ComfyUI入门初相识与默认工作流
ComfyUI是一个基于节点式工作流的Stable Diffusion可视化操作界面,通过将图像生成过程拆解为可自由组合的功能模块(如模型加载、文本编码、采样器等),实现对AI生成流程的精细控制。相比WebUI,ComfyUI具有更高的定制性、更好的性能表现和更强的流程复现能力,适合进阶用户进行复杂创作。其核心原理与Stable Diffusion一致,通过潜空间生成和迭代降噪来产生图像。本地部署
引言
说起来ComfyUI已经使用了很长一段时间了,比如模仿nano banana 的手办效果,各种动漫二次元的效果,甚至图生视频等都产生了社区内容传播价值。一直没有回过头来好好梳理一下这个东西。
今天小马来整理一下简单原理和入门理解。

一、什么是ComfyUI
ComfyUI 是专为 Stable Diffusion 设计的节点式图形用户界面(GUI),它将 SD 的图像生成过程拆解为多个可灵活组合的功能节点(如加载模型、文本提示、采样器、ControlNet 等),通过可视化连线构建完整的生图工作流,本质上是对 SD 底层运行逻辑的模块化封装和可视化操控工具。其核心功能(如文本编码、潜空间生成、图像解码等)均基于 SD 的原始架构实现,用户可通过节点自由配置 SD 的各项参数和扩展功能(如 LoRA、ControlNet),但所有计算仍依赖 SD 模型本身在本地显卡运行。
开源地址:https://github.com/comfyanonymous/ComfyUI
简单来说,SD 是 ComfyUI 的“引擎”,而 ComfyUI 则是 SD 的“可视化操作面板”,二者属于工具与底层模型的关系。
ComfyUI本质上是一个可视化的工作流引擎,它将Stable Diffusion等模型的复杂生成过程,解耦为一个个可连接、可复用的功能模块(节点),让你能像搭积木一样自由构建和控制AI图像生成流程。
🔬 核心架构与工作原理
它的原理可以通过以下核心模块和执行流程来理解:
| 模块/概念 | 功能与原理 | 关键节点示例 |
|---|---|---|
| 节点系统 | 系统的基础。每个节点是一个独立的功能单元(如加载模型、编码文本),通过输入/输出端口连接,形成有向无环图(DAG)。 | Checkpoint Loader, CLIP Text Encode, KSampler |
