Jina 模型的介绍,它们的功能,以及在 Elasticsearch 中的使用
Elastic与Jina合作推出的多模态AI模型为Elasticsearch提供了强大的语义搜索能力。该系列模型包含三大类:1)语义嵌入模型(如jina-embeddings-v4),支持文本/图像的多模态嵌入;2)重排序模型(如jina-reranker-v3),提升搜索结果精度;3)小型生成语言模型(如jina-vlm),用于特定任务处理。这些模型采用创新技术如Matryoshka表示学习和L
作者:来自 Elastic Scott Martens
探索 Jina 多模态嵌入、 Reranker v3 以及语义嵌入模型,并了解如何在 Elasticsearch 中通过 Elastic Inference Service ( EIS ) 原生使用它们。
Elasticsearch 原生集成了行业领先的 Gen AI 工具和提供商。查看我们的网络研讨会,了解如何超越 RAG 基础,或使用 Elastic Vector Database 构建可用于生产的应用。
要为你的使用场景构建最佳搜索解决方案,现在就开始免费的云试用,或在本地机器上尝试 Elastic。
Elastic Jina 为应用和业务流程自动化提供搜索基础模型。这些模型为将 AI 引入 Elasticsearch 应用和创新 AI 项目提供核心功能。
Jina 模型分为三大类,用于支持信息处理、组织和检索:
更多阅读:Elasticsearch:语义搜索 - Semantic Search in python
语义嵌入模型
语义嵌入背后的思想是, AI 模型可以学会用高维空间的几何关系来表示其输入含义的各个方面。
你可以将一个语义嵌入看作是高维空间中的一个点(技术上称为向量)。嵌入模型是一种神经网络,它接收一些数字数据作为输入(理论上可以是任何数据,但最常见的是文本或图像),并以一组数值坐标的形式输出对应的高维点位置。如果模型表现良好,两个语义嵌入之间的距离就与它们各自对应的数字对象在语义上有多相似成正比。
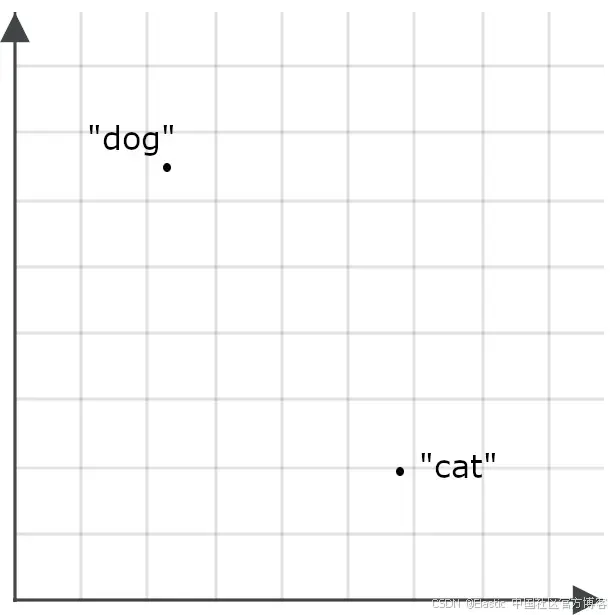
为了理解这对搜索应用为何重要,可以想象单词 “ dog ” 和单词 “ cat ” 各自对应为空间中的两个点:
