入门篇--知名企业-14-阿里巴巴-2--阿里巴巴AI全景:从电商大脑到AI生态的跃迁之路
阿里巴巴构建了覆盖AI全栈的生态体系,从基础设施、核心模型到行业应用。其通义千问(Qwen)系列大模型已发展至Qwen3,包含从0.5B到72B的全尺寸开源模型,支持文本、图像、代码等多模态处理。阿里云提供算力支持,平头哥芯片优化推理效率,百炼平台降低开发门槛。通义模型已在编程、办公、金融等8大领域落地,形成全球最大开源大模型生态之一。阿里通过"全栈自研+生态开放"策略,推动A
阿里巴巴的AI征途:从通义千问到全栈大模型生态
作者:Weisian
AI科技博主 · 开源社区贡献者 · 大模型实践者 · 相信中国AI应有世界话语权

博主前言
在全球AI竞赛白热化的今天,阿里巴巴无疑是中国最值得关注的科技巨头之一。不同于仅聚焦单一环节的企业,阿里走的是“全栈自研 + 生态开放”的独特路径——上至千亿参数的基础大模型,下至终端设备的落地应用,中间由算力基建与平台工具强力支撑。
近三年来,阿里在AI领域的投入与产出极为惊人:
- 3800亿元的AI基础设施投入;
- 构建起全球第一的开源大模型生态;
- 实现覆盖亿级用户的真实商业落地。
通义千问(Qwen)并非横空出世的黑马,而是阿里十年AI技术沉淀的一次集中爆发——从达摩院的基础研究,到阿里云的工程化落地,再到淘宝、钉钉、高德等亿级场景的真实锤炼。
更令人振奋的是,阿里选择了“开源”这条少有人走的路。在闭源模型主导商业竞争的当下,阿里不仅开放了从7B到72B的全系列大语言模型权重,还同步开源了多模态、语音、代码、推理优化等完整技术栈,构建起中国最活跃、最完整的开源大模型生态之一。
本文将以一名深度使用并参与多个通义项目的开发者视角,系统梳理以下核心问题:
- ✅ 通义大模型全家桶到底有哪些?
- ✅ 它们的技术亮点与实测表现如何?
- ✅ 普通开发者和企业如何真正用起来?
- ✅ 阿里AI战略背后的底层逻辑是什么?
无论你是想微调专属客服模型、探索多模态生成,还是评估国产大模型能否替代GPT-4,这篇内容都将提供一手、真实、可操作的答案。
一、阿里AI的演进:从“电商智能”到“通用智能”
1.1 早期实战驱动阶段(2009–2016)
双十一:阿里的AI“压力测试场”
2009年首届双十一期间,商品推荐主要依赖硬编码规则。例如,若用户购买过手机,则系统会推荐手机壳或充电宝。这种简单逻辑在流量激增时迅速失效。

真正的转折点出现在2012年——系统因高并发崩溃,迫使阿里全面转向数据驱动的AI解决方案。
关键里程碑:
- 2012年:成立iDST(数据科学与技术研究院),正式启动AI基础研究;
- 2014年:推荐系统全面升级为机器学习模型,点击率预估(CTR)能力显著提升;
- 2015年:“拍立淘”上线,支持以图搜物,标志着计算机视觉进入大规模商用;
- 2016年:受AlphaGo启发,阿里将AI提升至集团战略高度。
一个标志性故事:2015年团队用一张奶茶照片测试“拍立淘”,系统竟推荐了同款杯、吸管甚至相似颜色的衣服。那一刻,我们意识到——计算机视觉的商业化时代真的来了。
1.2 技术体系化阶段(2017–2020)
