AI助你掌控信息流:搭建个人专属AutoRSS,告别信息焦虑!
基于AI的自动化信息整合系统 本文介绍了一个利用AI技术搭建的个人信息整合系统,旨在高效收集和整理生物医学领域的前沿资讯。系统采用RSSHub+WeRSS进行信息源抓取,通过freshRSS实现信息整合,并利用Streamlit框架和第三方LLM API构建内容中控台。作者分享了WeRSS和freshRSS的配置技巧,包括docker部署、公众号订阅方法以及API交互实现。该系统可自动筛选优质内容
前言
前年年初,我曾计划过做生物医学相关的信息周刊,受限于时间和精力关系,很多材料仅仅是完成了收集没有继续整合。工作相关的原因,我每周都需要花费很多的时间来跟进最新的研究和新闻,尽管我们可以利用RSS、公众号或者邮件订阅等方式来收集和关注领域前沿信息,但是客户端软件内部的推荐算法经常会推送出一些材料吸引走我们的注意力。

在gpt-4刚推出的时候,已经有人开始尝试用AI做新闻材料的总结,但是那会儿的AI价格和指令遵循程度不高,在做自动化的时候需要花费大量精力做工具维护。而对于inoreader、folo或者suphub等自带gpt解读的信息整合流,其较高的价格和不太稳定的服务让我始终无法决定订阅。随着Gemini-3-flash以及Deepseek-V3.2等模型推出后,大模型的应用性价比来到了一个很好的平衡点,这提醒我是时候搭建一个属于个人的信息整合中心了。
💡 什么是RSS?你的专属信息“快递员”
简单来说,RSS(Really Simple Syndication,简易信息聚合)就像是你订阅的专属信息“快递员”。当你订阅了一个网站的 RSS 源后,每次网站发布新内容,这个“快递员”就会自动把最新、最纯净的内容摘要(通常包含标题、链接和部分正文)投递到你的聚合阅读器中。