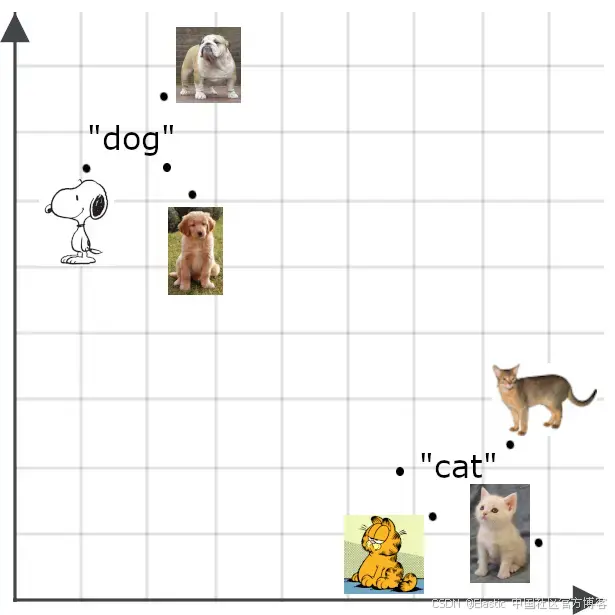
一个好的嵌入模型应该为单词 “ feline ” 生成一个比 “ cat ” 更接近、而不是 “ dog ” 的嵌入,而 “ canine ” 的嵌入也应该比 “ cat ” 更接近 “ dog ”,因为这些词的含义几乎相同:

如果模型是多语言的,我们也会期望 “ cat ” 和 “ dog ” 的翻译具有同样的效果:

嵌入模型将事物在含义上的相似或不相似,转化为嵌入之间的空间关系。上面的图片只有两个维度,便于在屏幕上展示,但嵌入模型生成的是具有几十到几千个维度的向量。这使它们能够为整段文本编码细微的语义差别,为包含数千字甚至更多内容的文档,在一个具有数百或数千个维度的空间中分配一个点。
多模态嵌入
多模态模型将语义嵌入的概念扩展到文本之外,尤其是图像。我们会期望一张图片的嵌入与对该图片的准确描述的嵌入彼此接近:
语义嵌入有很多用途。其中,你可以用它们来构建高效的分类器、进行数据聚类,以及完成多种任务,比如数据去重和数据多样性分析,这两者对于需要处理大量、无法手动管理数据的大数据应用都非常重要。
嵌入最直接、最重要的用途是在信息检索中。 Elasticsearch 可以存储以嵌入作为键的检索对象。查询会被转换为嵌入向量,搜索会返回其键与查询嵌入距离最近的已存储对象。
传统的基于向量的检索(有时称为稀疏向量检索)使用基于文档和查询中的词或元数据的向量,而基于嵌入的检索(也称为稠密向量检索)使用的是 AI 评估的语义而不是单词。这使它们通常比传统搜索方法更灵活,也更准确。
Matryoshka(套娃) 表示学习
嵌入的维度数量以及其中数值的精度会对性能产生显著影响。非常高维的空间和极高精度的数值可以表示高度细致和复杂的信息,但需要更大、训练和运行成本更高的 AI 模型。它们生成的向量需要更多存储空间,计算向量之间距离也需要更多计算资源。使用语义嵌入模型需要在精度和资源消耗之间做出重要权衡。
为了最大化用户的灵活性, Jina 模型采用了一种称为 Matryoshka Representation Learning 的训练技术。这种技术会将最重要的语义区分优先编码到嵌入向量的前几个维度中,因此即使截断高维部分,也能保持良好的性能。
