【论文阅读】Hybrid CNN-Transformer Network With Circular Feature Interaction for Acute Ischemic Stroke Les
研究背景与挑战病灶分割是诊断急性缺血性脑卒中(AIS)的一个基础且关键的步骤。NCCT仍然是测量AIS病灶的主流成像模态,因为它获取速度快且成本低。然而,在NCCT图像上进行AIS病灶分割非常困难,主要原因在于NCCT图像存在低对比度、噪声和伪影。提出的解决方案和模型架构:为了在NCCT上实现准确的AIS病灶分割,本研究提出了一种混合卷积神经网络(CNN)和Transformer网络,并结合了循环
论文链接:https://ieeexplore.ieee.org/document/10423037
Code: https://github.com/hulinkuang/Cl-SegNet
来源: IEEE TRANSACTIONS ON MEDICAL IMAGING
摘要:
- 研究背景与挑战
- 病灶分割的重要性: 病灶分割是诊断急性缺血性脑卒中(AIS)的一个基础且关键的步骤。
- 主流成像模态: NCCT仍然是测量AIS病灶的主流成像模态,因为它获取速度快且成本低。
- 分割挑战: 然而,在NCCT图像上进行AIS病灶分割非常困难,主要原因在于NCCT图像存在低对比度、噪声和伪影。
- 提出的解决方案和模型架构:为了在NCCT上实现准确的AIS病灶分割,本研究提出了一种混合卷积神经网络(CNN)和Transformer网络,并结合了循环特征交互和双侧差异学习。该模型主要由以下几个部分组成:
- 并行编码器(Parallel Encoders): 模型包含并行的CNN编码器和Transformer编码器,用于提取不同类型的特征。
- 循环特征交互模块(Circular Feature Interaction Module): 用于有效地结合来自CNN和Transformer编码器的特征。
- 共享CNN解码器(Shared CNN Decoder): 负责生成最终的分割结果。
- 双侧差异学习模块(Bilateral Difference Learning Module): 被置于解码器的底部,用于学习**大脑缺血侧与对侧(健康侧)**之间的差异信息。
- 模型关键创新点
- 新型Transformer块: 设计了一种新的Transformer块,旨在解决传统Transformer**弱归纳偏置(weak inductive bias)**的问题。
- 多级特征聚合(Multi-level Feature Aggregation): 为了有效地结合特征,首先设计了一个多级特征聚合模块,用于在每个编码器中结合多尺度特征。
- 循环特征交互模块的构成: 提出了一种新颖的特征交互模块,其中包含循环的CNN-到-Transformer(CNN-to-Transformer)和Transformer-到-CNN(Transformer-to-CNN)交互块。
- 双侧差异学习: 该模块在解码器的底部被提出,用于学习大脑缺血侧和对侧之间的不同信息。
- 实验结果与结论
- 数据集: 所提出的方法在三个AIS数据集上进行了评估:公共的AISD数据集、一个私有数据集和一个外部数据集。
- 性能: 实验结果表明,该方法在AISD和私有数据集上分别取得了61.39%和46.74%的Dice分数,优于17种最先进的分割方法。
- 临床意义: 对分割病灶进行体积分析以及外部验证结果表明,该方法有潜力为AIS诊断提供支持信息。
1. 引言
卒中及其诊断的重要性
- 卒中(Stroke) 是最普遍的脑血管疾病,也是全球第三大致死原因。
- 急性缺血性卒中(AIS) 占所有卒中病例的75%-85%,是由于脑部血流量减少,导致脑细胞损伤。
- 在临床实践中,通过卒中病灶分割(stroke lesion segmentation) 获得的病灶大小和位置信息,对于AIS的诊断、治疗决策和预后至关重要。
NCCT影像模态的挑战与现状
- 非增强CT(Non-contrast CT, NCCT) 仍然是AIS病灶测量的主要影像模态,因为它获取速度快、成本低(相比于MRI)。
- 然而,在NCCT上进行AIS病灶分割非常具有挑战性,原因在于:对比度低、噪声大和伪影多。
- 目前,手动分割 AIS病灶仍然是NCCT上病灶体积测量的标准方法,但它耗时且繁琐。
- 因此,临床上迫切需要自动化、准确 的NCCT卒中病灶分割方法。
基于深度学习的分割方法(CNN vs. Transformer)
卷积神经网络 (CNN) 方法的优势与局限性
- 自UNet出现以来,大多数现有的AIS病灶分割方法都采用了U型CNN架构,包括一个编码器和一个解码器。
- 这些方法使用一系列连续的卷积来提取特征,并通过跳跃连接(skip-connected) 将特征传送到解码器以生成分割掩模。
- 优势: CNN能够很好地捕捉局部信息。
- 局限性: 由于卷积操作固有的局部性(locality),基于CNN的方法在建模**长程依赖关系(long-range dependency,即全局信息)**方面存在限制,而全局信息对于图像分割任务至关重要。
Transformer 方法的优势与局限性
- 优势: Transformer具有捕获长程依赖关系的强大能力,已被应用于医学图像分割。
- 这些方法通常使用Transformer块构建编码器或解码器,并通过补丁合并(patch merging) 和 补丁扩展(patch expanding) 来实现特征图的降采样和升采样。
- 局限性:
- 缺乏归纳偏置(induction bias):导致Transformer模型难以训练。
- 数据需求大:为了达到更好的性能,Transformer需要大量的带标注数据进行训练,这对于医学图像分割任务来说很难实现。
混合 CNN-Transformer 方法的挑战:
- 如何有效地捕获 CNN 和 Transformer 特征
- 未有效学习 CNN 特征:
nnFormer和NesT仅使用 Transformer 块设计编码器,而用 CNN 来实现上采样和下采样。这可能导致它们无法学习到有效的 CNN 特征。 - 未有效学习 Transformer 特征:
TransUNet和UCATR使用 CNN 作为编码器,只在底部层使用 Transformer 块来捕获全局特征。这可能导致它们未能有效地学习到 Transformer 特征。
- 未有效学习 CNN 特征:
- 如何解决 Transformer 归纳偏置(Inductive Bias)弱的问题: Transformer 缺乏归纳偏置(即对局部性、平移不变性等先验知识的假设),通常需要大规模数据集才能获得良好性能。
- 医疗影像领域的困难: 医疗图像数据难以获取,且需要专家进行标注,导致带标注的医疗数据量通常有限。调查显示,一些未解决 Transformer 弱归纳偏置的方法(如
UNETR)在小规模医疗图像数据集上表现不佳。 - 结论: 解决 Transformer 的弱归纳偏置对于提高小规模 AIS 数据集的分割性能至关重要。
- 医疗影像领域的困难: 医疗图像数据难以获取,且需要专家进行标注,导致带标注的医疗数据量通常有限。调查显示,一些未解决 Transformer 弱归纳偏置的方法(如
- 如何实现 CNN 和 Transformer 特征的有效结合: CNN 和 Transformer 特征具有互补性(CNN 擅长局部信息,Transformer 擅长全局依赖),它们可以相互指导。但现有方法未能实现有效的特征交互。
- 简单输入/融合:
TransUNetCoTr使用卷积编码器提取特征后,直接将 CNN 特征输入到 Transformer 块中。 - 简单相加或拼接:
TransAttUNet对 CNN 和 Transformer 特征进行逐元素相加;MPViT简单地在每个阶段将特征进行拼接。
- 简单输入/融合:
- 如何有效利用临床先验知识来增强 AIS 病灶分割性能: 医生通常会利用脑部缺血侧和对侧之间的双侧差异来解释医学图像进行 AIS 病灶分割。
-
需要预处理: 大多数方法需要在输入阶段进行图像配准,或在网络开始时增加对齐网络,以利用图像的对称性。
缺点: 配准和对齐操作增加了预处理时间或网络的复杂性。
-
提出的解决方案与贡献:
为了应对上述挑战,作者提出了一种新的混合 CNN-Transformer 网络,并带有圆形特征交互和双侧差异学习模块。
- 解决挑战 A(有效捕获特征): 设计了一个 CNN 编码器和一个 Transformer 编码器并行运行,以分别有效地捕获 CNN 和 Transformer 特征。
- 解决挑战 B(解决弱归纳偏置): 设计了一种新的 Transformer 块,称为 Hybridformer 块。通过引入卷积模块,使得模型能够更有效地收敛。 Hybridformer 块使用不含参数的池化操作代替多头自注意力(multi-head self-attention),并结合了一个基于 CNN 的块(DWBlock) 来解决弱归纳偏置问题。
- 解决挑战 C(有效结合特征): 设计了一个圆形特征交互(Circular Feature Interaction, CFI)模块,包含基于注意力的 CNN-to-Transformer (C2T) 和 Transformer-to-CNN (T2C) 块。
- 解决挑战 D(有效利用临床先验知识): 设计了一个双侧差异学习(Bilateral Difference Learning, BDL)模块,该模块在解码器的高级语义空间中学习左右脑之间的差异。通过在高级语义空间中学习差异,可以避免复杂的配准或对齐操作,从而高效地利用双侧强度比较的临床先验知识,增强 AIS 病灶分割性能。
2. 相关工作
A. 基于 CNN 的方法
CNNs 是图像分割的首选模型,但其固有局限性在于难以有效地建模长距离依赖关系(全局信息)。
- 通用 CNN 分割模型:
- AttnUNet2D: 在 UNet 模型中,于上采样后应用了注意力机制。
- AttnUNet3D: 开发了一个基于注意力机制的 3D CNN 来分割脑肿瘤。
- nnUNet: 设计了一个自动确定模型架构和超参数的网络流程,并提供了 3D 和 2D 版本。
- AIS 特定的 CNN 模型: 这些方法针对 AIS 病灶分割的挑战进行了定制。
- UNet-RF : 采用两阶段方式将 CNN 和随机森林结合起来进行病灶分割。
- EIS-Net: 设计了三联体 CNN 编码器、编码器间特征差异计算块,以及共享解码器中的多级门控注意力模块,以实现准确的 AIS 病灶分割。
- SEAN: 设计了一个对齐网络来对齐图像,保持脑区域位于图像中心和水平对称,并设计了一个对称注意力模块来建模对称位置之间的关系。
- LambdaUNet: 提出了一种专为分割高度不连续的 2.5D 数据而设计的新方法。
- UNet-AM: 设计了一个残差、非对称 CNN 来解决梯度消失的问题。
- UNet-GC: 采用分组卷积分别处理参数图,使模型更加精简。
- ISNet: 采用分层网络作为骨干,并使用多尺度特征融合模块来融合不同级别的特征。
局限性总结: 虽然这些 CNN 方法在 AIS 病灶分割上有所进展,但其性能仍有待提高,并且它们通常没有有效地利用临床上的双侧差异(Bilateral Difference)知识。
B. 基于 Transformer 的方法
核心观点: Transformer 因其强大的全局建模能力,已成为自然语言处理和计算机视觉任务的首选模型。
Transformer 在图像分割中的应用:
- Swin Transformer: 提出了一种分层架构,通过“移位窗口”(shifted window)实现了线性计算复杂度。
- SwinUNet: 设计了一个纯基于 Transformer 的 U 型网络用于医学图像分割,取得了明显的改进。
局限性总结: 纯基于 Transformer 的方法通常需要大量数据集进行训练,这对于难以获取和标注的医学图像分割任务是一个挑战。
C. 混合 CNN 和 Transformer 的方法
核心观点: 混合模型结合了 CNN(擅长局部特征和归纳偏置)和 Transformer(擅长全局特征和长距离依赖)的优势,在医学图像分割领域取得了成功。
混合模型:
- TransUNet: 在 CNN 编码器的底部添加了 Transformer 层,用于全局上下文建模,从而改进医学图像分割。