达摩院成立:从“业务驱动”到“前瞻研究”
2017年云栖大会上,马云宣布成立达摩院,并承诺三年投入1000亿元。其组织架构聚焦三大方向:
- 机器智能实验室:负责NLP、计算机视觉、语音识别等基础AI研究;
- 数据计算实验室:攻关芯片、数据库、操作系统等底层技术;
- 金融科技实验室:探索区块链、风控、安全等金融级应用。
真实需求驱动创新:2018年,达摩院语音团队攻坚“方言识别”。一位工程师坦言:“淘宝上有大量不会说普通话的卖家和买家,这是真实的业务需求,也是技术的社会价值。”

二、基础设施层:AI的“算力底座”
2.1 阿里云:中国AI开发者的“水电煤”
阿里云已成为中国AI开发的核心基础设施,具备以下特征:
- 市场份额领先:中国公有云IaaS份额连续多年稳居第一(约35%);
- 开发者规模庞大:超300万AI开发者在其平台上构建应用;
- 算力集群强大:拥有全球最大的飞天AI训练集群之一。

典型开发者工作流(基于阿里云PAI平台)
开发者在阿里云上完成AI项目通常遵循三步流程:
- 数据准备:从OSS对象存储加载原始数据,并通过内置工具自动清洗、标注;
- 模型训练:选择PyTorch/TensorFlow框架,在高性能GPU实例(如ecs.gn7i,搭载A10 GPU)上进行分布式训练;
- 模型部署:一键发布为实时推理服务,支持自动扩缩容与QPS监控。

据阿里云官方数据,该流程相比自建GPU集群可降低约60%的综合成本。
核心技术亮点:
- 神龙计算架构:实现近乎零虚拟化开销,训练效率提升30%,成本下降25%;
- PAI全栈平台:
- PAI-DSW:交互式Notebook开发环境;
- PAI-DLC:容器化深度学习训练服务;
- PAI-EAS:低代码模型部署引擎;
- PAI-Designer:可视化拖拽建模工具;
- 多样化实例族:覆盖从边缘推理(gn6v)到千亿模型训练(ebmgn7ex)的全场景需求。
2.2 平头哥半导体:自研AI芯片的突破
阿里旗下平头哥半导体推出的“含光”系列AI芯片,专为高能效推理设计:
- 含光800(2019年):在ResNet-50模型上达到78,563 FPS,能效比达500 FPS/W,广泛应用于淘宝搜索、拍立淘等场景;
- 含光800升级版(2022年):新增对Transformer架构的硬件优化,BERT推理性能提升300%,并开始支持轻量级训练任务;
- 倚天710(2022年):基于ARM架构的通用服务器CPU,128核设计,性能领先同期产品20%,能效提升50%。
软硬协同优势显著:算法团队提出“需要稀疏计算支持”后,芯片团队仅用3个月即完成硬件适配——这种敏捷迭代能力,是互联网公司自研芯片的独特优势。

三、核心产品矩阵:覆盖AI全链路的三层体系
阿里AI布局遵循“底座 → 工具 → 应用”的闭环逻辑。
3.1 基础模型层:通义千问(Qwen)系列
通义千问的演进体现了从可用到卓越的跨越:
| 时间 | 版本 | 核心突破 |
|---|---|---|
| 2023.04 | Qwen 1.0 | 首次公开,集成至钉钉、淘宝 |
