大数据领域数据服务在物流行业的应用创新
本文旨在系统性地探讨大数据技术在物流行业的创新应用模式,分析数据服务如何赋能物流企业提升运营效率、降低成本和改善客户体验。研究范围涵盖从数据采集到智能决策的全流程技术实现。本文首先介绍物流大数据的基本特征,然后深入分析技术架构和核心算法,接着通过实际案例展示应用效果,最后探讨未来发展趋势。智能物流:利用物联网、大数据、AI等技术实现物流全流程自动化和智能化的系统供应链可视化:通过数据集成和可视化技
大数据领域数据服务在物流行业的应用创新
关键词:大数据、物流行业、数据服务、应用创新、智能物流、供应链优化、数据分析
摘要:本文深入探讨了大数据技术在物流行业的创新应用。我们将从物流行业的数据特征出发,分析大数据服务如何解决传统物流痛点,详细介绍智能物流系统的架构设计、核心算法和数学模型。通过实际案例展示大数据在路线优化、仓储管理、需求预测等方面的应用效果,并探讨未来发展趋势和技术挑战。文章旨在为物流企业数字化转型提供技术参考和实施路径。
1. 背景介绍
1.1 目的和范围
本文旨在系统性地探讨大数据技术在物流行业的创新应用模式,分析数据服务如何赋能物流企业提升运营效率、降低成本和改善客户体验。研究范围涵盖从数据采集到智能决策的全流程技术实现。
1.2 预期读者
- 物流企业技术决策者
- 大数据工程师
- 供应链管理人员
- 智慧城市规划者
- 物流科技创业者
1.3 文档结构概述
本文首先介绍物流大数据的基本特征,然后深入分析技术架构和核心算法,接着通过实际案例展示应用效果,最后探讨未来发展趋势。
1.4 术语表
1.4.1 核心术语定义
- 智能物流:利用物联网、大数据、AI等技术实现物流全流程自动化和智能化的系统
- 供应链可视化:通过数据集成和可视化技术实时监控供应链各环节状态
- 动态路径规划:根据实时交通和订单数据优化配送路线的算法
1.4.2 相关概念解释
- ETL(Extract-Transform-Load):数据抽取、转换和加载的过程
- 数字孪生:物理物流系统在数字空间的虚拟映射
- 预测性维护:基于设备数据分析预测故障发生时间的技术
1.4.3 缩略词列表
- IoT(Internet of Things)
- RFID(Radio Frequency Identification)
- GIS(Geographic Information System)
- TMS(Transportation Management System)
- WMS(Warehouse Management System)
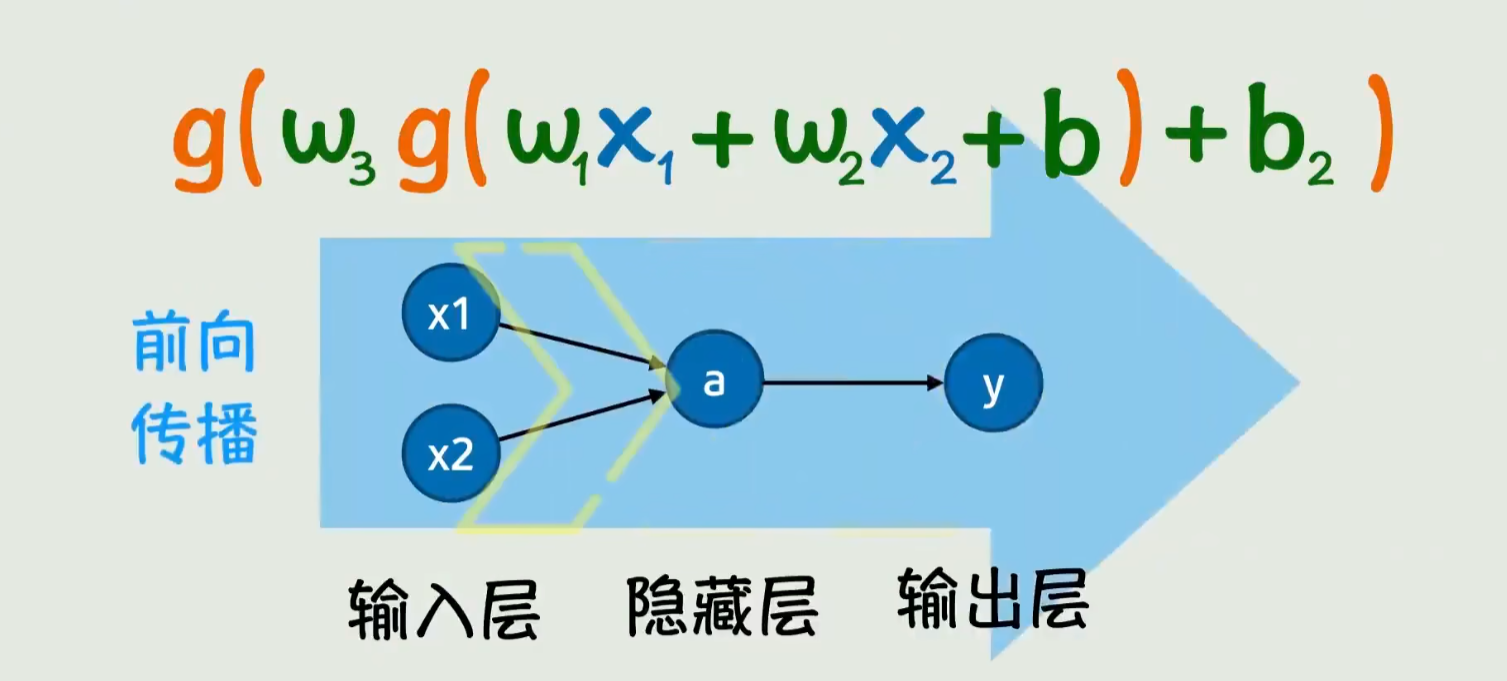
2. 核心概念与联系
物流大数据生态系统由多个相互关联的子系统构成:
物流大数据的主要特征可概括为5V模型:
- Volume:日均TB级数据量
- Velocity:实时数据流处理需求
- Variety:结构化与非结构化数据并存
- Veracity:数据质量参差不齐
- Value:高商业价值密度
3. 核心算法原理 & 具体操作步骤
3.1 物流路径优化算法
以下是基于遗传算法的路径优化实现:
import numpy as np
from deap import base, creator, tools, algorithms
# 初始化配送点坐标
points = np.random.rand(20, 2) * 100 # 20个配送点
# 计算距离矩阵
def create_distance_matrix(points):
n = len(points)
dist_matrix = np.zeros((n, n))
for i in range(n):
for j in range(n):
dist_matrix[i][j] = np.linalg.norm(points[i]-points[j])
return dist_matrix
distance_matrix = create_distance_matrix(points)
# 遗传算法设置
creator.create("FitnessMin", base.Fitness, weights=(-1.0,))
creator.create("Individual", list, fitness=creator.FitnessMin)
toolbox = base.Toolbox()
toolbox.register("indices", np.random.permutation, len(points))
toolbox.register("individual", tools.initIterate, creator.Individual, toolbox.indices)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
def evalTSP(individual):
distance = 0
for i in range(len(individual)):
from_city = individual[i]