- CoTr: 提出了一种混合框架来连接 CNN 和 Transformer,并利用可变形自注意力机制来降低传统 Transformer 的复杂性。
- nnFormer: 提出了基于局部和全局体素的自注意力机制来学习体素表示,并使用 CNN 进行下采样以引入归纳偏置。
- UNETR: 使用 Transformer 捕获全局多尺度信息,然后将这些特征输入 CNN 解码器。
- FAT-Net: 增加了一个额外的 Transformer 分支,以有效地捕获长距离依赖和全局上下文信息。
待解决的问题: 如何有效地结合 CNN 和 Transformer 的特征,仍然是一个悬而未决的问题。
3. 方法
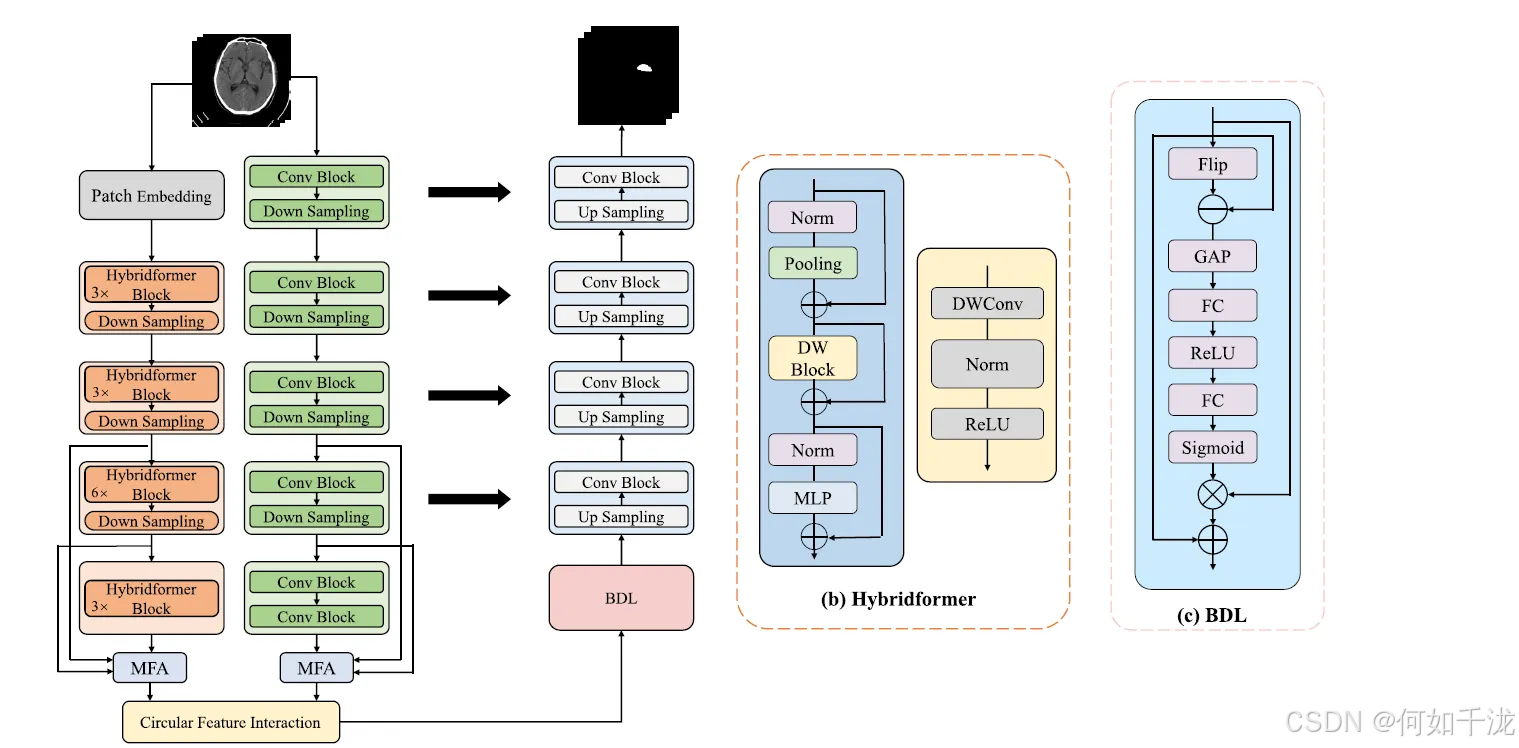
A. CNN 编码器
CNN编码器的设计类似于 nnUNet的设置,它由一系列堆叠的卷积层级组成,层级之间通过下采样进行连接。
- 结构: 每个层级包含一个卷积块 (Conv Block)。
- 卷积块细节: Conv Block 包括一个核大小为3的 3D 卷积层,后接实例归一化 (IN) 和 LeakyReLU 激活函数。
- 下采样: 下采样是通过一个步长为2的 Conv Block 实现的。
B. Transformer 编码器
Transformer编码器用于提取全局特征。
- 输入处理: 输入的医学图像首先通过一个 Patch Embedding Block 被分割成不重叠的图像块(patches)。
- NCCT特殊处理: 由于非对比CT(NCCT)扫描具有各向异性分辨率,这里使用的图像块大小为 1×4×4 以捕获更多空间信息。
- Patch Embedding 实现: 图像块嵌入是通过卷积操作实现的,其中核和步长与图像块大小相同。
- 分层结构和下采样: 受 Swin Transformer 启发,设计了一个分层 (hierarchical) Transformer 编码器,并通过下采样生成类似CNN的多级特征。
- 新的Transformer块: 提出的Transformer块结合了池化和卷积操作,称为 Hybridformer。
- 参数减少: 为了减少下采样中的模型参数数量,采用了 三线性插值 来降低特征图分辨率,并使用一个 1×1×1 卷积层来增加特征图的通道数。
- 阶段结构: 第1到第4阶段分别包含 3、3、6 和 3 个 Hybridformer 块。
Hybridformer 块 (Hybridformer Block):用于解决传统Transformer弱归纳偏置(weak inductive bias)问题而设计的新型块。
-
构成: 它由三个堆叠的残差子块组成,包含关键操作:池化操作 (Pooling Operation)、深度卷积块 (DWBlock) 和 多层感知机 (MLP)。
-
池化作为 Token Mixer: 一项近期研究 Metaformer表明,Transformer的固有优势来自于其通用架构而非Token Mixer的形式,并且使用简单的操作符进行Token Mixing也能达到良好性能。因此,由于平均池化 (Average Pooling) 没有参数且速度快,将其用作 Token Mixer 以减少参数。平均池化操作的核大小设置为3。
-
解决弱归纳偏置: 为了解决Transformer架构中的弱归纳偏置问题,并使其能够捕获高频信号,在第一个残差子块之后增加了一个深度卷积块 (DWBlock)。深度卷积与局部注意力(Local Attention)的效果相当。局部注意力可以聚合小区域内的信息,使模型感知该区域的快速变化,从而检测高频信息(如边缘)。
-
DWBlock 公式化: 假设输入特征为 X∈RC×D×H×WX∈R^{C×D×H×W}X∈RC×D×H×W(CCC 通道,分辨率 D×H×WD×H×WD×H×W)。
DWBlock(X)=δ(B(CDWk=5(X))) DWBlock(X)=δ(B(C_{DW}^{k=5}(X))) DWBlock(X)=δ(B(CDWk=5(X)))
其中:
- CDWk=5C_{DW}^{k=5}CDWk=5 表示核大小 k=5k=5k=5 的深度卷积。
- δδδ 是 ReLU 激活函数。
- BBB 是 批量归一化 (BN)。
-
MLP: 最后,使用一个MLP层来提取更本质的特征。
-
Hybridformer 块过程 (第 lll 层):
X~l=Pooling(Xl−1)+Xl−1,X‾l=DWBlock(X~l)+X~l,Xl=MLP(X‾l)+X‾l \widetilde X^l=Pooling(X^{l−1})+X^{l−1},\\ \overline X^l=DWBlock(\widetilde X^l)+\widetilde X^l,\\X^l=MLP(\overline X^l)+\overline X^l X l=Pooling(Xl−1)+Xl−1,Xl=DWBlock(X l)+X l,Xl=MLP(Xl)+Xl
其中 X~l\widetilde X^lX l、X‾l\overline X^lXl 和 XlX^lXl 分别表示 PoolingPoolingPooling、DWBlockDWBlockDWBlock 和
Hybridformer块的输出。 -
优势: Hybridformer 通过在 Transformer 架构中添加 DWBlock 来引入归纳偏置,有望在小规模数据集上表现良好,并优化模型的训练。
C. 多级特征聚合
为了更好地实现CNN编码器和Transformer编码器之间的特征交互,首先对它们各自的多级特征进行聚合。
- 聚合的必要性: 高级特征可以为图像分割提供更有效的抽象信息,因此只聚合最后3个层级的特征。
- 聚合过程: 将不同层级的特征通过三线性插值调整到相同大小,然后使用点状卷积 (PWConv) 在通道维度上聚合这些不同层级的特征。
- 简化模型: 通过这种多级特征聚合,可以避免在每个层级都进行卷积和Transformer编码之间的特征交互,从而降低模型的复杂性。
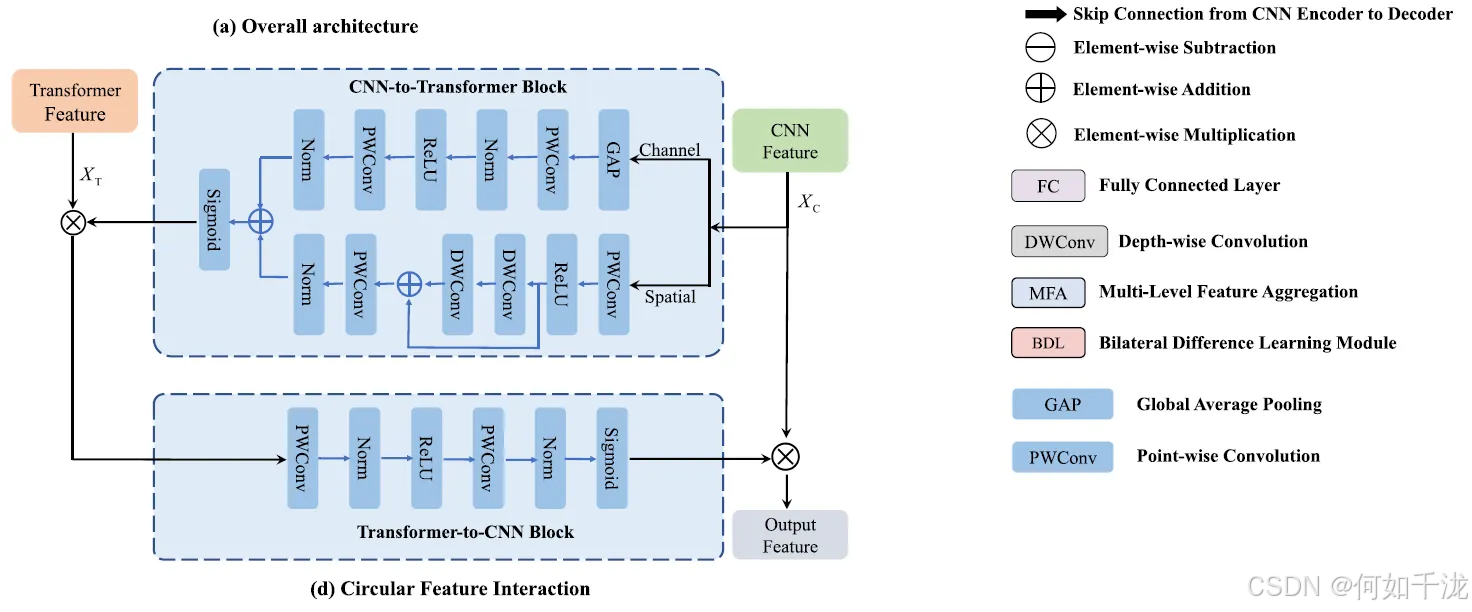
D. 循环特征交互模块