| 模型加载与调度 | 从检查点文件加载模型,并拆解为U-Net(去噪)、CLIP(文本编码)、VAE(图像编解码) 三个核心组件供后续节点使用。 | Checkpoint Loader |
| 条件控制与编码 | 文本提示词通过CLIP模型被编码为生成过程可理解的特征向量。ControlNet、IP-Adapter等节点可额外注入图像的结构、姿态、风格等条件。 | CLIP Text Encode, ControlNetApply |
| 潜空间与采样 | 这是Stable Diffusion的核心。图像在潜空间(一种压缩的高维空间)中被处理和生成。KSampler在该空间中进行多次迭代去噪,将随机噪声转化为目标图像。 |
Empty Latent Image, KSampler |
| 图像编解码 | VAE编码器将像素图压缩为潜空间表示(用于图生图);VAE解码器则将采样后的潜空间表示解码为最终的像素图像。 | VAE Encode, VAE Decode |
也就是说SD的原理是什么基本上就是ComfyUI的原理。
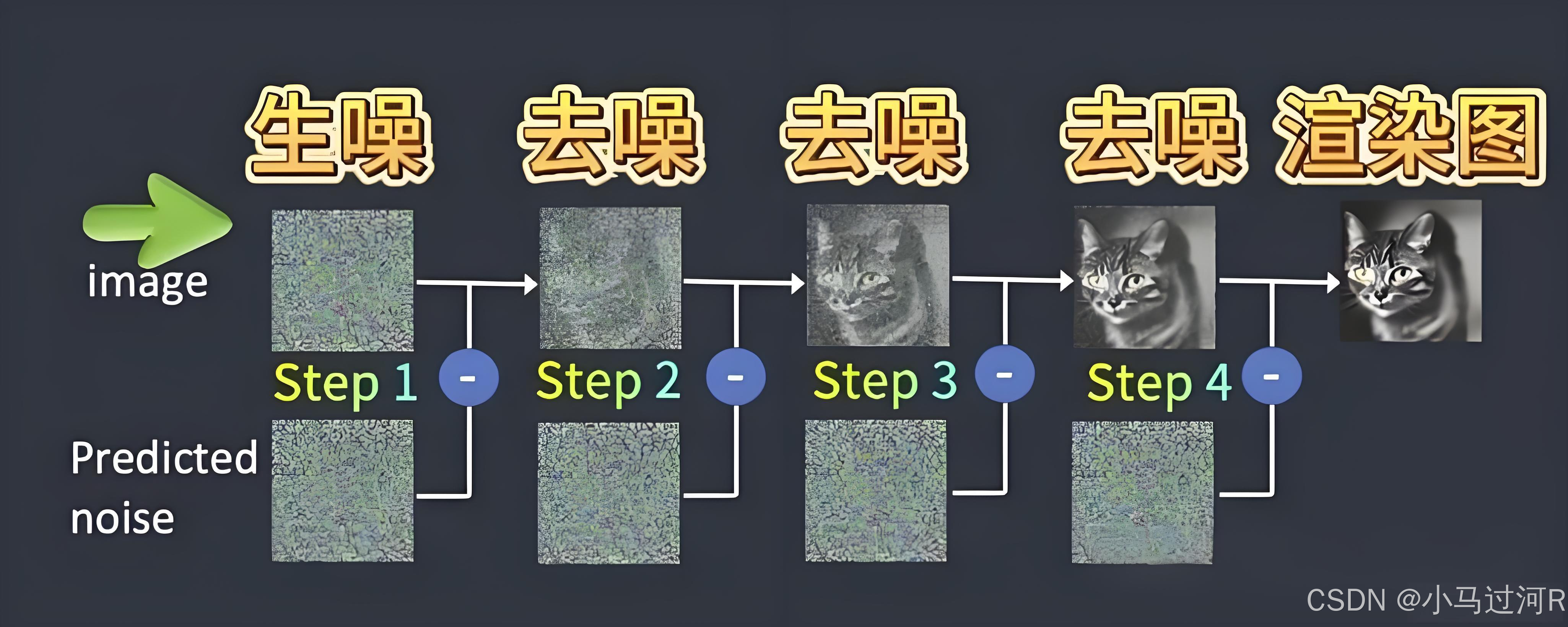
可以通俗理解为 Stable Diffusion 原理 = 先添加噪点 再不断降噪来生成清晰的图片。
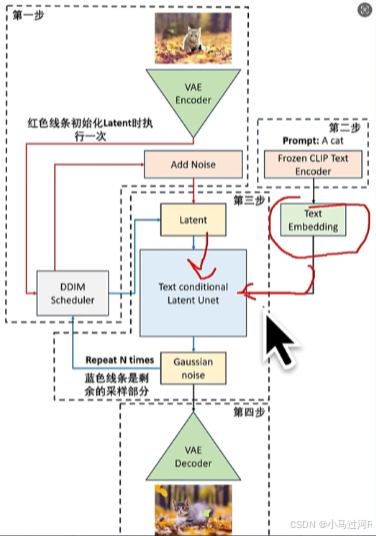
⚙️ 工作流的执行过程
当你点击“生成”时,ComfyUI的后端执行引擎会:
- 解析依赖:分析节点连接关系,进行拓扑排序,确定执行顺序。
- 智能调度与缓存:仅计算必要节点,并复用缓存结果以极大提升效率。
- 按序执行:依次执行节点,数据从上游流向下游。
- 资源管理:高效管理GPU显存,如自动卸载闲置模型。
✨ 主要特点
基于上述原理,ComfyUI拥有以下突出特点:
- 高自由度与可视化:节点式连接让复杂流程一目了然,可任意组合和实验。
- 卓越的复现性与分享:整个工作流可保存为
JSON文件或内嵌于生成图片的元数据中,他人一键即可完全复现。 - 高性能与低资源占用:因其高效的执行引擎和显存管理,生成速度通常比WebUI更快,且在低显存设备上表现更好。
- 强大的可扩展性:拥有活跃的社区,可通过安装自定义节点不断扩展功能(如视频生成、3D等)。