to_city = individual[(i+1)%len(individual)]
distance += distance_matrix[from_city][to_city]
return distance,
toolbox.register("mate", tools.cxOrdered)
toolbox.register("mutate", tools.mutShuffleIndexes, indpb=0.05)
toolbox.register("select", tools.selTournament, tournsize=3)
toolbox.register("evaluate", evalTSP)
# 运行算法
population = toolbox.population(n=100)
hof = tools.HallOfFame(1)
stats = tools.Statistics(lambda ind: ind.fitness.values)
stats.register("avg", np.mean)
stats.register("min", np.min)
result, log = algorithms.eaSimple(population, toolbox, cxpb=0.8, mutpb=0.2,
ngen=200, stats=stats, halloffame=hof, verbose=True)
best_route = hof[0]
print("最优路径:", best_route)
print("最短距离:", evalTSP(best_route)[0])
3.2 仓储货位优化算法
基于关联规则的货位优化算法:
from itertools import combinations
from collections import defaultdict
# 模拟订单数据
orders = [
['A','B','C'],
['A','D','E'],
['B','C','E'],
['A','C','E'],
['B','D','E'],
['A','B','C','E']
]
# 计算频繁项集
def get_frequent_itemsets(orders, min_support=0.3):
item_counts = defaultdict(int)
total_orders = len(orders)
# 计算单项支持度
for order in orders:
for item in order:
item_counts[item] += 1
# 筛选频繁单项
frequent_items = {item: count/total_orders
for item, count in item_counts.items()
if count/total_orders >= min_support}
# 生成候选项集
items = list(frequent_items.keys())
frequent_itemsets = {}
# 逐步增加项集大小
k = 2
while True:
candidates = list(combinations(items, k))
if not candidates:
break
candidate_counts = defaultdict(int)
for order in orders:
for candidate in candidates:
if set(candidate).issubset(set(order)):
candidate_counts[candidate] += 1
new_frequent = {cand: count/total_orders
for cand, count in candidate_counts.items()
if count/total_orders >= min_support}
if not new_frequent:
break
frequent_itemsets.update(new_frequent)
k += 1
return frequent_items, frequent_itemsets
# 计算关联规则
def generate_rules(frequent_items, frequent_itemsets, min_confidence=0.7):
rules = []
for itemset in frequent_itemsets:
if len(itemset) < 2:
continue
support = frequent_itemsets[itemset]
for i in range(1, len(itemset)):
for antecedent in combinations(itemset, i):
antecedent = frozenset(antecedent)
consequent = frozenset(itemset) - antecedent
if antecedent in frequent_items:
confidence = support / frequent_items[antecedent]
if confidence >= min_confidence:
rules.append((antecedent, consequent, confidence))
return sorted(rules, key=lambda x: -x[2])
# 执行分析
freq_items, freq_itemsets = get_frequent_itemsets(orders)
rules = generate_rules(freq_items, freq_itemsets)
print("频繁项集:", freq_itemsets)
print("\n关联规则:")
for rule in rules:
print(f"{set(rule[0])} => {set(rule[1])} (置信度: {rule[2]:.2f})")
4. 数学模型和公式 & 详细讲解 & 举例说明
4.1 车辆路径问题(VRP)数学模型
标准VRP问题可表示为:
最小化∑i=0n∑j=0n∑k=1mcijxijk约束条件:∑i=0ndiyik≤Qk,∀k∈{1,...,m}∑k=1myik=1,∀i∈{1,...,n}∑j=0nxijk=yik,∀i∈{0,...,n},k∈{1,...,m}∑i=0nxijk=yjk,∀j∈{0,...,n},k∈{1,...,m}∑i∈S∑j∈Sxijk≤∣S∣−1,∀S⊆{1,...,n},∣S∣≥2xijk∈{0,1},yik∈{0,1} \begin{aligned} &\text{最小化} \sum_{i=0}^n \sum_{j=0}^n \sum_{k=1}^m c_{ij}x_{ijk} \\ &\text{约束条件:} \\ &\sum_{i=0}^n d_i y_{ik} \leq Q_k, \quad \forall k \in \{1,...,m\} \\ &\sum_{k=1}^m y_{ik} = 1, \quad \forall i \in \{1,...,n\} \\ &\sum_{j=0}^n x_{ijk} = y_{ik}, \quad \forall i \in \{0,...,n\}, k \in \{1,...,m\} \\ &\sum_{i=0}^n x_{ijk} = y_{jk}, \quad \forall j \in \{0,...,n\}, k \in \{1,...,m\} \\ &\sum_{i \in S} \sum_{j \in S} x_{ijk} \leq |S|-1, \quad \forall S \subseteq \{1,...,n\}, |S| \geq 2 \\ &x_{ijk} \in \{0,1\}, y_{ik} \in \{0,1\} \end{aligned} 最小化i=0∑nj=0∑nk=1∑mcijxijk约束条件:i=0∑ndiyik≤Qk,∀k∈{1,...,m}k=1∑myik=1,∀i∈{1,...,n}j=0∑nxijk=yik,∀i∈{0,...,n},k∈{1,...,m}i=0∑nxijk=yjk,∀j∈{0,...,n},k∈{1,...,m}i∈S∑j∈S∑xijk≤∣S∣−1,∀S⊆{1,...,n},∣S∣≥2xijk∈{0,1},yik∈{0,1}
其中:
- nnn:客户点数量
- mmm:车辆数量
- cijc_{ij}cij:从点i到点j的运输成本
- did_idi:点i的需求量
- QkQ_kQk:车辆k的容量
- xijkx_{ijk}xijk:车辆k是否从i行驶到j
- yiky_{ik}yik:车辆k是否服务点i
4.2 库存优化模型
报童模型扩展版:
minq≥0[cq+h∫0q(q−x)f(x)dx+p∫q∞(x−q)f(x)dx] \min_{q \geq 0} \left[ c q + h \int_0^q (q - x) f(x) dx + p \int_q^\infty (x - q) f(x) dx \right] q≥0min[cq+h∫0q(q−x)f(x)dx+p∫q∞(x−q)f(x)dx]
最优解满足:
F(q∗)=p−cp+h F(q^*) = \frac{p - c}{p + h} F(q∗)=p+hp−c
其中:
- qqq:订货量
- ccc:单位成本
- hhh:单位持有成本
- ppp:单位缺货成本
- f(x)f(x)f(x):需求概率密度函数
- F(x)F(x)F(x):需求累积分布函数
5. 项目实战:代码实际案例和详细解释说明
5.1 开发环境搭建
推荐使用以下技术栈:
- 数据采集:Apache Kafka, Flume
- 数据处理:Apache Spark, Flink
- 存储:HDFS, MongoDB, Elasticsearch
- 分析:Python (Pandas, Scikit-learn), R
- 可视化:Tableau, Grafana
Docker compose配置示例:
version: '3'