核心思想: 由于该模型具有并行的卷积神经网络(CNN)编码器和Transformer编码器,特征交互模块成为提高分割性能的关键因素。CNN提取的特征(擅长捕获局部信息)和Transformer提取的特征(擅长捕获长距离依赖/全局信息)是互补的,它们可以相互指导和完善。
模块目的: 在经过多级特征聚合(MFA)模块之后,为了有效结合来自CNN编码器和Transformer编码器的特征,作者提出了一个基于注意力机制的循环特征交互(CFI)模块。
组成部分:
- CNN-to-Transformer 交互块 (C2T)
- Transformer-to-CNN 交互块 (T2C)
该模块设计为“循环”结构:它首先使用C2T块,将CNN特征输入其中以调整Transformer特征;然后,将经过调整的Transformer特征输入到T2C块中,以调整原始的CNN特征。
CNN-to-Transformer 交互块 (C2T)
目的:C2T块旨在利用CNN的特征来调整(或精炼)Transformer的特征,从而增强这些特征中的全局信息。它通过在通道维度和空间维度上分别捕获全局信息来实现这一点。
实现细节: 假设XCX_CXC是来自CNN编码器的特征,XTX_TXT是来自Transformer编码器的特征。
-
通道维度(Channel Dimension)注意力:
- 首先使用全局平均池化 (GAP) 来获取不同通道的权重。
- 然后利用点式卷积 (PWConv) 作为通道上下文聚合器。
- 通道注意力分支 (CA) 由:GAP → PWConv → 批量归一化 (BN) → ReLU 激活 → 另一个 PWConv → 另一个 BN 组成。
-
空间维度(Spatial Dimension)注意力:
- 理论上应使用大核卷积进行全局空间特征提取,但直接使用计算成本高。
- 因此,通过结合PWConv和深度可分离卷积 (DWConv) 来在性能和计算成本之间取得平衡。
- 空间注意力分支 (SA) 由:PWConv → ReLU → 两个带残差连接的 DWConv 操作(用于提取不同尺度的空间特征) → 另一个 PWConv → BN 组成。
-
特征调整:
- 最后,将通道分支的特征和空间分支的特征进行元素级相加 (⊕⊕⊕)。
- 使用 Sigmoid (σσσ) 函数生成权重图。
- 该权重图用于调整 Transformer 的特征 (XTX_TXT)。
-
数学表达:
C2T=σ(CA(XC)⊕SA(XC)) C2T=σ(CA(X_C)⊕SA(X_C)) C2T=σ(CA(XC)⊕SA(XC))
其中,CACACA 是通道注意力分支,SASASA 是空间注意力分支,σσσ 是 Sigmoid 函数,⊕⊕⊕ 是元素级相加。
Transformer-to-CNN 交互块 (T2C)
-
目的:T2C块旨在利用Transformer中的全局特征来精炼(或详细阐述)来自CNN编码器的特征,并增强这些CNN特征中的局部信息。
-
实现细节: T2C块结构相对简单,它包含一系列卷积、归一化和激活操作,最终通过 Sigmoid 生成权重图。
-
数学表达:
T2C=σ(B(CPW(δ(B(CPW(C2T(XC)⊗XT)))))) T2C=σ(B(C_{PW}(δ(B(C_{PW}(C2T(X_C)⊗X_T)))))) T2C=σ(B(CPW(δ(B(CPW(C2T(XC)⊗XT))))))
这里,BBB 是批量归一化,CPWC_{PW}CPW 是点式卷积,δδδ 是 ReLU 激活,σσσ 是 Sigmoid 函数。
CFI 模块总结
- 整体操作: CFI模块将T2C和C2T块结合起来,实现特征的循环交互:
- C2T块首先接收CNN特征 (XCX_CXC) 并利用它生成一个注意力图。
- 这个注意力图与Transformer特征 (XTX_TXT) 进行元素级乘法 (⊗⊗⊗),完成第一次特征调整。
- 调整后的特征 (C2T(XC)⊗XTC2T(X_C)⊗X_TC2T(XC)⊗XT) 被输入 T2C 块进行处理。
- T2C块的输出(另一个注意力图)与原始 CNN 特征 (XCX_CXC) 进行元素级乘法 (⊗⊗⊗),完成最终特征的精炼。
- 总体的数学表达:
CFI=T2C(C2T(XC)⊗XT)⊗XC CFI=T2C(C2T(X_C)⊗X_T)⊗X_C CFI=T2C(C2T(XC)⊗XT)⊗XC
- 注意:这个交互模块仅用于两个编码器的最底层(即高语义层次)。
E. 共享CNN解码器
CNN解码器概述
- 结构相似性: CNN解码器的结构类似于nnUNet。
- 对称层: 解码器中每一层的卷积层都与其在CNN编码器中对称的相应层保持一致。
- 连接和上采样: 使用跳跃连接(Skip connection) 来整合编码器和解码器的特征。使用转置卷积(Transposed convolution) 进行特征图的上采样操作。
- 特殊模块: 在解码器的最底层(bottom layer),设计了一个专门用于学习双侧大脑差异(bilateral brain differences) 的模块。
双侧差异学习模块 (Bilateral Difference Learning Module, BDL)
-
动机: 在非增强CT(NCCT)扫描中,将缺血侧与对侧大脑进行比较是视觉识别急性缺血性卒中(AIS)病灶细微信号的关键步骤。对两侧大脑之间的差异信息进行建模可以增强网络对这些区域的注意力。
-
传统方法的局限性: 现有的多数方法通过在输入阶段将原始图像和翻转配准后的图像输入网络,或在开始时添加对齐网络来学习双侧差异特征 。然而,这些方法会增加模型的复杂性,并且分割结果容易受到配准或对齐效果的影响。
-
BDL的设计理念:
- 较深的特征级别(Deeper levels)通常具有更大的感受野(receptive field)。
- 在这些较深的特征图上,一个小区域对应于原始图像中更大的区域。
- 在这种情况下,深层特征图中对称的左右区域的特征,更有可能来自原始图像中对应的解剖区域。
- 因此,模型可以直接使用这些深层的左右区域特征来替代原始图像中对称的解剖区域特征。
-
BDL的具体实现:
- 特征翻转和相减: 首先对特征图 XXX 进行水平左右翻转,得到 XflipX_{flip}Xflip。然后,将翻转后的特征图从原始特征图中减去(X−XflipX−X_{flip}X−Xflip),以获得原始双侧特征差异。