二、ComfyUI 和 WebUI区别
ComfyUI 和 WebUI 是 Stable Diffusion 最常用的两款图形界面,但设计理念和适用场景差异很大。简单来说,WebUI 像是界面直观的“一体机”,适合快速上手;而 ComfyUI 则像是可深度定制的“组装电脑”,为追求控制和效率的用户设计。
为了帮你快速了解,我将它们的主要区别整理成了下表:
| 维度 | Stable Diffusion WebUI (AUTOMATIC1111) | ComfyUI |
|---|---|---|
| 核心理念 | 直观易用,开箱即用。提供固定的表单式界面,适合快速生成。 | 高度定制,模块化流程。通过连接节点自由构建和可视化工作流。 |
| 界面与操作 | 网页形式,参数以按钮、滑块、输入框排列,逻辑直观。 | 节点式界面。用户需手动添加、连接功能模块来构建流程,初期有一定学习门槛。 |
| 性能与效率 | 功能全面,但界面本身会占用一定资源。显存管理相对基础。 | 性能优化更好。通常生成速度更快,显存占用更低,在低显存设备上表现更佳。 |
| 工作流与复现性 | 操作步骤固化,复杂流程需手动切换。复现结果需完整记录所有参数。 | 核心优势。整个流程可保存/分享为JSON文件或图片元数据,实现100%精确复现。 |
| 生态与扩展 | 插件生态极其丰富,社区成熟,教程和解决方案众多。 | 插件(自定义节点)同样丰富,但生态相对较新。高度自由化带来了强大的复杂流程构建能力。 |
| 适用人群 | 新手、日常创作者、设计师。希望快速产出效果,不愿深究技术细节。 | 进阶用户、研究者、批量生产者。追求极致控制、效率、自动化,或需要复杂、可复用流程。 |
🤔 如何选择?
你可以根据自己的情况参考以下建议:
- 从 WebUI 开始:如果你是刚接触Stable Diffusion的新手,或者主要进行随机的、探索性的创作,希望用最少的精力快速出图,WebUI 是你的最佳选择。
- 选择 ComfyUI:如果你符合以下任一情况:
- 已经熟悉SD基本原理,不满足于固定操作,希望深度控制每一个生成步骤。
- 需要进行大批量、自动化的图像生成任务。
- 电脑显存较小,需要更高效的资源管理。
- 需要搭建和保存复杂、可重复使用的生产流程(如固定风格的商业图生成)。