在实际使用中,这意味着 Jina 模型的用户可以自行选择嵌入的维度数量。选择更少的维度会降低精度,但性能下降幅度很小。在大多数任务中,每当将嵌入大小减少 50% 时, Jina 模型的性能指标只会下降约 1–2%,直到大小减少约 95% 为止。
非对称检索
语义相似度通常是对称测量的。比较 “ cat ” 和 “ dog ” 得到的值,与比较 “ dog ” 和 “ cat ” 得到的值是相同的。但在使用嵌入进行信息检索时,如果打破对称性,将查询的编码方式与检索对象的编码方式区分开,会效果更好。
这是因为嵌入模型的训练方式。训练数据包含相同元素(如单词)在许多不同上下文中的实例,模型通过比较元素在上下文中的相似性和差异来学习语义。
例如,我们可能发现单词 “ animal ” 与 “ cat ” 或 “ dog ” 出现的上下文重叠不多,因此 “ animal ” 的嵌入可能不会特别接近 “ cat ” 或 “ dog ”:
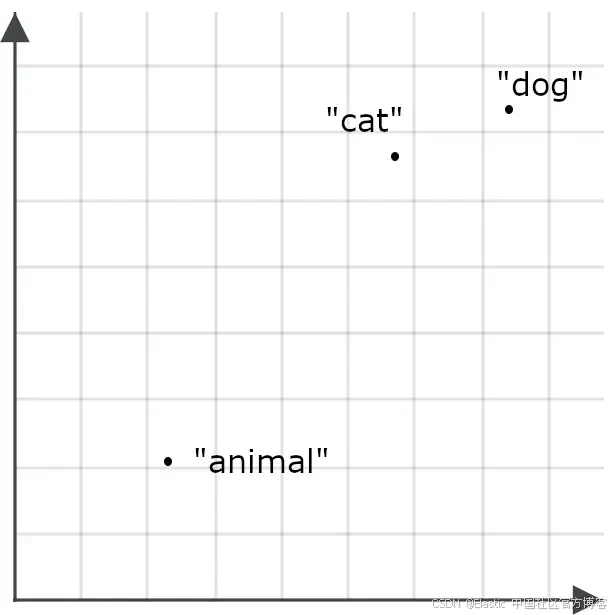
这会使得以 “ animal ” 为查询的检索不太可能返回关于 cat 和 dog 的文档——这与我们的目标相反。因此,当 “ animal ” 作为查询时,我们会采用不同的编码方式,而不是作为检索目标时的编码方式:
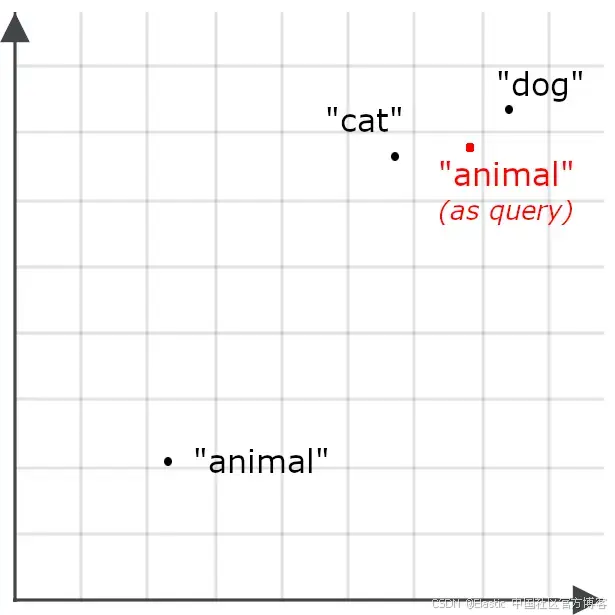
非对称检索意味着对查询使用不同的模型,或者专门训练一个嵌入模型,使其在存储用于检索时采用一种编码方式,而在处理查询时采用另一种编码方式。
多向量嵌入
单一嵌入适用于信息检索,因为它们符合索引数据库的基本框架:我们使用单个嵌入向量作为检索键存储可检索对象。当用户查询文档存储时,查询会被转换为嵌入向量,文档中键与查询嵌入在高维嵌入空间中最接近的文档会被检索出来作为候选匹配。
多向量嵌入的工作方式略有不同。它们不生成固定长度的向量来表示整个查询或存储对象,而是为其较小的部分生成一系列嵌入。这些部分通常是文本的 token 或单词,视觉数据则是图像块。这些嵌入反映了该部分在其上下文中的含义。
例如,考虑以下句子:
- She had a heart of gold.
- She had a change of heart.
- She had a heart attack.
