用了这么久大模型,看着他们一天天进化,变得更聪明,更懂我。跟大模型的聊天记录也越来越多,随便打开一个大模型都是翻不到头的历史对话。想到还有无数个我这样跟大模型聊天的人,不禁感慨又好奇:大模型,是怎么记住全世界这么多人这么多对话的呢?
对接大模型的时候,可以使用OpenAi的标准接口。对于聊天来说,只有一个接口,并且这个接口很简单:发送一个Post请求,带上token,带上参数。
然而Post是一次性的:发送一次请求,接收一次返回。交互双方谁也不知道下次请求什么时候会来,下次请求是否还是同一个对象发来。
如果说,我们跟大模型的对话是开了一个只有双方的聊天室,那难道大模型一直在等我们的输入吗?如果我们不输入它会一直等下去吗?Post这种一次性的请求,又是怎么样大模型知道这新来的请求就是我们上次聊天的后续输入呢?
或者说,OpenAi这个异常简单的接口,是怎么让大模型记住我们之前交流了什么的呢?
实际上,大模型本身不保存交流记录,也不会开个二人聊天室一直等我们。也就是所谓的:大模型没有记忆。
之所以大模型跟我们交流时看上去记得跟我们聊过的内容,是因为我们跟它对话时,每次我们都会把历史对话带给它,它都把历史对话复习一遍,然后基于本次的认知回答我们最新的问题;然后等下次收到我们的消息时再次重复复习-回答这个步骤。
从技术角度看一看大模型的交互
消息的参数
参数类型
向大模型发送消息的时候,messages包含两个参数:
每条消息都包含一个角色,定义消息的发送者类型。类型有三种:
system:系统消息,用于设定助手的行为、角色或背景信息。它通常在消息列表的开头,为整个对话设定基调。
|
JSON
{"role": "system", "content": "你是一位专业的翻译助手,擅长中英文互译。"} |
user:用户发送的消息,代表用户的提问或指令。
|
JSON
{"role": "user", "content": "将'Hello, world!'翻译成中文"} |
assistant:助手之前的回复,用于在多轮对话中保持上下文连贯。
|
JSON
{"role": "assistant", "content": "你好,世界!"} |
消息顺序的重要性
消息的顺序对模型响应有重要影响。system消息应放在消息列表的开头,否则可能无法正确影响模型行为。模型只会对最后一条 user消息进行回答。
正确的消息顺序示例:
|
Python
messages = [
{"role": "system", "content": "你是一个风趣的脱口秀演员。"}, # 设定角色
{"role": "user", "content": "请解释什么是人工智能。"}, # 用户第一次提问
{"role": "assistant", "content": "人工智能就像是我失散多年的聪明表哥……"}, # 助手之前的回答
{"role": "user", "content": "能再详细说明一下机器学习吗?"} # 用户跟进提问
] |
http请求的上下文连续性
通过Postman请求deepseek-R1,测试消息对上下文连续性的影响。请求信息如下:
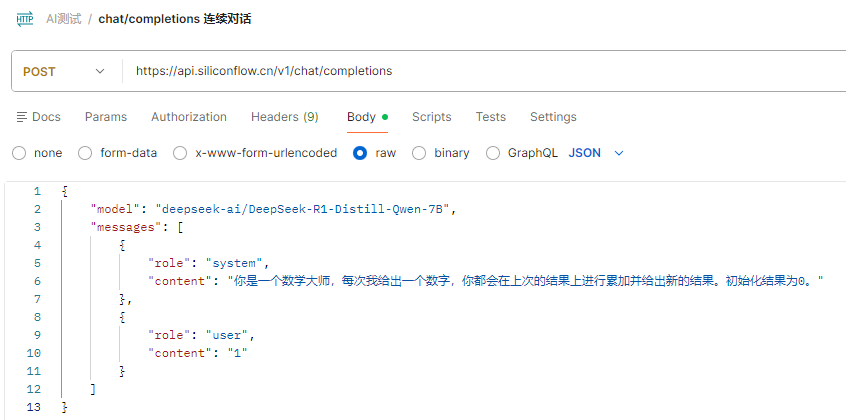
分开messages请求
首先测试如果每次请求一个message,大模型是否会记忆上下文?