services:
zookeeper:
image: confluentinc/cp-zookeeper:latest
environment:
ZOOKEEPER_CLIENT_PORT: 2181
kafka:
image: confluentinc/cp-kafka:latest
depends_on:
- zookeeper
ports:
- 9092:9092
environment:
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092
spark:
image: bitnami/spark:latest
ports:
- 4040:4040
volumes:
- ./data:/data
mongodb:
image: mongo:latest
ports:
- 27017:27017
volumes:
- ./mongo-data:/data/db
5.2 智能调度系统实现
import pandas as pd
from datetime import datetime, timedelta
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, udf
from pyspark.sql.types import *
# 初始化Spark
spark = SparkSession.builder \
.appName("LogisticsOptimization") \
.config("spark.executor.memory", "4g") \
.getOrCreate()
# 模拟订单数据
order_schema = StructType([
StructField("order_id", StringType()),
StructField("customer_id", StringType()),
StructField("pickup_location", StringType()),
StructField("delivery_location", StringType()),
StructField("weight", DoubleType()),
StructField("volume", DoubleType()),
StructField("priority", IntegerType()),
StructField("create_time", TimestampType()),
StructField("due_time", TimestampType())
])
orders_data = [
("ORD001", "CUST001", "LOC001", "LOC005", 10.5, 0.5, 1, datetime.now(), datetime.now()+timedelta(hours=3)),
("ORD002", "CUST002", "LOC002", "LOC006", 15.0, 0.8, 2, datetime.now(), datetime.now()+timedelta(hours=4)),
("ORD003", "CUST003", "LOC003", "LOC007", 8.0, 0.3, 1, datetime.now(), datetime.now()+timedelta(hours=2)),
("ORD004", "CUST004", "LOC004", "LOC008", 20.0, 1.2, 3, datetime.now(), datetime.now()+timedelta(hours=5))
]
orders_df = spark.createDataFrame(orders_data, order_schema)
# 车辆数据
vehicle_schema = StructType([
StructField("vehicle_id", StringType()),
StructField("current_location", StringType()),
StructField("capacity", DoubleType()),
StructField("volume_capacity", DoubleType()),
StructField("speed", DoubleType()),
StructField("available_time", TimestampType())
])
vehicles_data = [
("VH001", "LOC001", 1000.0, 10.0, 60.0, datetime.now()),
("VH002", "LOC002", 1500.0, 15.0, 50.0, datetime.now()),
("VH003", "LOC003", 800.0, 8.0, 70.0, datetime.now())
]
vehicles_df = spark.createDataFrame(vehicles_data, vehicle_schema)