它的优势在于:
- 主动获取: 不再被动等待推荐,你可以主动选择你真正想看的信息源。
- 信息纯净: 剔除了网站上的广告、弹窗和无关内容,只保留核心信息。
- 高效聚合: 将多个网站的更新集中在一个地方阅读,大大节省时间。
- 掌控权回归: 彻底摆脱平台算法的“信息茧房”,让阅读回归你的掌控。
工作流架构
我在搭建这个信息整合中心的时候,核心目标主要是2个,一是定期整理值得阅读的材料,二是提供一个“科技爱好者周刊”风格的周刊总览;这个核心灵感来自我长期订阅的一个AI推送网站:https://www.bestblogs.dev/(AI和产品相关的技术阅读博客)
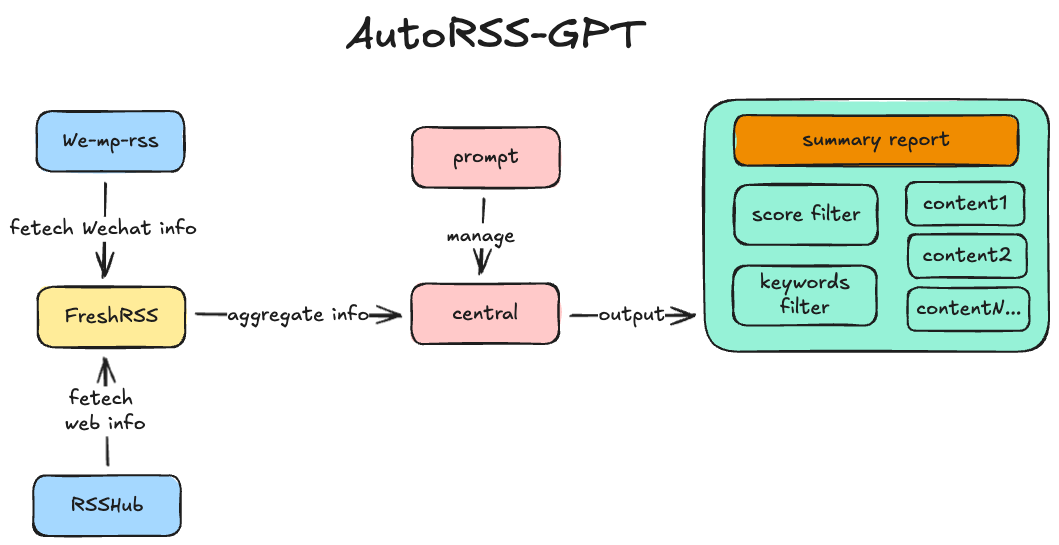
另一方面,我常用的信息源主要是两种,一是支持RSS的各大web网站或者个人博客,二是微信公众号中高质量订阅号的内容推送。(尽管我也会通过邮件订阅一些网站的信息推送,例如huggingface、Medium或者Kaggle等,但这些网站通常推送的内容信息简短实效性强,不需要过于整合处理)
基于这些需求,我大致确定了整个技术栈结构:
信息源抓取:RSSHub+WeRSS
信息源整合:freshRSS
内容整合和中控台:freshRSS-api+streamlit+第三方LLM API
实际上,开源社区中实际上已经有类似的项目:
https://github.com/yinan-c/RSSbrew
https://github.com/yinan-c/RSS-GPT
但是由于其在支持RSS导入功能上不够好用,特别是对于我这种已经积累了一部分RSS链接的用户来说,手动一个一个的添加不太方便。
