。
这就好比一个高级会诊:病人(输入图像)来了,分诊台(路由网络)快速判断病情复杂度,然后只呼叫最对口的几位专家(个专家)进行会诊,而不是让全院所有医生(个专家)都来围观。效率自然大幅提升。
专家设计:高效且多样的“专科医生”
那么,这些“专家”本身是如何设计的呢?为了满足实时检测的严苛速度要求,每个专家都必须极其高效。
高效架构:每个专家 的核心是一个深度可分离卷积(DWConv)。与标准卷积相比,DWConv将空间滤波和通道混合解耦,能大幅减少参数和计算量(FLOPs)。这确保了即使专家总数 较多,整体计算开销依然可控。
多样化感受野:为了让专家们“术业有专攻”,作者赋予他们不同的“视野范围”。每个专家的DWConv使用不同的卷积核大小 ,例如 , , 。这样,有的专家擅长捕捉局部细节(小感受野),有的专家善于理解上下文关系(大感受野)。路由网络可以根据图像中目标的尺度分布,智能地组合不同“视野”的专家。
路由网络:轻量而精准的“调度中心”
路由网络是整个动态系统的“大脑”,它必须快速且准确地做出决策。它的设计遵循一个核心原则:决策基于全局语义,而非局部细节。
-
信息聚合:首先,通过全局平均池化(GAP) 将整个特征图 压缩为一个全局描述符 。这相当于让模型“扫一眼”整体画面,把握全局复杂度。
-
轻量计算:然后将 输入一个超轻量的门控网络 。 仅由两个 卷积层构成,中间通过一个SiLU激活函数连接。为了进一步压缩计算,作者引入了通道缩减率 ,大幅降低了中间层的通道数。
整个路由决策的计算与特征图的空间大小 无关,只取决于通道数 和专家数 。这意味着即使处理高分辨率特征图,路由开销也微乎其微,完美契合实时需求。
分阶段路由:训练稳定与推理高效的秘诀
这是YOLO-Master设计中最精妙的一环。如何在训练时让所有专家都充分学习,又在推理时保持极高的计算稀疏性?
训练阶段:软Top-K路由
在训练时,路由网络为所有专家生成权重,但只保留前 个最大的权重,其余置零,然后再对这 个权重进行归一化。关键点在于,这个“选择-归一化”的过程是可微分的,梯度可以通过被选中的专家权重,回传到路由网络和所有专家网络。这确保了:
-
梯度流通:所有专家,即使某次未被激活,也能通过权重竞争间接获得梯度,避免“专家崩溃”(某些专家永远学不到东西)。
-
鼓励专业化:路由网络在训练中学会区分不同专家的特长,形成互补。
推理阶段:硬Top-K路由
在部署时,模型切换到“硬”模式。直接根据路由分数选出Top-K个专家,只执行这 个专家的前向计算,其余专家的计算被完全跳过。这实现了真正的计算稀疏化,带来了显著的推理加速。
这种“训练用软,推理用硬”的分阶段策略,是平衡学习效果与运行效率的黄金法则。
负载均衡损失:防止“明星专家”垄断
在MoE训练中,一个常见问题是路由网络会倾向于将所有输入都路由给初期表现较好的少数几个“明星专家”,导致其他专家被“饿死”。为了解决这个问题,YOLO-Master引入了一个负载均衡损失 。
这个损失函数会计算每个专家在训练批次中的平均被激活率 ,然后惩罚其与理想均匀分布 的偏差:
通过将这个损失与标准的YOLO检测损失 加权结合:
模型被强制要求“雨露均沾”,确保所有专家都能得到充分的训练,从而最大化整个专家池的多样性和表达能力。
实战思考:负载均衡损失中的超参数 设置非常微妙:太大可能损害检测精度,太小则无法平衡专家负载。在你的项目中,你会如何设计实验来确定这个值?
