从 ChatGPT 到 Word:如何快速精确删除中英混排中的多余空格
如何让 AI 写的东西“一看就像人写的”🌚
好久不见大家!我 —— 终于又回来啦!
这一年真的过得匆匆忙忙但不游刃有余哈哈哈哈哈!自己的课题一直在库库做:6 月想着 8 月搞定,8 月又觉得 10 月可以,10 月再一看……那就年底吧,结果还是 —— 计划永远赶不上变化哈哈哈,那就争取年后不知道哪月顺利收官吧!
公众号这边也不小心被我按下了暂停键,但其实心里一直记得这里,也记得一直支持我的大家呜呜呜呜呜呜呜呜!真的超级感谢大家一直都在,感动!!!所以,2026 年 —— 我决定:正式恢复更新!
接下来,我会慢慢但很认真地把这里重新经营起来,继续分享一些真正对大家有用、能少踩坑的好内容 —— 不管是保姆级教程、文献精讲、经验分享,还是那些“只有自己被折磨过才会写出来”的经验总结等等,当然,我也会继续坚持咱们一直以来的准则:要知道出品,必属精品!
希望接下来,能和大家一起把这里重新变得热闹起来!
新的一年以及以后的以后,还请大家多多指教啦 👋
从 ChatGPT 到 Word,排版翻车啦!
如果你最近经常:
- 用 ChatGPT / Claude / Gemini 写论文、报告、基金本子
- 把内容直接复制到 Word
- 然后发现:
- 中文和英文之间莫名多出空格
- 数字和中文被硬生生“拆开”
- α、β、≥、Ⅲ 这些符号和中文之间怎么看都别扭
那你大概率已经踩过这个坑啦哈哈哈哈哈哈!
我们先来看一个很典型的小例子,比如你让 ChatGPT 帮你写一段说明文字,它给了你这样一段内容:
在本研究中,我们基于 AI-driven antibody design pipeline 对抗体 framework region 进行系统性优化,同时保持 CDR specificity 不变。结果表明,经过优化后,抗体对 protein A 的 binding affinity 显著提高。
进一步的 structural modeling 结果显示,VH FR3 区域在 stabilizing antigen binding conformation 中起关键作用。部分设计序列在 CDRH3 周围表现出 altered interaction pattern,可能影响 binding dynamics 和 kon / koff 参数。
使用 AlphaFold 3 与 ESMFold 对设计抗体进行结构预测发现,整体 folding confidence(pLDDT ≥ 85)在 framework optimization 前后保持稳定,预测结构间的 RMSD < 1.5 Å,提示未发生显著 structural deviation。
在 functional validation 阶段,humanized antibody 显示出更低的 predicted immunogenicity,同时维持与 parental antibody 相近的 binding kinetics,进一步验证了 AI assisted antibody engineering 在 therapeutic antibody development 中的可行性。
在 ChatGPT 的界面里看起来是这样的:

说实话,看着还挺舒服,对叭!