# 距离矩阵
distance_data = [
("LOC001", "LOC005", 15.0),
("LOC002", "LOC006", 20.0),
("LOC003", "LOC007", 12.0),
("LOC004", "LOC008", 25.0),
# 添加更多位置间距离...
]
distance_df = spark.createDataFrame(distance_data, ["loc1", "loc2", "distance"])
# 调度算法
def schedule_orders(orders_df, vehicles_df, distance_df):
# 将数据收集到驱动程序
orders = orders_df.collect()
vehicles = vehicles_df.collect()
distance_dict = {(row.loc1, row.loc2): row.distance
for row in distance_df.collect()}
# 按优先级和紧急程度排序订单
sorted_orders = sorted(orders,
key=lambda x: (-x.priority,
(x.due_time - x.create_time).total_seconds()))
assignments = []
for order in sorted_orders:
best_vehicle = None
min_cost = float('inf')
for vehicle in vehicles:
# 计算车辆到取货点的距离
pickup_dist = distance_dict.get((vehicle.current_location, order.pickup_location),
float('inf'))
# 计算配送距离
delivery_dist = distance_dict.get((order.pickup_location, order.delivery_location),
float('inf'))
total_dist = pickup_dist + delivery_dist
# 检查容量约束
if (vehicle.capacity >= order.weight and
vehicle.volume_capacity >= order.volume):
# 计算成本 (这里简化为距离)
cost = total_dist
if cost < min_cost:
min_cost = cost
best_vehicle = vehicle
if best_vehicle:
# 记录分配
assignments.append({
'order_id': order.order_id,
'vehicle_id': best_vehicle.vehicle_id,
'pickup_time': (datetime.now() +
timedelta(hours=pickup_dist/best_vehicle.speed)),
'delivery_time': (datetime.now() +
timedelta(hours=(pickup_dist+delivery_dist)/best_vehicle.speed)),
'cost': min_cost
})
# 更新车辆状态 (在实际系统中应该持久化这些变更)
best_vehicle.current_location = order.delivery_location
best_vehicle.capacity -= order.weight
best_vehicle.volume_capacity -= order.volume
best_vehicle.available_time = (datetime.now() +
timedelta(hours=(pickup_dist+delivery_dist)/best_vehicle.speed))
return spark.createDataFrame(assignments)
# 执行调度
assignments_df = schedule_orders(orders_df, vehicles_df, distance_df)
assignments_df.show()
5.3 代码解读与分析
上述智能调度系统实现了以下核心功能:
-
数据模型设计:
- 订单数据模型包含位置、重量、体积、优先级和时间约束等关键属性
- 车辆数据模型包含当前位置、载重能力、容积能力和速度等属性
- 距离矩阵存储位置间距离信息
-
调度算法逻辑:
- 订单按优先级和紧急程度排序
- 为每个订单寻找最合适的车辆:
- 检查容量约束
- 计算取货和配送的总距离
- 选择使总成本最小的车辆
- 更新车辆状态以反映新分配的任务
-
优化方向:
- 引入实时交通数据动态更新距离矩阵
- 考虑多点取货和配送的复杂场景
- 加入机器学习预测模型预估配送时间
- 实现分布式计算处理大规模数据
6. 实际应用场景
6.1 实时货物追踪系统
结合IoT设备实现:
- RFID标签实时采集货物位置
- 温度湿度传感器监控冷链物流
- 震动传感器检测运输质量
6.2 智能仓储管理
- 基于计算机视觉的自动分拣
- AGV机器人路径规划
