LLM - 面向工程实践的Agent Skills设计方法论
摘要: 在Agent开发中,过度加载上下文会导致性能、质量和成本问题。Anthropic提出的三层技能结构(元数据层、正文层、附属文件层)通过渐进式加载实现高效上下文管理。建议从"工具视角"转向"工作流视角"组织技能,确保每个技能聚焦单一能力。实践案例显示,将SKILL.md控制在200行内可提升4.8倍token利用率,显著降低延迟和溢出风险。落地时需审计
文章目录
概述
在 2025–2026 这一波 Agent 浪潮里,“会调工具”的智能体已经不稀奇,真正难的是:如何让 Agent 在复杂工程场景下稳定、快速、省钱地跑起来。 许多团队在接入 Skills/Tools 后兴奋地把代码库、SOP、配置文档统统塞给模型,结果不是上下文经常爆炸,就是响应时间漫长、幻觉频出,最后不得不回到“人工兜底”。
接下来我将尝试从一线实践出发,围绕 Anthropic 提出的 Agent Skills 三层结构与上下文工程方法论,系统梳理如何重构 Skills、控制上下文规模、提升 token 利用率,并用一个“从踩坑到顿悟”的案例串起整套思路。
为什么你的 Agent 会被“上下文”拖垮
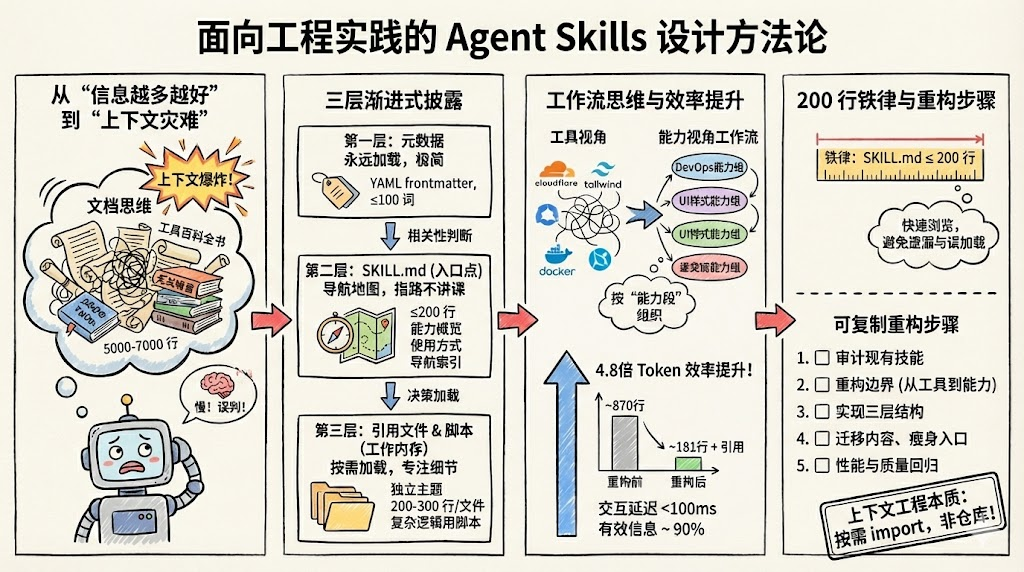
大多数人第一次设计 Agent Skills 时,都会不自觉掉进一个陷阱:信息越多越好。
典型表现包括:
- 为每个工具写一份冗长的 SKILL 文档,覆盖所有场景与反例。
- 在一次任务中激活多个技能,把几千行文档和配置一股脑塞进上下文。
- 为了“安全”和“鲁棒”,不断追加注意事项、规范条款、业务背景描述。
这类做法在小 demo 上勉强可用,一旦放到真实工程场景就会暴露三类问题:
- 性能问题:上下文长度接近模型上限,每轮调用都要扫描海量无关信息,响应明显变慢。
- 质量问题:模型在噪声极大的上下文中做决策,容易出现抓错重点、误用示例、忽略关键约束等现象。
- 成本问题:大量与当前任务无关的文档被反复发送到模型,token 消耗呈指数级增长。
“Context Engineering(上下文工程)将取代传统提示词工程,成为 Agent 应用的核心竞争力”。 但真正落地时,如果仍使用“写一份大文档”这种思路来写技能,就很难兑现这个口号。
Agent Skills 的三层结构:让技能拥有“近乎无限上下文”
