使用SPEC-KIT
传统软件开发中,“代码为王”,规格说明书(Specs)往往只是开发的脚手架,写完代码就丢弃了。Spec Kit 颠覆了这一点:规格说明书不再是文档,而是可执行的蓝图。先定义“做什么”(What)和“为什么”(Why),再由 AI 处理“怎么做”(How)。不再一次性通过 Prompt 生成代码,而是通过多个步骤(原则 -> 规格 -> 计划 -> 任务 -> 实现)逐步细化。创建项目的“宪法”(C
github仓库地址:github/spec-kit: 💫 Toolkit to help you get started with Spec-Driven Development
b站视频P:用SPEC-KIT告别低效的AI编程_哔哩哔哩_bilibili
介绍
1. 核心理念:什么是规格驱动开发 (SDD)?
传统软件开发中,“代码为王”,规格说明书(Specs)往往只是开发的脚手架,写完代码就丢弃了。 Spec Kit 颠覆了这一点:
-
规格即代码: 规格说明书不再是文档,而是可执行的蓝图。
-
意图优先: 先定义“做什么”(What)和“为什么”(Why),再由 AI 处理“怎么做”(How)。
-
多步精炼: 不再一次性通过 Prompt 生成代码,而是通过多个步骤(原则 -> 规格 -> 计划 -> 任务 -> 实现)逐步细化。
2. 核心工作流程 (The Process)
Spec Kit 定义了一套严格的交互式开发流程,通过一组 Slash Commands(斜杠命令) 来驱动 AI Agent 完成开发。
第一阶段:准备 (Setup)
-
安装工具: 使用
uv(Python 包管理器)安装specify-cli。 -
初始化项目: 使用
specify init <项目名> --ai <你的AI助手>初始化。它支持 Claude, Gemini, Copilot, Cursor 等多种 Agent。
第二阶段:定义原则 (Principles)
-
命令:
/speckit.constitution -
作用: 创建项目的“宪法”(Constitution)。这是项目的治理原则,定义了代码质量标准、测试规范、UI 一致性要求等。
-
意义: 所有的后续开发都会基于这些原则,确保 AI 不会“放飞自我”。
第三阶段:编写规格 (Spec)
-
命令:
/speckit.specify -
作用: 描述你要构建的功能(User Stories 和功能需求)。
-
关键点: 此时不涉及技术栈(不谈 React, Python 等),只谈业务逻辑和用户价值。
第四阶段:澄清与计划 (Clarify & Plan)
-
命令:
/speckit.clarify(可选但推荐)-
AI 会反问你一些模糊不清的需求,通过问答完善规格。
-
-
命令:
/speckit.plan-
技术决策: 此时才指定技术栈(例如:使用 Vite, SQLite, Vanilla JS)。
-
AI 会生成详细的技术实现计划、数据模型、API 规范等文档。
-
第五阶段:任务拆解 (Breakdown)
-
命令:
/speckit.tasks-
将计划转化为可执行的、细颗粒度的任务列表(Tasks)。
-
包含依赖关系管理(先写 Model 再写 Service)和并行开发标记。
-
包含测试驱动开发(TDD)的步骤。
-
第六阶段:执行 (Execution)
-
命令:
/speckit.implement-
AI 根据生成的任务列表,一步步自动执行代码编写、文件创建和测试。
-
3. 技术生态与支持
Spec Kit 的设计非常灵活,不绑定特定的 AI 模型,而是作为中间层(Tooling/Framework)存在。
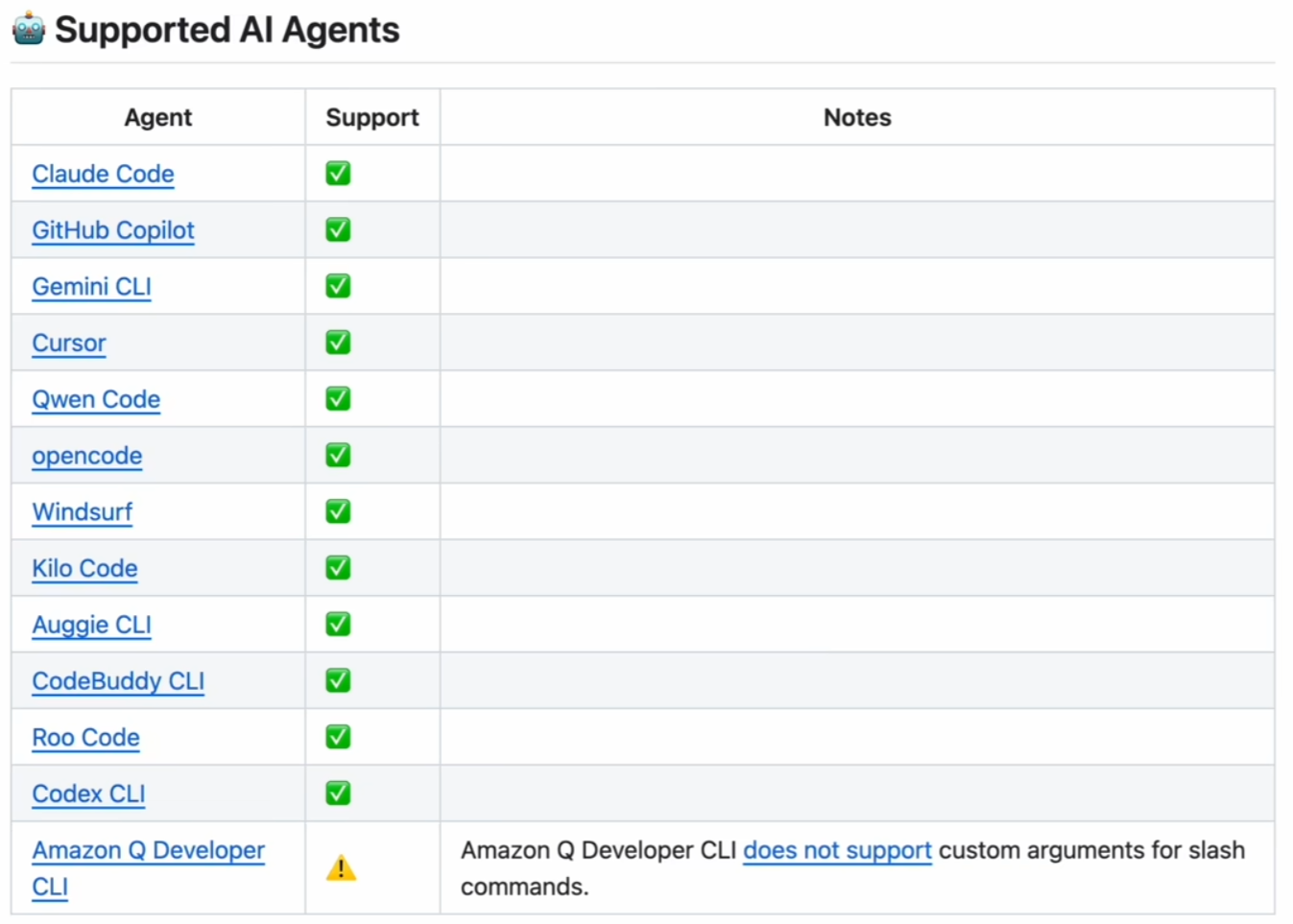
-
支持的 AI Agent:
-
CLI 类: Claude Code, Gemini CLI, GitHub Copilot CLI, Amazon Q Developer CLI 等。
-
IDE 类: Cursor, Windsurf, VS Code (Copilot)。
-
其他: Qwen Code, DeepSeek (通过通用接口) 等。
-
-
环境要求:
-
Python 3.11+
-
uv包管理器 -
Git
-
4. 适用场景 (Development Phases)
文档提到了两种主要开发模式:
-
从 0 到 1 (Greenfield):
-
从头开始生成应用。
-
适合快速原型开发、探索不同的技术栈(比如用同一套 Spec 让 AI 分别用 React 和 Vue 实现一遍做对比)。
-
-
已有项目改造 (Brownfield):
-
迭代式增加新功能。
-
遗留系统现代化改造。
-
5. 总结:Spec Kit 解决了什么痛点?
-
消除“幻觉”与不可控: 通过
/speckit.constitution和分步计划,限制 AI 的随机性,使其输出符合工程标准的代码。 -
上下文管理: Spec Kit 自动维护
.specify目录下的文档(spec.md, plan.md, tasks.md),让 AI 始终拥有完整的项目上下文,而不是仅仅依赖对话历史。 -
工程化落地: 它不仅仅是写代码,还包含了需求分析、架构设计、任务拆解和测试,这是一个完整的软件工程闭环。
一句话总结: Spec Kit 是一个让 AI 从“聊天机器人”变成“初级软件工程师”的标准化管理框架,它用结构化的文档(Spec)取代了随意的对话(Chat)。
实战
安装
windows 安装uv
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"注意本地python需要大于等于11
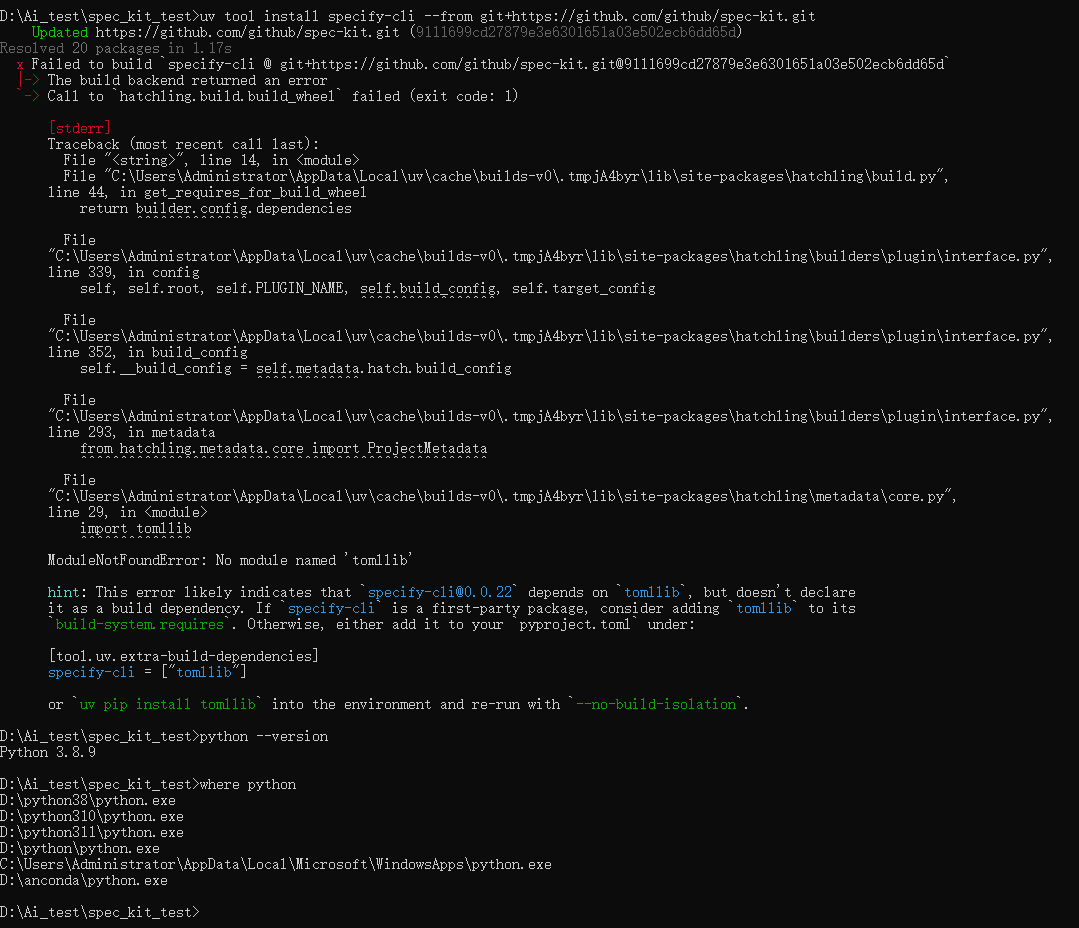
uv python install 3.12