| 2023.10 | Qwen 2.0 | 千亿参数规模,推出8大行业模型 |
| 2024.06 | Qwen2系列 | 开源0.5B至72B全尺寸模型,支持128K上下文 |
| 2025.01 | Qwen2.5-Max | 预训练数据超20万亿tokens,综合性能对标GPT-4 |
| 2025.04 | Qwen3系列 | 中国首个“混合推理模型”,总参数235B,激活仅22B |
| 2025.07 | Qwen-Image / Qwen3-Coder | 完成文本、图像、代码全模态覆盖 |
截至2025年4月,通义开源模型数量超200个,全球下载量突破3亿次,衍生模型超10万个,正式超越Llama系列,成为全球最大开源大模型生态。所有模型均采用 Apache 2.0 协议,允许免费商用。
3.2 平台工具层:MaaS 2.0时代的全栈服务商
- 百炼平台:提供从精调、评估到部署的一站式企业AI开发体验;
- Aegaeon系统:支持多模型动态路由与混合推理,实测GPU资源消耗降低82%;
- PAI-灵骏:面向超大规模模型的智算服务平台,可支撑千亿参数训练。
平台设计高度开发者友好:
- 模型同步发布于 Hugging Face 与 ModelScope(魔搭);
- 支持云端微调与本地私有化部署;
- Qwen-7B可在消费级显卡(如RTX 3090)上流畅运行,真正实现“人人可玩AI”。

3.3 行业应用层:8大垂直模型 + 全场景落地
阿里针对高频场景推出专业化模型:
| 模型 | 领域 | 核心能力 |
|---|---|---|
| 通义灵码 | 编程 | 支持30+语言,代码生成、修复、注释 |
| 通义智文 | 办公 | 长文档摘要、多语言翻译、格式转换 |
| 通义听悟 | 音频 | 语音转写、会议纪要、多语种字幕 |
| 通义星尘 | 创意 | 文案、海报、短视频脚本生成 |
| 通义点金 | 金融 | 市场分析、风险预警、财报解读 |
| 通义晓蜜 | 客服 | 7×24智能客服,大幅降低人力成本 |
| 通义仁心 | 医疗 | 病历分析、影像解读、用药建议 |
| 通义法睿 | 法律 | 合同审查、法条检索、案例分析 |
端侧多模态突破:2025年3月发布的 Qwen2.5-Omni-7B,仅7B参数即可处理文本、图像、音频、视频输入,采用创新的 Thinker-Talker 架构与 TMRoPE 位置编码,显著降低音视频响应延迟,适用于视障导航、烹饪指导等场景。
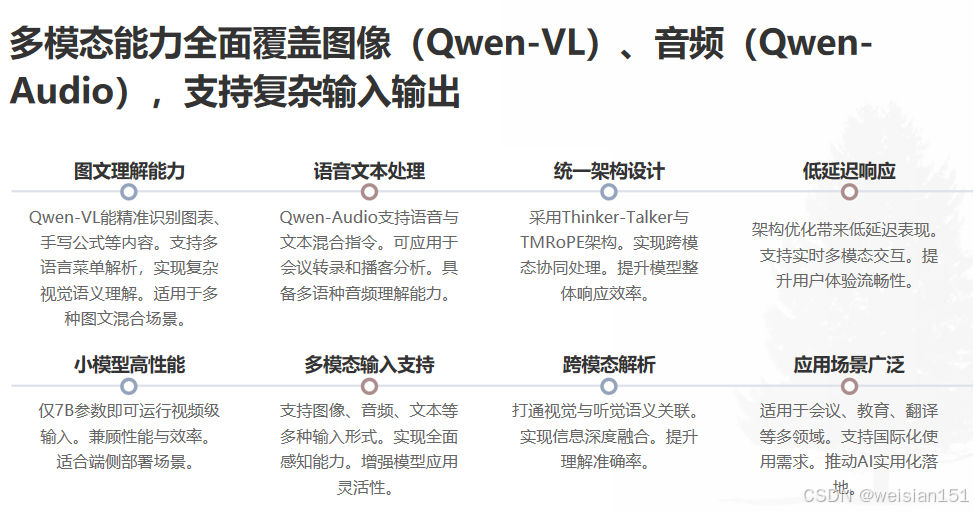
四、通义大模型家族全景图
很多人以为“通义千问 = Qwen”,实则远不止于此。阿里构建的是覆盖语言、视觉、语音、代码、推理、具身智能的全栈AI体系。
4.1 核心语言模型系列(Qwen)
| 模型 | 参数量 | 特点 | 开源状态 | 适用场景 |
|---|---|---|---|---|
| Qwen-Max | ~72B | 最强性能,复杂任务 | API Only | 企业级高精度问答 |
| Qwen-Plus | 中等 | 速度与效果平衡 | API + 部分开放 | 中等复杂度任务 |