- 动态货位分配优化
6.3 需求预测与网络优化
- 使用时间序列分析预测区域需求
- 设施选址优化模型
- 动态定价策略
6.4 绿色物流创新
- 碳排放计算与优化
- 新能源车辆调度
- 包装回收预测模型
7. 工具和资源推荐
7.1 学习资源推荐
7.1.1 书籍推荐
- 《物流大数据分析与应用》- 王建军
- 《Supply Chain Analytics》- Narendra Agrawal
- 《The Logistics and Supply Chain Innovation Handbook》- John Manners-Bell
7.1.2 在线课程
- Coursera: “Supply Chain Analytics” by Rutgers University
- edX: “Data Science for Supply Chain Analytics” by MIT
- Udacity: “AI for Logistics” Nanodegree
7.1.3 技术博客和网站
- Logistics Viewpoints (logisticsviewpoints.com)
- Supply Chain Digital (supplychaindigital.com)
- Google AI Blog - Logistics section
7.2 开发工具框架推荐
7.2.1 IDE和编辑器
- Jupyter Notebook/Lab
- PyCharm Professional
- VS Code with Python插件
7.2.2 调试和性能分析工具
- Spark UI
- Grafana for monitoring
- Python Profiler
7.2.3 相关框架和库
- 优化求解器: Google OR-Tools, Gurobi
- 地理计算: GeoPandas, OSMnx
- 机器学习: TensorFlow, PyTorch
7.3 相关论文著作推荐
7.3.1 经典论文
- “Vehicle Routing Problem with Time Windows” - Solomon (1987)
- “A Genetic Algorithm for the Vehicle Routing Problem” - Baker & Ayechew (2003)
7.3.2 最新研究成果
- “Deep Reinforcement Learning for Logistics Optimization” - Nature (2021)
- “Digital Twin in Logistics: A Systematic Literature Review” - IJPR (2022)
7.3.3 应用案例分析
- Amazon Robotics: 仓储自动化案例研究
- UPS ORION系统: 路线优化实践
- DHL Resilience360: 风险管理平台
8. 总结:未来发展趋势与挑战
8.1 技术发展趋势
- 数字孪生技术:构建物流系统全生命周期的数字映射
- 自动驾驶物流:无人卡车和配送机器人的普及
- 区块链溯源:增强供应链透明度和可信度
- 边缘计算:实现分布式实时数据处理
8.2 业务创新方向
- 共享物流平台
- 按需仓储服务
- 众包配送网络
- 循环物流经济
8.3 主要挑战
- 数据孤岛问题:跨企业数据共享机制
- 实时性要求:毫秒级决策响应
- 安全与隐私:敏感数据保护
- 人才缺口:复合型技术人才短缺
9. 附录:常见问题与解答
Q1: 如何评估物流大数据项目的ROI?
A: 建议从以下维度评估:
- 运营效率提升(如车辆利用率、人均处理量)
- 成本节约(燃油、人力、库存成本)
- 客户体验改善(准时交付率、投诉率)
- 碳排放减少量
Q2: 中小企业如何低成本实施物流大数据方案?
A: 推荐路径:
- 从SaaS解决方案入手
- 优先实施高ROI的模块(如路径优化)
- 利用开源工具降低技术成本
- 考虑与第三方物流数据平台合作
Q3: 如何处理物流数据中的噪声和异常值?
A: 常用方法:
- 基于规则过滤(速度突变、不可能路线等)
- 统计方法(Z-score, IQR)
- 机器学习异常检测(Isolation Forest, Autoencoder)
- 结合业务知识的人工复核机制
10. 扩展阅读 & 参考资料
- 中国物流与采购联合会.《中国智慧物流发展报告2023》
- McKinsey & Company. “Digital twins: The art of the possible in product development and beyond” (2022)
- Gartner. “Hype Cycle for Supply Chain Strategy” (2023)
- World Economic Forum. “The Future of the Last-Mile Ecosystem” (2020)
- IEEE Transactions on Intelligent Transportation Systems (最新期)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献132条内容
已为社区贡献132条内容

所有评论(0)