uv tool install specify-cli --from git+https://github.com/github/spec-kit.git --python 3.12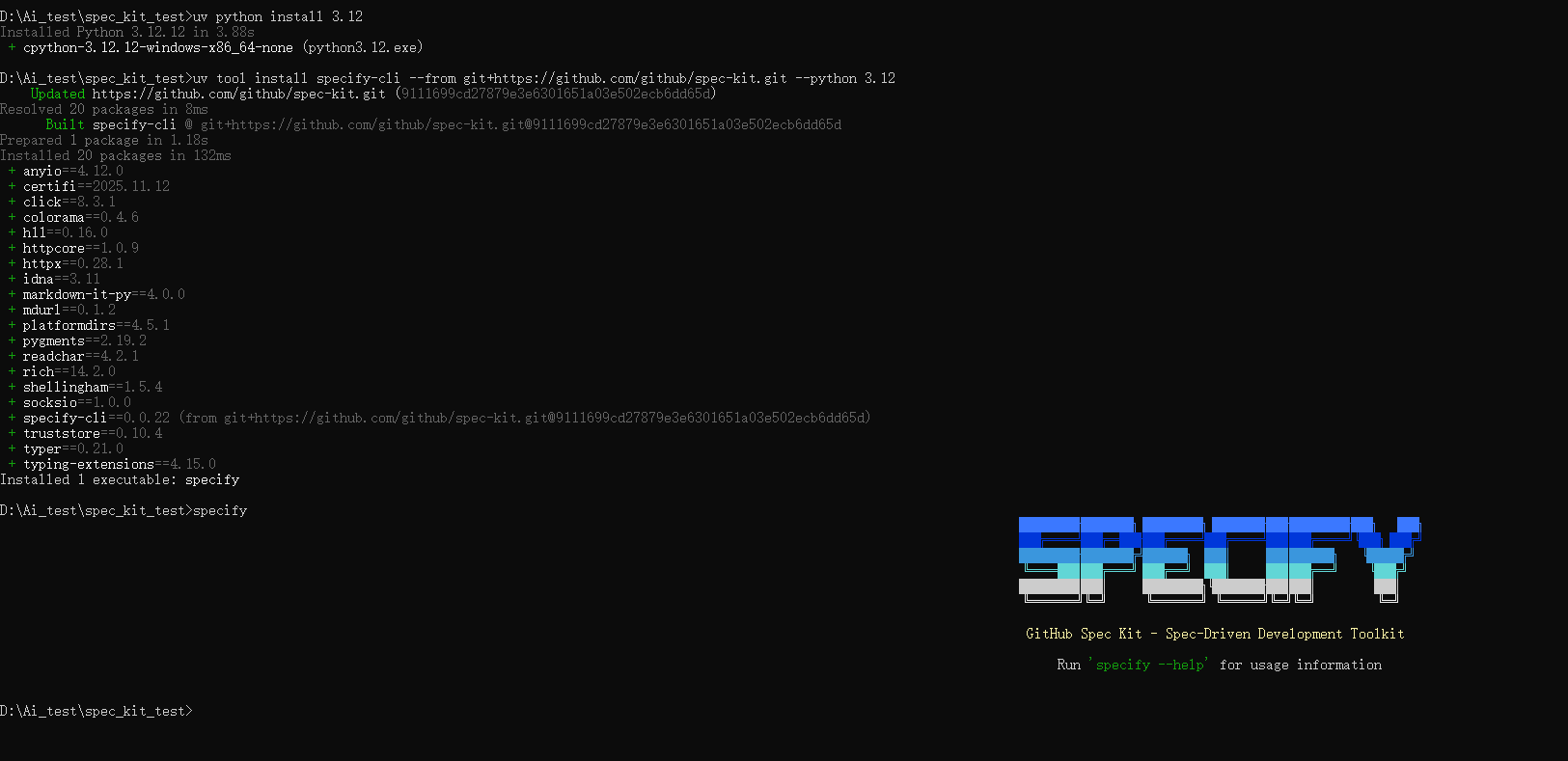
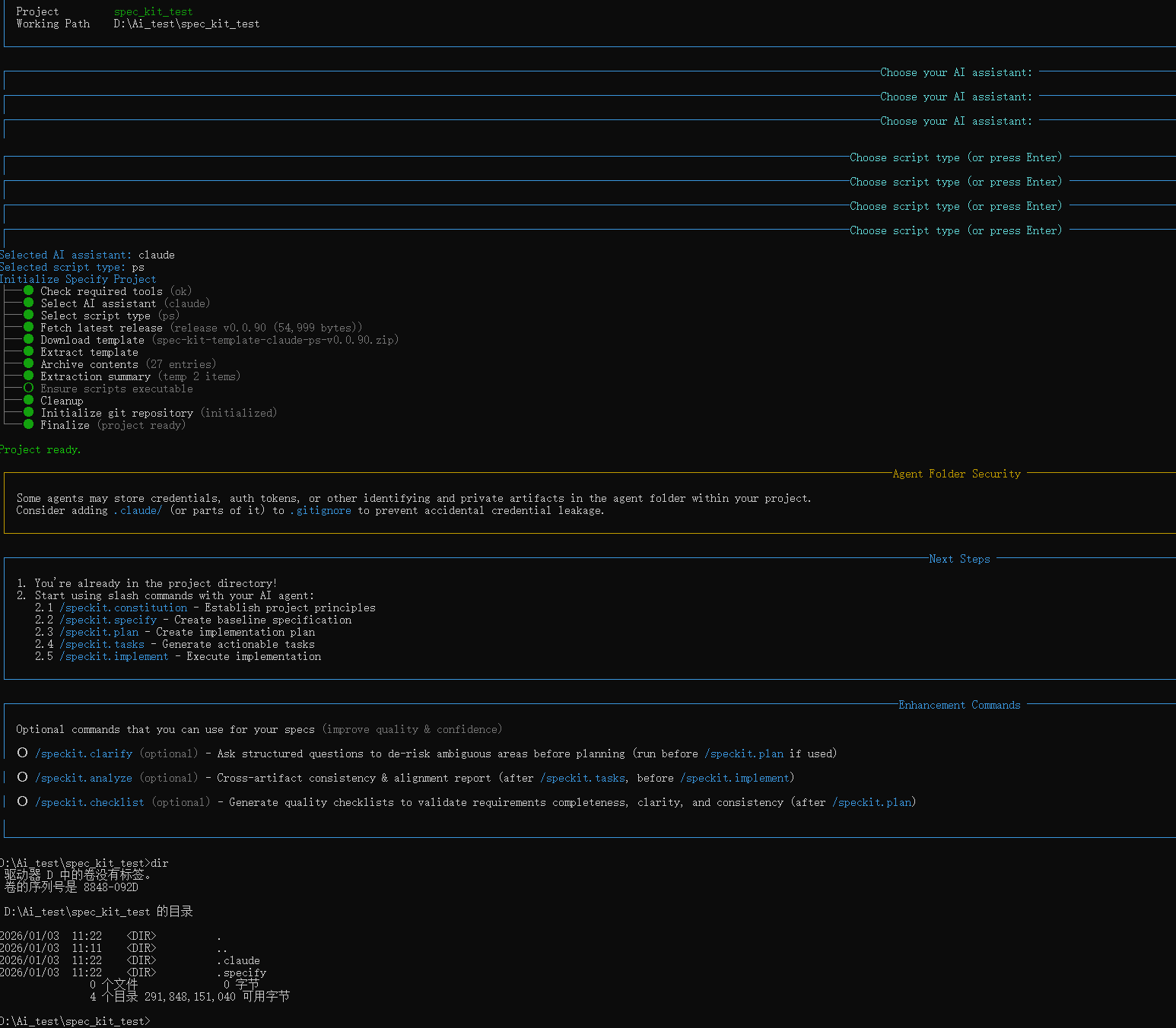
项目初始化
specify
specify init --here
选择了claude code,windows 适合使用ps powershell
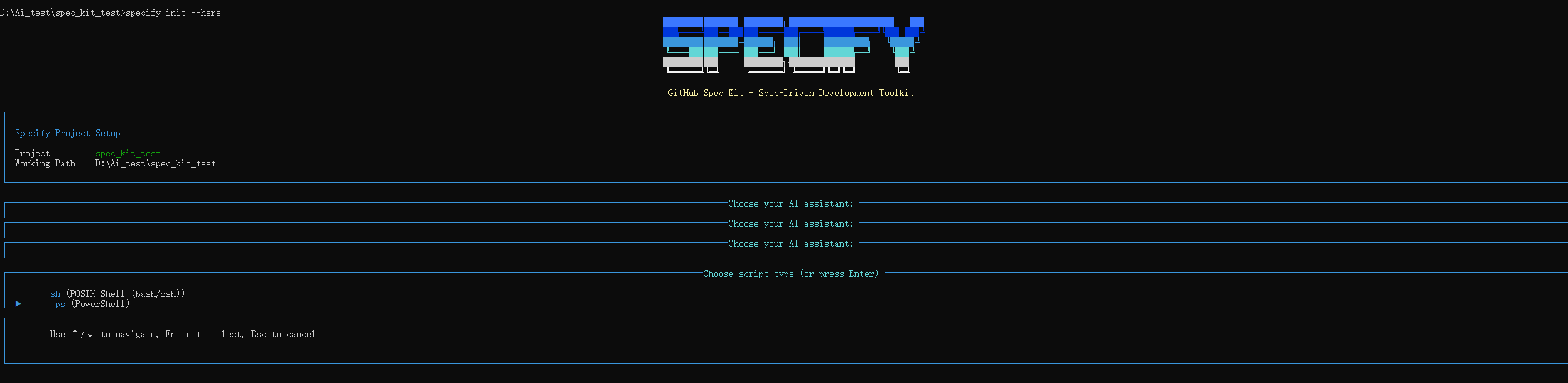
完成初始化,会在项目中自动创建一些文件
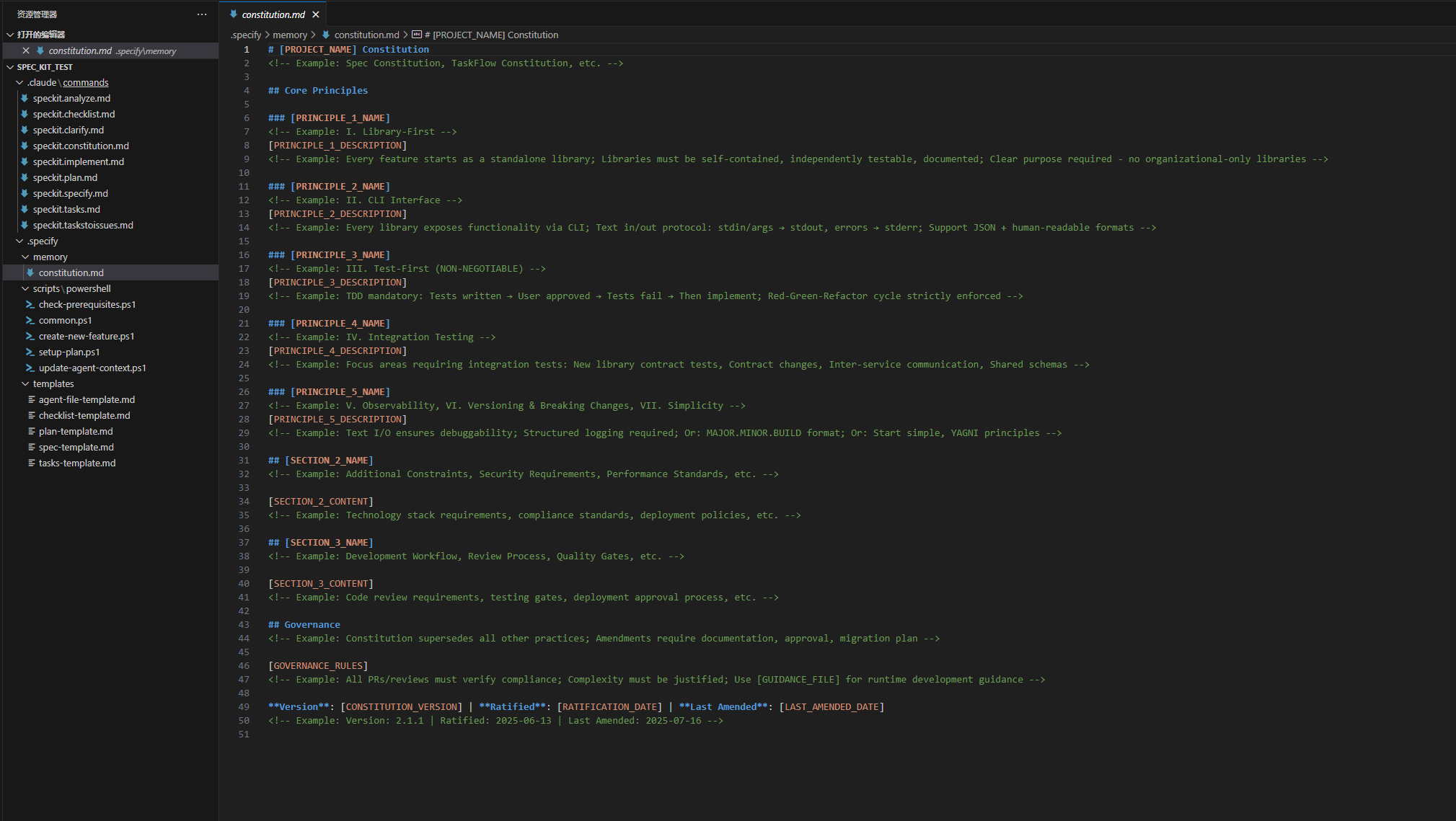
spec_kit_test/
├─ .claude/
│ └─ commands/
│ ├─ speckit.analyze.md
│ ├─ speckit.checklist.md
│ ├─ speckit.clarify.md
│ ├─ speckit.constitution.md
│ ├─ speckit.implement.md
│ ├─ speckit.plan.md
│ ├─ speckit.specify.md
│ ├─ speckit.tasks.md
│ └─ speckit.taskstoissues.md
├─ .git/
│ ├─ hooks/
│ ├─ info/
│ ├─ logs/
│ ├─ objects/
│ └─ refs/
└─ .specify/
├─ memory/
│ └─ constitution.md
├─ scripts/
│ └─ powershell/
│ ├─ check-prerequisites.ps1
│ ├─ common.ps1
│ ├─ create-new-feature.ps1
│ ├─ setup-plan.ps1
│ └─ update-agent-context.ps1
└─ templates/
├─ agent-file-template.md
├─ checklist-template.md
├─ plan-template.md
├─ spec-template.md
└─ tasks-template.md
目录用途概览
- .claude/:Claude/Codex 的命令模板集合;commands/ 里的各个 speckit.*.md 是不同工作流步骤的指令或提示模板。
- .git/:Git 版本控制元数据(hooks、refs、objects 等);通常不手动改动。
- .specify/:spec‑kit 的核心资源目录
- memory/:项目“宪法/原则/约定”等长期记忆与规范。
- scripts/powershell/:辅助脚本(环境检查、创建新特性、建立计划、更新 agent 上下文等)。
- templates/:规范化输出模板(spec、plan、tasks、checklist、agent file 等)。
定义原则
启用claude code 发现其中引入了许多spec-kit slash命令
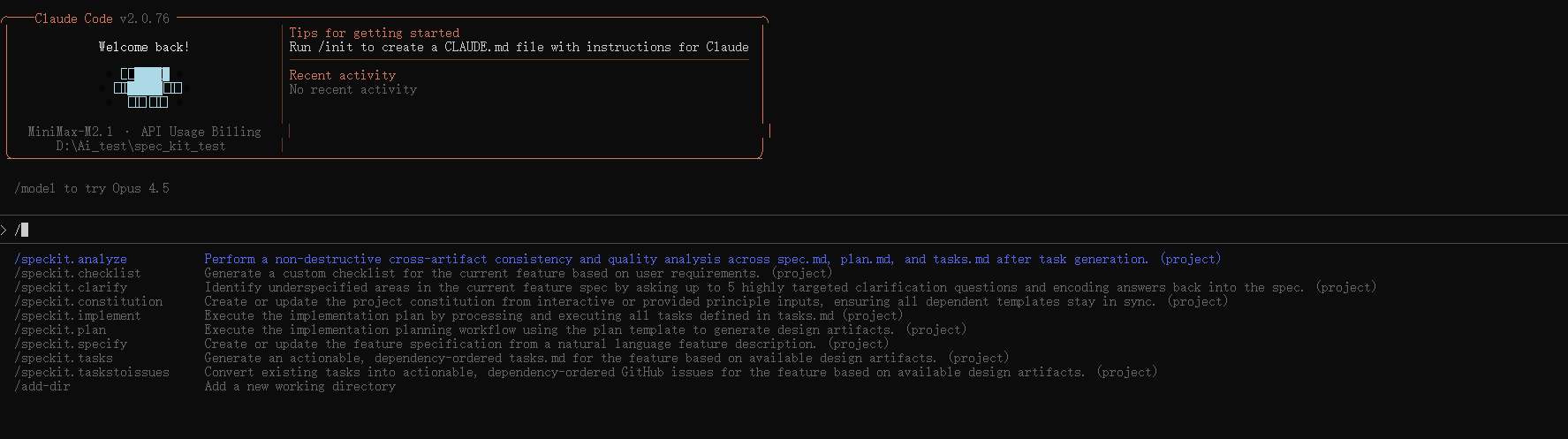
/speckit.constitution Create principles focused on code quality, testing standards, user experience consistency, and performance requirements1. /speckit.constitution 是干什么的?
这个命令的作用是给 AI 立规矩,也就是制定项目的“宪法”或“基本法”。
-
它的核心作用: 它会创建一个文件(
.specify/memory/constitution.md),里面记录了你对这个项目的所有非功能性要求。 -
为什么重要? 在随后的每一个开发步骤(写代码、做计划、拆解任务)中,AI 都会被迫回头查阅这个“宪法”。如果你不立规矩,AI 可能会“随性发挥”(比如有时写注释有时不写,或者用你不喜欢的代码风格)。
你可以把它理解为技术总监(你)给初级程序员(AI)下达的《开发规范手册》。
2. 可以用自定义中文写吗?
完全可以,而且效果通常更好。
底层的 AI 模型(如 Claude、GPT-4 等)对中文的理解能力非常强。用中文描述你的需求,往往比用生硬的英文更能准确传达你的意图。
3. 中文指令示例
你可以直接将原文的英文提示词替换为具体的中文要求。例如:
你可以这样输入:
/speckit.constitution 请制定项目的开发原则。核心要求包括:1. 代码质量:所有复杂的逻辑必须有清晰的中文注释,变量命名需符合驼峰命名法。2. 测试标准:每个核心函数必须配备单元测试 (Pytest)。3. 性能:数据库查询必须优化,避免 N+1 问题。4. UI风格:保持极简风格,类似 Ant Design。
执行后发生的事情:
-
AI 会理解这段中文。
-
它会在
.specify/memory/constitution.md文件中生成一份结构化的文档(可能是英文的,也可能是中文的,取决于 AI 的习惯,但内容会通过你的要求来约束它)。 -
以后你让它写代码时,它就会记得“哦,老板说过要写中文注释”和“要避免 N+1 问题”

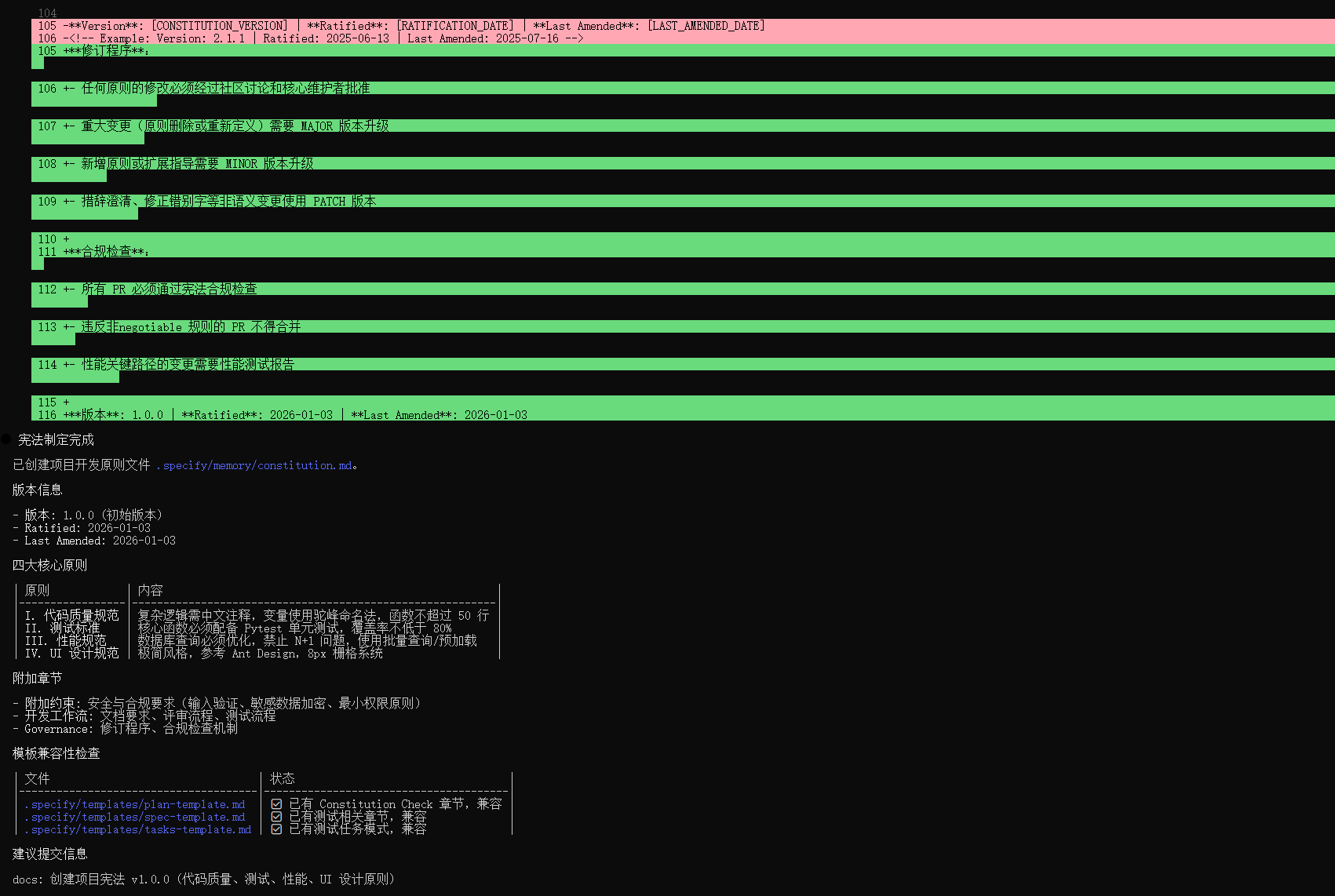
重写后的constitution.md文档
<!--
Sync Impact Report
==================
Version change: N/A → 1.0.0 (Initial creation)
Added principles:
- I. 代码质量规范 (Code Quality Standards)
- II. 测试标准 (Testing Standards)
- III. 性能规范 (Performance Standards)
- IV. UI 设计规范 (UI Design Standards)
Added sections:
- 附加约束 (Additional Constraints) - 安全与合规要求
- 开发工作流 (Development Workflow) - 文档、评审、测试流程
Templates requiring updates:
- .specify/templates/plan-template.md: ✅ Constitution Check section already present
- .specify/templates/spec-template.md: ✅ Already aligned with testing requirements
- .specify/templates/tasks-template.md: ✅ Already includes test task patterns
-->
# Spec Kit Constitution
## Core Principles
### I. 代码质量规范 (Code Quality Standards)
所有复杂的业务逻辑必须有清晰的中文注释,解释算法的设计意图和实现逻辑。
变量命名必须符合驼峰命名法 (camelCase),类名使用大驼峰命名法 (PascalCase)。
代码结构应保持简洁清晰,单个函数不超过 50 行(不含注释)。
**非negotiable 规则**:
- 任何超过 5 行的逻辑块必须有中文注释
- 公共 API 必须包含完整的 docstring(中文说明参数和返回值)
- 配置文件、环境变量等必须使用有意义的命名
**理由**:中文注释确保团队成员易于理解代码逻辑,提升代码可维护性;驼峰命名法是业界通用规范,增强代码一致性。
### II. 测试标准 (Testing Standards) - NON-NEGOTIABLE
每个核心函数必须配备单元测试,使用 Pytest 框架。测试覆盖率要求核心模块不低于 80%。
**非negotiable 规则**:
- 核心业务逻辑函数必须有对应的测试文件 (`test_*.py`)
- 测试用例必须覆盖正常流程、边界条件和异常场景
- 每个 PR 必须包含相关功能的测试,或说明豁免原因
- 测试必须遵循 Arrange-Act-Assert 模式
**理由**:测试是代码质量的底线保障,确保功能正确性,便于重构和回归验证。
### III. 性能规范 (Performance Standards)
数据库查询必须优化,避免 N+1 查询问题。所有数据库交互必须使用批量查询或预加载 (prefetch) 机制。
**非negotiable 规则**:
- 关联数据的查询必须使用 JOIN、preload 或 eager loading
- 循环内的数据库查询是严格禁止的(必须重构为批量查询)
- 大数据量操作必须分批处理,避免内存溢出
- 关键路径的查询必须添加监控和超时控制
**理由**:N+1 问题是最常见的性能杀手,严重影响系统响应速度和用户体验。
### IV. UI 设计规范 (UI Design Standards)
前端 UI 保持极简风格,参考 Ant Design 设计规范。
**非negotiable 规则**:
- 配色以中性色为主,遵循 Ant Design 色板
- 组件保持简洁,避免过度装饰和复杂的视觉层次
- 间距和留白遵循 8px 基础栅格系统
- 交互反馈必须即时、明确(loading、success、error 状态)
**理由**:极简设计提升用户认知效率,降低学习成本;Ant Design 是业界成熟的设计体系。
## 附加约束 (Additional Constraints)
### 安全与合规要求
- 所有用户输入必须经过验证和清理,防止注入攻击
- 敏感数据(密码、token、密钥)必须加密存储,传输使用 HTTPS
- 遵循最小权限原则,服务账户仅授予必要的访问权限
- 安全相关的日志必须脱敏处理,不记录敏感信息
## 开发工作流 (Development Workflow)
### 文档要求
- 每个功能必须有对应的 README 说明安装、配置和使用方法
- API 接口必须使用 OpenAPI/Swagger 文档化
- 数据库变更必须有对应的迁移说明
### 评审流程
- 所有代码变更必须通过 Pull Request 审核
- 代码评审必须检查:代码质量、测试覆盖、性能影响、安全风险
- 复杂逻辑必须附带设计文档和评审理由说明
### 测试流程
- 功能开发前先编写失败的测试用例(测试驱动开发 TDD 推荐)
- CI 流水线必须包含完整的单元测试和集成测试
- 性能测试作为 CI 门禁,检测回归性性能下降
## Governance
本宪法是项目开发的最高准则,优先于其他开发文档。
**修订程序**:
- 任何原则的修改必须经过社区讨论和核心维护者批准
- 重大变更(原则删除或重新定义)需要 MAJOR 版本升级
- 新增原则或扩展指导需要 MINOR 版本升级
- 措辞澄清、修正错别字等非语义变更使用 PATCH 版本
**合规检查**:
- 所有 PR 必须通过宪法合规检查
- 违反非negotiable 规则的 PR 不得合并
- 性能关键路径的变更需要性能测试报告
**版本**: 1.0.0 | **Ratified**: 2026-01-03 | **Last Amended**: 2026-01-03
编写规格
1. /speckit.specify 是做什么的?
这个命令相当于让你扮演产品经理的角色。你需要告诉 AI 你想做一个什么样的软件,它包含哪些功能,用户怎么使用它。
-
输入: 一段关于产品功能的自然语言描述(就像你发给外包公司的需求文档摘要)。
-
输出: AI 会根据你的描述,在
specs/目录下生成一份结构化的规格说明书 (spec.md)。这份文档会包含:-
用户故事 (User Stories)
-
功能需求列表
-
验收标准 (Acceptance Criteria)
-
