英伟达收购 Jamba 模型的母公司AI21 — Nvidia in advanced talks to buy Israel‘s AI21 Labs for up to $3 billion
Jamba是一款采用SSM-Transformer混合架构的尖端大语言模型。相较于传统基于Transformer的模型,它能显著提升吞吐效率,同时在多数主流基准测试中表现优于或持平同规模级别的领先模型。作为首个实现生产级规模的Mamba架构模型,Jamba为研究和应用开辟了新的可能性。虽然初期实验已展现出令人鼓舞的优势,我们预期通过后续优化与探索将进一步提升其性能。
A 2023 funding round valued AI21 at $1.4 billion. Nvidia and Alphabet's (GOOGL.O), opens new tab Google participated in that funding.
AI21, founded in 2017 by Amnon Shashua and two others, is among a clutch of AI startups that have benefited from a boom in artificial intelligence, attracting strong interest from venture capital firms and other investors.
Shashua is also the founder and CEO of Mobileye, a developer of self-driving car technologies.
Calcalist said AI21 has long been up for sale and talks with Nvidia have advanced significantly in recent weeks. It noted that Nvidia's primary interest in AI21 appears to be its workforce of roughly 200 employees, most of whom hold advanced academic degrees and "possess rare expertise in artificial intelligence development."
Calcalist said the deal to buy AI21 is estimated at between $2 billion and $3 billion.
Nvidia, which has become the most valuable company in history at more than $4 trillion, is planning a large expansion in Israel with a new R&D campus of up to 10,000 employees in Kiryat Tivon, just south of the port city of Haifa - Israel's third-largest city.
Nvidia CEO Jensen Huang has described Israel as the company’s "second home."
Nvidia has said that when completed, the campus will include up to 160,000 square meters (1.7 million square feet) of office space, parks and common areas across 90 dunams (22 acres), inspired by Nvidia's Santa Clara, California, headquarters. Nvidia expects construction to begin in 2027, with initial occupancy planned for 2031.
Reporting by Steven Scheer; Editing by Lisa Shumaker
-----------------------
2023年一轮融资使AI21 Labs估值达到14亿美元。英伟达和谷歌母公司Alphabet参与了该轮投资。
这家2017年由Amnon Shashua等三人联合创立的公司,是乘着人工智能热潮崛起的初创企业代表之一,获得了风投机构和其他投资者的强烈关注。Shashua同时还是自动驾驶技术开发商Mobileye的创始人兼CEO。
当地媒体披露,AI21 Labs长期处于待售状态,与英伟达的谈判近几周取得重大进展。报道指出英伟达主要看中其约200人的研发团队,其中多数拥有高等学历并"具备人工智能开发领域的稀缺专长"。
据估算这笔收购交易金额将在20至30亿美元之间。
市值突破4万亿美元成为史上最具价值企业的英伟达,正计划在以色列大幅扩张业务——将在港口城市海法(以色列第三大城市)南郊的Kiryat Tivon建设可容纳万名员工的新研发园区。英伟达CEO黄仁勋将以色列称为公司的"第二故乡"。
该公司表示,占地22英亩的园区建成后将包含16万平方米办公空间及配套绿地,设计灵感源自加州圣克拉拉总部。建设工程预计2027年启动,首批设施计划2031年投入使用。
https://huggingface.co/ai21labs
Use Cases
Jamba’s long context efficiency, contextual faithfulness, and steerability make it ideal for a variety of business applications and industries, such as:
- Finance: Investment research, digital banking support chatbot, M&A due diligence.
- Healthcare: Procurement (RFP creation & response review), medical publication and reports generation.
- Retail: Brand-aligned product description generation, conversational AI.
- Education & Research: Personalized chatbot tutor, grants applications.