Anthropic 在《Equipping agents with tools and skills》中提出了一个关键设计:Skill 是由指令、脚本和资源组成的结构化文件夹,通过三层渐进式加载机制,让 Agent 在有限上下文下访问近乎无限的外部知识与能力。
结合多篇技术解析,可以把一个 Skill 拆成三层来理解:
Level 1:元数据层(Metadata)
- 位置:通常是技能目录中的元数据字段或 YAML frontmatter。
- 内容:技能名称、简短描述、适用场景、标签等。
- 作用:作为索引,在技能列表中帮模型做“要不要考虑这个技能”的初筛。
这一层必须非常小巧,原因有二:
- 元数据常驻上下文,或经常被用来做技能检索,体积越小越不容易挤占推理空间。
- 这里的信息用于“决策是否打开技能”,不承担具体执行逻辑,没有必要写得很长。
Level 2:正文内容层(SKILL.md)
- 位置:技能目录下的 SKILL.md 文件主体。
- 内容:技能的核心指令、SOP 流程、关键约束、引用资源的索引等。
- 加载方式:只有当模型判定该技能相关、准备使用时,才会读取并加载这部分内容。
- 作用:指导模型如何在该技能域内思考与行动,是认知流程的主体。
典型技能正文的平均加载应控制在一个可管理的 token 范围内,避免成为新的上下文瓶颈,这与后文的“200 行规则”不谋而合。
Level 3:附属文件层(References & Scripts)
- 位置:技能目录中的其他 Markdown 文档、配置文件、脚本、示例数据等。
- 内容:详细说明、分场景 SOP、示例、复杂规则、代码脚本等。
- 加载方式:按需加载——只有当正文指示“阅读某文件”,模型才会通过工具读取并将其内容加入上下文。
- 作用:把庞大的背景知识与操作细节外置,在需要时再提取一小部分进入模型的上下文窗口。
更重要的是,Skill 所包含的脚本往往在外部执行环境中运行,模型只看到结构化的执行结果,而不是脚本源代码本身,从而大幅减轻上下文负载。
从架构角度看,Skill 将 Agent 的“认知空间”(可加载的文本上下文)和“行动空间”(文件系统 + 脚本执行环境)彻底拆开,使得“技能包体积”与“上下文窗口大小”不再线性绑定。
从“工具视角技能”到“工作流视角技能”
理解了三层结构之后,一个更大的设计问题是:技能包到底应该围绕什么来组织?