表面上看,它们非常相似,但多向量模型很可能为每个 “ heart ” 的实例生成不同的嵌入,表示它在整个句子上下文中的不同含义:
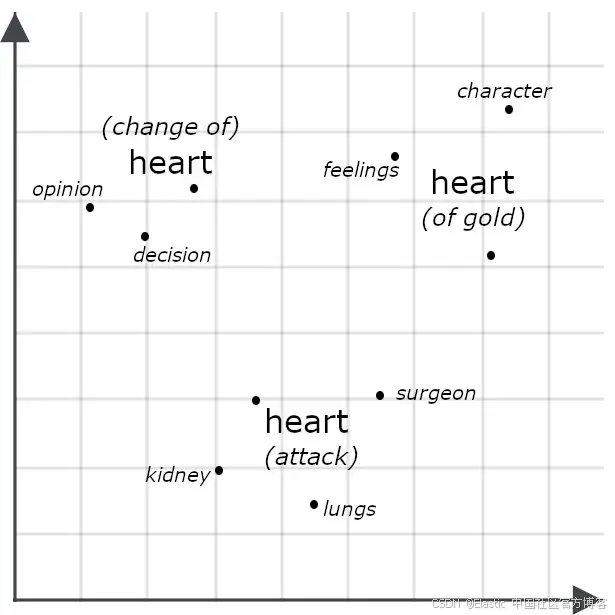
通过多向量嵌入比较两个对象通常涉及测量它们的 Chamfer 距离:将一个多向量嵌入的每个部分与另一个的每个部分进行比较,并将它们之间的最小距离求和。其他系统,包括下面描述的 Jina Rerankers,会将它们输入一个专门训练用于评估相似性的 AI 模型。这两种方法通常比仅比较单向量嵌入的精度更高,因为多向量嵌入包含比单向量嵌入更多的详细信息。
然而,多向量嵌入不太适合索引。它们通常用于重排序任务,如下一节中 jina-colbert-v2 模型所描述的。
Jina 嵌入模型
Jina embeddings v4
jina-embeddings-v4 是一个拥有 38 亿(3.8x10⁹)参数的多语言、多模态嵌入模型,支持多种常用语言的文本和图像。它使用了一种新型架构,利用视觉知识和语言知识提升两类任务的性能,使其在图像检索,尤其是视觉文档检索方面表现出色。这意味着它可以处理图表、幻灯片、地图、截图、页面扫描和图解等图像 —— 这些常见图像通常包含重要的嵌入文本,而传统计算机视觉模型训练于现实场景图片时无法覆盖。
我们通过紧凑的低秩适配器(Low-Rank Adaptation, LoRA)对该模型进行了多任务优化。这使得我们可以训练一个单一模型在多个任务上进行专精,而不会影响任何任务的性能,并且对内存或计算的额外开销最小。
主要特点包括:
- 在视觉文档检索上表现出最先进的性能,同时在多语言文本和常规图像处理上也超过了更大型的模型。
- 支持大输入上下文:32,768 个 token 大约相当于 80 页双倍行距的英文文本,20 兆像素相当于 4,500 x 4,500 像素的图像。
- 用户可选择嵌入维度,从最大 2048 维到最小 128 维。实证发现,低于该阈值性能会显著下降。
- 支持单向量嵌入和多向量嵌入。文本的多向量输出为每个输入 token 生成一个 128 维嵌入;图像的多向量输出为覆盖图像所需的每个 28x28 像素块生成一个 128 维嵌入。
- 通过专门训练的一对 LoRA 适配器优化非对称检索。
- 优化语义相似度计算的 LoRA 适配器。
- 专门支持编程语言和 IT 框架,也通过 LoRA 适配器实现。
我们开发 jina-embeddings-v4 作为一个通用、多用途工具,用于广泛的常见搜索、自然语言理解和 AI 分析任务。考虑到其能力,它是一个相对较小的模型,但部署仍需显著资源,最适合通过云 API 或在高负载环境中使用。
Jina embeddings v3
jina-embeddings-v3 是一个紧凑、高性能、多语言、仅文本的嵌入模型,参数少于 6 亿。它支持最多 8192 个 token 的文本输入,并输出单向量嵌入,嵌入维度可由用户选择,从默认的 1024 维到最小 64 维。
我们为多种文本任务训练了 jina-embeddings-v3 —— 不仅包括信息检索和语义相似性,还包括分类任务,如情感分析和内容审核,以及聚类任务,如新闻聚合和推荐。与 jina-embeddings-v4 类似,该模型提供 LoRA 适配器,专门用于以下使用场景:
- 非对称检索
- 语义相似度
- 分类
- 聚类
jina-embeddings-v3 的模型远小于 jina-embeddings-v4,输入上下文也大幅缩小,但运行成本更低。尽管如此,它在文本处理上性能仍非常有竞争力,是许多用例的更佳选择。
Jina 代码嵌入
Jina 的专用代码嵌入模型 —— jina-code-embeddings(0.5b 和 1.5b)——支持 15 种编程语言和框架,以及与计算机和信息技术相关的 English 文本。它们是紧凑模型,参数分别为 5 亿(0.5x10⁹)和 15 亿(1.5x10⁹)。两个模型都支持最多 32,768 个 token 的输入上下文,并允许用户选择输出嵌入维度:小模型为 896 到 64 维,大模型为 1536 到 128 维。
这些模型支持针对五种任务特定的非对称检索,使用前缀微调(
Jina ColBERT v2
jina-colbert-v2 是一个拥有 5.6 亿参数的多向量文本嵌入模型。它是多语言模型,使用 89 种语言的材料进行训练,并支持可变嵌入维度和非对称检索。
如前所述,多向量嵌入不适合索引,但非常适合提高其他搜索策略结果的精度。使用 jina-colbert-v2,你可以提前计算多向量嵌入,然后在查询时用它们对检索候选进行重排序。这种方法的精度低于下一节中的重排序模型,但效率更高,因为它只涉及比较已存储的多向量嵌入,而不必为每个查询和候选匹配调用整个 AI 模型。它非常适合在使用重排序模型的延迟和计算开销过大,或者需要比较的候选数量太多而不适合重排序模型的场景中使用。
该模型输出一系列嵌入,每个输入 token 对应一个嵌入,用户可以选择 128、96 或 64 维的 token 嵌入。候选文本匹配限制为 8,192 个 token。查询采用非对称编码,因此用户必须指定文本是查询还是候选匹配,并且查询 token 数量必须限制在 32 个以内。
)而非 LoRA 适配器:
- 代码到代码(Code to code):跨编程语言检索相似代码,用于代码对齐、代码去重,以及支持移植和重构。
- 自然语言到代码(Natural language to code):根据自然语言查询、注释、描述和文档检索匹配代码。
- 代码到自然语言(Code to natural language):将代码匹配到文档或其他自然语言文本。
- 代码补全(Code-to-code completion):建议相关代码以完成或增强现有代码。
- 技术问答(Technical Q&A):识别与信息技术相关问题的自然语言答案,非常适合技术支持场景。
这些模型在处理计算机文档和编程材料任务时提供出色性能,同时计算成本相对较低,非常适合集成到开发环境和代码助手中。
Jina CLIP v2
jina-clip-v2 是一个拥有 9 亿参数的多模态嵌入模型,训练目标是让文本和图像在嵌入空间中彼此接近,如果文本描述了图像的内容。它的主要用途是基于文本查询检索图像,但它也是一个高性能的纯文本模型,从而降低用户成本,因为无需为文本到文本和文本到图像的检索使用不同模型。