核心工具安装实践
WeRSS和freshRSS解决了99%以上的信息获取难题,我们只需要根据官方教程完成安装和配置即可(建议使用docker,后续建议均基于Macos系统下的docker配置)
WeRSS配置tips
WeRSS工具的安装和配置参考文档:https://github.com/rachelos/we-mp-rss/blob/main/README.zh-CN.md
快速安装仅需一条命令:
docker run -d --name we-mp-rss -p 8001:8001 -v ./data:/app/data docker.1ms.run/rachelos/we-mp-rss:latest
启动后访问:http://localhost:8001/ 便可进入到WeRSS的处理中控
默认账户和密码是:admin/admin@123
在主页左上角可通过点击“+订阅”->“添加公众号”的方式来增加需要获取信息的公众号,添加完成后,点击主页面的“订阅”来生成RSS链接,用于导入到FreshRSS中统一管理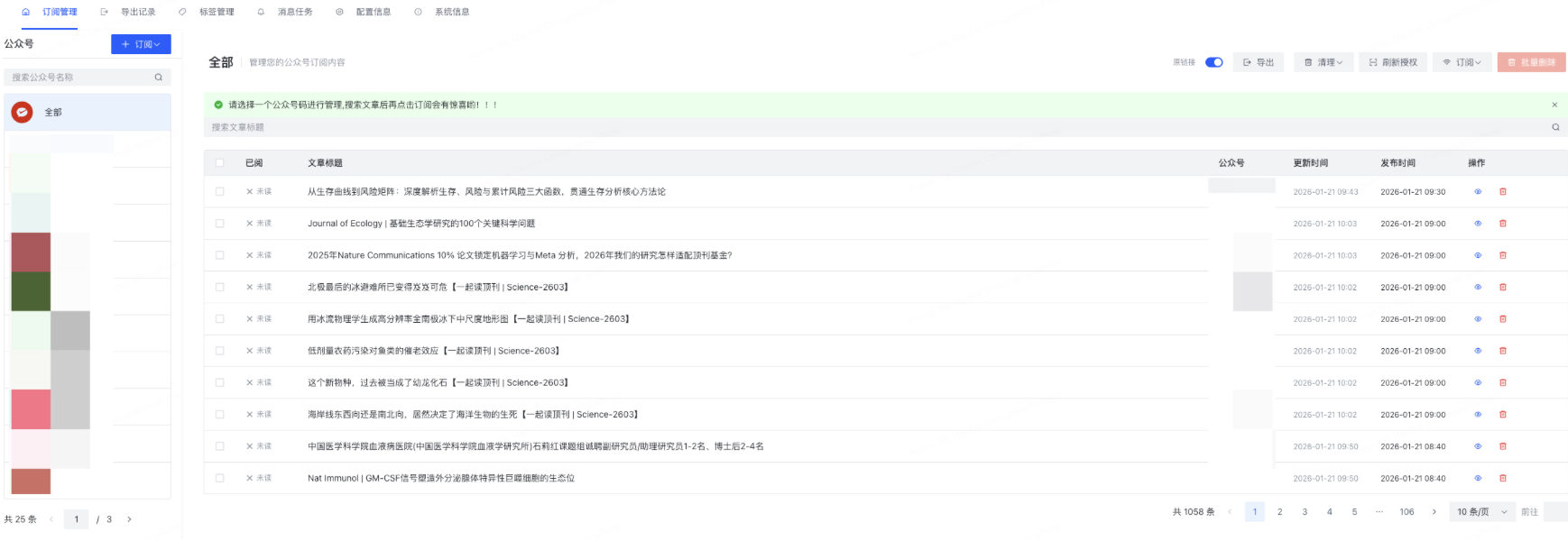
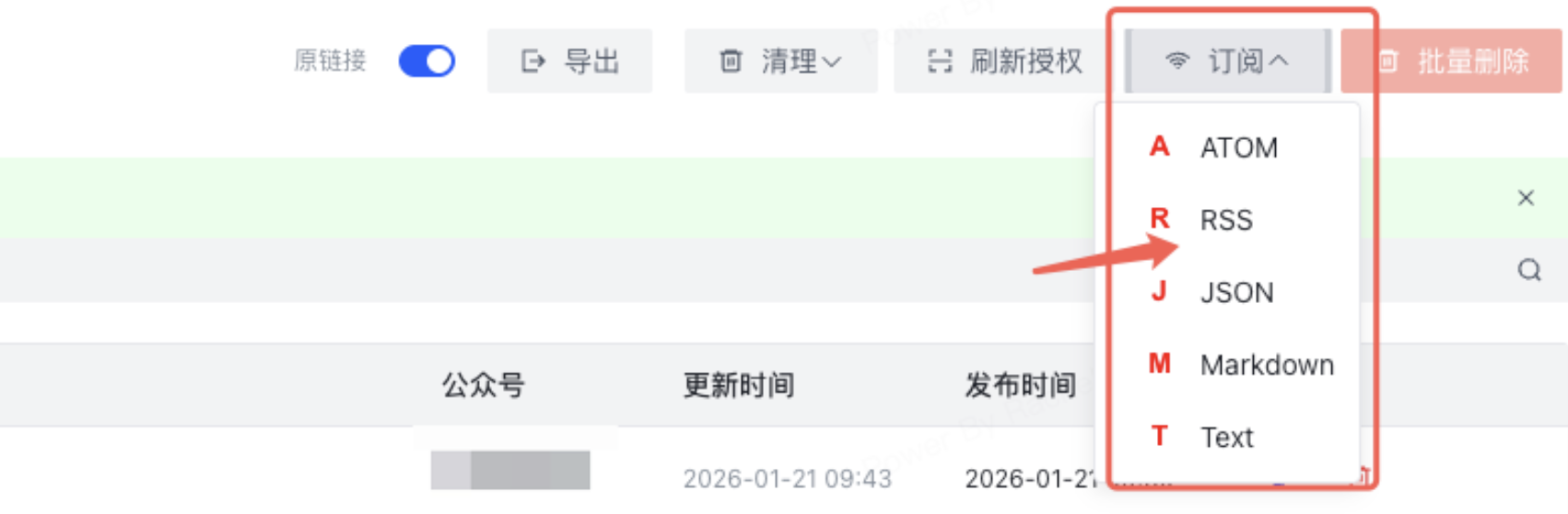
!!需要注意!!:如果WeRSS和freshRSS都采用docker构建,两者的网络环境实际上是独立的,使用WeRSS生成的链接需要将前缀的localhost:8001更改为
host.docker.internal,也就是http://host.docker.internal:8001/feed/all.rss,否则freshRSS将无法正常获取WeRSS抓取的信息!