注意: 这一步通常只描述业务逻辑和功能(What & Why),不要描述具体的编程语言或数据库技术(How)。比如不要在这里说“用 Python 写”或者“用 React 框架”,技术栈的定义是在下一步 /speckit.plan 进行的。
/speckit.specify 开发一个个人记账应用。
核心功能包括:
1. 记账:用户可以快速输入金额、选择分类(餐饮、交通、购物等)、添加备注。
2. 统计:主页显示当月总支出和收入。提供饼图展示各分类的支出占比。
3. 预算:用户可以设置每月预算上限,当支出超过80%时在界面显眼处提示。
4. 交互:界面要简洁,尽量减少点击次数,支持深色模式。
不需要登录功能,数据保存在本地即可。
2. 最佳实践建议
在使用这个命令时,遵循以下原则效果最好:
-
忘记技术: 专注于“用户能做什么”,而不是“后台怎么写”。
-
越细越好: 比如不要只说“要有搜索功能”,要说“支持通过关键词搜索账单备注,并且支持按日期范围筛选”。
-
定义边界: 明确说什么不做(比如上面例子里的“不需要登录”),这能极大地简化 AI 的开发难度。

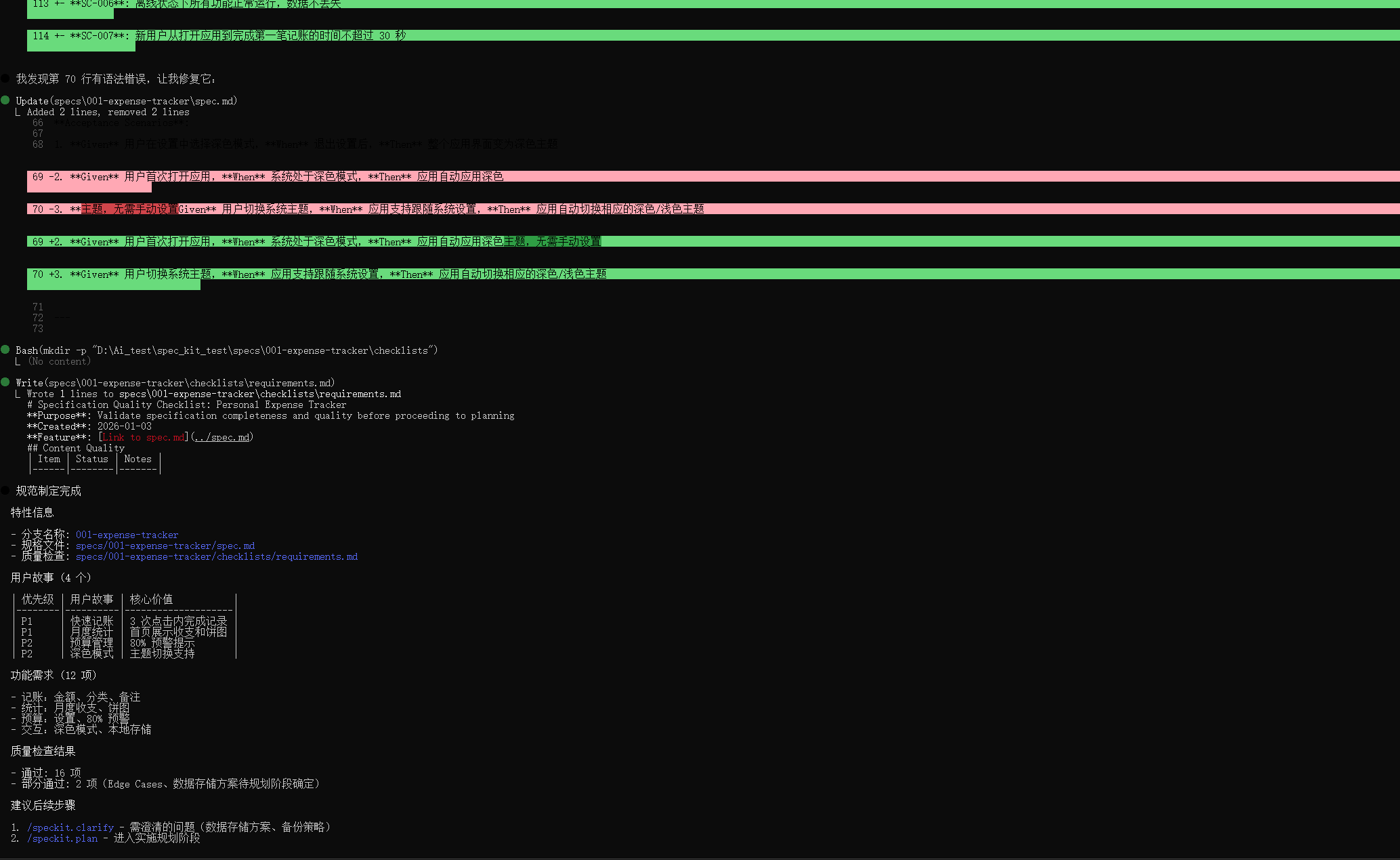
其自动新建的需求说明
# Personal Expense Tracker
**Feature Branch**: `001-expense-tracker`
**Created**: 2026-01-03
**Status**: Draft
**Input**: "开发一个个人记账应用。核心功能包括:1. 记账:用户可以快速输入金额、选择分类(餐饮、交通、购物等)、添加备注。2. 统计:主页显示当月总支出和收入。提供饼图展示各分类的支出占比。3. 预算:用户可以设置每月预算上限,当支出超过80%时在界面显眼处提示。4. 交互:界面要简洁,尽量减少点击次数,支持深色模式。不需要登录功能,数据保存在本地即可。"
## User Scenarios & Testing *(mandatory)*
### User Story 1 - Quick Expense Recording (Priority: P1)
作为普通用户,我希望能够快速记录每一笔支出,以便追踪我的日常开支。
**Why this priority**: 记账是应用的核心功能,用户首次使用时的体验直接影响留存率
**Independent Test**: 用户可以通过 3 次以内的点击完成一笔支出记录,无需登录或复杂操作
**Acceptance Scenarios**:
1. **Given** 用户打开应用,**When** 输入金额、选择分类、点击确认,**Then** 支出记录成功保存,显示操作成功提示
2. **Given** 用户输入金额为 0 或负数,**When** 点击确认,**Then** 显示错误提示,阻止保存
3. **Given** 用户未选择分类,**When** 点击确认,**Then** 显示提示要求选择分类
---
### User Story 2 - Monthly Statistics Overview (Priority: P1)
作为用户,我希望在首页看到当月的总支出和总收入,以及各类别的支出占比图表。
**Why this priority**: 用户打开应用的主要目的是查看财务状况,清晰的概览能帮助用户快速了解自己的消费习惯
**Independent Test**: 用户打开应用即可看到当月统计数据,无需任何额外操作
**Acceptance Scenarios**:
1. **Given** 用户有当月记账记录,**When** 打开应用首页,**Then** 显示当月总支出和总收入金额,以及相比上月的变化趋势
2. **Given** 用户有多笔不同分类的支出,**When** 查看统计页面,**Then** 显示饼图,清晰展示各分类的支出占比
3. **Given** 当月无任何记账记录,**When** 打开应用,**Then** 显示友好的空状态提示,引导用户开始记账
---
### User Story 3 - Budget Management (Priority: P2)
作为用户,我希望设置每月预算,并在接近或超出预算时收到提醒。
**Why this priority**: 预算功能是帮助用户控制开支的核心工具,80% 预警机制能帮助用户及时调整消费行为
**Independent Test**: 用户设置预算后,当支出达到设定金额的 80% 时,应用在首页显眼位置显示警告提示
**Acceptance Scenarios**:
1. **Given** 用户已设置月度预算为 5000 元,**When** 当月支出达到 4000 元(80%),**Then** 首页显示预算预警提示,颜色醒目(如红色或橙色)
2. **Given** 用户支出超过预算上限,**When** 打开应用,**Then** 预警提示变为更强烈的警告样式
3. **Given** 用户修改预算金额,**When** 保存后,**Then** 预警提示根据新预算重新计算
---
### User Story 4 - Dark Mode Support (Priority: P2)
作为用户,我希望能够切换深色/浅色模式,以适应不同光线环境。
**Why this priority**: 深色模式是现代应用的基本需求,能减少夜间使用时的眼睛疲劳
**Independent Test**: 用户可以在设置中切换主题,系统记住用户偏好并自动应用
**Acceptance Scenarios**:
1. **Given** 用户在设置中选择深色模式,**When** 退出设置后,**Then** 整个应用界面变为深色主题
2. **Given** 用户首次打开应用,**When** 系统处于深色模式,**Then** 应用自动应用深色主题,无需手动设置
3. **Given** 用户切换系统主题,**When** 应用支持跟随系统设置,**Then** 应用自动切换相应的深色/浅色主题
---
### Edge Cases
- 用户在离线状态下添加记录,数据是否本地保存并联网后同步?