但真正的“翻车现场”,发生在你粘进 Word 的那一刻
当你把这段话复制到 Word 里之后,画风突然就变了:
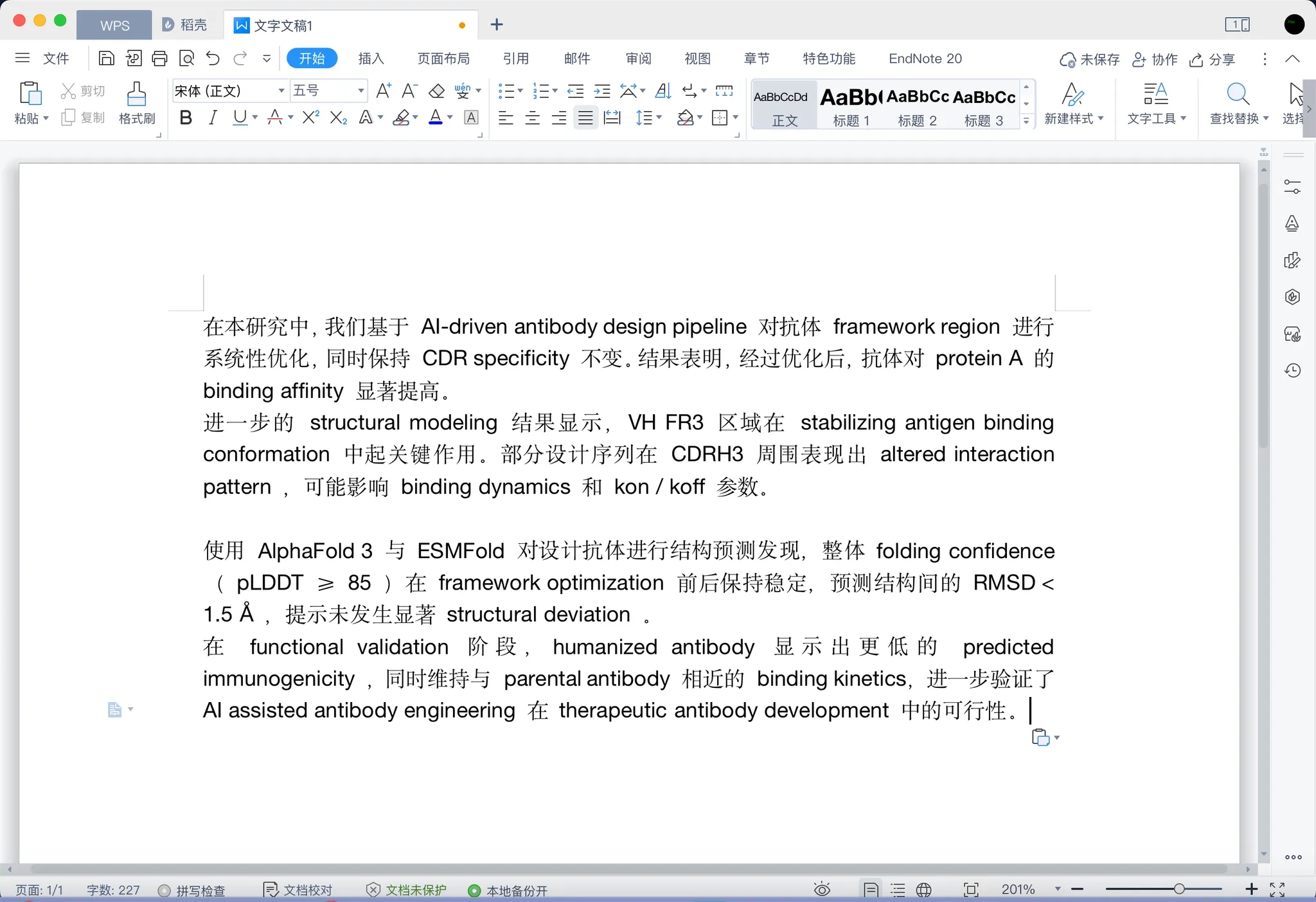
是不是一下子就觉得不对劲啦!
明明内容一字没改,但整段文字:
- 该连的地方没连
- 不该空的地方全是空格
- 中英混排显得既不像中文,也不像英文
专业度直接掉了一截!
更尴尬的是,这种问题往往会被一眼看出来,导师、审稿人或者老板扫一眼就能判断:
“哦,这段是 AI 直接粘过来的。”
那种瞬间心里一沉的感觉,你懂的 🌚
问题的根源,其实不在 AI,而在 Word
需要先说一句:AI 生成的文本本身是“干净的”。
你可能已经无数次遇到过这些情况:
第 3 章(数字和中文被拆开)p ≤ 0.05(符号前后多一个空格)TNF α 表达升高Ⅲ 期 结果显示
这些空格看起来像是“普通空格”,但实际上,很多并不是我们键盘主动敲出来的那种。
常见的包括:
- 不可断行空格(NBSP)
- 从网页或 PDF 里带进来的全角空格
- AI 输出中为了排版保留的格式间隙
最重要的是,**Word 本身就会在中英文字符之间自动留出视觉间距,根本不需要我们手动加空格啦!**所以这个时候,这些空格就会显得很多余,需要删掉它们!