| Qwen-Turbo | 小规模 | 极快响应,低成本 | API | 高频简单问答 |
| Qwen-72B | 72B | 开源最强中文模型之一 | ✅ Apache 2.0 | 本地部署、研究、微调 |
| Qwen-32B/14B/7B/1.8B/0.5B | 逐级递减 | 覆盖端到云全场景 | ✅ 全部开源 | 手机、嵌入式、边缘设备 |
关键突破:
- 超长上下文:最高支持32,768 tokens;
- 强中文理解:C-Eval、CMMLU榜单长期第一;
- 多语言支持:覆盖100+语言,含泰米尔语、斯瓦希里语;
- 推理优化:通过 vLLM/TensorRT-LLM,7B模型可在消费级显卡实时运行。
4.2 多模态模型:让AI“看懂”世界
- Qwen-VL / Qwen-VL-Chat:支持图像+文本输入,可识别复杂图表、手写公式、多语言菜单,权重与代码全开源;
- Qwen-Audio / Qwen-Audio-Chat:支持音频+文本输入,用于会议纪要、语音客服、播客分析;
- 注:早期多模态框架 OFA 已升级为 Qwen-VL 技术底座。
4.3 垂直能力模型:专精领域的“专家”
| 模型 | 领域 | 能力 | 开源状态 |
|---|---|---|---|
| Qwen-Coder | 编程 | 支持80+语言,代码生成/解释 | ✅ |
| Qwen-Math | 数学 | 解题、证明、符号计算 | ✅ |
| Qwen-Bio | 生物医药 | 蛋白质结构预测、文献挖掘 | 部分开源 |
| Qwen-Agent | 智能体 | 工具调用、自主规划、多步推理 | 开发中 |
所有模型均可通过 ModelScope(魔搭)平台 组合调用,构建复杂AI工作流。
五、关键技术成就:从科研突破到全球认可
5.1 核心技术创新
- 混合推理架构(Qwen3):集成“快思考+慢思考”,激活参数仅22B,部署成本降至4张H20显卡;
- 注意力门控技术:获 NeurIPS 2025 最佳论文奖,首token注意力占比从46.7%降至4.8%;
- 多模态融合:TMRoPE + 区块串流处理,实现音视频低延迟同步;
- 长上下文处理:Qwen3-30B-A3B 支持 256K tokens,轻松处理百万字文档。
5.2 行业权威认可
2025年12月,国际机构 Omdia 发布《全球企业级MaaS市场分析》,阿里云获评全球领导者,在以下5大维度获最高评级:
- 基础模型丰富性
- 模型精调能力
- Agent开发支持
- 成本优化水平
- 生产部署成熟度
成为中国首个在MaaS领域获此殊荣的企业。
5.3 全球客户覆盖
- 服务超 100万家企业客户;
- 国际客户:国际奥委会、宝马、LV、欧莱雅、西门子、星巴克;
- 国内市场:2025上半年,超70%《财富》中国500强企业采用生成式AI,阿里云渗透率高达53%,居行业第一。
六、真实应用场景:AI在阿里体系内“活”起来
6.1 电商:AI重构购物全链路(2025天猫双11)
消费者端:
- 对话式搜索理解复杂语义(如“两岁半女儿不爱刷牙该买什么”),相关性提升20%;