- 权重图生成: 利用Squeeze-and-Excitation (SE) 模块来获取该特征差异的权重图。SE模块包括:全局平均池化(GAP)操作、两个全连接层(FC)和一个ReLU(δδδ)激活函数。
- 加权与残差连接: 将生成的权重图(通过 Sigmoid (σσσ) 激活)与原始输入特征 XXX 进行逐元素相乘(⊗⊗⊗)。最后,添加一个残差连接,将输入特征和生成的双侧特征差异相结合。
-
BDL公式:
BDL(X)=σ(FC(δ(FC(GAP(X−Xflip)))))⊗X+X BDL(X)=σ(FC(δ(FC(GAP(X−X_{flip})))))⊗X+X BDL(X)=σ(FC(δ(FC(GAP(X−Xflip)))))⊗X+X
其中:σσσ 是 Sigmoid 函数,FCFCFC 是全连接层,δδδ 是 ReLU 函数,XflipX_{flip}Xflip 是 XXX 的水平左右翻转特征。
F. 损失函数 (Loss Function)
模型采用在医学图像分割中最常用的联合 Dice 损失和交叉熵损失函数:
L=α(1−2∑y^nyn+ϵ∑(y^n+yn)+ϵ)+β(−E[ynlogy^n]) L=α(1−\frac {2∑\hat y^ny^n+ϵ} {∑(\hat y^n+y^n)+ϵ})+β(−{E} [y^nlog\hat y^n]) L=α(1−∑(y^n+yn)+ϵ2∑y^nyn+ϵ)+β(−E[ynlogy^n])
- Dice 损失: 公式中的第一项是 Dice 损失,用于衡量预测和真实标签之间的重叠度。
- 交叉熵损失: 第二项是交叉熵损失,用于衡量预测概率分布和真实标签分布之间的差异。
- 参数定义:
- y^\hat yy^ 和 yyy 分别代表预测值和真实标签 。
- EEE 是期望操作。
- ϵϵϵ 是一个平滑因子。
- ααα 和 βββ 分别代表这两种损失的权重。
4. 实验
A. 数据集
为了评估所提出方法的性能,研究人员在三个急性缺血性卒中(Acute Ischemic Stroke, AIS)病灶数据集上进行了实验:
- AISD 数据集 (AISD Dataset):
- 这是一个公开的 AIS 数据集,包含 397 例非增强 CT (Non-Contrast CT, NCCT) 扫描和相应的 MRI 扫描。
- 所有患者的卒中发作到 CT 扫描的时间 (onset-to-CT time) 少于 24 小时。
- 卒中病灶是在 NCCT 上由医生根据 MRI 扫描作为参考标准手动勾画的。
- 数据集被随机划分为:
- 训练集:305 例 NCCT 扫描。
- 验证集:40 例 NCCT 扫描。
- 测试集:52 例 NCCT 扫描。
- 私有数据集 A :
- 该数据集来自武汉协和医院,包含 350 例 NCCT 扫描和相应的弥散加权成像 (DWI) 扫描。
- 所有患者的卒中发作到 CT 扫描的时间 少于 3 小时(表明这是极早期的卒中)。
- 病灶的真实标注 (Ground Truth, GT) 是在 DWI 上手动勾画的。
- 数据集被随机划分为:
- 训练集:245 例 NCCT 扫描。
- 验证集:35 例 NCCT 扫描。
- 测试集:70 例 NCCT 扫描。
- 外部 AIS 数据集:
- 除了 AISD 和私有数据集 A 用于内部验证外,研究人员还从武汉协和医院金银湖院区收集了 32 例 AIS 患者的 NCCT 扫描作为外部验证数据集。
- 这些 CT 扫描的发作到 CT 时间少于 3 小时。
- 手动分割的标注是在 CT 扫描后大约 1 小时获取的 DWI 上勾画的。
B. 实施细节
所有实验均在 PyTorch 框架下,使用配备 32 GB 内存的 NVIDIA Tesla V100 GPU 和 CentOS7.9.2009 系统上实施。
- 超参数调整: 每个数据集的超参数都是在其验证集上根据 Dice 分数进行调整的。
- 编码器设置: 编码器中第一层的特征通道数设置为 16。
- 训练细节:
- 模型使用 SGD (随机梯度下降) 优化器进行训练。
- 批处理大小 (Batch size) 为 2。
- 训练了 160 个 epoch。
- 初始学习率设置为 0.01,并使用因子为 0.9 的 poly 学习率调度(poly learning rate schedule)。
- 损失权重: 联合 Dice 损失和交叉熵损失的权重 α 和 β 均实验性地设置为 1。
对比方法: 研究中共比较了 17 种现有先进 (SOTA) 方法:
- 9 种 2D 方法: AttnUNet2D、Swin-Unet、TransUNet、FAT-Net、nnUNet2D、LambdaUNet、ISNet、UNet-AM 和 UNet-GC。
- 8 种 3D 方法: AttnUNet3D、nnFormer、UNETR、CoTr 、nnUNet、3D-UNet、UNet-RF和 EIS-Net。
评估指标:
- 分割性能评估:
- Dice score (Dice 分数)。
- 95% Hausdorff Distance (HD95) (95% 豪斯多夫距离)。
- Average Symmetric Surface Distance (ASSD) (平均对称表面距离)。
- 体积分析评估:
- Accuracy (准确率)。
- Pearson correlation coefficient (皮尔逊相关系数)。
- Kappa。
- Area Under Curve (AUC) (曲线下面积) 及其 95% 置信区间 (CI)。
统计分析:
- Wilcoxon 符号秩检验 (Wilcoxon signed-rank test):用于 Dice、HD95 和 ASSD 的统计分析。
- 卡方检验 (Chi-squared test):用于准确率的统计分析。
- Z 检验 (Z test):用于皮尔逊相关系数、Kappa 和 AUC 的统计分析。
5. 结果
A. 内部数据集上的对比方法结果
两个内部数据集上的定量比较
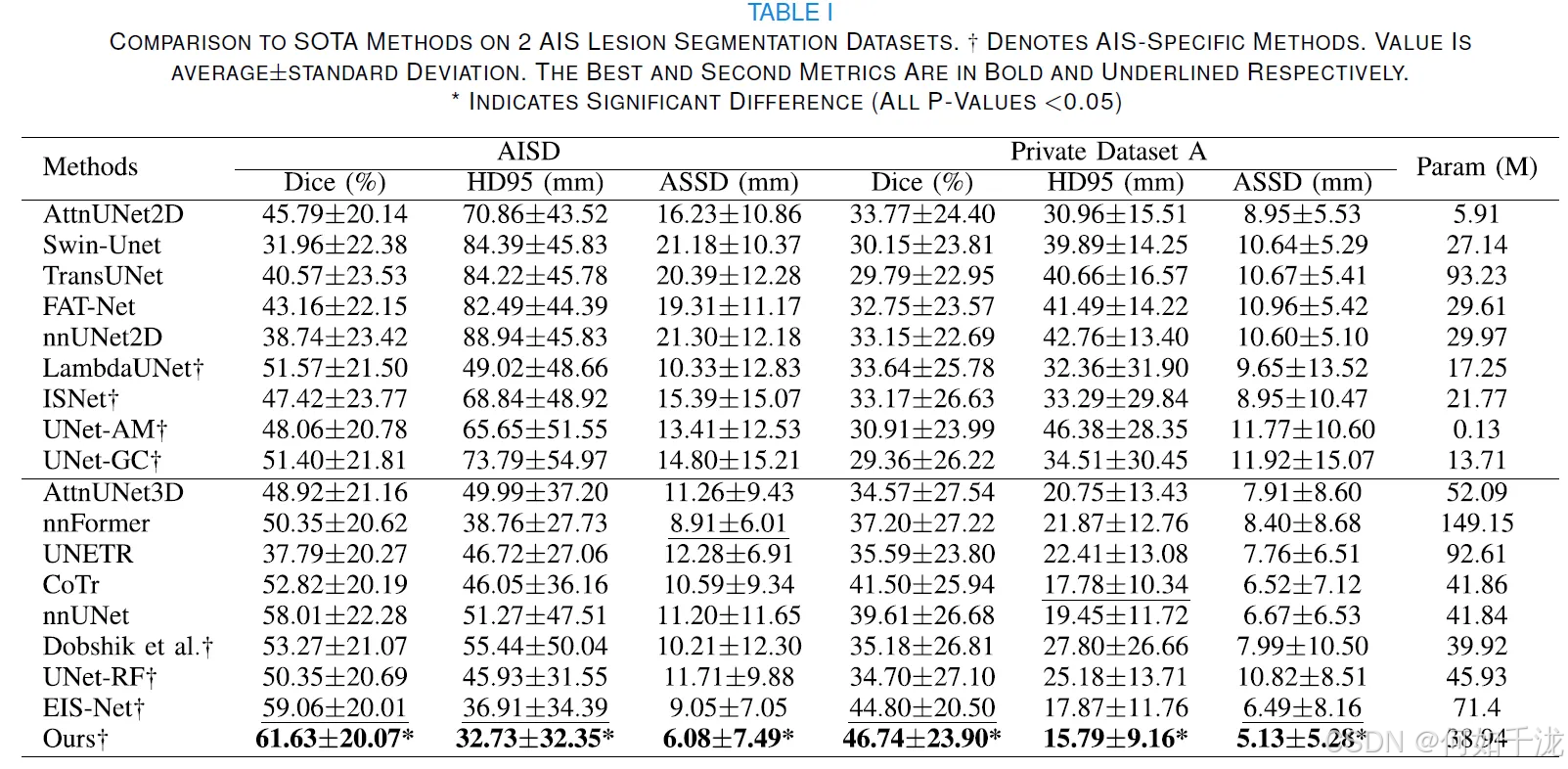
- 性能优越性: 表格 I 展示了所提出的方法与17种最先进(SOTA)方法在两个急性缺血性卒中(AIS)病灶分割数据集——AISD和Private Dataset A上的定量比较。