数据不说谎,动态计算就是强
理论再美妙,也需要数据支撑。YOLO-Master在五个极具挑战性的基准数据集上进行了全面测试,结果令人振奋。
SOTA对比:全面领先,效率兼得
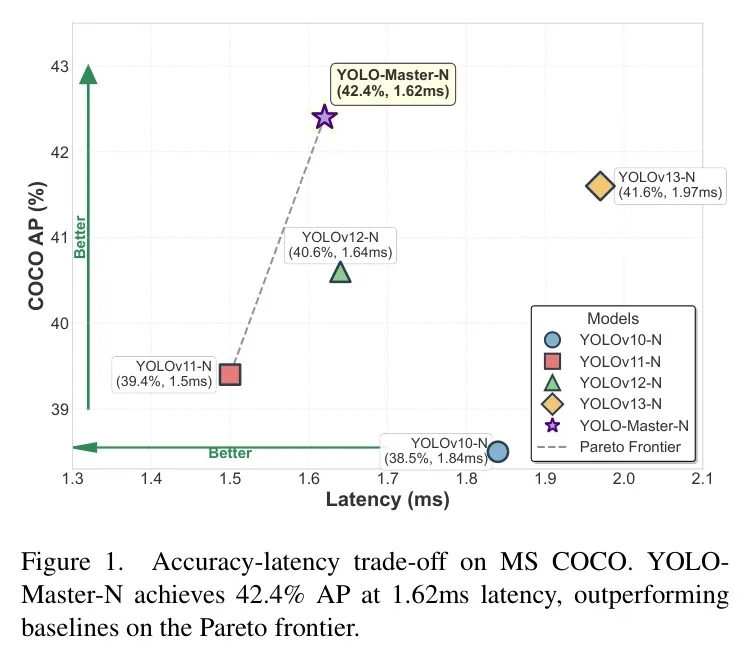
我们以最常用的MS COCO数据集为例。YOLO-Master-Nano版本在取得 42.4% mAP的同时,推理延迟仅为 1.62毫秒。
这意味着什么?与同期优秀的YOLOv13-N相比,YOLO-Master-N 精度高出0.8%,同时推理速度快了17.8%!真正做到了“又快又好”。
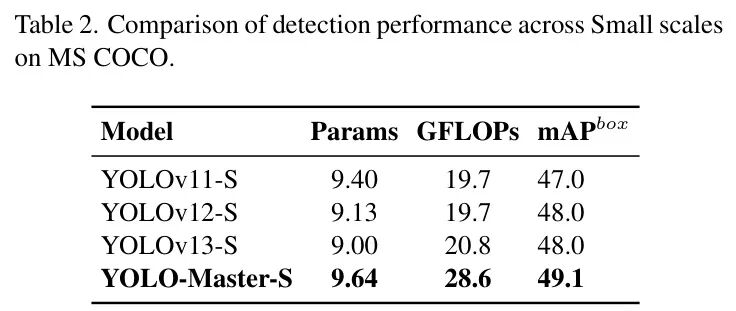
图:在MS COCO上的检测性能对比。YOLO-Master在参数量(Params)相近的情况下,实现了更高的mAP和更快的速度(更高FPS)
这种优势在复杂场景下更为显著。在目标密集的VisDrone(无人机视角)和KITTI(自动驾驶)数据集上,YOLO-Master的精度提升分别达到了 +2.1% 和 +1.5%。这直接验证了其动态分配资源的能力:在面对大量小目标或复杂场景时,模型能够自动分配更多“专家”资源,从而获得更优的性能。
消融实验:关键设计的深度剖析
1. ES-MoE模块放在哪里?
这是决定成败的关键决策。作者进行了详尽的消融实验:
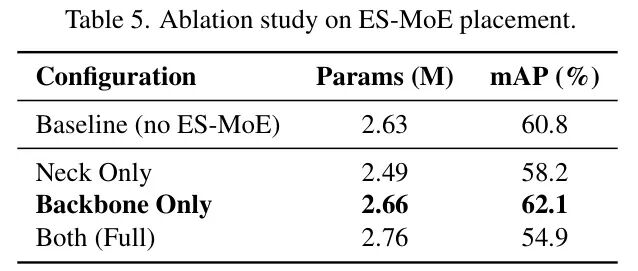
图:ES-MoE模块不同放置策略的消融实验。仅插入Backbone效果最佳,同时插入Backbone和Neck会导致性能严重下降
结果一目了然:
-
• 仅插入Backbone:性能最佳(mAP 62.1%),相比基线提升1.3%。这证实了在特征提取源头进行动态计算的重要性。
-
• 仅插入Neck:效果不佳(mAP 58.2%)。因为Neck处理的是Backbone提取后的特征,如果Backbone是静态的,提取的特征本身缺乏多样性,Neck的路由机制也难以发挥。
-
• 同时插入两者:性能严重下降(mAP 54.9%)。原因是Backbone和Neck的路由网络在训练时会产生冲突的梯度,相互干扰,导致训练不稳定。
这个实验给出了一个至关重要的设计准则:动态计算机制,应尽可能前置。
2. 每次激活几个专家(K值)?