- 应用被强制关闭后,正在编辑的草稿数据是否会丢失?
- 如何处理跨时区用户的时间显示问题?
- 数据本地存储空间满时如何处理?
## Requirements *(mandatory)*
### Functional Requirements
- **FR-001**: 系统 MUST 允许用户快速添加支出记录,包含金额、分类、备注字段
- **FR-002**: 系统 MUST 预置常用分类:餐饮、交通、购物、娱乐、生活、通讯、其他
- **FR-003**: 系统 MUST 允许用户自定义添加分类
- **FR-004**: 系统 MUST 在首页显示当月总支出和总收入金额
- **FR-005**: 系统 MUST 提供饼图展示各类别的支出占比
- **FR-006**: 系统 MUST 允许用户设置每月预算金额
- **FR-007**: 系统 MUST 当支出达到预算 80% 时,在首页显眼位置显示预警提示
- **FR-008**: 系统 MUST 支持深色模式和浅色模式切换
- **FR-009**: 系统 MUST 自动检测系统主题设置并应用相应的主题
- **FR-010**: 系统 MUST 将所有数据保存在本地存储中,无需用户登录
- **FR-011**: 系统 MUST 提供数据导出功能(可选,防止数据丢失)
- **FR-012**: 系统 MUST 记录每笔支出的时间戳,用于月度统计筛选
### Key Entities
- **Transaction**: 交易记录,包含金额、分类、备注、创建时间、类型(收入/支出)
- **Category**: 分类,包含名称、图标、类型(收入/支出)、用户自定义标识
- **Budget**: 预算设置,包含月度金额、月份、创建时间
## Success Criteria *(mandatory)*
### Measurable Outcomes
- **SC-001**: 用户可以在 3 次点击内完成一笔支出记录
- **SC-002**: 首页加载时间不超过 1 秒,数据实时更新
- **SC-003**: 饼图渲染时间不超过 500 毫秒
- **SC-004**: 预算 80% 预警提示在首页加载后 200 毫秒内可见
- **SC-005**: 主题切换后 300 毫秒内完成界面刷新
- **SC-006**: 离线状态下所有功能正常运行,数据不丢失
- **SC-007**: 新用户从打开应用到完成第一笔记账的时间不超过 30 秒
澄清与计划
这个命令是开发流程中的**“技术架构师”**环节。
1. /speckit.plan 是做什么的?
如果说上一步 /speckit.specify 是在定义“要做什么”(业务需求),那么这一步就是在定义“怎么做”(技术实现)。
-
它的作用: 确定技术栈、架构模式、数据库选择以及关键的第三方库。
-
输入: 你对技术的偏好。
-
输出: AI 会生成详细的
plan.md(实施计划)、data-model.md(数据模型)等文件。它会根据你的要求决定是用 Python 还是 Node.js,是用 MySQL 还是本地文件存储。
对于你提供的这段英文示例:
"The application uses Vite with minimal number of libraries..."
它的意思是:“这个应用要用 Vite 构建(前端工具),尽量少用第三方库(保持轻量),尽量用原生 HTML/CSS/JS。图片不上传到云端,元数据存要在本地的 SQLite 数据库里。” —— 这是一段非常具体的技术约束。
2. plan
/speckit.plan 本项目采用 Python 后端 + 原生前端的轻量级架构。
技术栈具体要求:
1. 后端:使用 Python (推荐使用 Flask 框架,因为它轻量且适合配合简单前端)。
2. 前端:使用原生 HTML, CSS, JavaScript,不使用 React/Vue 等复杂框架。
3. 数据库:使用 SQLite 存储账目和分类数据。
4. 交互模式:可以通过简单的 API 交互,或者直接使用 Python 的模板渲染(Jinja2)。3. 中文写法示例
你可以根据你想做的项目类型,参考以下模板:
场景 A:如果你想做一个 Python 爬虫/工具(基于你之前的环境)
Plaintext
/speckit.plan 本项目使用 Python 3.12 开发。
技术栈要求:
1. 核心逻辑:使用 requests 库进行网络请求,使用 BeautifulSoup4 进行页面解析。
2. 数据存储:爬取的数据保存为 CSV 文件,存放在 data/ 目录下。
3. 界面:不需要图形界面(GUI),直接通过命令行交互,使用 argparse 处理参数。
4. 依赖管理:使用 standard library 尽量减少外部依赖,除了上述提到的库。
场景 B:如果你想做一个现代 Web 网站
Plaintext
/speckit.plan 本项目采用前后端分离架构。
1. 前端:使用 React 框架,配合 TailwindCSS 进行样式设计(追求美观)。
2. 后端:使用 Python 的 FastAPI 框架提供 API 接口。
3. 数据库:使用 SQLite 存储数据,通过 SQLAlchemy 进行 ORM 映射。
4. 部署:代码需要易于在 Docker 容器中运行。
场景 C:如果你想做一个简单的本地小工具(类似原文)
Plaintext
/speckit.plan 技术栈要极简。
使用纯 HTML + JavaScript,不需要任何复杂的框架(如 React/Vue)。
数据直接保存在浏览器的 LocalStorage 中。
样式使用原生的 CSS,不需要 Bootstrap。
确保代码结构清晰,通过 index.html 直接打开就能运行。
总结
/speckit.plan 就是你指定“工具箱”的时候。 请告诉 AI 你想用哪种编程语言、哪个数据库、哪个框架。如果你不指定,AI 可能会随机选择(比如它可能会擅自决定用 Next.js,但你其实只想要个简单的 HTML)。
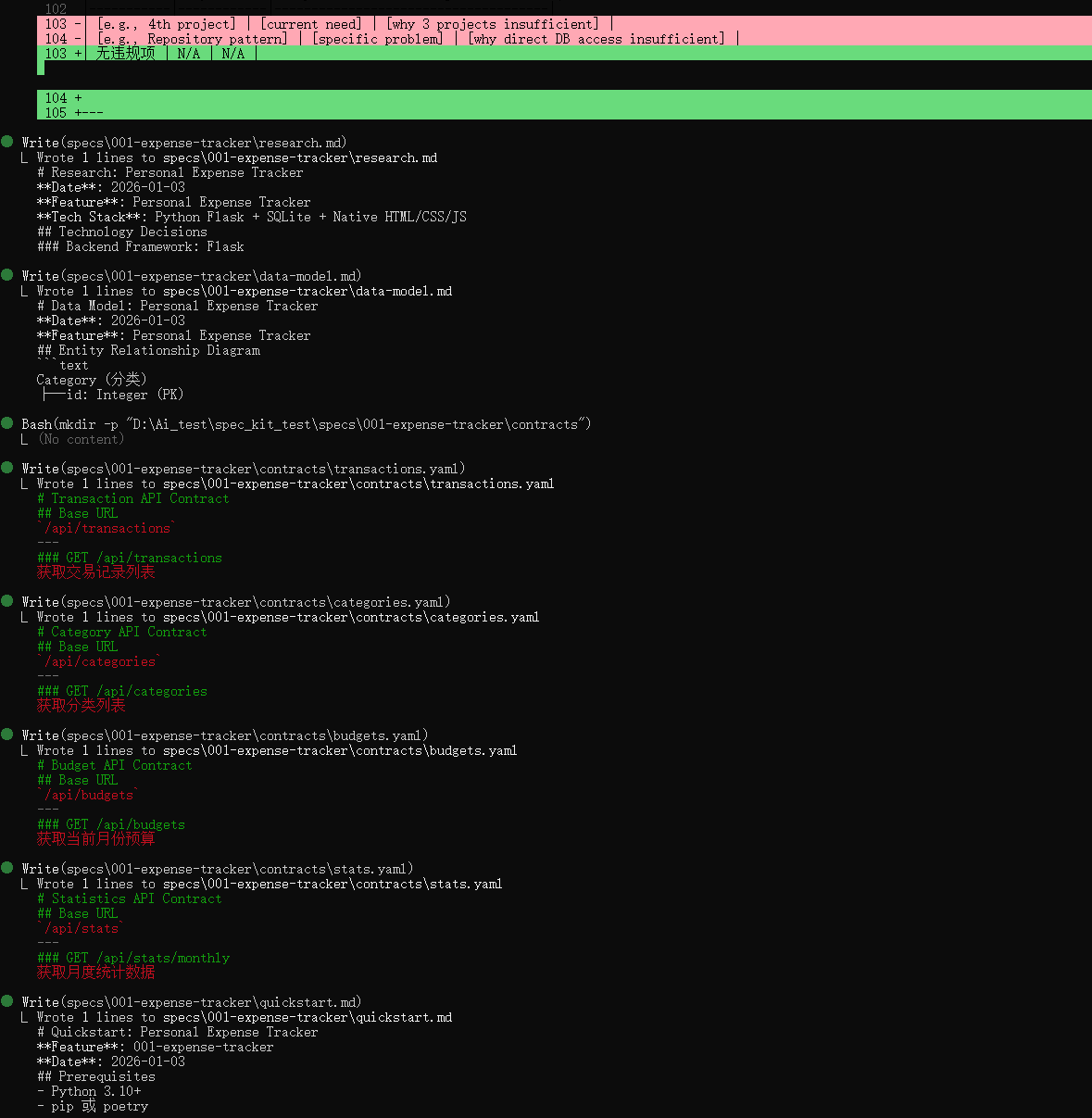
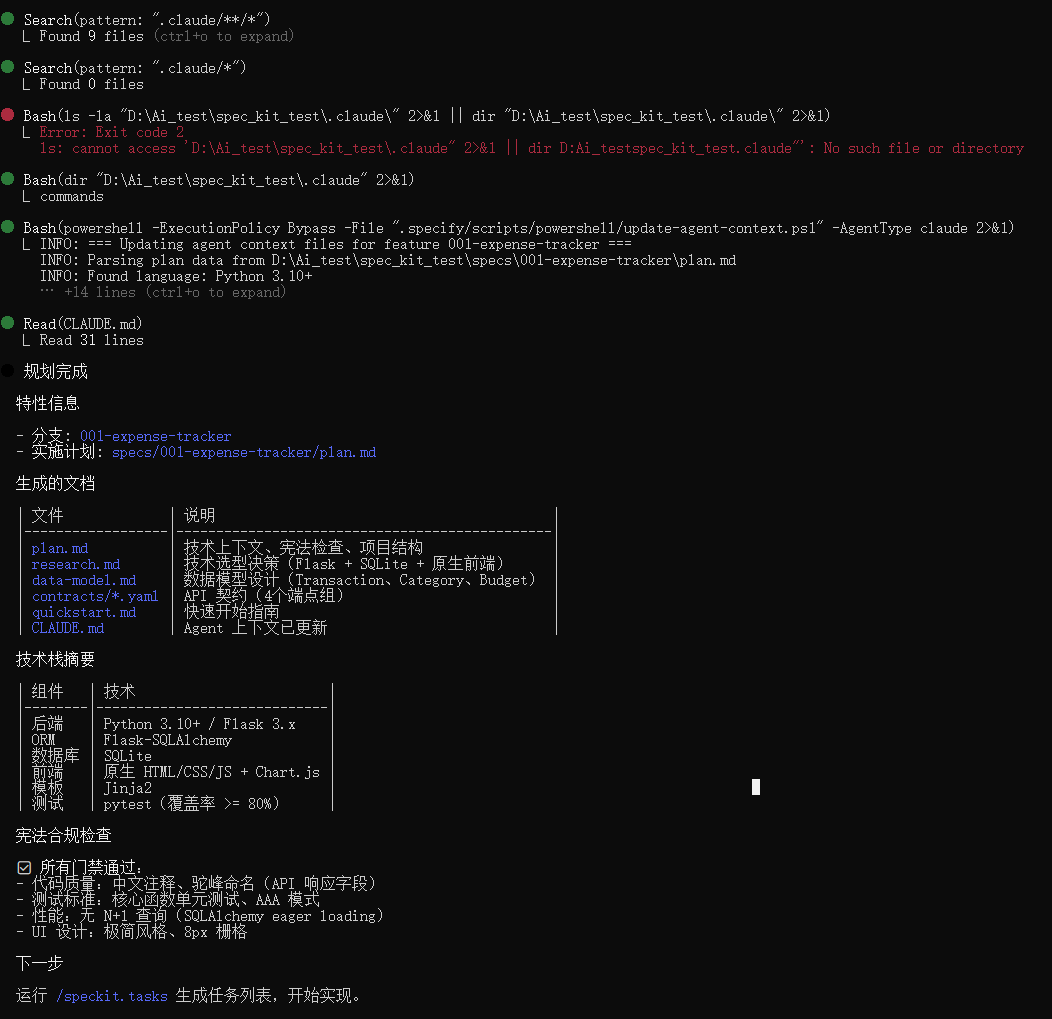
生成技术栈相关的计划文件,也会定义好数据约束,各种接口等
# Implementation Plan: Personal Expense Tracker
**Branch**: `001-expense-tracker` | **Date**: 2026-01-03 | **Spec**: [link](spec.md)
**Input**: Feature specification from `/specs/001-expense-tracker/spec.md`
## Summary
开发一个个人记账 Web 应用,支持快速记账、月度统计、预算管理和深色模式。技术栈采用 Python Flask 后端 + 原生 HTML/CSS/JS 前端 + SQLite 数据库,数据本地存储无需登录。