该模型支持 8,192 token 的文本输入上下文,图像在生成嵌入前会缩放至 512x512 像素。
对比语言–图像预训练(CLIP)架构易于训练和操作,并能生成非常紧凑的模型,但存在一些根本性限制。它们无法利用一种媒介的知识来提升在另一种媒介上的性能。换句话说,虽然模型可能知道单词 “ dog ” 和 “ cat ” 的语义比任何一个与 “ car ” 更接近,但它不一定知道狗的图片和猫的图片比它们各自与汽车图片更相关。
它们还存在所谓的模态差距(modality gap):关于狗的文本嵌入可能比狗的图片嵌入更接近关于猫的文本嵌入。基于这一限制,我们建议将 CLIP 用作文本到图像的检索模型,或纯文本模型,而不要在单次查询中混合使用两者。
重排序模型
重排序模型会将一个或多个候选匹配项与查询一起作为模型输入,并直接进行比较,从而生成精度更高的匹配结果。
原则上,你可以直接使用重排序器进行信息检索,通过将每个查询与每个存储文档进行比较,但这计算成本非常高,除了最小的数据集外几乎不可行。因此,重排序器通常用于评估通过其他方法找到的相对较短的候选匹配列表,比如基于嵌入的搜索或其他检索算法。重排序模型非常适合用于混合和联合搜索方案,其中搜索可能意味着查询会发送到不同数据集的独立搜索系统,每个系统返回不同结果。它们在将多样化结果合并为单个高质量结果方面表现出色。
基于嵌入的搜索可能需要大量投入,包括重新索引所有存储的数据,并改变用户对结果的期望。在现有搜索方案中添加重排序器,可以在不重构整个搜索解决方案的情况下,带来许多 AI 的好处。
Jina 重排序模型
Jina Reranker m0
jina-reranker-m0 是一个拥有 24 亿(2.4x10⁹)参数的多模态重排序模型,支持文本查询和由文本和/或图像组成的候选匹配。它是视觉文档检索的领先模型,非常适合用于存储 PDF、文本扫描、截图以及其他包含文本或半结构化信息的计算机生成或修改的图像,也适用于由文本文档和图像混合组成的数据。
该模型接受单个查询和一个候选匹配,并返回一个分数。当相同查询用于不同候选时,分数可比较并用于排序。它支持总输入大小最多 10,240 个 token,包括查询文本和候选文本或图像。覆盖图像所需的每个 28x28 像素块都算作一个 token,用于计算输入大小。
Jina Reranker v3
jina-reranker-v3 是一个拥有 6 亿参数的文本重排序模型,在同等规模模型中性能处于最先进水平。与 jina-reranker-m0 不同,它接受单个查询和最多 64 个候选匹配的列表,并返回排序顺序。它的输入上下文为 131,000 个 token,包括查询和所有文本候选。
Jina Reranker v2
jina-reranker-v2-base-multilingual 是一个非常紧凑的通用重排序模型,具有额外功能以支持函数调用和 SQL 查询。参数少于 3 亿,提供快速、高效且准确的多语言文本重排序,并额外支持选择与文本查询匹配的 SQL 表和外部函数,非常适合 agentic 场景使用。
小型生成语言模型