在不少团队的实践中,最常见的做法是“工具视角”:
- Cloud 服务一个技能(含各种 API、部署方式、权限规范)。
- Tailwind/Ant Design 一个技能(含完整组件文档与设计指南)。
- 数据库一个技能,前端框架一个技能,CI/CD 一个技能……
这种方式在概念上清晰,但在 Agent 实际执行任务时容易出问题:
- 真实任务往往跨越多个工具,例如“实现一个新页面并上线生产”,需要框架、UI、接口、部署等能力。
- 如果每个工具单独建技能,Agent 需要并行激活多个 Skills,等于是同时读多份“大百科”,上下文很快被填满。
越来越多的实践文章开始强调:应当从“工具视角”转向“工作流/能力视角”来划分技能边界。
所谓“工作流视角”,就是围绕开发流程的关键阶段设计 Skills,例如:
- devops:聚焦“部署与运维”能力,内部可以整合若干云平台或 CI/CD 工具的使用规范。
- ui-styling:聚焦“统一 UI 风格与组件规范”,内部可以包含 Tailwind、设计系统约定等内容。
- web-frameworks:聚焦“搭建和扩展 Web 应用骨架”,整合 Next.js、路由、状态管理等能力。
这样有几个明显好处:
- 在一个具体任务中,Agent 激活的是“当前阶段的能力”,而不是“一堆工具手册”。
- 同一技能内部内容围绕单一能力目标组织,语义更加集中,有利于模型在有限上下文中抓重点。
- 技能之间互补而非重叠,减少多个技能之间的说明冲突和冗余。
可以把这种转变理解为:从“按产品线写文档”转向“按流水线设计工位”。
重构案例
有一位开发者在使用 Claude Code 时,把几乎所有项目背景和操作指南都写进了单一 SKILL.md,结果在真实项目里触发了上下文灾难:每次任务都会被迫加载大量无关内容,响应延迟和成本居高不下。 在参考官方 Skill 结构与上下文工程实践后,他进行了系统重构,并总结出一个简单却有效的经验法则:入口文件 SKILL.md 控制在 200 行以内。
重构前的状态
- 单个技能 SKILL.md 约 800–900 行,涵盖背景描述、长篇 SOP、反面示例、历史版本说明等。
- 激活一次技能,几乎等价于把整个文档都塞给模型,初始加载就吞掉大量 token。
- 典型任务中,如果同时激活多个技能,总上下文行数动辄数千行,模型需要在一堆噪声中寻找关键指令。
重构后的结构
按照前文“三层结构 + 工作流视角”的原则,他做了这样的调整:
- Level 1 元数据层:
- 用极短的 YAML 描述技能名称、能力标签与适用场景,例如“部署无服务器函数”“调试 TypeScript 单元测试”等。
- 作为统一索引,被 Agent 用于技能发现与初选。
- Level 2 SKILL.md:
- 严格控制在约 200 行,保留:
- 能力概览与边界说明;
- 主干 SOP 流程(偏伪代码级);
- 引用文件索引与“何时读取某文件”的指引。
- 删除冗长解释,将示例、长故事、详细条款迁移到引用文件。
- 严格控制在约 200 行,保留:
- Level 3 附属文件层:
- 按主题拆分成多个 200–300 行的 Markdown 文档(如“Cloudflare Worker 部署步骤”“UI 组件命名规范”);
- 在 SKILL.md 中通过简短说明引导模型“按需打开”,避免一次性全部加载。
定量收益
在对比前后同一类任务(例如代码修改和部署)时,可以看到非常明显的改进趋势:
- 初始加载内容大幅下降:
- 同一技能激活时,首次加载行数从约 800+ 行降到 200 行左右。
- Token 利用率提升约 4.8 倍:
- 在典型多轮任务中,同样的上下文预算下,可承载更多与当前任务强相关的内容,冗余信息显著减少。
- 响应延迟与溢出风险降低:
- 由于每轮调用需要扫描的上下文量缩减,响应速度明显提升;
- 上下文溢出从“经常发生”变成“极端长会话中的偶发问题”。
结合其他关于上下文工程的实战经验,这种量级的 token 节省与性能提升,在多步长链路、多 Agent 场景中会被成倍放大,带来显著的成本与稳定性优势。
实战落地:为你的 Agent 做一次“技能体检”
如果你已经在项目里使用 Skills/Tools,可以按下面这套流程为自己的 Agent 做一次系统“体检与瘦身”。
第一步:做一份技能审计表
对当前所有技能进行全面盘点,重点关注:
- 每个 SKILL.md 的行数与大致 token 规模。
- 是否存在大量历史说明、长篇背景描述、重复示例。
- 一个典型业务工作流(如“新需求开发 → 测试 → 部署”)需要激活多少技能,总共加载了多少行内容。
可以简单用脚本统计每个技能目录的文件行数,并在真实调用日志中抽样查看每轮请求的上下文大小。
第二步:重构技能边界(从工具到能力)
对每个技能问三个问题:
- 它解决的是哪个“能力缺口”?