然后,所有人都会做同一件事
这个时候你会怎么做呢?
没错,开始用 Backspace 一个一个删!
少的话还勉强能忍,多起来就是真正的折磨 🌚:
- 删不完
- 容易漏
- 越删越怀疑人生
更现实的是,你永远无法确认:**是不是每一处该处理的空格,都已经处理干净了。**在论文、标书或正式报告里,这种“不确定性”,本身就是一种隐患。
这种“一个一个删”的方式,真的已经落伍啦!
很多人可能都知道,在写代码时可以用 正则表达式 来处理复杂的字符串。其实,Word 里也有类似的东西 —— “通配符替换”!
只要方法对,用几条规则,它可以直接帮我们:
- 一次性处理所有中英混排空格
- 不影响正常的英文句内空格
- 不用逐行检查,也不需要反复返工
换句话说,这件事完全没必要手动完成。是的,这些看起来让人头疼的空格问题,真的可以直接交给工具来处理啦!
接下来,我们就一步一步用 Word 自带的功能,把它彻底解决!
一套“真正可用”的解决方案(亲测有效)
-
打开 Word 的
替换(不同电脑的快捷方式各不相同,这里我就不展示啦,相信聪明的你一定可以的!)
-
点击
高级搜索,勾选使用通配符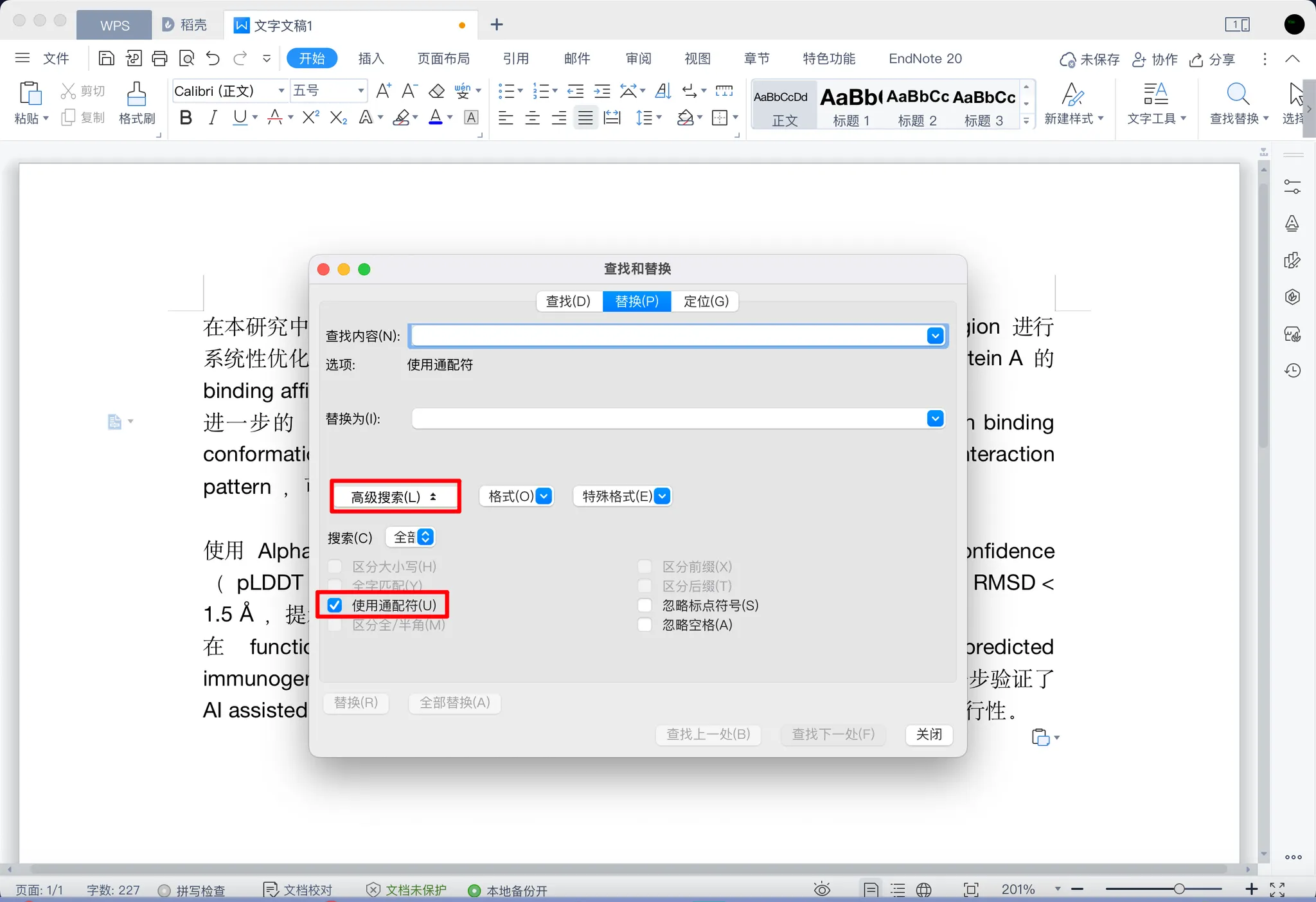
-
一键删除「中文 + 英文 / 数字 / 符号」之间的空格
查找内容为:
([! -~])[ ]@([ -~])替换为:
\1\2就像下面这样:

这条规则可以同时处理:
- 中文 + 英文
- 中文 + 数字
- 中文 + ≥ ≤ ±
- 中文 + α β γ
- 中文 + 罗马数字 ⅠⅡⅢ
因为:
[! -~]= 所有非 ASCII 字符,包括:中文、希腊字母(α β γ Δ κ)、数学符号(≥ ≤ ± ≠ ∑ √)、罗马数字(ⅠⅡⅢⅣ)、全角符号(%,。 ())、中文标点等。[ -~]= 所有 ASCII 字符,包括:英文(a–z A–Z)、数字(0–9)、半角符号(+ - = > < / %)等。@:前面的内容,重复 1 次或多次。这里表示 1 个或多个连续的空格,意思是不管有 1 个空格,还是 10 个空格,都会一次全处理掉。\1\2:\1表示把匹配到的第 1 部分,\2表示把匹配到的第 2 部分,\1\2则表示把“第 1 部分”和“第 2 部分”贴在一起,中间不要空格。处理前后对比:
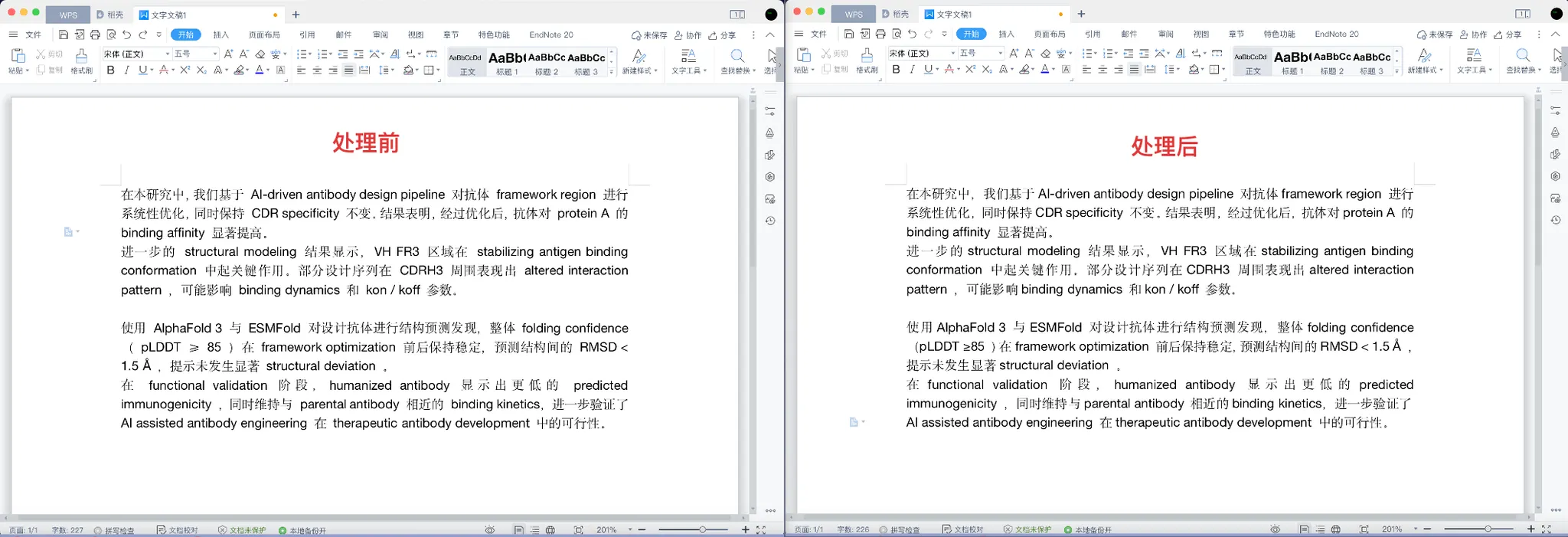
是不是感觉有哪里变啦!没错!只要是
中文 XXX的内容,都已经变成了中文XXX。还没完还没完,我们还需要把反方向的XXX 中文处理为中文XXX,我们继续! -
处理反方向(英文 / 数字 / 符号 + 中文)
查找内容:
([ -~])[ ]@([! -~])替换为:
\1\2如下所示:
我们看看效果怎么样:

铛铛铛铛!可以看到
XXX 中文也已经变为中文XXX啦!
我们看一下初始状态和最终状态对比: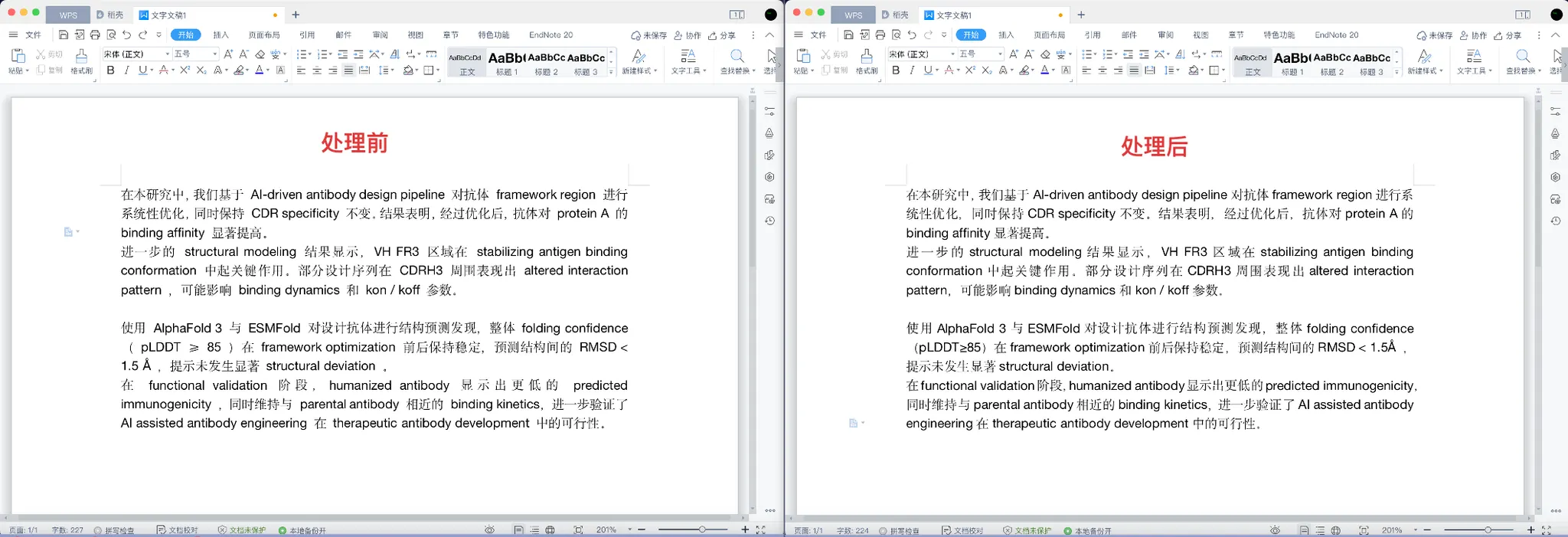
最终处理版本如下:
在本研究中,我们基于AI-driven antibody design pipeline对抗体framework region进行系统性优化,同时保持CDR specificity不变。结果表明,经过优化后,抗体对protein A的binding affinity显著提高。