- 个性化推荐点击率实现双位数增长;
- “拍立淘”升级:拍照即推荐商品,识别包装文字,助力长者。
商家端:
- 虚拟“AI团队”:静态图生成营销视频;
- AI美工月产2亿图、500万视频,点击率提升10%;
- AI生意参谋生成1000万份经营报告;
- AI客服“店小蜜”日省2000万元运营成本;
- AI竞价机制提升广告ROI 12%。
此次落地证明:AI不是“锦上添花”,而是重塑电商底层逻辑的核心生产力。
6.2 办公:钉钉的AI全面改造
用户输入任意指令,即可唤起十余项AI能力:会议纪要、文案撰写、应用搭建、实时翻译。截至2023年11月,17条产品线全面智能化,并开放AI PaaS底座赋能生态伙伴。
前沿实验:通过钉钉自然语言指令远程操控工业机器人,实现“办公直达生产”。
6.3 多场景渗透
- 高德地图:AI语音助手支持复杂指令(如“找评分4.5+带充电桩的火锅店”);
- 饿了么:AI调度优化配送路径;
- 菜鸟:AI仓储机器人自动分拣、精准库存管理;
- 工业制造:AI质检系统快速识别缺陷,提升合格率。
阿里AI已渗透至商业运转的每一个毛细血管。
七、开源生态:中国AI的“Linux时刻”
7.1 魔搭(ModelScope):中国的 Hugging Face
- 模型数量:超5万个(截至2025年);
- 通义专区:Qwen全系列一键部署;
- 特色功能:
- 在线 Notebook(免配置);
- 模型推理 Demo;
- 微调模板(LoRA/DPO/RLHF)。
作者实测:用魔搭 + Qwen-7B + LoRA,在24GB显存下3小时训练出法律咨询助手,准确率超85%。
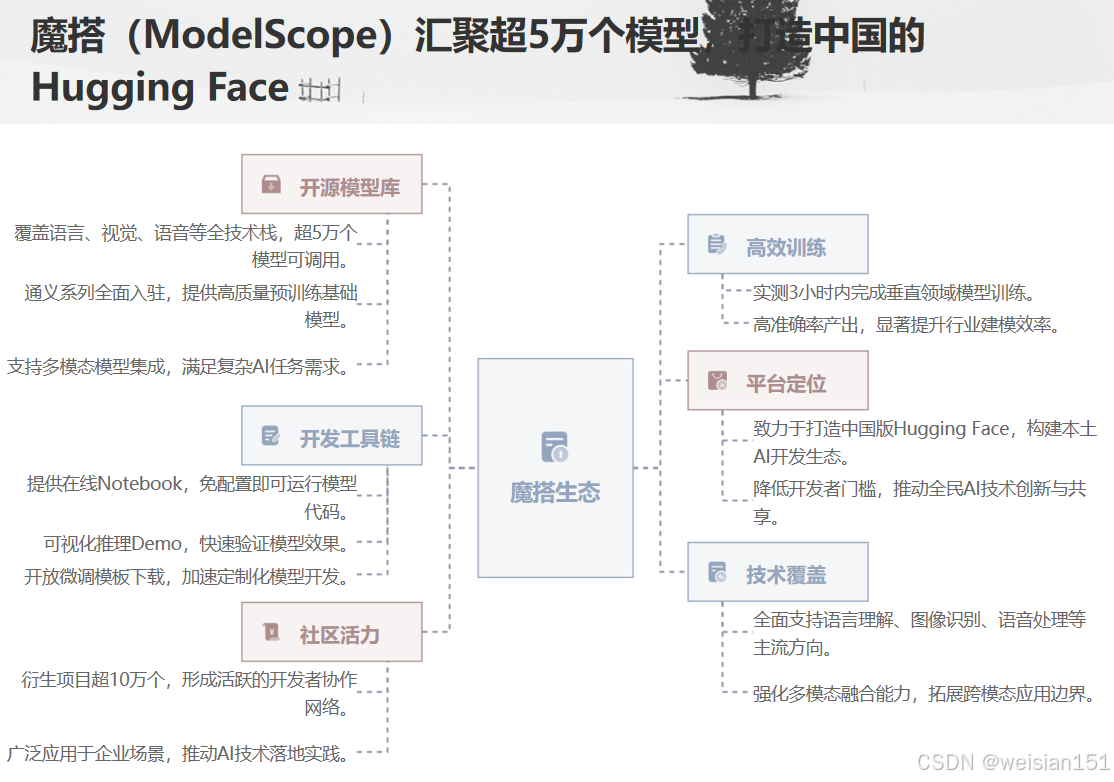
7.2 社区活跃度:真正在“用”的开源
- GitHub Stars:Qwen官方仓库超 50k+;
- 衍生项目:
- Qwen-Agent(智能体框架)
- Qwen-Chinese-Chat(中文优化版)
- Qwen-Mobile(手机端量化方案)
- 企业采用:小米、OPPO、招商银行、国家电网等已用于内部知识库、客服、数据分析。
八、技术特色与差异化优势
8.1 超大模型训练能力
飞天AI平台支持超大规模训练:
- GPU集群规模:超10,000张卡;
- 自研RDMA网络:延迟 < 2微秒;
- OSS存储带宽:100GB/s;
- 并行策略:3D并行(数据+流水线+张量)。
关键技术:
- 非均匀流水线并行;
- 混合精度训练(FP16+FP32);
- 梯度压缩与断点续训。
8.2 多模态融合技术
通义万象架构包含:
- 文本编码器:Qwen-72B;
- 视觉编码器:ViT-Huge + VideoSwin;
- 对齐模块:Cross-attention + 对比学习;
- 生成器:扩散模型(图) + 自回归(文)。
特色能力:
- 中文场景理解(如“水墨风孙悟空”);
- 文档结构化提取(发票/合同/表格,准确率99%);
- 视频摘要(10分钟视频30秒生成摘要)。
8.3 安全与对齐技术
阿里构建了完整的AI治理框架,包含:
- 安全过滤(有害内容拦截率99.9%);
- 偏见检测(覆盖100+敏感维度);
- 响应后审计与隐式水印;
- 关键决策可解释性。
九、为什么选择通义?对比国际主流模型
| 维度 | Qwen-72B | Llama 3 70B | GPT-4 | Claude 3 Opus |
|---|---|---|---|---|
| 中文能力 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 开源程度 | ✅ 完全开源 | ✅ 权重开源 | ❌ 闭源 | ❌ 闭源 |
| 商用许可 | Apache 2.0(可商用) | Meta许可(有限制) | 付费API | 付费API |
| 多模态 | ✅ Qwen-VL/Audio | ❌ | ✅ | ✅ |
| 本地部署 | ✅ 支持 | ✅ 支持 | ❌ | ❌ |
| 中文社区 | 极活跃 | 一般 | 无 | 无 |
结论:
- 若需完全可控、可商用、私有化部署的中文大模型 → Qwen 是当前最优解;
- 若追求极致英文或黑盒体验 → 选 GPT-4 或 Claude。
十、给开发者的实用指南
10.1 快速上手路径
路径一:云端API(最快)
可通过 DashScope SDK 调用通义千问模型:
# 快速上手示例:调用 qwen-max(需安装 dashscope)
from dashscope import Generation
response = Generation.call(model="qwen-max", prompt="用Python写快速排序")
路径二:本地部署(安全)
使用 ModelScope 下载开源模型并在本地运行:
# 本地部署示例(需安装 modelscope + vLLM)
from modelscope import snapshot_download
model_dir = snapshot_download("qwen/Qwen-7B-Chat")
# 后续通过 vLLM 或 Transformers 加载推理
免费资源:
- 通义千问网页版(免费体验);
- ModelScope(开源模型免费下载);
- 阿里云(每月免费额度)。
10.2 微调与定制化
微调策略建议:
- 数据量 < 1,000 且显存 < 16GB:优先使用提示词工程;
- 数据量 < 10,000 且显存 ≥ 24GB:推荐 LoRA 微调;
- 数据量 ≥ 10,000 且显存 ≥ 80GB:可考虑全参数微调。
作者实战经验(法律咨询模型):
- 提示词工程:70%准确率;
- LoRA微调(约500元):85%;
- 全参微调(约5000元):89%;
最终选择LoRA,性价比最优。
10.3 性能优化技巧
推理优化建议:
- 量化:采用 W8A8 量化,速度提升3–5倍;
- 动态批处理:提升吞吐量;
- KV缓存优化:减少重复计算;
- 硬件加速:优先选用含光800芯片。
成本控制建议:
- 预热实例避免冷启动;
- 设置自动扩缩容;
- 缓存常见请求结果;
- 优先选用7B而非70B模型(性价比更高)。