## Technical Context
**Language/Version**: Python 3.10+
**Primary Dependencies**: Flask 3.x, Flask-SQLAlchemy, Jinja2
**Storage**: SQLite (本地文件存储)
**Testing**: pytest (单元测试), pytest-flask (集成测试)
**Target Platform**: Web 浏览器 (桌面/移动端响应式)
**Project Type**: Web application (Flask + Native Frontend)
**Performance Goals**: 首页加载 <1秒,饼图渲染 <500ms
**Constraints**: 无需登录,数据本地存储,单用户场景
**Scale/Scope**: 单用户本地使用,预计最多几千条记录
## Constitution Check
*GATE: Must pass before Phase 0 research. Re-check after Phase 1 design.*
### Code Quality Gates (Principle I)
| Gate | Status | Notes |
|------|--------|-------|
| 复杂逻辑有中文注释 | ✅ PASS | 需在代码审查中验证 |
| 变量驼峰命名 (camelCase) | ✅ PASS | Python 使用 snake_case,但 API 响应字段用 camelCase |
| 函数不超过 50 行 | ✅ PASS | 需在代码审查中验证 |
### Testing Gates (Principle II) - NON-NEGOTIABLE
| Gate | Status | Notes |
|------|--------|-------|
| 核心函数有单元测试 | ✅ PASS | Transaction、Category、Budget 服务需测试 |
| 测试覆盖率 >= 80% | ✅ PASS | CI 流水线需配置覆盖率检查 |
| 测试遵循 AAA 模式 | ✅ PASS | 测试规范已明确 |
### Performance Gates (Principle III)
| Gate | Status | Notes |
|------|--------|-------|
| 无 N+1 查询 | ✅ PASS | 使用 SQLAlchemy eager loading |
| 批量操作分页处理 | ✅ PASS | 统计查询需分页或限制 |
### UI Design Gates (Principle IV)
| Gate | Status | Notes |
|------|--------|-------|
| 极简风格 (Ant Design) | ✅ PASS | 原生 CSS 参考 Ant Design 规范 |
| 8px 栅格系统 | ✅ PASS | CSS 变量定义基准间距 |
**Result**: ✅ ALL GATES PASS - Ready for Phase 0
## Project Structure
### Documentation (this feature)
```text
specs/001-expense-tracker/
├── plan.md # This file
├── research.md # Phase 0 output
├── data-model.md # Phase 1 output
├── quickstart.md # Phase 1 output
├── contracts/ # Phase 1 output
└── tasks.md # Phase 2 output (/speckit.tasks)
```
### Source Code (repository root)
```text
expense-tracker/
├── app.py # Flask 应用入口
├── config.py # 配置文件
├── models.py # SQLAlchemy 数据模型
├── services/ # 业务逻辑层
│ ├── __init__.py
│ ├── transaction.py # 记账服务
│ ├── category.py # 分类服务
│ ├── budget.py # 预算服务
│ └── stats.py # 统计服务
├── api/ # API 路由
│ ├── __init__.py
│ ├── transactions.py
│ ├── categories.py
│ ├── budgets.py
│ └── stats.py
├── static/ # 静态资源
│ ├── css/
│ │ └── style.css
│ ├── js/
│ │ └── app.js
│ └── images/
├── templates/ # Jinja2 模板
│ ├── base.html
│ ├── index.html
│ └── settings.html
├── tests/ # 测试目录
│ ├── __init__.py
│ ├── unit/
│ ├── integration/
│ └── conftest.py
└── data/ # SQLite 数据库文件
└── expense.db
```
**Structure Decision**: 采用 Flask 单项目结构,前后端分离但通过 Jinja2 模板渲染首页,API 处理数据交互。
## Complexity Tracking
> **Fill ONLY if Constitution Check has violations that must be justified**
| Violation | Why Needed | Simpler Alternative Rejected Because |
|-----------|------------|-------------------------------------|
| 无违规项 | N/A | N/A |
---
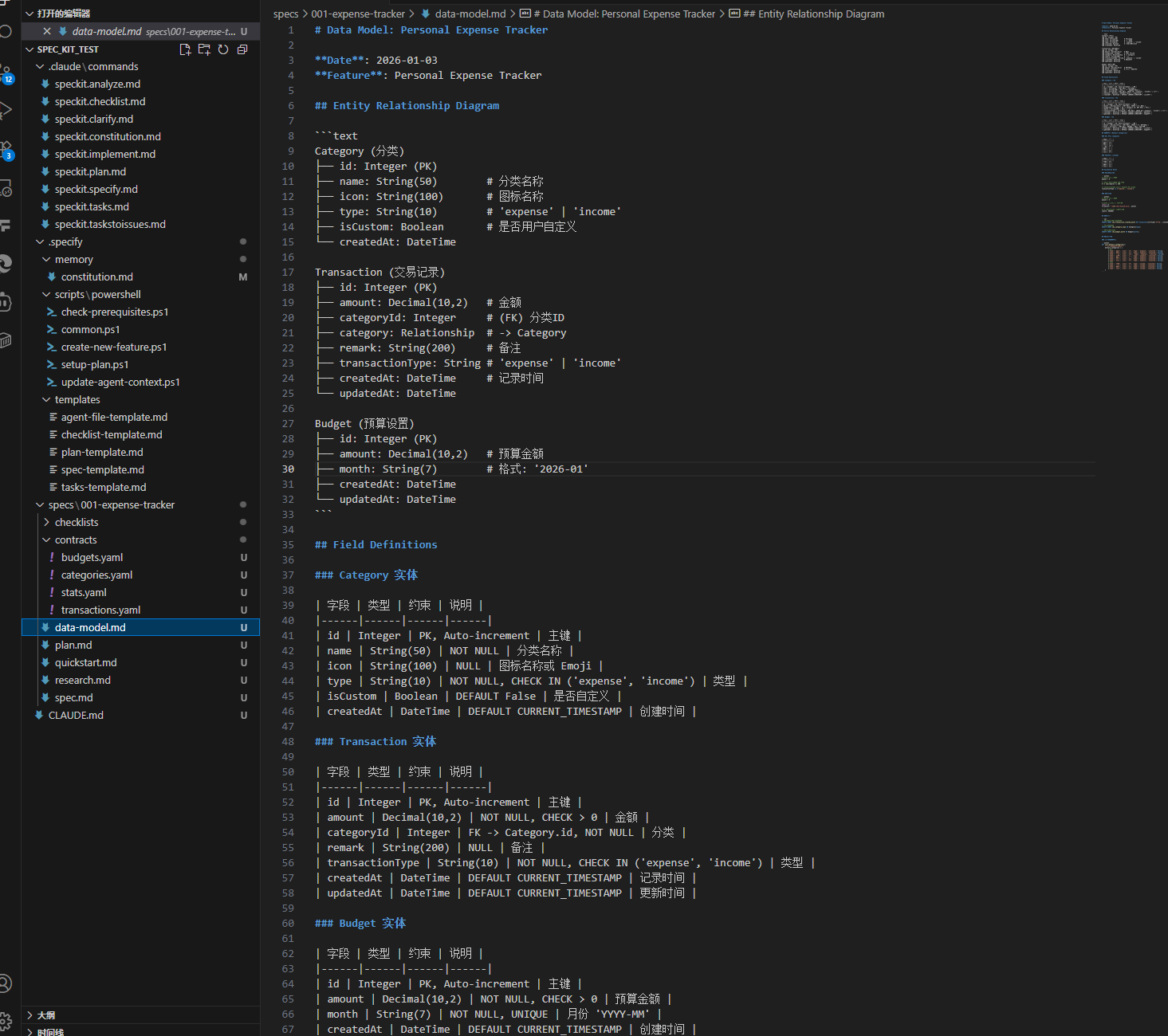
任务拆解
1. /speckit.tasks 是做什么的?
如果说上一步 /speckit.plan 是画出了建筑蓝图,那么这一步就是制定施工时间表。
-
核心作用: 它会将宏大的技术计划拆解成一个个极小的、可执行的原子任务。
-
输入: 刚刚生成的
plan.md(技术计划书)。 -
输出: 生成一个
tasks.md文件。
2. 它具体会生成什么?