在总专家数 的情况下,作者测试了不同的 值。
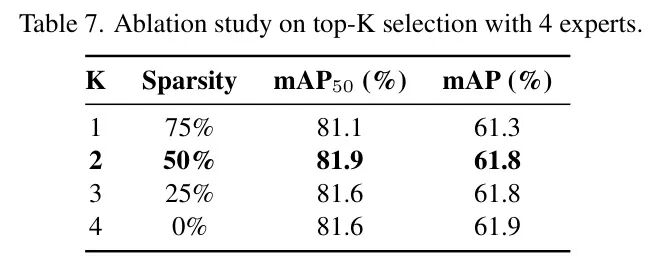
图:Top-K选择中不同K值的性能对比。K=2时达到最优权衡
结果显示,K=2(稀疏率50%)时达到最优性能。K=1时能力不足,K=3或4时性能不再提升且计算增加。这说明,两个互补的专家协同工作,足以应对大多数场景,是效率与精度的最佳平衡点。
3. 泛化到其他视觉任务
更令人惊喜的是,YOLO-Master的“动态大脑”不仅适用于检测。
- • 图像分类:在ImageNet上,YOLO-Master-clsN的Top-1准确率达到76.6%,比YOLOv12高出4.9%。
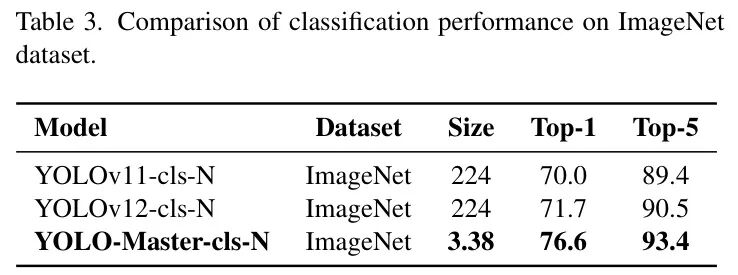
图:在ImageNet分类任务上的性能对比,显示其强大的特征提取能力 - • 实例分割:在分割任务上,其Mask mAP达到35.6%,比基线提升2.8%。
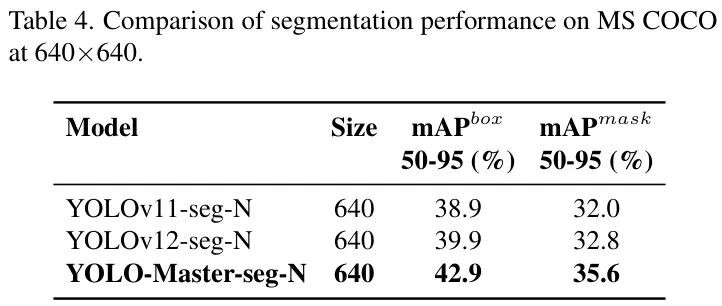
图:在实例分割任务上的性能提升,证明其定位和掩码预测能力同步增强
这些跨任务的卓越表现,证明YOLO-Master的ES-MoE设计是一个通用的、强大的视觉架构改进,其“动态稀疏计算”的思想具有广泛的推广价值。
客观评价
当然,没有任何技术是完美的。YOLO-Master在带来显著性能提升的同时,也需要我们客观看待其挑战:
-
训练复杂度:引入MoE机制后,训练过程需要精心设计负载均衡损失,并可能需要对超参数(如 )进行调优,这增加了训练阶段的复杂性。
-
路由决策开销:虽然路由网络本身很轻量,但在一些极端追求吞吐量的场景下,其额外的计算分支和条件判断,可能成为潜在的瓶颈,需要针对特定硬件进行深度优化。
-
理论理解:动态稀疏网络的行为比静态网络更难以从理论上完全分析。为什么某个专家会被特定场景激活?其可解释性仍需进一步研究。
然而,这些挑战并不能掩盖其开创性的价值。它成功地将大语言模型中成熟的MoE范式,移植到了对计算效率要求极高的实时视觉任务中,并取得了突破性成果,这本身就是一项了不起的成就。
价值升华与行动号召
回顾全文,YOLO-Master为我们带来了三个核心启示:
-
从“静态架构”到“动态计算”:它证明了为视觉模型赋予根据输入内容动态调整计算资源的能力,是突破现有精度-效率权衡的关键路径。
-
“稀疏激活”是高效的源泉:通过轻量级路由智能选择专家子集,实现了计算量的按需分配,在保持甚至提升精度的同时大幅降低平均计算成本。
-
设计需要系统性思维:成功的关键不在于简单堆砌MoE模块,而在于对放置位置、路由策略、损失函数等进行系统性的协同设计。
这项技术最吸引你的地方是什么?是它在密集小目标场景下显著的性能提升,还是其“一次训练,动态推理”的优雅思想?
深度思考:你认为YOLO-Master所代表的“动态稀疏计算”范式,最可能率先在哪个AI应用场景中大规模落地?是自动驾驶的复杂环境感知,无人机巡检中的小目标检测,还是移动端AR的实时物体识别?欢迎在评论区留下你的观点!
支持原创:如果这篇近5000字的深度解读帮你彻底理解了YOLO-Master的精髓,点赞+在看就是对我最大的支持!分享给你的技术伙伴,一起探讨AI模型的未来!
关注提醒:点击右上角设为星标,第一时间获取更多颠覆性的AI技术深度解读!
参考
YOLO-Master: MOE-Accelerated with Specialized Transformers for Enhanced Real-time Detection

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)