十一、未来展望:阿里AI的三大方向
- Agent智能体:AI从“回答问题”进化为“完成任务”(如订机票、写周报、调试代码);
- 端云协同:Qwen-Tiny运行于手机,Qwen-Max部署于云端,无缝切换;
- AI for Science:加速药物研发、气候模拟、材料设计。
阿里CTO周靖人:“未来的操作系统,是AI操作系统。”
而通义,就是阿里的答案。
十二、博主总结:阿里AI的核心竞争力与未来展望
阿里的AI长征:三个瞬间
- 2015年双十一:AI推荐系统首次扛住912亿GMV,技术团队欢呼:“我们的AI真的撑住了。”
- 2023年云栖大会:老开发者感慨:“从买虚拟机到调大模型,这是技术的传承。”
- 上周:大学生团队用Qwen-7B开发乡村法律助手,帮助老人语音咨询——“AI让技术有了温度。”
阿里AI的核心竞争力
不是某一项技术领先,而是“全栈自研 + 生态开放 + 商业落地”的闭环能力:
- 基础设施:云 + 芯片;
- 基础模型:通义系列;
- 行业应用:零售、医疗、城市等;
- 开发者生态:魔搭 + 百炼;
- 商业化路径:从双11到全球500强。
这种体系化作战能力,让阿里实现“更多应用 → 更多数据 → 更好模型 → 更多应用”的正向循环。
给不同角色的建议
- 学习者:从 ModelScope 开始,亲手运行开源模型;
- 开发者:关注阿里云AI平台,离商业最近;
- 创业者:在生态中找细分机会,勿重复造轮子;
- 观察者:关注阿里如何平衡开源与商业、创新与责任。
结语:开源,是中国AI走向世界的船票
曾在硅谷AI峰会上,一位美国工程师对我说:
“你们中国的 Qwen,是我们实验室现在最常测试的开源模型之一。”
那一刻我明白:
技术无国界,但话语权有。
当西方巨头用闭源筑起高墙,阿里选择打开大门——
把模型、工具、文档、社区,全部交给开发者。
这不是慈善,而是一种信念:
真正的AI革命,不属于某一家公司,而属于每一个敢于创造的人。
如果你还没尝试通义千问,不妨今天就去魔搭点开一个 Demo,
输入一句:
“请用李白的风格,写一首关于AI的诗。”
看看中国大模型,如何用千年诗意,回应未来之问。

资源附录:深入学习路径
动手实践
- ModelScope:开源模型库
- 阿里云百炼:大模型开发平台
- 通义千问体验
技术文档
学习课程
- 阿里云AI认证体系
- 吴恩达 × 阿里云《大模型实践》课程
- 云栖大会技术分论坛回放
推荐学习顺序
- 第一周:通义千问网页版体验
- 第二周:ModelScope 下载 Qwen-7B 本地运行
- 第三周:阿里云PAI平台训练首个模型
- 第四周:基于Qwen开发一个简单应用
作者后记
上周,我用 Qwen-VL 帮一位视障朋友“看”了一张老照片。
AI描述道:“一位老人坐在桂花树下,手里拿着一封泛黄的信,阳光透过树叶洒在他肩上。”
他听完后沉默良久,说:“那是我父亲。谢谢你,让我再次‘看见’他。”
这就是AI该有的样子——
不炫技,不割韭菜,
只是温柔地,帮人连接那些被遗忘的光。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)