- 具体指标: 所提出的方法在AISD和Private Dataset A上均取得了最佳性能:
- Dice分数: AISD上为 61.63±20.07%,Private Dataset A上为 46.74±23.90%。
- HD95(95% Hausdorff Distance): AISD上为 32.73±32.35,Private Dataset A上为 15.79±9.16。
- ASSD(Average Symmetric Surface Distance): AISD上为 6.08±7.49,Private Dataset A上为 5.13±5.28。
- 结论: 所提出的方法优于所有SOTA的2D和3D方法。
- 与AIS特定方法的比较: 它还显著优于7种针对AIS的特定方法(包括ISNet、LambdaUNet等),所有 P 值都小于0.00$。
- 3D与2D方法的对比: 3D方法的性能优于2D方法,这表明3D空间信息可能有助于更好地将病灶与正常脑组织区分开。
- 混合架构的有效性: 与、nnFormer和UNETR等混合架构的比较表明,所提出的循环特征交互模块对于AIS病灶分割是有效的。
可视化检查示例
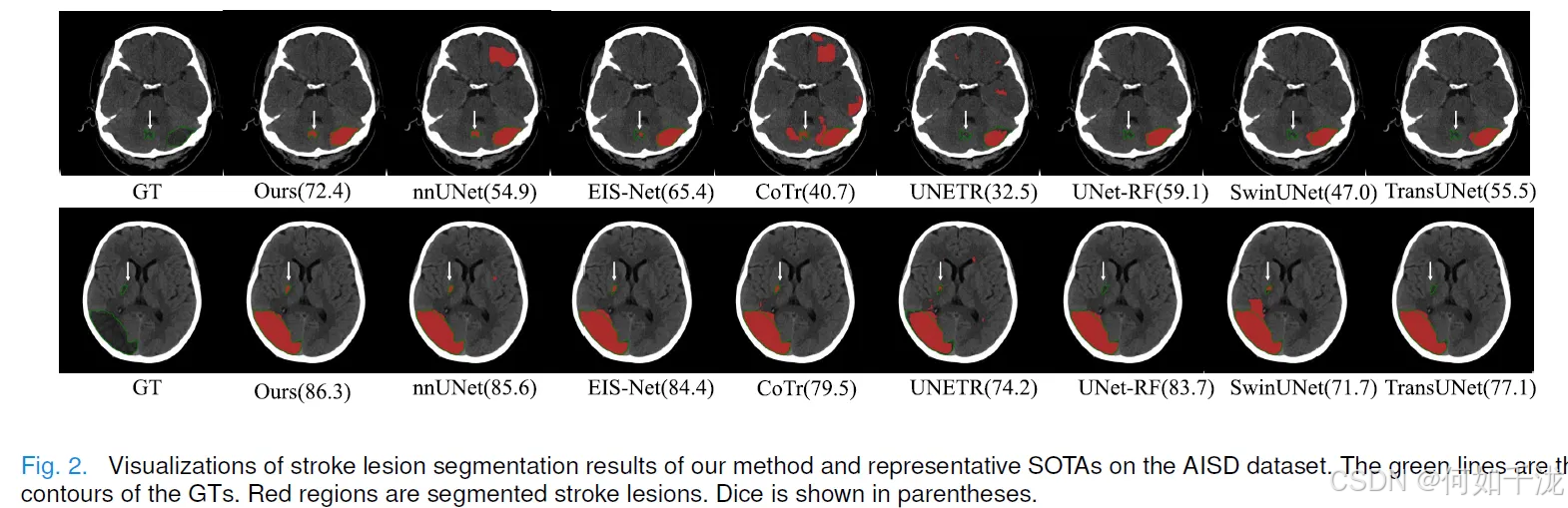
- 图 2 展示了AISD数据集上一些代表性方法的可视化分割结果。
- 优势体现: 结果显示,所提出的方法分割的病灶比其他SOTA方法更好地匹配了地面真实值(GT)。
- 具体案例: 例如,在图 2 的第一行,所提出的方法能够更准确地分割出小的病灶成分(白箭头所示),且假阴性(false negatives)少得多。
病灶体积分析
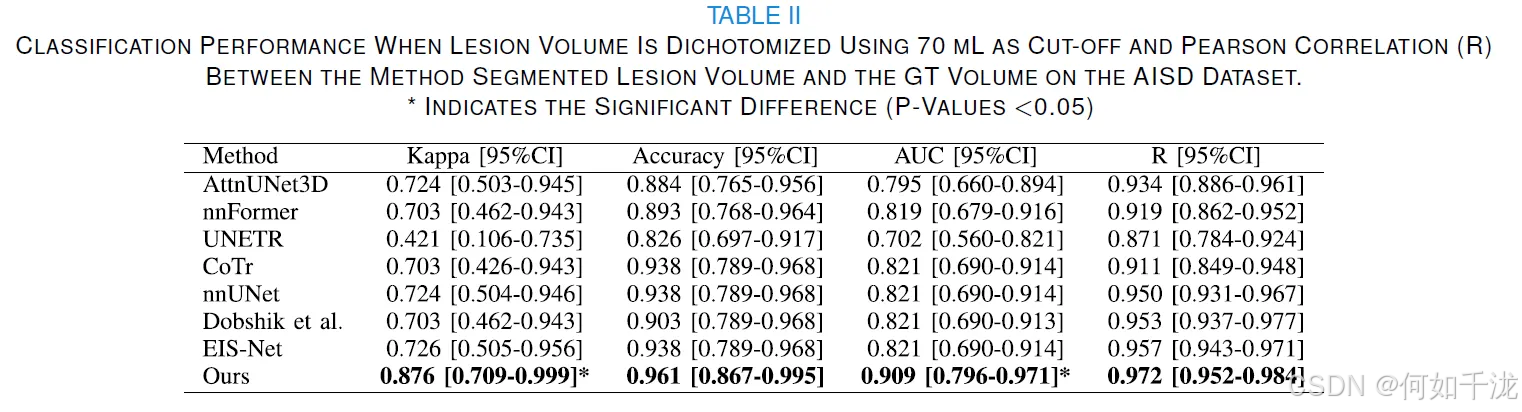
- 分析方法: 对所提出的方法和几种SOTA方法进行了病灶体积分析,包括病灶体积之间的皮尔逊相关系数(Pearson coefficients)和以 70 mL 为界限的二分类体积分类性能。
- 相关性: 表格 II 显示,在AISD数据集上,所提出的方法分割的病灶体积与GT体积呈强正相关(R=0.972,P<0.001)。
- 分类性能: 以 70 mL 为界限的体积分类结果(表格 II)显示,所提出的方法实现了最佳分类准确性:
- Kappa 值为0.876 [0.709-0.999]。
- AUC 值为 0.909 [0.796-0.971]。
- 准确率(Accuracy)为 0.961 [0.867-0.995]。
Bland-Altman图(图 3(a)): 展示了所提出的方法分割的病灶体积与GT体积之间的一致性。
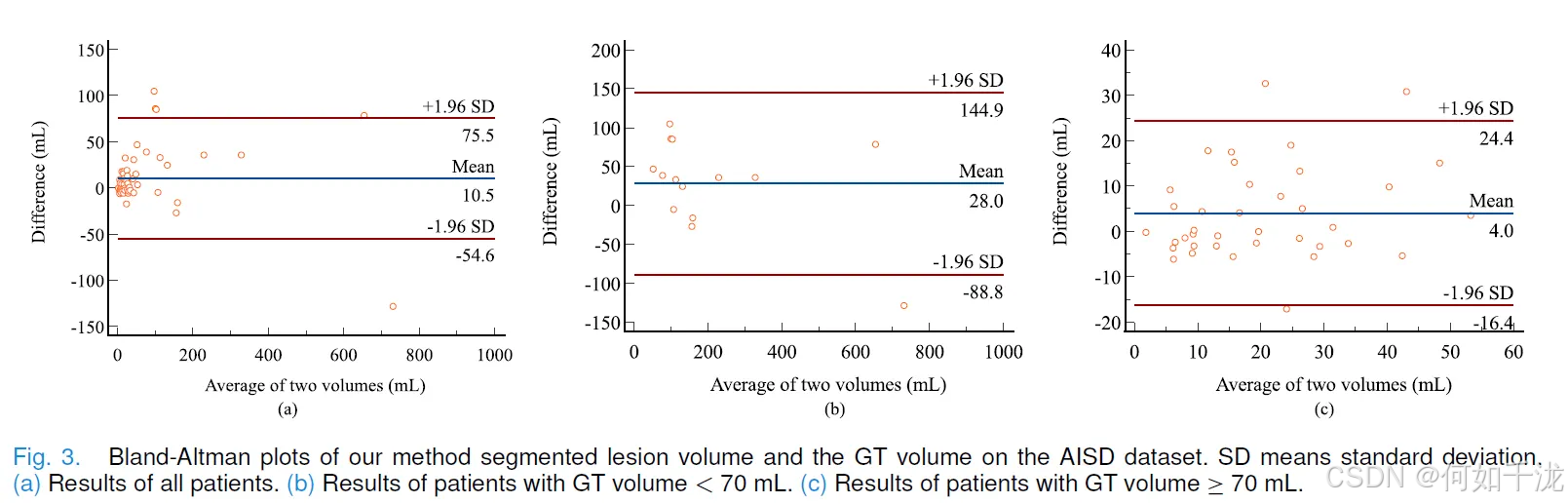
- 所有患者的平均体积差异为 10.5 mL。
- GT体积 ≤70 mL 的患者,平均差异很小(4 mL,图 3(b))。
- GT体积 ≥70 mL 的患者,平均差异为 28 mL(图 3©)。
B. 外部 AIS 数据集上的结果
-
目的: 为了验证所提出方法的泛化能力,在外部 AIS 数据集上进行了外部临床验证。
-
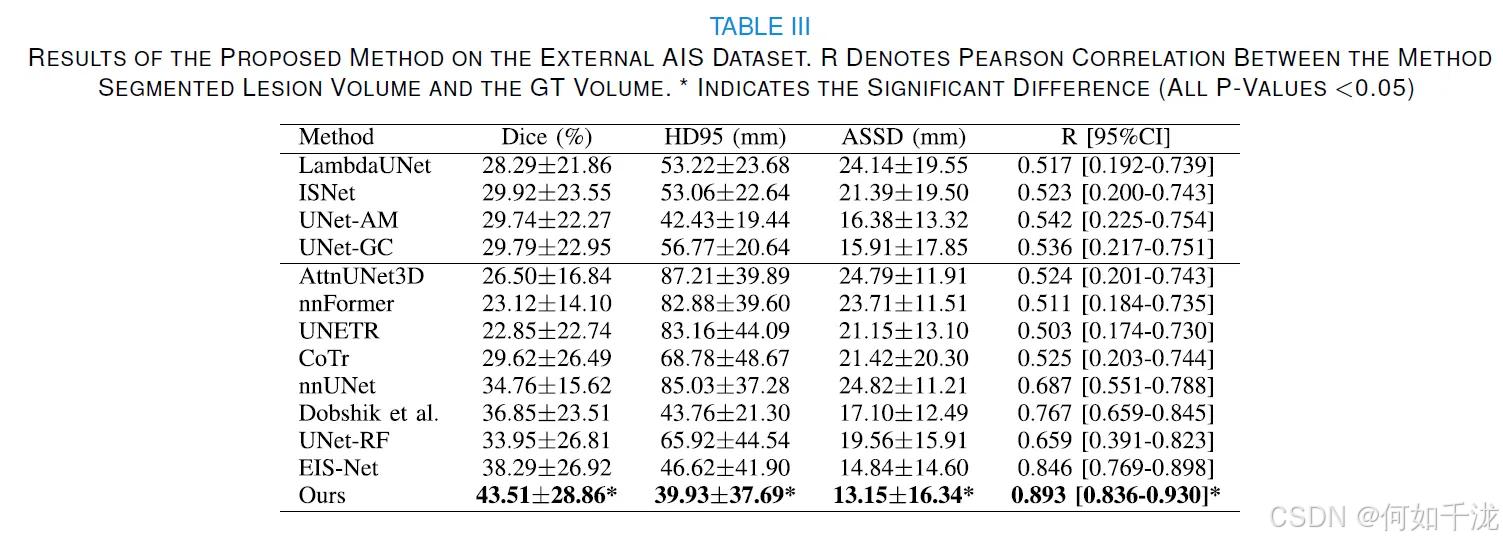
性能指标: 表格 III 显示,所提出的方法在外部 AIS 数据集上仍取得了最佳性能:
- Dice 分数:43.51±28.86%。
- HD95:39.93±37.69 mm。
- ASSD:13.15±16.34 mm。
-
结论: 优于所有比较的 SOTA 方法。
-
体积相关性: 所提出的方法分割的病灶体积与 GT 体积显示出强相关性(R=0.893,P<0.001)。
-
二分类体积分析: 使用 70 mL 截止值的体积分析结果(表格 IV)显示,所提出的方法取得了卓越的分类准确性:
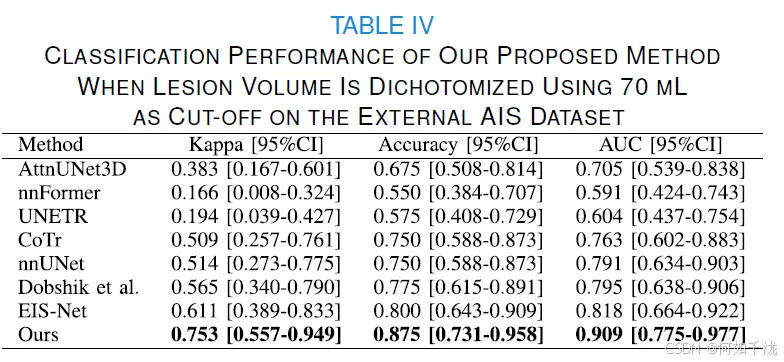
- Kappa 值为 0.753 [0.557-0.949]。
- AUC 值为 0.909 [0.775-0.977]。
- 准确率(Accuracy)为 0.875 [0.731-0.958]。
-
临床意义: 尽管所提出的方法在外部 AIS 数据集上的 Dice 分数可能不高,但其测量的病灶体积与 GT 病灶体积吻合良好,突显了其为临床应用提供有价值体积信息的潜力。
C. 消融研究
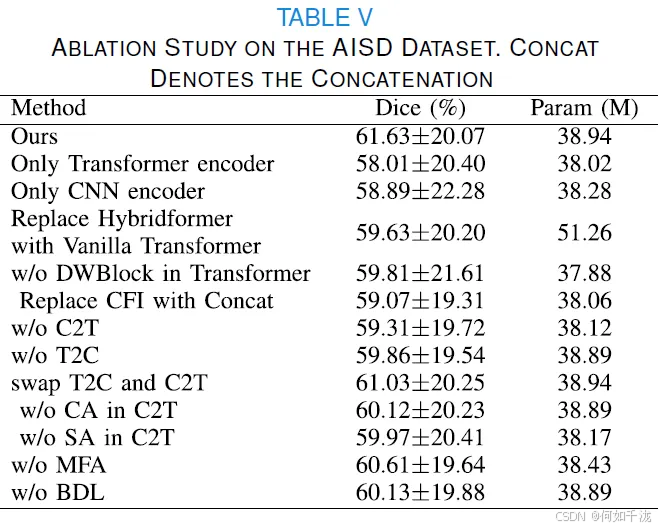
并行编码器的有效性
- 设计目的: 该模型使用了并行(Parallel)的CNN编码器和Transformer编码器来同时提取局部(CNN)和全局(Transformer)特征。
- 实验内容: 进行了四组实验来验证并行编码器的有效性:
- 单独使用CNN编码器: 结果显示Dice得分下降了2.74%。
- 单独使用Transformer编码器: 结果显示Dice得分下降了3.62%。
- 特征通道与参数量分析:
- 当使用并行编码器时,最优的初始特征通道数是16。
- 当单独使用CNN或Transformer编码器时,最优的初始特征通道数是32。
- 尽管并行编码器的参数量比单独使用最优配置(32个通道)的CNN或Transformer编码器略高(分别高出0.66M和0.92M),但性能更好。
- 进一步比较(相同通道数):
- 当强制单独使用CNN或Transformer编码器时,将初始特征通道数设为与并行编码器相同的16,虽然参数量大幅减少(分别减少16.58M和20.77M),但Dice得分下降更为显著(分别下降6.39%和8.48%)。
- 结论: 这些结果表明并行编码器更有效,并且能够以更少的特征(更少的初始特征通道数)实现最佳性能。
Hybridformer的有效性
- 设计目的: Hybridformer是该模型中提出的Transformer块。
- 实验内容:
- 替换为Transformer: 将Hybridformer替换为传统的Transformer块,Dice得分下降了2%。
- 移除DWBlock(Depthwise Convolution Block): 移除Hybridformer中的DWBlock,Dice得分下降了1.83%。