Jamba的长上下文效率、上下文忠实度和可操控性使其成为各种商业应用和行业的理想选择,例如:
金融领域:投资研究、数字银行支持聊天机器人、并购尽职调查。
医疗健康:采购(RFP创建与响应审核)、医学出版物和报告生成。
零售行业:符合品牌定位的产品描述生成、对话式人工智能。 教育与研究:个性化聊天机器人导师、资助申请撰写。
https://huggingface.co/ai21labs/Jamba-v0.1
Jamba is a state-of-the-art, hybrid SSM-Transformer LLM. It delivers throughput gains over traditional Transformer-based models, while outperforming or matching the leading models of its size class on most common benchmarks.
Jamba is the first production-scale Mamba implementation, which opens up interesting research and application opportunities. While this initial experimentation shows encouraging gains, we expect these to be further enhanced with future optimizations and explorations.
This model card is for the base version of Jamba. It’s a pretrained, mixture-of-experts (MoE) generative text model, with 12B active parameters and a total of 52B parameters across all experts. It supports a 256K context length, and can fit up to 140K tokens on a single 80GB GPU.
Jamba是一款采用SSM-Transformer混合架构的尖端大语言模型。相较于传统基于Transformer的模型,它能显著提升吞吐效率,同时在多数主流基准测试中表现优于或持平同规模级别的领先模型。
作为首个实现生产级规模的Mamba架构模型,Jamba为研究和应用开辟了新的可能性。虽然初期实验已展现出令人鼓舞的优势,我们预期通过后续优化与探索将进一步提升其性能。
本模型卡对应Jamba基础版本。该预训练模型采用专家混合(MoE)架构,具备120亿活跃参数及总计520亿专家参数,支持256K上下文长度,可在单块80GB GPU上处理高达14万token的文本内容。
论文
https://arxiv.org/pdf/2403.19887
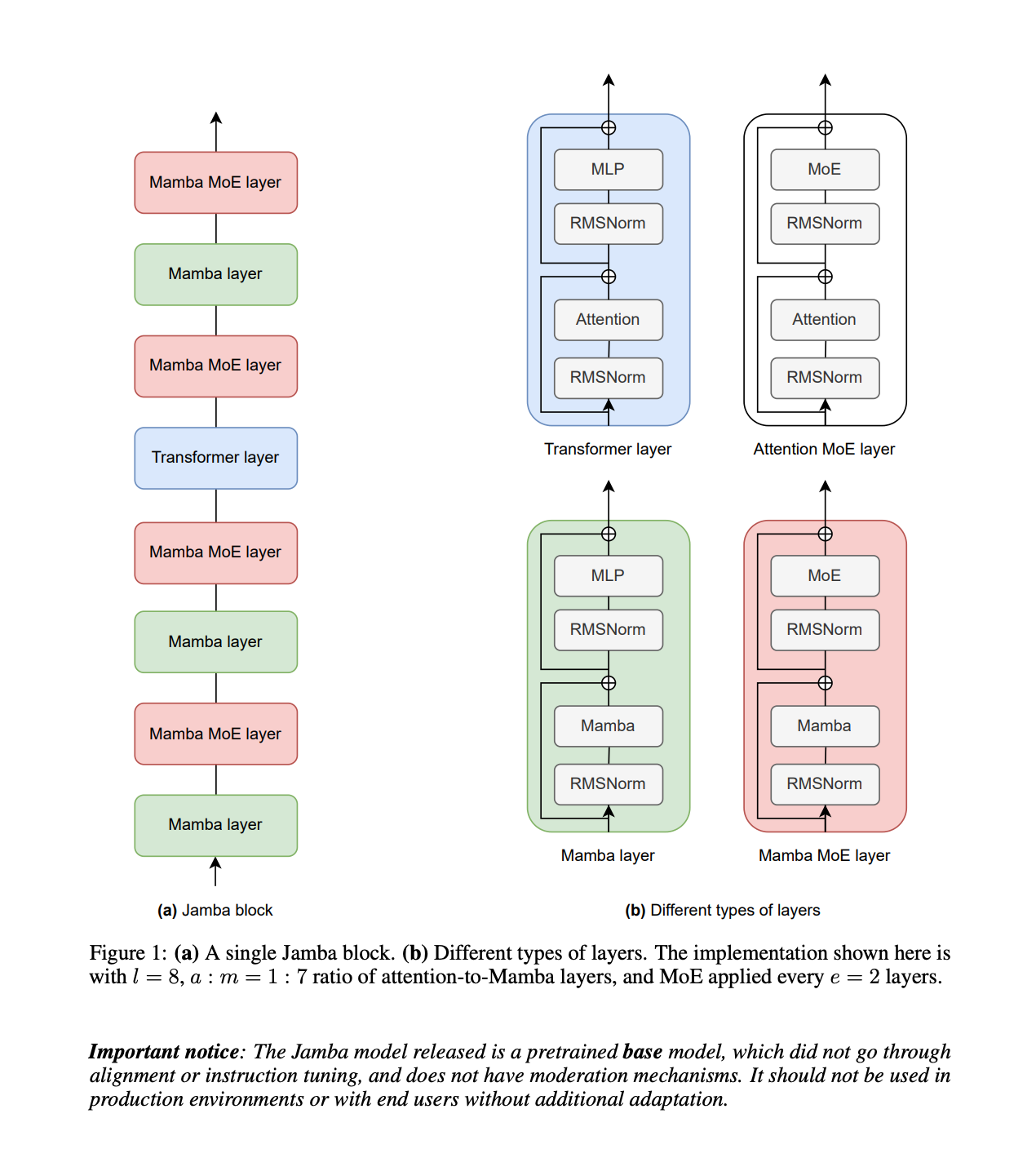
We present Jamba, a new base large language model based on a novel hybrid Transformer-Mamba mixture-of-experts (MoE) architecture. Specifically, Jamba interleaves blocks of Transformer and Mamba layers, enjoying the benefits of both model families. MoE is added in some of these layers to increase model capacity while keeping active parameter