它不是简单列出“写代码”三个字,而是会生成非常详细的步骤。基于你的Python 记账应用,它生成的任务列表可能会长这样:
User Story 1: 基础环境搭建
[ ] 创建
requirements.txt并添加 Flask 和 SQLAlchmey 依赖。[ ] 创建
app.py入口文件,编写基础的 Flask Hello World 路由。User Story 2: 数据库设计 3. [ ] 在
models.py中定义Transaction(账目)类,包含金额、分类、备注字段。 4. [ ] 编写初始化脚本init_db.py,用于生成 SQLite 数据库文件。User Story 3: 记账功能实现 5. [ ] 创建
templates/add.html,编写包含金额和分类的 HTML 表单。 6. [ ] 在app.py中编写/add路由的 POST 逻辑,将表单数据存入 SQLite。
3. 为什么要用它?(核心价值)
-
处理依赖关系: AI 会知道必须先创建数据库模型,后写前端页面,否则代码会报错。这个命令就是为了确立这个先后顺序。
-
防止 AI 偷懒或出错: 如果让 AI 一次性“把整个APP写出来”,它往往会写漏东西或产生 Bug。通过拆解成几十个小任务,AI 每次只专注写一个函数或一个文件,准确率极高。
-
断点续传: 如果开发中途断电或报错,因为有任务列表,你可以清楚知道目前进度在第几步。
总结
这是一个自动化拆解的过程。 你只需要输入 /speckit.tasks(通常不需要加额外参数),AI 就会读取你的计划,自动帮你把“施工工单”列好。
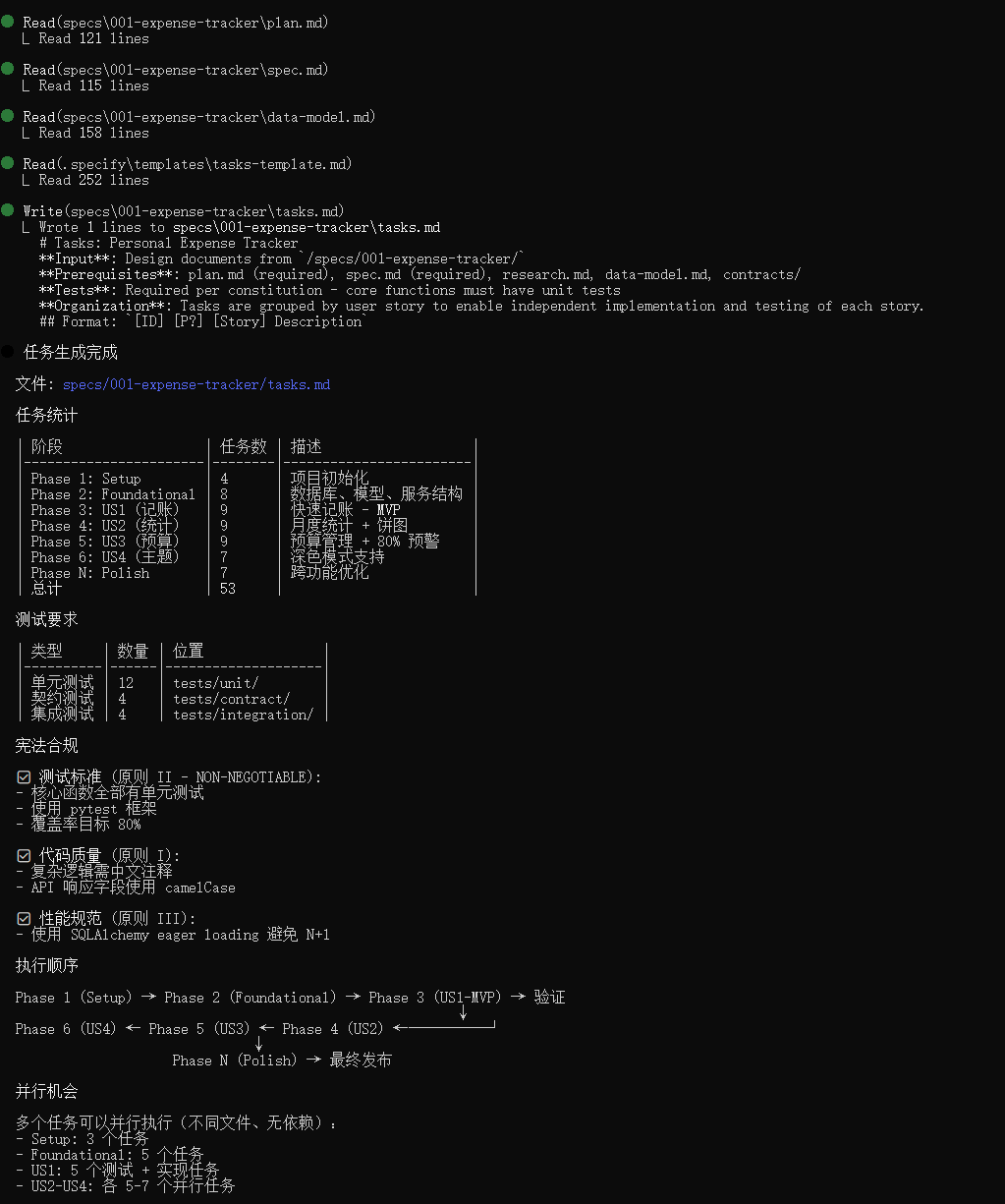
生成可执行的任务计划 task.md
# Tasks: Personal Expense Tracker
**Input**: Design documents from `/specs/001-expense-tracker/`
**Prerequisites**: plan.md (required), spec.md (required), research.md, data-model.md, contracts/
**Tests**: Required per constitution - core functions must have unit tests
**Organization**: Tasks are grouped by user story to enable independent implementation and testing of each story.
## Format: `[ID] [P?] [Story] Description`
- **[P]**: Can run in parallel (different files, no dependencies)
- **[Story]**: Which user story this task belongs to (e.g., US1, US2, US3, US4)
- Include exact file paths in descriptions
## Path Conventions
- Project root: `expense-tracker/`
- Tests: `expense-tracker/tests/`
- Source: `expense-tracker/`
---
## Phase 1: Setup (Shared Infrastructure)
**Purpose**: Project initialization and basic structure
- [ ] T001 Create project directory structure per plan.md
- [ ] T002 Create requirements.txt with Flask 3.x, Flask-SQLAlchemy, pytest, pytest-flask
- [ ] T003 [P] Create config.py with Flask configuration
- [ ] T004 [P] Create .env.example for environment variables
---
## Phase 2: Foundational (Blocking Prerequisites)
**Purpose**: Core infrastructure that MUST be complete before ANY user story can be implemented
**CRITICAL**: No user story work can begin until this phase is complete
### Tests for Foundational
> **NOTE: Write these tests FIRST, ensure they FAIL before implementation**
- [ ] T005 [P] Unit test for config loading in tests/unit/test_config.py
- [ ] T006 [P] Integration test for database connection in tests/integration/test_db.py
### Implementation for Foundational
- [ ] T007 Create app.py with Flask application factory
- [ ] T008 Create models.py with SQLAlchemy Base and all entities (Category, Transaction, Budget)
- [ ] T009 [P] Create services/__init__.py
- [ ] T010 [P] Create api/__init__.py
- [ ] T011 [P] Create tests/__init__.py and conftest.py with pytest fixtures
- [ ] T012 [P] Implement database initialization in app.py (create tables, seed default categories)
**Checkpoint**: Foundation ready - user story implementation can now begin in parallel
---
## Phase 3: User Story 1 - Quick Expense Recording (Priority: P1) 🎯 MVP
**Goal**: 用户可以通过 3 次点击内完成一笔支出记录
**Independent Test**: 打开应用 → 输入金额 → 选择分类 → 点击确认 → 记录保存成功
### Tests for User Story 1
> **NOTE: Write these tests FIRST, ensure they FAIL before implementation**
- [ ] T013 [P] [US1] Contract test for POST /api/transactions in tests/contract/test_transactions.py
- [ ] T014 [P] [US1] Unit test for Transaction model validation in tests/unit/test_transaction.py
- [ ] T015 [P] [US1] Unit test for TransactionService.create() in tests/unit/test_transaction_service.py
### Implementation for User Story 1
- [ ] T016 [P] [US1] Implement TransactionService in services/transaction.py
- [ ] T017 [P] [US1] Implement category service helper in services/category.py
- [ ] T018 [US1] Implement GET /api/categories endpoint in api/categories.py
- [ ] T019 [US1] Implement POST /api/transactions endpoint in api/transactions.py
- [ ] T020 [US1] Create transaction form in templates/transaction_form.html (embedded in index.html)
- [ ] T021 [US1] Add quick-add UI component in static/js/app.js (3-click flow)
- [ ] T022 [US1] Add transaction form validation and API call
**Checkpoint**: At this point, User Story 1 should be fully functional and testable independently
---
## Phase 4: User Story 2 - Monthly Statistics Overview (Priority: P1)
**Goal**: 首页显示当月收支统计和饼图
**Independent Test**: 打开首页即可看到当月总支出、收入和分类占比饼图
### Tests for User Story 2
> **NOTE: Write these tests FIRST, ensure they FAIL before implementation**
- [ ] T023 [P] [US2] Contract test for GET /api/stats/summary in tests/contract/test_stats.py
- [ ] T024 [P] [US2] Unit test for StatsService in tests/unit/test_stats_service.py
- [ ] T025 [P] [US2] Integration test for category breakdown calculation in tests/integration/test_stats.py
### Implementation for User Story 2
- [ ] T026 [P] [US2] Implement StatsService in services/stats.py
- [ ] T027 [P] [US2] Implement GET /api/stats/summary endpoint in api/stats.py
- [ ] T028 [P] [US2] Implement GET /api/stats/category-breakdown endpoint
- [ ] T029 [US2] Add statistics display in templates/index.html
- [ ] T030 [US2] Add Chart.js pie chart integration in static/js/app.js
- [ ] T031 [US2] Add empty state handling for no transactions
**Checkpoint**: At this point, User Stories 1 AND 2 should both work independently
---
## Phase 5: User Story 3 - Budget Management (Priority: P2)
**Goal**: 用户可以设置预算,支出达 80% 时显示预警
**Independent Test**: 设置预算后,当支出达到 80%,首页显示警告提示
### Tests for User Story 3
> **NOTE: Write these tests FIRST, ensure they FAIL before implementation**
- [ ] T032 [P] [US3] Contract test for POST /api/budgets in tests/contract/test_budgets.py
- [ ] T033 [P] [US3] Unit test for BudgetService in tests/unit/test_budget_service.py
- [ ] T034 [P] [US3] Integration test for budget warning calculation in tests/integration/test_budget.py
### Implementation for User Story 3
- [ ] T035 [P] [US3] Implement BudgetService in services/budget.py
- [ ] T036 [P] [US3] Implement GET /api/budgets endpoint in api/budgets.py
- [ ] T037 [P] [US3] Implement POST /api/budgets endpoint
- [ ] T038 [P] [US3] Implement GET /api/budgets/check endpoint for warning status
- [ ] T039 [US3] Add budget settings page in templates/settings.html
- [ ] T040 [US3] Add budget warning UI component in index.html
- [ ] T041 [US3] Add budget warning logic (80% warning, 100% over-budget)
**Checkpoint**: At this point, User Stories 1, 2, AND 3 should all work independently
---
## Phase 6: User Story 4 - Dark Mode Support (Priority: P2)
**Goal**: 用户可以切换深色/浅色模式,系统自动跟随系统设置
**Independent Test**: 在设置中切换主题,应用界面立即更新;系统深色模式下自动应用深色
### Tests for User Story 4
> **NOTE: Write these tests FIRST, ensure they FAIL before implementation**
- [ ] T042 [P] [US4] Unit test for theme toggle in static/js in tests/unit/test_theme.py
### Implementation for User Story 4
- [ ] T043 [P] [US4] Define CSS variables for light/dark theme in static/css/style.css
- [ ] T044 [P] [US4] Create dark theme CSS rules following Ant Design principles
- [ ] T045 [P] [US4] Implement theme detection (prefers-color-scheme) in static/js/app.js
- [ ] T046 [P] [US4] Implement theme toggle with localStorage persistence
- [ ] T047 [US4] Add theme switcher UI in templates/settings.html
- [ ] T048 [US4] Add theme initialization on page load
**Checkpoint**: All user stories should now be independently functional
---
## Phase N: Polish & Cross-Cutting Concerns
**Purpose**: Improvements that affect multiple user stories
- [ ] T049 [P] Add data export endpoint GET /api/transactions/export in api/transactions.py
- [ ] T050 [P] Implement CSV export functionality
- [ ] T051 [P] Add unit tests for Category model in tests/unit/test_category.py
- [ ] T052 [P] Run full test suite with coverage check (target: 80%)
- [ ] T053 [P] Update README.md with usage instructions
- [ ] T054 [P] Verify all static files load correctly (CSS, JS, Chart.js)
- [ ] T055 [P] Cross-browser testing (Chrome, Firefox, Safari)
---
## Dependencies & Execution Order
### Phase Dependencies
- **Setup (Phase 1)**: No dependencies - can start immediately
- **Foundational (Phase 2)**: Depends on Setup completion - BLOCKS all user stories
- **User Stories (Phase 3-6)**: All depend on Foundational phase completion
- User stories can proceed in parallel (if staffed)
- Or sequentially in priority order (P1 → P2)
- **Polish (Final Phase)**: Depends on all user stories being complete
### User Story Dependencies
- **User Story 1 (P1)**: Can start after Foundational (Phase 2) - No dependencies on other stories
- **User Story 2 (P1)**: Can start after Foundational (Phase 2) - Can share TransactionService with US1
- **User Story 3 (P2)**: Can start after Foundational (Phase 2) - Independent
- **User Story 4 (P2)**: Can start after Foundational (Phase 2) - Independent
### Within Each User Story
- Tests MUST be written and FAIL before implementation
- Models before services (done in Foundational)
- Services before endpoints
- Core implementation before integration
- Story complete before moving to next priority
### Parallel Opportunities
- All Setup tasks marked [P] can run in parallel
- All Foundational tasks marked [P] can run in parallel (within Phase 2)
- Once Foundational phase completes, all user stories can start in parallel
- All tests for a user story marked [P] can run in parallel
- Different user stories can be worked on in parallel by different team members
---
## Parallel Execution Examples
### User Story 1
```bash
# Run tests for User Story 1 together:
Task: "Contract test for POST /api/transactions in tests/contract/test_transactions.py"
Task: "Unit test for Transaction model in tests/unit/test_transaction.py"
Task: "Unit test for TransactionService in tests/unit/test_transaction_service.py"
# Launch models + services together:
Task: "Implement TransactionService in services/transaction.py"
Task: "Implement category service helper in services/category.py"
```
### User Story 2
```bash
Task: "Implement StatsService in services/stats.py"
Task: "Implement GET /api/stats/summary endpoint"