- 结论: 这些结果验证了所设计的Hybridformer块是有效的,它对性能提升有积极作用。
循环特征交互模块(CFI)的有效性
- 设计目的: CFI模块旨在实现并行CNN和Transformer编码器之间更有效的特征交互。
- 实验内容:
- 替换为简单拼接(Concatenation): 将CFI模块替换为简单的特征拼接操作,Dice得分下降了2.56%,而参数量仅减少了0.88M。
- 移除C2T块(CNN-to-Transformer block)或T2C块(Transformer-to-CNN block): CFI包含C2T和T2C两个关键部分。移除任一部分都会导致性能下降,这表明两者都对性能提升有贡献。
- C2T块内部组件的有效性:
- 移除通道注意力(CA): Dice得分下降了1.51%。
- 移除空间注意力(SA): Dice得分下降了1.66%。
- 移除CA或SA后,参数量减少微乎其微(0.05M和0.77M)。
- 结论: 这表明C2T块中设计的并行通道注意力和空间注意力能够以极小的参数增量(小于1M)提升分割性能。
- 交互顺序的影响: 交换C2T和T2C块的顺序,Dice得分下降了0.6%,这表明这两个块的顺序也是重要的。
多级特征聚合模块(MFA)的有效性
- 设计目的: MFA用于融合来自编码器不同层级的特征。
- 实验内容:
- 移除MFA: 在进行循环特征交互之前移除MFA,只使用最底层的特征。结果显示Dice得分下降了1.02%,参数量仅减少了0.51M。
- 结论: 这表明融合多级特征是有效的,并且参数量的增加微不足道(小于1M)。
双边差异学习模块(BDL)的有效性
- 设计目的: BDL模块用于捕捉大脑左右两侧解剖区域的特征差异,以指导病灶分割。
- 实验内容:
- 移除BDL模块: 移除BDL模块后,Dice得分下降了1.5%,参数量仅下降了0.05M。
- 结论: 这表明所设计的BDL模块能够有效地捕获双边差异,从而提高性能。
6. 讨论
B. 计算复杂度分析
这部分内容旨在比较所提出的方法与所有作为对比的3D最先进(SOTA)方法在计算效率和性能方面的权衡。
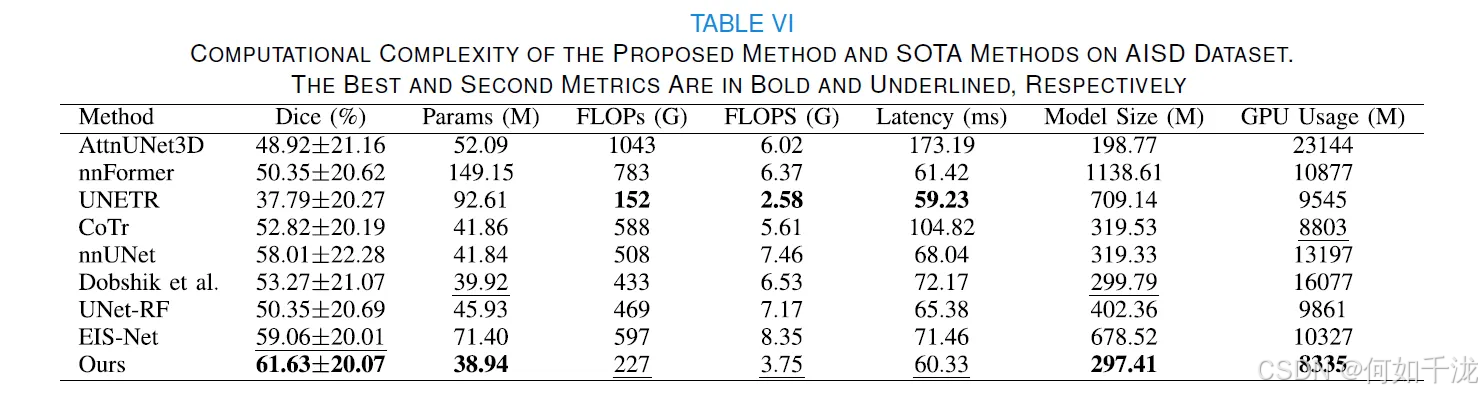
- 比较指标:研究人员比较了提议方法和其他3D方法在以下方面的表现:参数数量(number of parameters)、浮点运算次数(FLOPs,计算量)、每秒浮点运算次数(FLOPS,计算速度)、延迟(Latency)、模型大小(model size)和GPU内存使用量(GPU memory usage)。
- 提议方法的优势:根据表VI的数据,提议的方法在实现最高Dice分数(分割性能指标)的同时,拥有最少的参数(38.94M),最小的模型大小(297.41M)和最低的GPU内存使用量(8335M)。
- 效率对比:提议的方法在FLOPs (227G)、FLOPS (3.75G) 和延迟 (60.33ms) 方面排名第二,仅次于UNETR (152G, 2.58G, 59.23ms)。然而,提议方法的Dice分数 (61.63±20.07%) 远高于UNETR (37.79±20.27%)。
- 结论:这些结果表明,在所有3D方法中,所提出的方法不仅达到了最佳的分割性能,而且在分割性能和计算复杂度之间取得了最佳的平衡(tradeoff)。
C. MFA(多级特征聚合模块)的输入级别影响
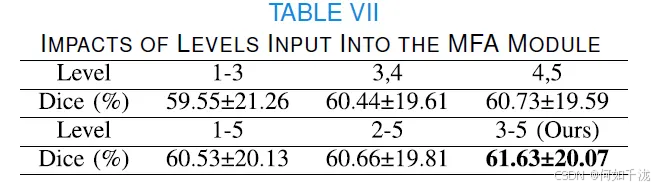
这部分实验验证了高级特征(High-level features)对于准确分割的有效性,通过融合来自不同级别的特征(使用MFA模块)进行测试。
- 实验发现:当仅聚合高级特征(Level 3-5) 时,获得了最佳的分割结果(Dice为61.63±20.07%)。
- 低级特征的影响:当仅聚合浅层特征(Level 1-3) 时,Dice分数下降了2.08%。
- 解释:浅层阶段的特征主要包含局部信息,而高级特征则更有效,能够获得准确的分割结果。
D. 循环特征交互模块(CFI)的影响

这部分实验旨在确定CFI模块在编码器中应用的最佳位置。
- 实验设置:在编码器的不同级别应用交互模块进行实验,其中除了Level 5之外,所有级别的交互模块输出都通过跳跃连接(skip-connected)传输到解码器。
- 最佳位置:最佳分割性能(Dice为61.63±20.07%)是在CNN特征和Transformer特征仅在最后一个级别(last level)进行交互时获得的。
- 最差结果:当在所有级别都使用特征交互模块时,结果最差(Dice为59.42±21.62)。
- 解释:推测在所有级别使用特征交互模块可能会导致冗余,从而影响分割结果。
E. 双侧差异学习模块(BDL)的位置影响

这部分实验探索了BDL模块放置在解码器不同级别时的有效性。
- 实验发现:随着BDL在解码器中的位置逐渐加深,分割性能也逐渐提高,并在最深(第5级) 的位置达到了最佳分割结果(Dice为61.63±20.07%)。
- 解释:这可能是因为在解码器最深层( deepest level)的特征图上,左右对称区域的特征更可能源自原始图像中的对称区域。因此,BDL模块能够有效地捕获大脑两侧的特征差异。
F. BDL相对于配准和对齐的优势
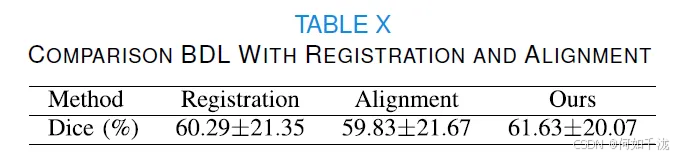
这部分实验旨在验证所提出的BDL模块相对于传统的图像配准(Registration)或对齐(Alignment)操作的优势。
- 对比实验设置:
- 实验一(配准):在预处理阶段,首先翻转原始图像,然后使用ANTsPy提供的配准功能对翻转后的图像进行配准。将原始图像和配准后的图像输入网络。
- 实验二(对齐):在输入阶段使用对齐网络(如SEAN)来调整输入图像,然后移除BDL模块。
- 结果对比:
- 用配准和对齐操作替换BDL模块后,Dice分数分别下降了1.34%和1.8%。
- BDL模块的参数非常少(仅0.05M)。
- 效率和复杂度对比:
- 配准过程导致时间消耗增加(每张图像约30秒)。
- 对齐网络显著增加了参数数量(18.34M)。
- 结论:这些结果证明了所提出的BDL模块的优势和有效性,并验证了BDL使所提出的方法无需进行配准和对齐操作(registration and alignment operations free)。