进一步的structural modeling结果显示,VH FR3区域在stabilizing antigen binding conformation中起关键作用。部分设计序列在CDRH3周围表现出altered interaction pattern,可能影响binding dynamics和kon / koff参数。使用AlphaFold 3与ESMFold对设计抗体进行结构预测发现,整体folding confidence(pLDDT≥85)在framework optimization前后保持稳定,预测结构间的RMSD < 1.5Å ,提示未发生显著structural deviation。
在functional validation阶段,humanized antibody显示出更低的predicted immunogenicity,同时维持与parental antibody相近的binding kinetics,进一步验证了AI assisted antibody engineering在therapeutic antibody development中的可行性。
可以看到,所有碍事的空格都已经被删除啦!而英文语句内部的空格完全不受影响!NICE!
那么问题来啦:是不是所有「中文 + 符号 / 数字」之间的空格,都应该被无条件删掉呢?
其实也不是。
在实际写作中,有些英文技术指标或专业符号,我们反而会刻意保留空格,让表达更清晰、更美观。例如:
pLDDT ≥ 85RMSD < 1.5 Åp < 0.05
如果被处理成:
pLDDT≥85RMSD<1.5Å
虽然语义没错,但在论文、报告或基金本子里,整体观感会明显下降。
那我们该怎么办呢?请继续往下看!
不一定要“全删”,你也可以选择性处理
我们简单展示几个常见的案例修改效果:
| 原文 | 处理后 |
|---|---|
| 第 3 章 | 第3章 |