```
---
## Implementation Strategy
### MVP First (User Story 1 Only)
1. Complete Phase 1: Setup
2. Complete Phase 2: Foundational (CRITICAL - blocks all stories)
3. Complete Phase 3: User Story 1
4. **STOP and VALIDATE**: Test User Story 1 independently
5. Deploy/demo if ready
### Incremental Delivery
1. Complete Setup + Foundational → Foundation ready
2. Add User Story 1 → Test independently → Deploy/Demo (MVP!)
3. Add User Story 2 → Test independently → Deploy/Demo
4. Add User Story 3 → Test independently → Deploy/Demo
5. Add User Story 4 → Test independently → Deploy/Demo
6. Polish phase → Final release
### Parallel Team Strategy
With multiple developers:
1. Team completes Setup + Foundational together
2. Once Foundational is done:
- Developer A: User Story 1 (Core记账)
- Developer B: User Story 2 (统计图表)
- Developer C: User Story 3 + 4 (预算 + 主题)
3. Stories complete and integrate independently
---
## Task Summary
| Phase | Task Count | Description |
|-------|------------|-------------|
| Phase 1: Setup | 4 | Project initialization |
| Phase 2: Foundational | 8 | Database, models, services structure |
| Phase 3: US1 (记账) | 9 | Quick expense recording |
| Phase 4: US2 (统计) | 9 | Monthly statistics + pie chart |
| Phase 5: US3 (预算) | 9 | Budget management + warning |
| Phase 6: US4 (主题) | 7 | Dark mode support |
| Phase N: Polish | 7 | Cross-cutting improvements |
| **Total** | **53** | |
### Parallel Tasks
- Setup: T002, T003, T004 (3 tasks)
- Foundational: T005, T006, T009, T010, T011 (5 tasks)
- User Story 1: T013, T014, T015, T016, T017 (5 tasks)
- User Story 2: T023, T024, T025, T026, T027, T028 (6 tasks)
- User Story 3: T032, T033, T034, T035, T036, T037, T038 (7 tasks)
- User Story 4: T042, T043, T044, T045, T046 (5 tasks)
### Tests Required
| Category | Count | Location |
|----------|-------|----------|
| Unit Tests | 12 | tests/unit/ |
| Contract Tests | 4 | tests/contract/ |
| Integration Tests | 4 | tests/integration/ |
---
## Notes
- [P] tasks = different files, no dependencies
- [Story] label maps task to specific user story for traceability
- Each user story should be independently completable and testable
- Verify tests fail before implementing
- Commit after each task or logical group
- Stop at any checkpoint to validate story independently
- Avoid: vague tasks, same file conflicts, cross-story dependencies that break independence
---
## Constitution Compliance Checklist
- [x] Tests required: Core functions have unit tests (Transaction, Category, Budget, Stats services)
- [x] Test framework: pytest (per constitution Principle II)
- [x] Coverage target: 80% (per constitution Principle II)
- [x] Chinese comments: Required in all complex logic (add to service implementations)
- [x] camelCase: API responses use camelCase field names
- [x] No N+1: Use SQLAlchemy eager loading in StatsService
执行
1. /speckit.implement 是做什么的?
如果说之前的步骤是立规矩(Constitution)、画图纸(Specify & Plan)和排工期(Tasks),那么这一步就是进场施工。
-
核心作用: 它会读取上一步生成的
tasks.md(任务列表),按照顺序自动执行里面的每一个任务。 -
它会做什么:
-
写代码: 创建 Python 文件、HTML 文件等。
-
跑命令: 自动在终端执行
pip install、mkdir等命令。 -
运行测试: 如果任务里包含测试,它会运行测试确保代码能跑通。
-
更新状态: 每完成一个任务,它会自动把
tasks.md里对应的[ ]变成[x]。
-
2. 如何让它“只做第一个任务”?
默认情况下,/speckit.implement 会尝试一口气把所有任务都做完。但因为你是在和 AI(如 Claude)对话,你可以通过自然语言指令来控制它的行为。
你不需要寻找特殊的参数,只需要在命令后面加上你的具体要求即可。
请发送这条指令:
Plaintext
/speckit.implement 请只执行任务列表(tasks.md)中的第一个任务,完成后请暂停并向我汇报。不要继续执行后续任务。
3. 为什么要这样操作?
-
验证环境: 第一个任务通常是“环境搭建”(比如安装 Flask、创建文件夹)。只跑第一个任务可以帮你确认 Python 环境、数据库驱动等是否都配置正确了,避免一开始就跑偏。
-
建立信心: 看着 AI 成功创建了第一个文件,你会对后续的自动编码更有把握。
-
人工干预: 如果第一个任务做得不够完美(比如文件夹结构你不喜欢),你可以立刻修改,而不用等它写完整个项目再改。
总结
现在,请直接把上面那句带中文要求的命令发送给 AI。它会读取任务列表,完成第一项(通常是项目初始化),然后停下来等待你的下一步指示。
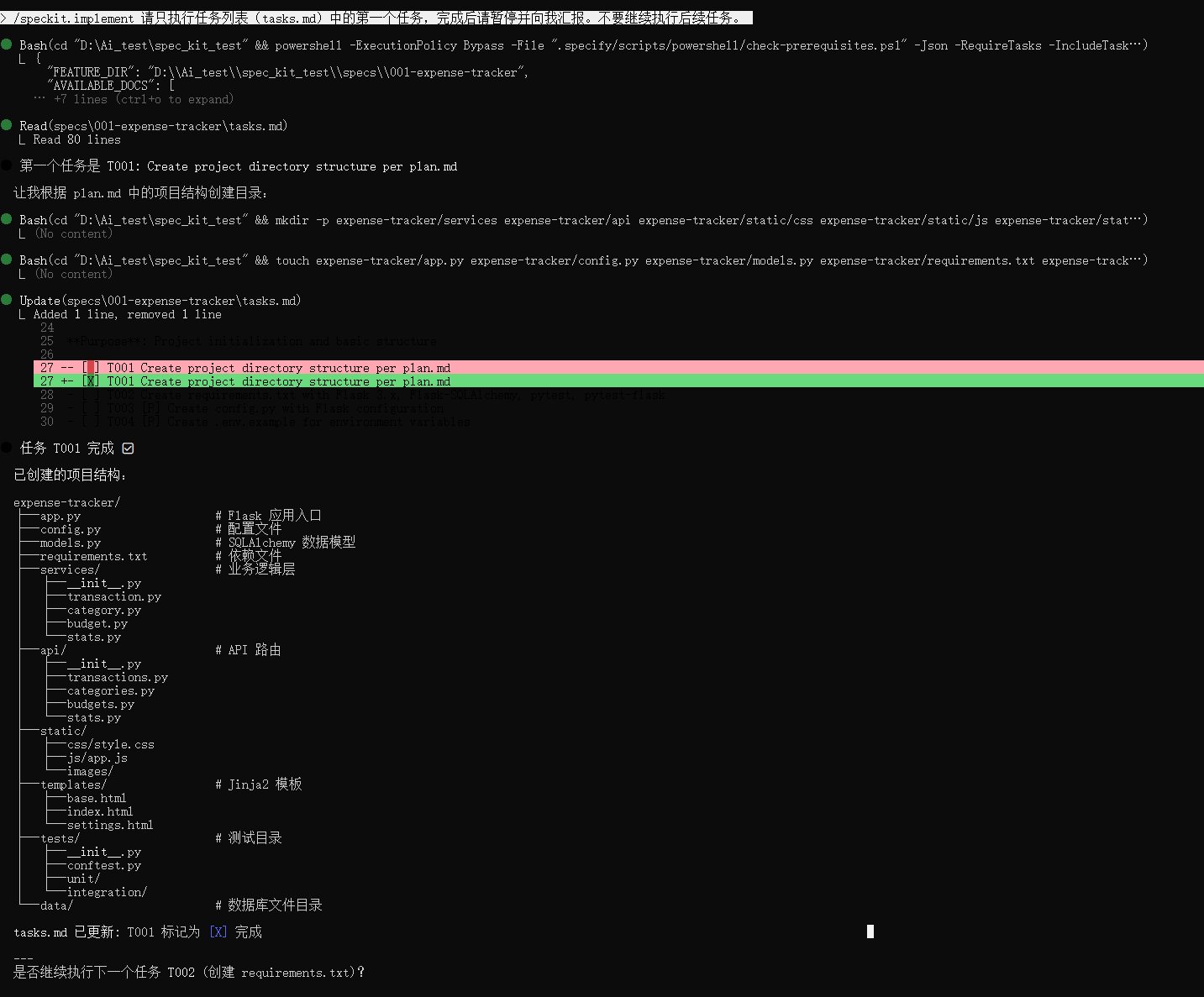
第一个任务成功完成,项目框架搭建完成
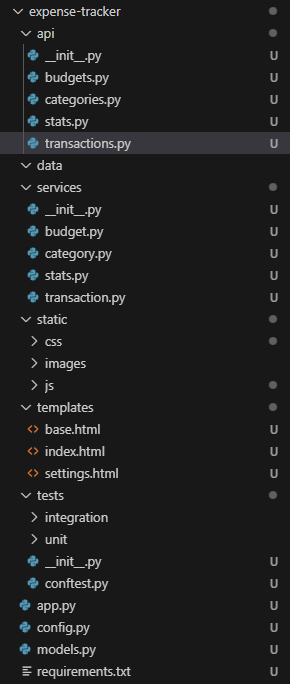
第一个任务执行成功,可以看到在 task.md文件中的 T001号任务前面进行了标记,表明该任务成功完成,所以就是可以分任务,并结合任务完成结果,阶段性去完成整个项目

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)