usage manageable. This flexible architecture allows resource- and objective-specific configurations. In the particular configuration we have implemented, we end up with a powerful model that fits in a single 80GB GPU. Built at large scale, Jamba provides high throughput and small memory footprint compared to vanilla Transformers, and at the same time state-of-the-art performance on standard language model benchmarks and long-context evaluations. Remarkably, the model presents strong results for up to 256K tokens context length. We study various architectural decisions, such as how to combine Transformer and Mamba layers, and how to mix experts, and show that some of them are crucial in large scale modeling. We also describe several interesting properties of these architectures which the training and evaluation of Jamba have revealed, and plan to release checkpoints from various ablation runs, to encourage further exploration of this novel architecture. We make the weights of our implementation of Jamba publicly available under a permissive license. Model: https://huggingface.co/ai21labs/Jamba-v0.1
我们推出Jamba——一种基于新型混合架构(结合Transformer与Mamba专家混合系统MoE)的基础大语言模型。该模型创新性地交错堆叠Transformer模块与Mamba层,兼具两类架构优势。部分层级引入MoE机制,在保持可控激活参数量的同时扩展模型容量。这种灵活架构支持根据资源条件和目标任务进行定制化配置。在我们实现的特定配置中,最终模型仅需单块80GB GPU即可部署。大规模构建的Jamba相比传统Transformer架构,既实现了高吞吐量与低内存占用,又在标准语言模型基准测试和长上下文评估中达到业界顶尖水平。值得注意的是,该模型在长达256K token的上下文窗口中仍保持强劲性能。我们深入研究了多种架构决策(如Transformer与Mamba层的组合方式、专家混合策略等),揭示其中某些设计对大规模建模的关键影响。基于Jamba训练评估过程中发现的结构特性,我们将发布多组消融实验检查点,以促进对这一创新架构的持续探索。本模型权重已采用宽松许可证开源发布。
模型地址:https://huggingface.co/ai21labs/Jamba-v0.1


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献75条内容
已为社区贡献75条内容

所有评论(0)