| p ≤ 0.05 | p≤0.05 |
| TNF α 表达 | TNFα表达 |
| Ⅲ 期 研究 | Ⅲ期研究 |
需要说明的是,前面介绍的做法并不是只能“一刀切”啦!
在真实使用场景中,很多小伙伴们其实只需要处理某一类空格问题,比如:
- 只删除 中文与英文之间 的空格
- 只删除 中文与数字之间 的空格
- 只清理 中文之间不小心出现的空格(最容易被发现是 AI 生成粘贴来的 🌚)
- 保留所有正常英文句子里的空格不动
也就是说,我们完全可以按需要进行精准处理!我们一起来看看具体该怎么操作吧!
删掉“中文与英文之间”的空格
这是 AI 生成内容里最常见、也最影响观感的一类空格问题,例如:
基于 AI driven 方法使用 deep learning 模型CDR region 表现稳定
我们想要的效果是:
基于AI driven方法使用deep learning模型CDR region表现稳定
但同时要 保留英文内部正常的空格(如 deep learning 中间不能动)。
这个时候,我们可以打开 Word 的「查找和替换」,只需要:
-
查找内容(打开“使用通配符”):
([一-龥]) ([A-Za-z])[一-龥]:表示任意一个中文字符。一到龥,覆盖的是常用汉字在 Unicode 里的连续区间。A-Z:所有大写字母a-z:所有小写字母[A-Za-z]:匹配任意一个英文字符(不区分大小写) -
替换为:
\1\2
点一次「全部替换」,即可搞定!
这条规则的含义是:只删除“中文字符 + 英文字母”中间的那个空格,不会影响纯英文句子中的空格。
接下来,我们还需要再处理一下反方向,查找内容(打开“使用通配符”)([A-Za-z]) ([一-龥])替换为\1\2,就万事大吉啦!