- 这个能力通常出现在工作流的哪个阶段?
- 当前技能边界是否只围绕一个主线任务?
在这个基础上:
- 将高度耦合的工具技能合并到同一个能力技能组,例如 devops、ui-styling、data-ingestion 等。
- 对过大、覆盖多条能力线路的技能进行拆分,使每个技能在心智模型中一句话就能描述清楚。
- 为每个技能写一段不超过两行的“使命描述”,帮助模型判断何时使用它。
第三步:按三层结构重写技能目录
围绕每个重构后的技能,按三层模型重新搭建目录结构:
- Level 1 元数据:
- 使用简洁的 YAML 或注释,包含名称、标签、适用场景和依赖关系。
- Level 2 SKILL.md:
- 200 行左右的入口文件,只保留:
- 能力边界说明;
- 主流程 SOP;
- 引用资源列表与使用指引。
- 200 行左右的入口文件,只保留:
- Level 3 附属文件:
- 将详细说明、示例、配置、扩展场景放入独立文件中;
- 在 SKILL.md 中通过“当出现 X 场景时,请阅读 Y 文件”的方式显式链接。
注意在正文中明确告诉模型“不要一次性加载所有引用文件,而是根据当前任务逐步展开”,以强化渐进式披露的行为模式。
第四步:引入“200 行规则”和冷启动测试
为避免技能在迭代中慢慢“长胖”,可以制定几条简单的团队规范:
- SKILL.md 不超过 200 行,一旦超过就必须拆分或迁移内容到引用文件。
- 冷启动测试:
- 清空会话,仅激活某一个技能,统计首次加载总行数/总 token。
- 将“冷启动上下文 ≤ 500 行”作为红线阈值,超出则触发重构。
- 关键工作流的上下文预算:
- 为典型工作流设置最大可接受上下文预算(例如 8k token),定期检查真实调用是否超限。
这些指标不必一开始就极端严格,但一旦设定,就应纳入自动化测试或上线前检查流程,保证体系长期保持健康。
第五步:观测与迭代
重构之后,不要只看“有没有更快”,更要关注:
- 任务成功率是否提升、幻觉是否减少。
- 模型是否更倾向按照预期 SOP 行事,而不是随机发挥。
- 工程团队是否更容易理解与维护 Skills 文档,而非把它当成一次性“提示词工程”。
结合实际调用日志,可以继续微调技能拆分粒度、入口信息密度,以及附属文件的组织方式,形成一套适合自己团队的“上下文工程基线”。
结语:上下文工程是 Agent 的“架构活”
回头看这几年 Agent 的发展脚步,可以看到一个越来越清晰的趋势:单轮提示词调优的重要性在下降,而上下文工程与技能架构设计的价值在上升。
对正在一线做 Agent 系统的开发者和技术负责人来说,有几点值得长期记住:
- Skills 是“能力模块”,不是“长文档”,它们需要结构化、可组合、可渐进展开。
- 上下文是“工作内存”,不是“知识仓库”,真正庞大的知识和工具应该通过文件系统与执行环境托管在模型之外。
- 技能边界应围绕工作流阶段而不是工具产品线设计,才能让 Agent 在现实任务中跑得顺、跑得久。
- 用硬指标(行数、token、冷启动成本)来约束技能演化,是把上下文工程从“玄学”变成“工程”的关键一步。
当你开始像设计系统架构那样设计 Skills,而不仅仅是在界面里堆提示词时,你的 Agent 会从“偶尔惊艳”变成“稳定可靠”,真正成为团队工作流的一部分,而不是一个孤立的聊天玩具。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 37
37 0
0- 0



 已为社区贡献114条内容
已为社区贡献114条内容

所有评论(0)