- 有技术背景,乐于探索和搭建个性化工作流。
三、ComfyUI默认工作流讲解
这是一个默认的工作流,我们来做一下主流程的节点介绍分析。
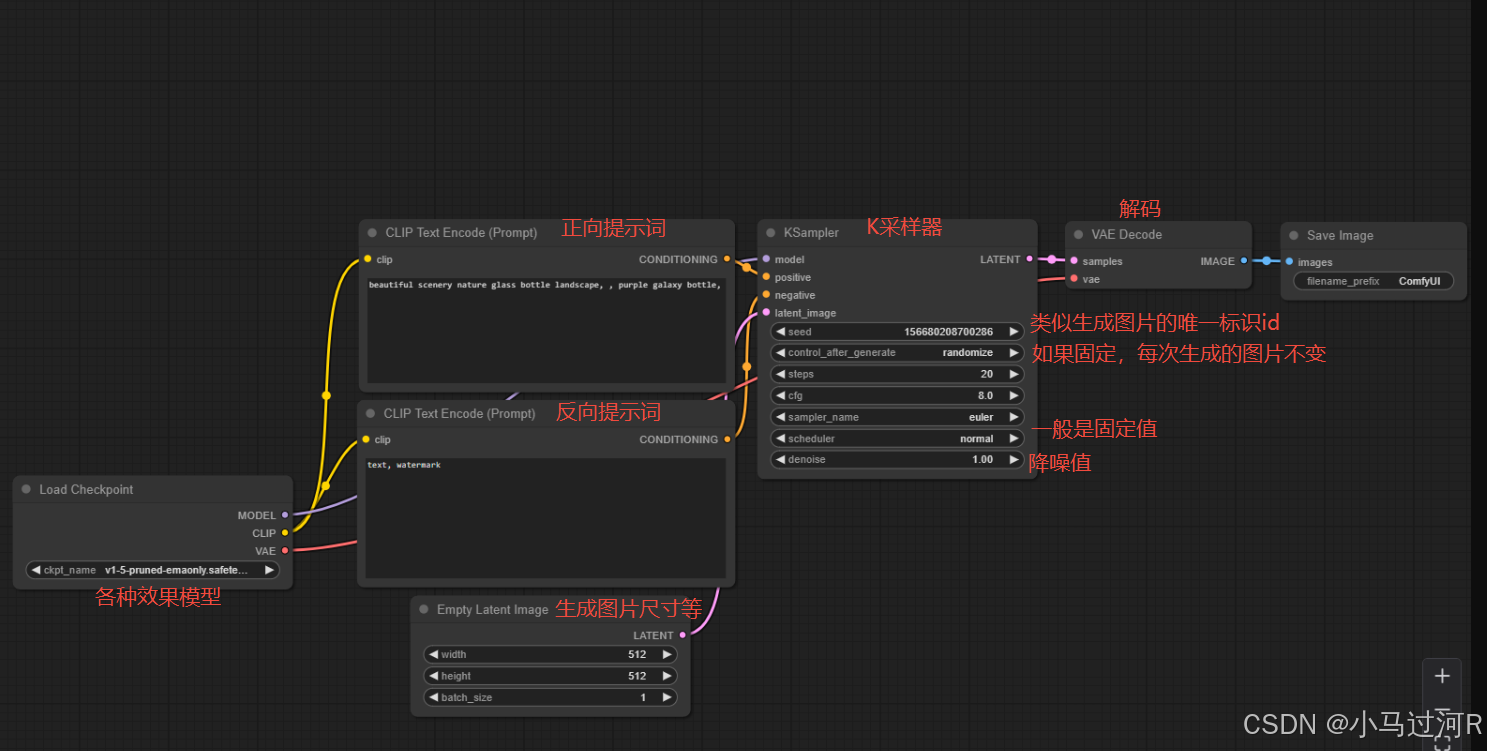
相同颜色的点通常与相同颜色的点相连。
如果是一个图生图工作流,则风格由 效果模型和提示词来决定,图片是否与原图相似则由那个降噪值设置大小决定,值越小变化就越小。
这里需要注意,反向提示词不代表说是不能出现,而是减少出现。一般正向和反向提示词我们都会在前面部分加入一些固定的词,比如高清,这个可以在网上查即可,提示词只支持英文。越靠前的提示词权重越高,所以一般我们把对质量要求的提示词放前面。
默认工作流只代表主流程原理,至于其他非默认节点或自定义节点等的添加那就是按需加载了,有些工作流可能都不含默认工作流的节点。
图生视频原理 可以理解为是通过多图片(24张/s)合成的视频视觉效果。ComfyUI也是按照这个原理产出视频的。
安装插件:
ComfyUI Manager Menu - >Custom Nodes Manager
关于官方原生整合包和安装插件:https://baijiahao.baidu.com/s?id=1824062540201074783&wfr=spider&for=pc
本地部署硬件条件:
- 内存:最低8G,建议16G。
- 显卡:显存8G以上,最低20/30系列Nvidia独立显卡,推荐使用40系列Nvidia独立显卡。N卡(英伟达)效果最佳,A卡(超威/AMD)次之,I卡(英特尔)支持较差。
四、总结
本篇作为入门,更多深度玩法小马后续更新,想快速入门的同学小马推荐这个教程,也可以先睹为快。
- 彩蛋的位置~
2025年能入围博客之星top300 《2025博客之星年度评选入围榜单公布》着实是意料之外情理之中,硬着头皮总结了2025年这一年的酸甜苦辣《2025,在AI星河中遨游,于CSDN星畔留痕》,真的是 “写最好的代码,买最好的假发”。新的一年希望我们都能砥砺前行。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 21
21 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)