freshRSS配置tips
freshRSS的安装和部署主要参考文档:https://github.com/FreshRSS/FreshRSS/tree/edge/Docker
需要注意的是,如果国内用户使用时遇到网络问题,建议使用https://1ms.run/服务来加速,例如
docker run -d --restart unless-stopped --log-opt max-size=10m \
-p 8080:80 \
-e TZ=Europe/Paris \
-e 'CRON_MIN=1,31' \
-v freshrss_data:/var/www/FreshRSS/data \
-v freshrss_extensions:/var/www/FreshRSS/extensions \
--name freshrss \
freshrss/freshrss # 将这里的image名更换为docker.1ms.run/freshrss/freshrss
完成部署之后,我们可以通过访问网址:http://localhost:8080/i/(这里的8080端口以实际传递给docker的-p参数为准)或者docker desktop来观察服务是否运行
freshRSS可通过“订阅管理”->“添加订阅源或分类”来实现RSS链接的导入
建议在浏览器中安装插件:RSSHub Radar快速分析当前网站是否支持RSS并生成相应RSS链接
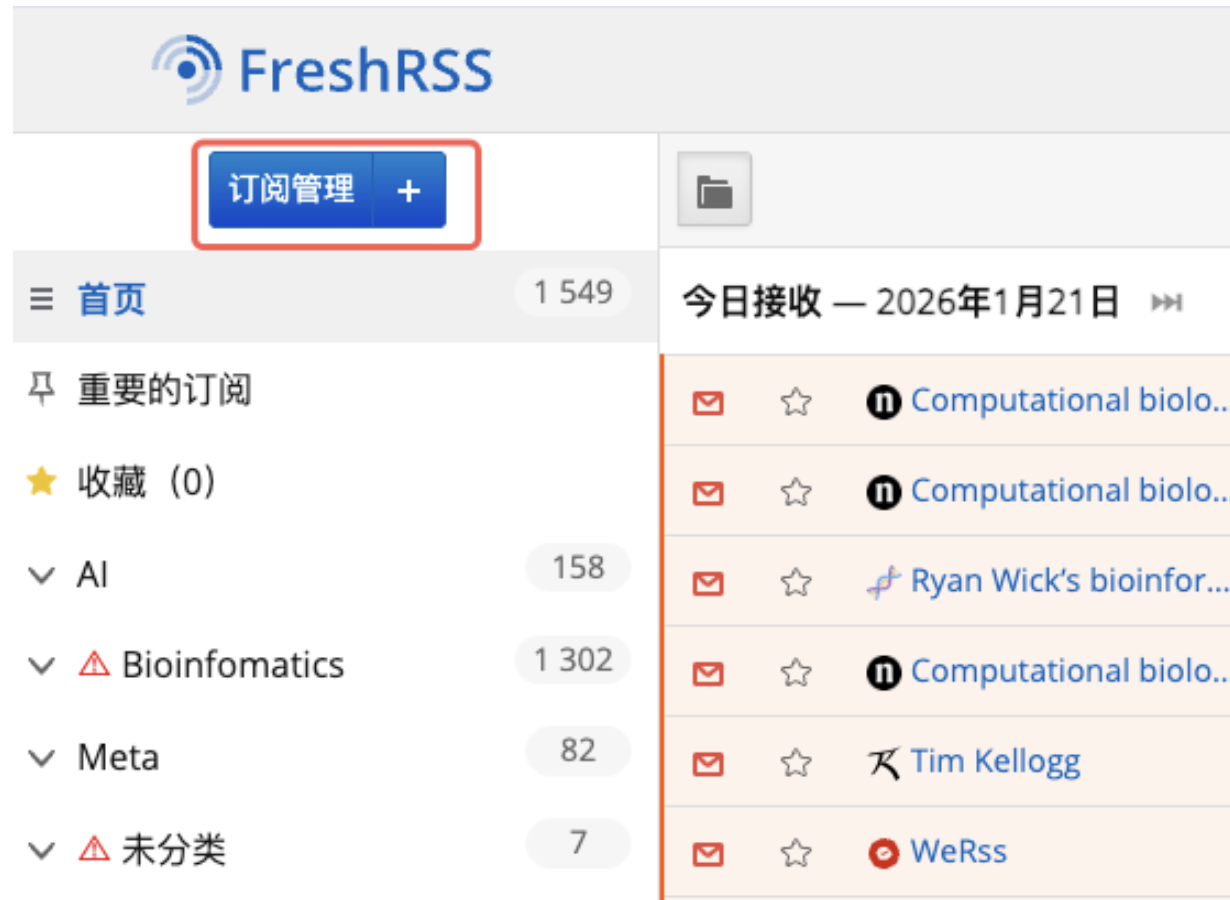
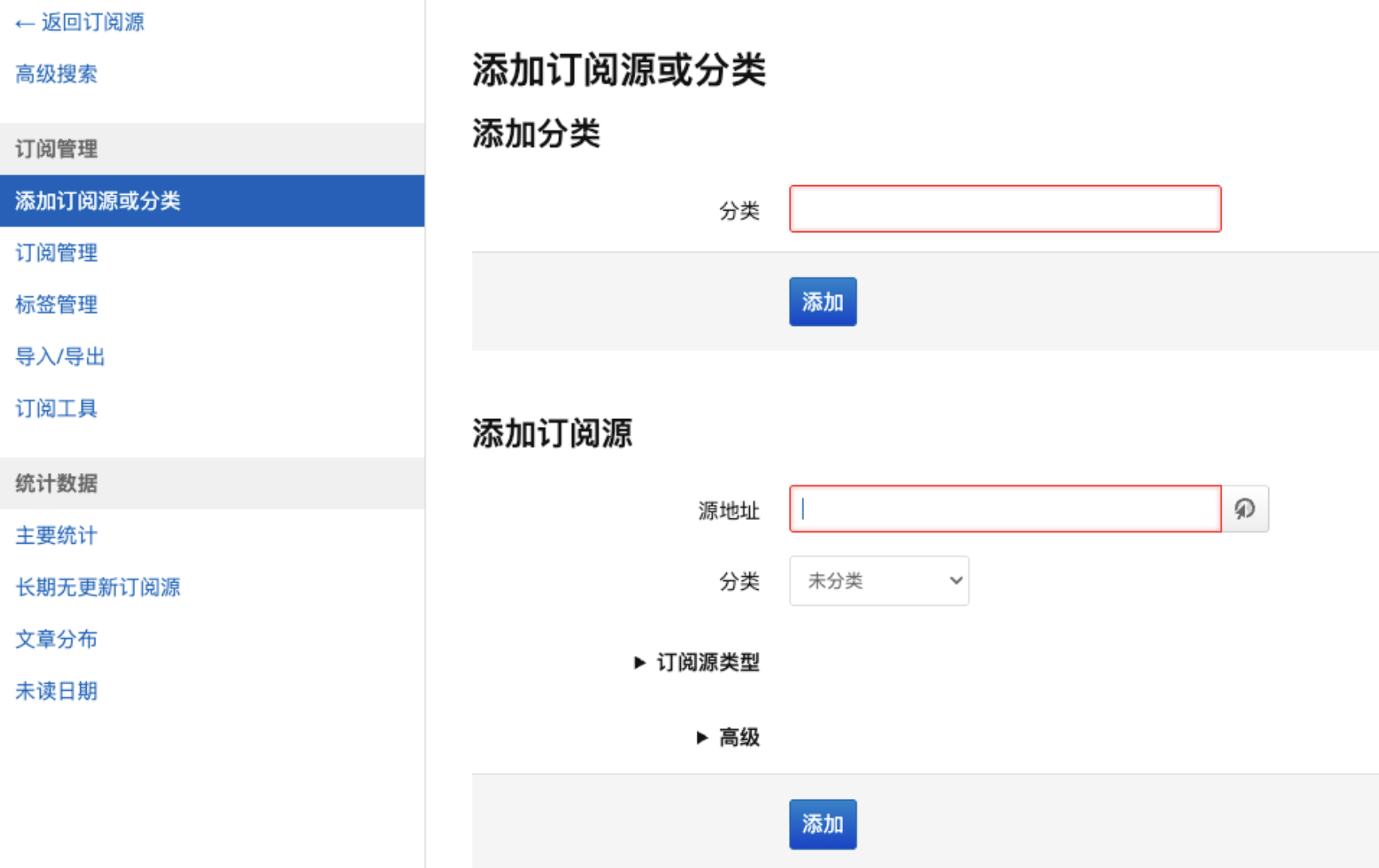
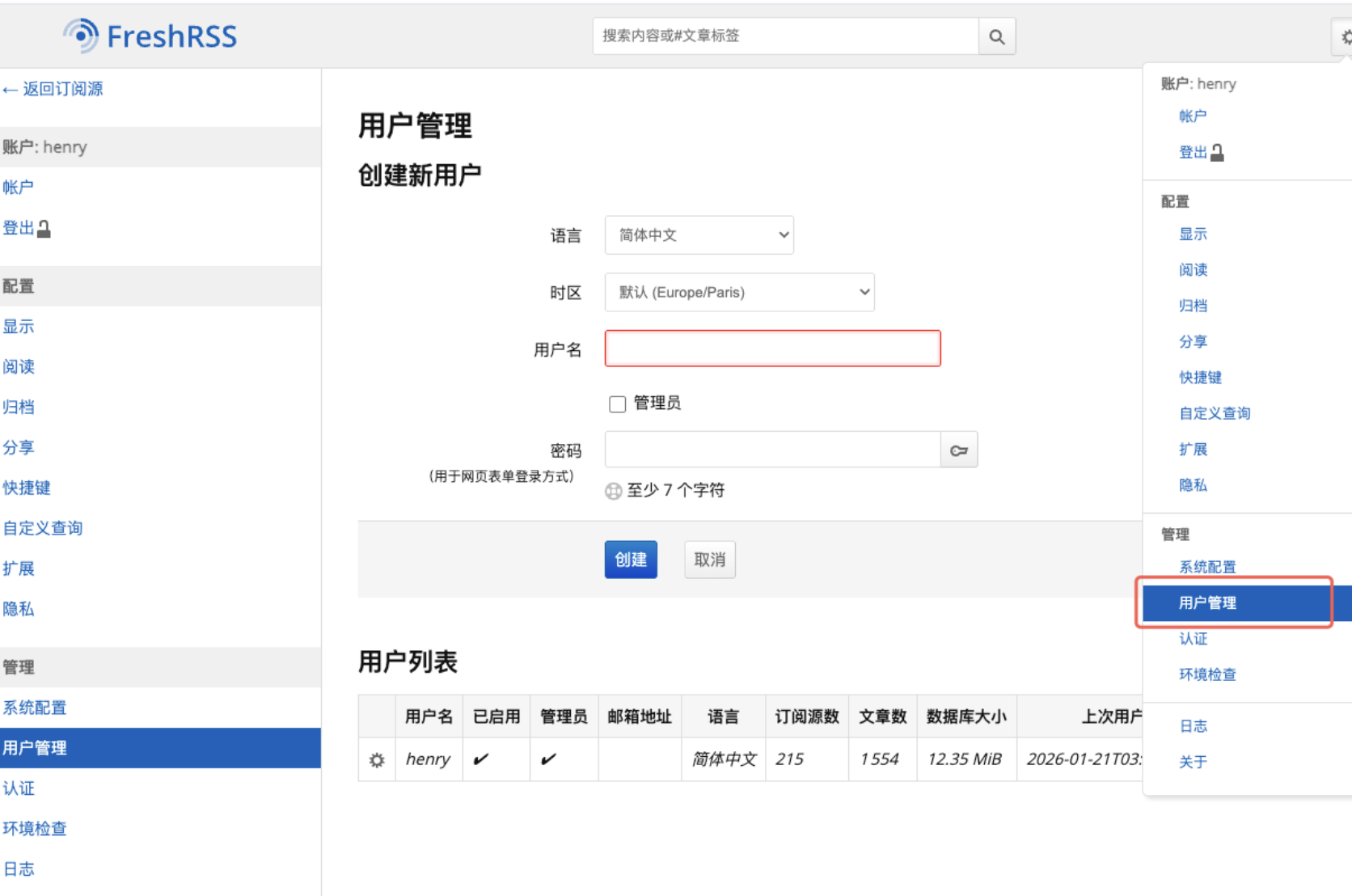
为了让我们的中台能够与freshRSS进行交互,我们需要进入用户管理进行设置(初次进入可能需要设置用户账户和密码,建议保存好)
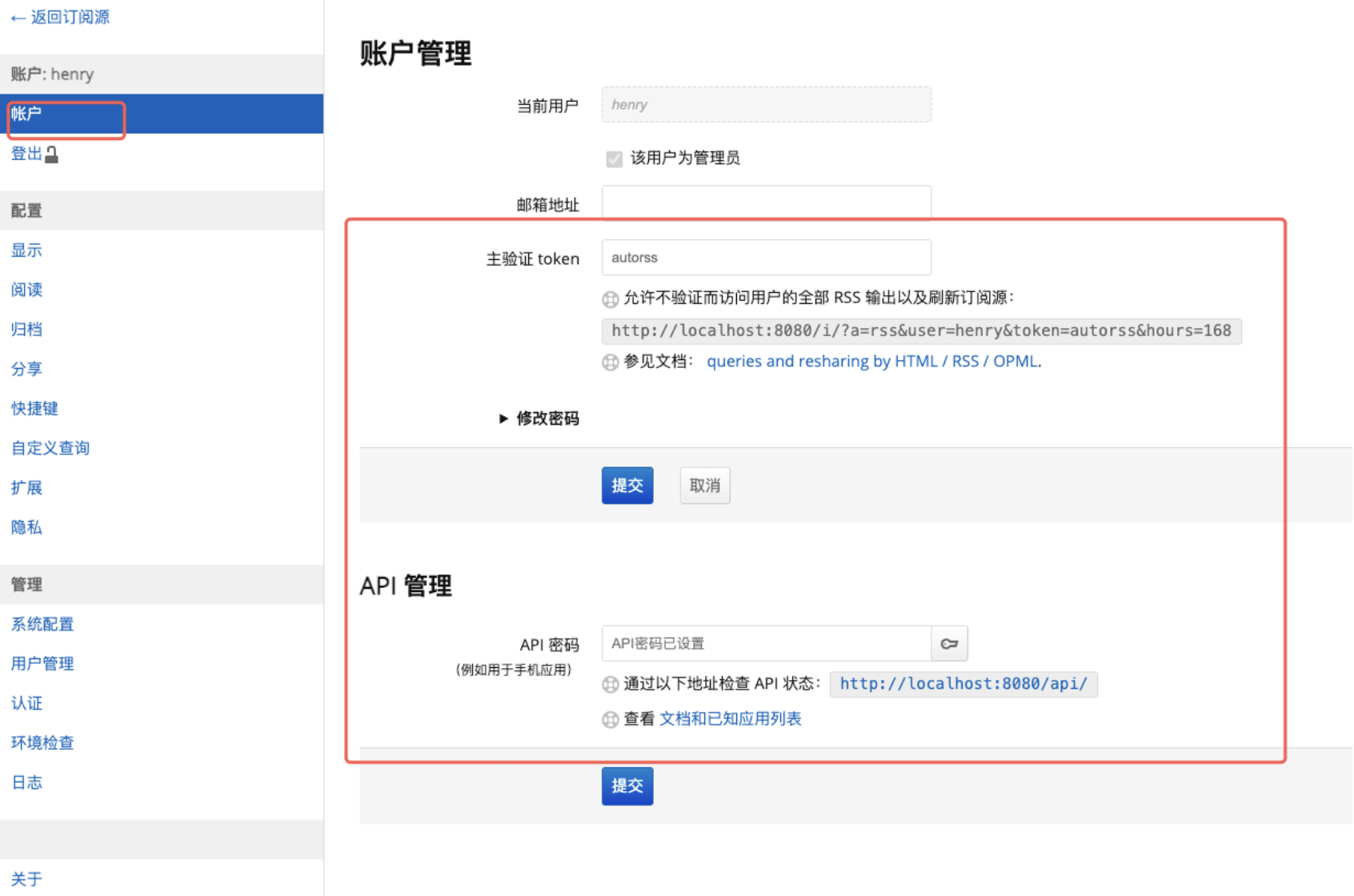
然后在账户中,配置账户主验证token和API密码(这里的api密码很重要,用于数据中台与freshRSS交互使用)
完成上述操作后,便可实现在python中访问
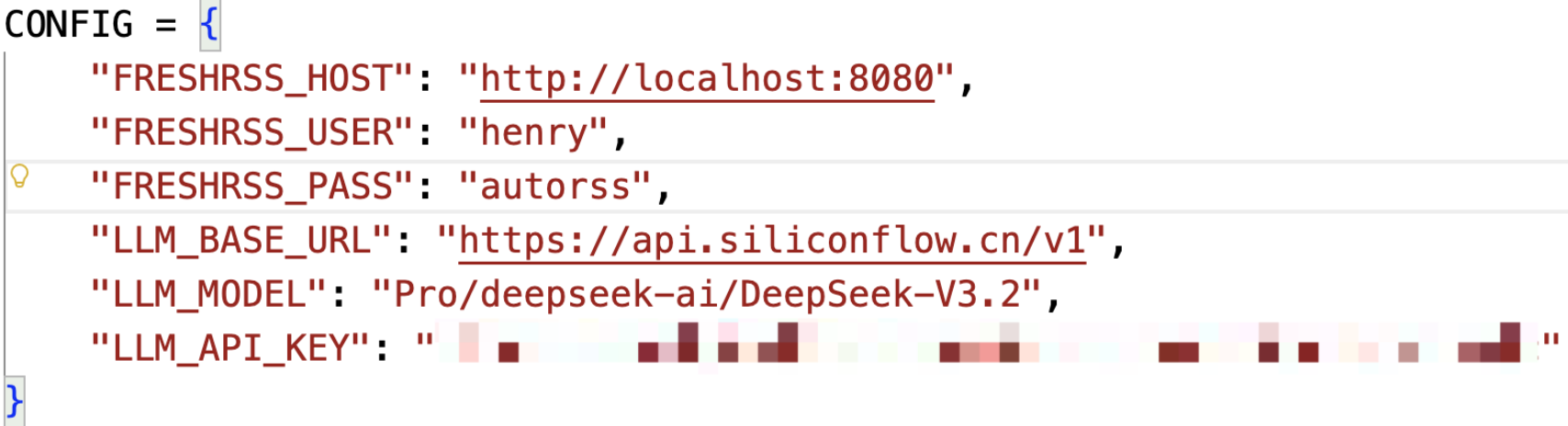
例如使用fresh-api来实现交互:
def fetch_rss_articles(days=7, max_count=100):
"""从 FreshRSS 获取源数据"""
print("📡 连接 FreshRSS...")
client = FreshRSSAPI(