G. 混合网络中 Transformer 参数的比较
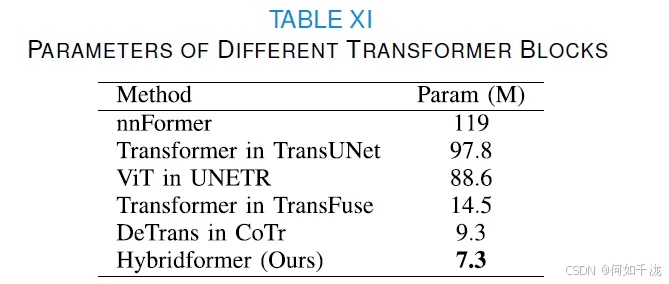
核心内容: 研究人员进行了一项额外的实验,评估了在不同的混合 CNN-Transformer 网络中,Transformer 块的参数数量。
主要发现:
- 设计的 Hybridformer 块拥有最少的参数数量(7.3M),明显少于其他方法中的 Transformer 块参数量。
- 尽管参数较少,但 Hybridformer 块仍然获得了更好的分割性能。
- 结论: 这表明 Hybridformer 块能够在保持较低参数量的同时,维持良好的分割性能。
H. 其他分割任务上的实验
核心内容: 为了探究所提出方法的通用性(适用性),研究人员在另外两个分割任务上进行了评估:BraTS2019 上的脑肿瘤分割和 Pancreas CT 数据集上的胰腺分割。
实验设置:
- BraTS2019 数据集: 包含 335 名患者的四种模态图像(原生和增强 T1、T2、T2 FLAIR),GT 包含三个肿瘤子区域:水肿(ED)、增强肿瘤(ET)和非增强肿瘤(NET)。评估结果展示了全肿瘤(WT)、增强肿瘤(ET)和肿瘤核心(TC)的 Dice 分数。
- Pancreas 数据集: 提供了 281 个 CT 扫描,包含胰腺和癌症的 GT。
- 在这两个数据集的训练集上均进行了五折交叉验证。
主要发现:
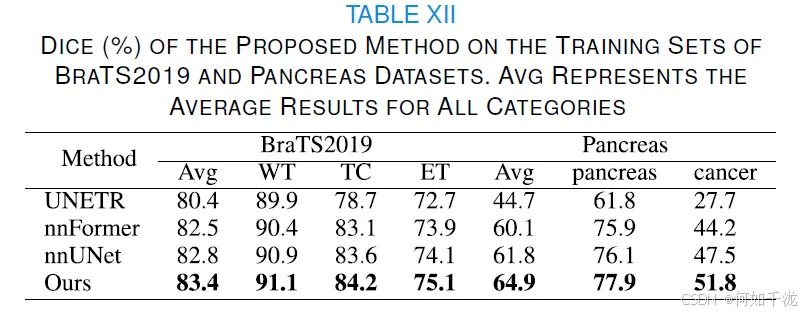
-
定量结果: 该方法在 BraTS2019 和 Pancreas 数据集上分别取得了 83.4% 和 64.9% 的平均 Dice 分数,优于三种代表性的通用 SOTA 方法(UNETR、nnFormer 和 nnUNet)。
-
可视化结果:
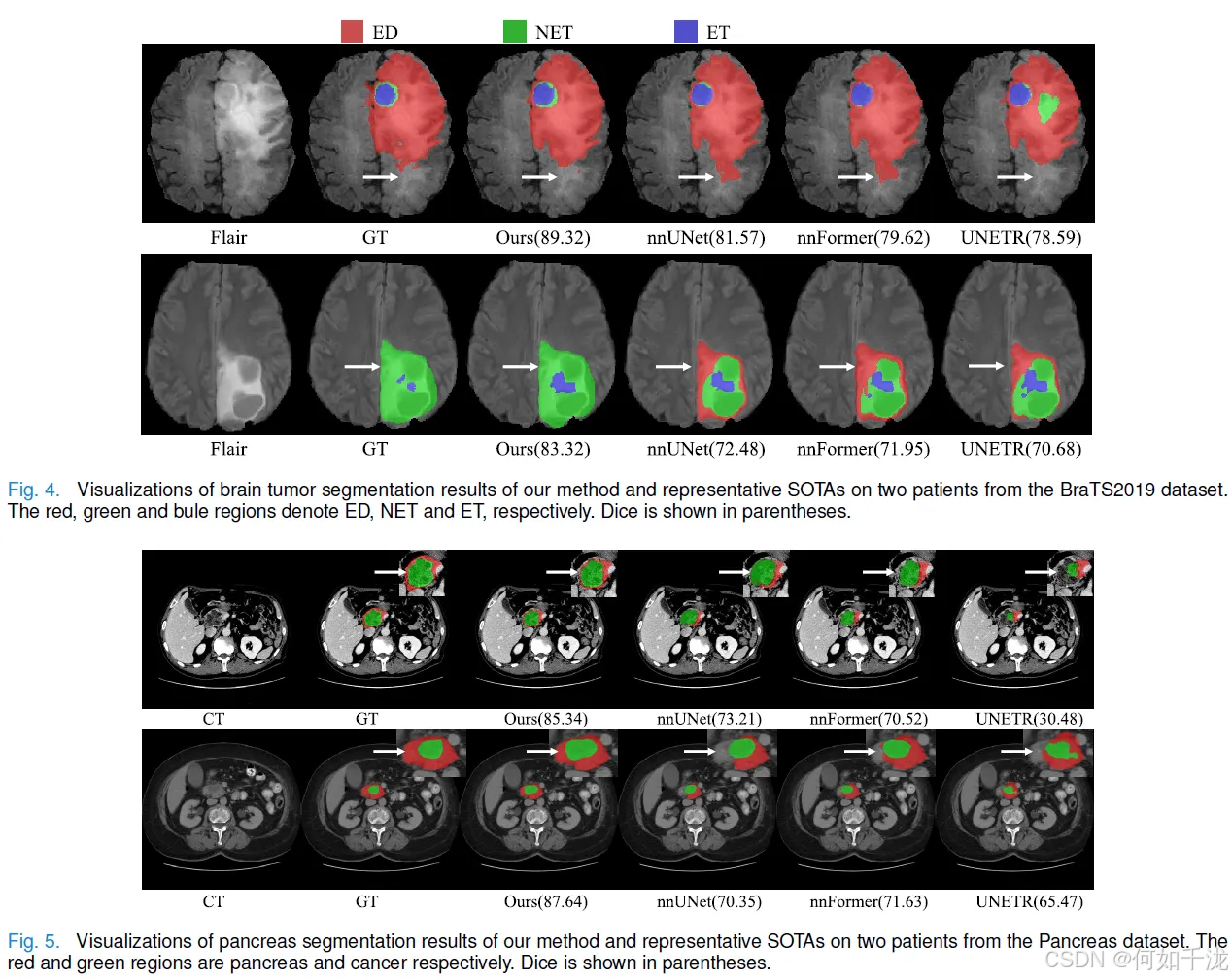
- 在 BraTS2019 上,该方法对于 ED 类别的假阳性分割较少(相对于 nnUNet 和 nnFormer)。
- 在 Pancreas 数据集上,该方法实现了更精确的胰腺分割。
-
结论: 这些实验证明了所提出的方法具有应用于并转化为其他医学图像分割任务的潜力。
I. BDL 在不同任务上的适用性
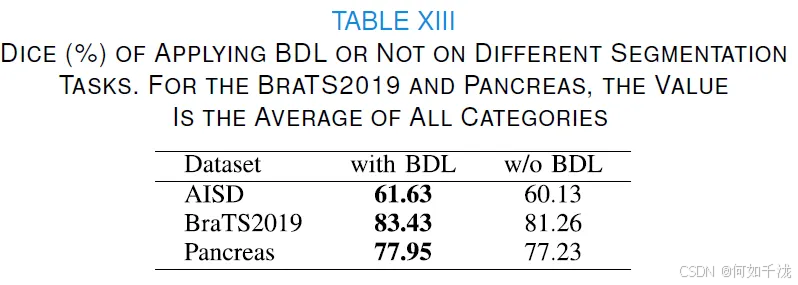
核心内容: 研究人员测试了双边差异学习(BDL)模块在不同结构特性数据集上的效果:AISD 和 BraTS2019(具有对称结构)以及 Pancreas(缺乏对称结构)。
主要发现:
- 对称结构数据集(AISD 和 BraTS2019): 移除 BDL 后,Dice 分数分别下降了 1.5% 和 2.17% 。
- 非对称结构数据集(Pancreas): 移除 BDL 后,Dice 分数下降了 0.72% 。
- 结论: BDL 模块更适合具有对称结构的数据集,尽管它也能适应缺乏对称性的数据集,但效果会减小。
适用性解释:
- BDL 模块采用残差结构:将学习到的双边差异特征与原始输入特征进行元素级相加。
- 当图像具有对称结构时,经过充分训练后,双边差异特征会变得更加显著,从而使得 BDL 的残差输出权重更高,对性能提升贡献更大。
- 当图像缺乏对称结构时,双边差异信息不那么有用,经过训练后,双边差异特征的贡献会被忽略,从而使得 BDL 的残差输出权重较小,对性能的提升作用较小。
J. 应用大规模 SAM 进行 AIS 病灶分割
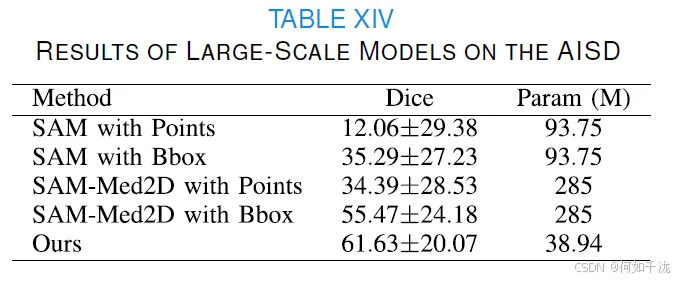
背景介绍:
- 近期,大规模的“分割一切模型”(Segment Anything Model, SAM)和专为医学图像设计的 SAM-Med2D在图像分割任务中取得了令人期待的成果。
- 为了探究这些模型在 AIS 病灶分割中的表现,作者直接在 AISD 数据集的测试集上对它们进行了评估。
评估方法:
- 对于每张 3D CT 扫描,评估时采用了两种提示(prompt)方式:
- 点提示 (Point Prompt): 根据对应的地面真实值(GT),随机选择 5 个点作为包含病灶的 2D 切片的提示。
- 边界框提示 (Bounding Box Prompt, bbox): 使用病灶 GT 的边界框作为提示。
结果对比:
- SAM 模型的 Dice 系数表现:
- 使用点提示:12.06±29.38%
- 使用边界框提示:35.29±27.23%
- SAM-Med2D 模型的 Dice 系数表现:
- 使用点提示:34.39±28.53%
- 使用边界框提示:55.47±24.18%
- 作者提出方法的 Dice 系数表现: 61.63±20.07%
结论:
- 无论是使用点提示还是边界框提示,SAM 和 SAM-Med2D 获得的 Dice 系数都低于作者提出的方法(61.63±20.07%)。
- 这表明作者提出的方法更适合 AIS 病灶分割任务。
- 此外,作者的方法是全自动的,相比需要人工交互(提供提示)的 SAM 和 SAM-Med2D,在实现效率上具有优势。
K. 局限性与未来工作
- 局限性:
- 模型复杂度和参数数量: 作者提出的方法具有两个并行的编码器和 38.94M 的参数。为了实际应用,需要开发一个更轻量级的混合 CNN-Transformer 网络。
- 数据集规模: 目前使用的数据集相对较小。未来应收集更多的 AIS 患者的非增强 CT (NCCT) 扫描数据,以提高模型的鲁棒性。
- 未来工作 :
- 开发一个轻量级的混合 CNN-Transformer 网络,以方便实际应用。
- 收集更多 NCCT 扫描数据,以增强模型的鲁棒性。
7. 结论
- 技术创新: 提出了一个用于 NCCT 上的 AIS 病灶分割的混合 CNN-Transformer 网络。
- 卓越性能: 在两个数据集上,该方法分割准确性高,且显著优于 17 种现有的最先进方法。
- 临床价值: 分割出的病灶体积与真实体积高度吻合,且在外部验证中表现最佳,显示出其在 AIS 诊断和临床应用中的巨大潜力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)