删掉“中文与中文之间”的空格
有时候,AI 生成或复制过程中,会在中文之间莫名插入空格(其实也不是算莫名其妙啦,AI 有时候其实喜欢把重点内容加粗或者两边插入空格用于强调,却没想到给大家造成了这种困扰哈哈哈哈哈哈),比如:在本研究中,我们强调 稳定性与可解释性 同等重要。模型并非一味追求更高的性能,而是需要在 engineering robustness 与 biological relevance 之间取得平衡。
这种情况在人眼看来是非常别扭的,也最容易被当成排版问题。我们希望删除中文与中文之间的空格,但是中文与英文之间、英文语句内部的空格依旧保留,可以这样处理:
查找内容(打开“使用通配符”):
([一-龥]) ([一-龥])
替换为:
\1\2
执行「全部替换」后:在本研究中,我们强调稳定性与可解释性同等重要。模型并非一味追求更高的性能,而是需要在 engineering robustness 与 biological relevance 之间取得平衡。
删掉“中文与数字之间”的空格
在 Word 的「查找和替换」里,只需要:
-
查找内容(打开“使用通配符”):
([一-龥]) ([0-9])[0-9]:表示任意一个数字 -
替换为:
\1\2
再处理一下反方向,查找内容(打开“使用通配符”)([0-9]) ([一-龥])替换为\1\2,搞定!
效果示例:第 3 章 → 第3章,实验 1 结果 → 实验1结果
这套方法,尤其适合正在用 AI 的你
AI 生成的内容,往往都有一些共通特点:
- 中英混排频繁
- 数学符号、希腊字母、特殊字符较多(主要看大家的领域啦)
- 内容结构长,人工逐条校对的成本极高
在这种情况下,用规则替换,其实是在做一件很重要的事情 —— **把 AI 生成的文本,转换成一个真正“Word 友好”的版本。**这样一来,我们就不需要花费大量时间去反复检查格式细节,也不用担心因为排版问题影响专业度啦!
Word「通配符替换」常用符号速查表
⚠️ 前提:切记,这些要在 Word 的 “查找与替换” → 勾选「使用通配符」 时才会生效哟!
| 通配符 | 含义(人话版) | 常见用途 | 示例说明 |
|---|---|---|---|
[] |
字符集合 | 指定“这几类字符中的任意一个” | [A-Za-z] = 任一英文字符 |
[一-龥] |
任一中文汉字 | 精准定位中文 | 匹配“中”“研”“究”等 |
[A-Za-z] |
任一英文字母 | 中英分界 | AI / protein / design |
[0-9] |
任一数字 | 数值处理 | 0–9 |
[! -~] |
任一可打印英文字符(不含中文) | 中英文/符号边界 | 英文、数字、≥、α 等 |
[ -~] |
任一可打印 ASCII 字符(含空格) | 英文+符号匹配 | 比 ! -~ 范围更大 |
[ ] |
半角空格 | 精准匹配空格 | 非制表符、非换行 |
@ |
前一项 重复 1 次或多次 | 压缩多个空格 | [ ]@ = 1 个或多个空格 |
* |
前一项 重复 0 次或多次 | 可选内容 | 很少用,容易过度匹配 |
! |
前一项 出现 0 或 1 次 | 可有可无的字符 | 类似正则 ? |
() |
分组 / 捕获 | 替换时引用 | \1、\2 |
\1 \2 |
引用第 1 / 第 2 个分组 | 重组文本结构 | 保留左右字符 |
^p |
段落标记 | 处理换行 | 段落分隔 |
^t |
制表符 | 表格/对齐问题 | tab |
^13 |
换行符(软回车) | PDF/网页复制 | 常见于粘贴内容 |
^s |
不断行空格(NBSP) | AI / 网页复制 | 看不见但删不掉 |
如果你身边还有:
- 被论文格式折磨到崩溃的同学
- 用 AI 写基金、报告或评估材料的同事
- 每次把内容粘进 Word 都要重新排版的人
把这篇文章转给他,大概率会收获一句:
“你也太懂了吧!请受我一拜!”
文末碎碎念
那今天的分享就到这里啦!我们下期再见哟!
最后顺便给自己推荐一下嘿嘿嘿!
如果我的分享对你有用的话,欢迎关注点赞在看转发分享阿巴阿巴阿巴阿巴巴巴!这可是我的第一原动力!
蟹蟹你们的喜欢和支持!!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)