host=CONFIG["FRESHRSS_HOST"],
username=CONFIG["FRESHRSS_USER"],
password=CONFIG["FRESHRSS_PASS"]
)
entries = client.get_unreads()
candidates = []
now_utc = datetime.now(timezone.utc)
for entry in entries:
timestamp = getattr(entry, 'created_on_time', 0)
if not timestamp: continue
pub_date = datetime.fromtimestamp(timestamp, tz=timezone.utc)
if (now_utc - pub_date).days > days:
continue
raw_html = getattr(entry, 'html', '') or ''
clean_text = clean_html(raw_html)
if len(clean_text) < 50: continue
candidates.append({
"title": entry.title,
"link": getattr(entry, 'url', getattr(entry, 'link', '#')),
"pub_date": pub_date.strftime('%Y-%m-%d %H:%M'),
"source": getattr(entry, 'feed', {}).get('title', 'Unknown'),
"content_text": clean_text
})
candidates.sort(key=lambda x: x['pub_date'], reverse=True)
return candidates[:max_count]
工作流中控
为了节约开发时间,我使用的streamlit框架来快速完成web应用搭建;整个应用设计非常简单,包含核心分析、历史报告以及提示词管理;
以下是个人开发的中控使用演示:
autorss
其中AI处理的核心工作流主要包含3个步骤:
1.内容过滤;2.文章深度分析和打分;3.全局总结;
提示词管理则能让我在不同领域之间快速切换和分析

项目代码已提交到:https://github.com/mixiaoluo88/AutoRSS.git
如果你在搭建过程中遇到任何问题,随时与联系作者交流。
总结
我们处在信息爆炸的时代,无处不在的信息和推荐算法都会吸引走我们有限的专注力。如何让信息成为我们行动路上的助力而不是障碍,这个问题的答案可能正是帮助我们在数字生活夺回自我行动意识掌控权的方法。
在本期之后,我将定期分享基于当前工作流审核过滤的信息,采用AI工作流和人工审核的方式来推送,感兴趣的小伙伴欢迎订阅。
相关阅读
https://osnsyc.top/posts/wechat-db-to-rss/
https://www.bestblogs.dev/
术语表
- Docker: (一种轻量级容器化技术,能让应用及其运行环境在任何地方快速部署和运行)
- FreshRSS: (一款免费开源的自托管 RSS 聚合阅读器,可以帮助你收集和阅读来自不同网站的 RSS 订阅内容)
- Streamlit: (一个用于快速创建数据应用的 Python 框架,能将数据脚本转换为可交互的 Web 应用)
- LLM (Large Language Model): (大型语言模型,如 GPT、Gemini 等,具备强大的文本理解、生成和推理能力)
- RSSHub: (一个开源项目,可以将几乎任何信息源转换为 RSS 订阅,极大扩展了 RSS 的应用范围)
- WeRSS: (一个用于抓取微信公众号内容的工具,将其转化为 RSS 源)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)