生成语言模型是指像 OpenAI 的 ChatGPT、Google Gemini 以及 Anthropic 的 Claude 这样的模型,它们接受文本或多媒体输入,并输出文本。大语言模型(arge language models - LLMs)与小语言模型(small language models - SLMs)之间没有明确界限,但开发、运行和使用顶级 LLM 的实际问题是众所周知的。最知名的 LLM 并未公开分发,因此只能估计其规模,但 ChatGPT、Gemini 和 Claude 预计在 1–3 万亿(1–3x10¹²)参数范围内。
运行这些模型,即便公开可用,也远超传统硬件能力,需使用最先进的芯片并组成庞大的并行阵列。你可以通过付费 API 访问 LLM,但这会产生高额成本、较大延迟,并难以满足数据保护、数字主权和云迁移的要求。此外,训练和定制此类模型的成本也非常可观。
因此,研究人员投入大量精力开发更小的模型,这些模型可能不具备最大 LLMs 的全部能力,但能以较低成本完成特定任务。企业通常部署软件来解决特定问题,AI 软件也不例外,因此基于 SLM 的解决方案通常比 LLM 更可取。它们通常可以在普通硬件上运行,速度更快、能耗更低,并且更容易定制。
随着我们关注如何将 AI 最有效地引入实际搜索解决方案,Jina 的 SLM 产品也在不断增长。
Jina SLMs
ReaderLM v2
ReaderLM-v2 是一个生成语言模型,可根据用户提供的 JSON schema 和自然语言指令,将 HTML 转换为 Markdown 或 JSON。
数据预处理和规范化是开发优秀数字数据搜索解决方案的重要环节,但现实世界的数据,尤其是来自网页的信息,通常非常混乱,简单的转换策略常常非常脆弱。ReaderLM-v2 提供了智能 AI 模型解决方案,能够理解网页 DOM 树的混乱结构,并稳健地识别有用元素。
该模型拥有 15 亿(1.5x10⁹)参数,比最先进的 LLM 小三个数量级,但在这个单一任务上的表现与它们相当。
Jina VLM
jina-vlm 是一个拥有 24 亿(2.4x10⁹)参数的生成语言模型,训练目标是回答关于图像的自然语言问题。它在视觉文档分析方面表现非常强大,即回答关于扫描件、截图、幻灯片、图解以及类似的非自然图像数据的问题。
例如:

它在识别图像中的文本方面也非常出色:

但 jina-vlm 真正擅长的是理解信息性和人工生成图像的内容:
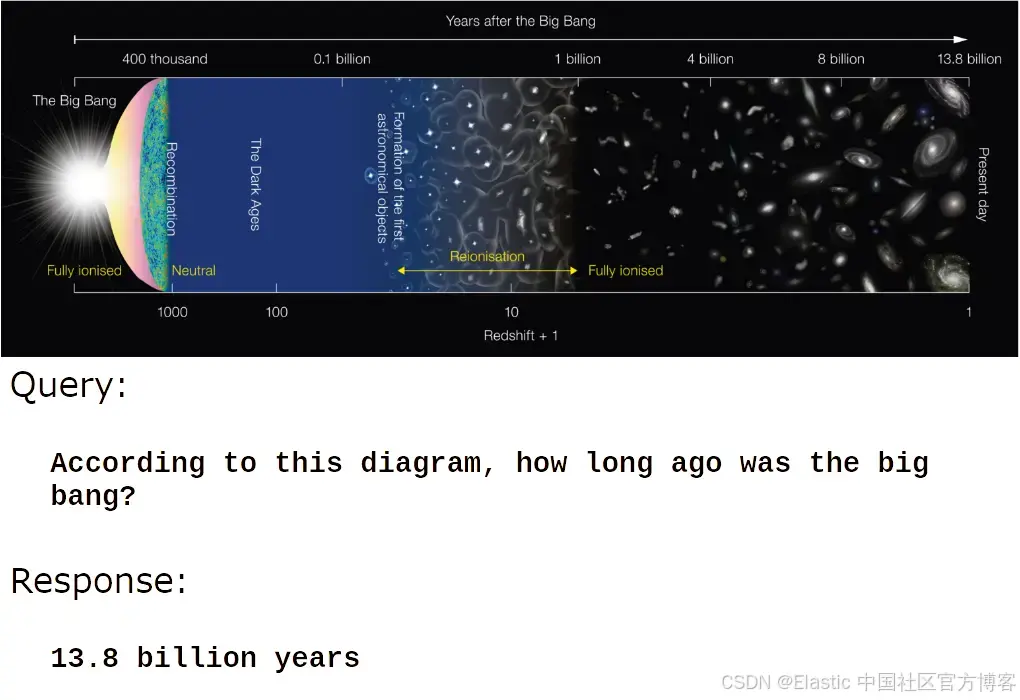
或者:

jina-vlm 非常适合自动生成图像说明、产品描述、图片替代文本,以及为视障人士提供的可访问性应用。它还为检索增强生成(RAG)系统使用视觉信息,以及让 AI agent 无需人工即可处理图像创造了可能性。
原文:https://www.elastic.co/search-labs/blog/jina-models-elasticsearch-guide

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 14
14 0
0- 0



 已为社区贡献123条内容
已为社区贡献123条内容

{kind=link}
{kind=link}
{kind=link}
{kind=link}
所有评论(0)