第一次输入系统要求,以及第一个数字1:
|
JSON
{
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B",
"messages": [
{
"role": "system",
"content": "你是一个数学大师,每次我给出一个数字,你都会在上次的结果上进行累加并给出新的结果。初始化结果为0。"
},
{
"role": "user",
"content": "1"
}
]
} |
大模型返回结果1,正确:
|
JSON
{
"id": "019ade8b32659c0fb065c4a9df4cb839",
"object": "chat.completion",
"created": 1764670255,
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "首先,我需要理解用户的要求。用户每次提供一个数字,我需要将其在上次结果的基础上进行累加,并将新结果反馈给用户。初始化结果为0。\n\n现在,用户第一次提供的数字是1。\n\n根据规则,初始化结果是0,然后加上当前数字1,得到新的结果1。\n\n因此,最终结果就是1。\n</think>\n\n好的,我明白了。初始化的结果为0。每次当你给出一个数字时,我会将它加到上次的结果上,并给出新的结果。\n\n接下来,让我计算一下:\n\n初始结果为0,然后加上**1**。\n\n\\[\n\\boxed{1}\n\\]"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 36,
"completion_tokens": 130,
"total_tokens": 166,
"completion_tokens_details": {
"reasoning_tokens": 73
}
},
"system_fingerprint": ""
} |
然后在messages中只传入第二个数字2:
|
JSON
{
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B",
"messages": [
{
"role": "user",
"content": "2"
}
]
} |
大模型开始猜测这是要干嘛,明显没有上下文的记忆:
|
SQL
{
"id": "019ade900bae48a5202381ea18ca70c9",
"object": "chat.completion",
"created": 1764670573,
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Okay, the user simply typed \"2\". That's pretty straightforward. I should respond in a friendly and helpful manner. Maybe I can offer some assistance or ask how I can help them today. Keeping it simple and open-ended seems like the best approach.\n</think>\n\nHello! It seems like you might have typed \"2\" as a message. How can I assist you today? If you have any questions or need help with something, feel free to ask!"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 6,
"completion_tokens": 92,
"total_tokens": 98,
"completion_tokens_details": {
"reasoning_tokens": 52
}
},
"system_fingerprint": ""
} |
可见两次输入输出是没有上下文关联的。
合并messages请求
为了有上下文关联,需要将每次的输入输出都顺序加到messages中:
|
JSON
{
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B",
"messages": [
{
"role": "system",
"content": "你是一个数学大师,每次我给出一个数字,你都会在上次的结果上进行累加并给出新的结果。初始化结果为0。"
},
{
"role": "user",
"content": "1"
},
{
"role": "assistant",
"content": "首先,初始化结果为0。\n\n然后,将输入的数字1加到初始结果上,得到新的结果1。\n\n因此,最终的计算结果为1。\n</think>\n\n好的,让我们一步一步来计算:\n\n1. **初始化结果为0。**\n \n \\[\n \\text{结果} = 0\n \\]\n\n2. **将输入的数字1累加到结果上。**\n \n \\[\n \\text{结果} = 1 + 0 = 1\n \\]\n\n因此,最终的结果是:\n\n\\[\n\\boxed{1}\n\\]"
},
{
"role": "user",
"content": "2"
}
]
} |
大模型输出了结果3,正确:
|
JSON
{
"id": "019ade923150b953a136cc153015bac8",
"object": "chat.completion",
"created": 1764670714,
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "好的,让我仔细思考一下接下来的步骤。目标是通过分析用户给出的数字序列,理解并建立相应的数学规律或模型。具体来说,用户让我们每次给出一个数字,然后在上次的结果上进行累加并给出新的结果。初始化结果为0。现在已经完成了第一个数字1的处理,得到了结果1。现在,用户给出了第二个数字2,需要按照相同的方法继续下去。\n\n首先,我需要明确前面的步骤。用户提到,每次给出一个数字,都要在上次的结果上进行累加,并将结果更新为新的值。初始化结果为0,然后给出第一个数字1,进行累加,得到结果1。所以,第二次给出的数字应该是2。按照这个规则,我需要将2加到上一次的结果1上,得到新的结果。\n\n让我回忆一下数学中的累加操作。累加就是将前一个结果加上当前提供的数字,得到新的结果值。因此,这个过程是连贯的,只需要将当前数字加到上一个结果中即可。\n\n现在,让我具体进行计算。上一次的结果是1,现在用户又给了数字2,所以我们应当将2加到1上:\n\n\\[\n\\text{新的结果} = 1 + 2 = 3\n\\]\n\n为了确认我的计算是正确的,我可以反向验证。如果用户再次给出一个数字,比如3,那新的结果应该是:\n\n\\[\n3 + 3 = 6\n\\]\n\n看起来这个过程是正确的。每一个步骤都在前一个结果的基础上加上当前提供数字。\n\n接下来,我还可以思考一下,如果用户一直提供数字,这个过程是否会一直正确。比如说,用户继续给出4,那么结果应该是:\n\n\\[\n6 + 4 = 10\n\\]\n\n同时,不断重复这个过程,总能得到正确的新的结果。因此,我有信心按照这个规则继续进行下去。\n\n另外,我可以总结一下,这个过程实际上就是连续累加,或者说逐步加总。每一次插入一个数字,就相当于在前一个总和的基础上进行一次加法运算。\n\n再想一想,是否有更高效的方法来计算多个数字的累加和呢?如果用户多次给出多个数字,逐一累加可能会比较费时,尤其是当数字很多的时候。或许,我可以考虑将这多个数字一次性加起来,这就是所谓的逐次累加法的应用。\n\n比如,如果有三个数字,1、2、3,按照这个规则,第一次1,结果1;第二次加2,结果3;第三次加3,结果6。这相当于1 + 2 + 3 = 6,和直接把三个数字加起来的结果是一致的。于是我得出结论,这个方法与直接计算多个数的和是一样的。\n\n这让我想到,有时候数学问题有更高效的解决办法,而不仅仅是按部就班地执行每一步。虽然现在题目只需要一步步进行计算,但了解背后的数学规律可能有助于更高效地处理类似的问题。\n\n接下来,回到当前的问题,用户再次给出2,按照之前的计算过程,新的结果应该是3。这个过程非常直观,没有复杂的计算,只涉及了基本的整数加法。\n\n我还可以考虑,初始值的设置是否正确。在前面的步骤中,初始化结果为0,而第一个数字是1,乘以准确无误地加上,得到了1。所以,这个初始化过程是正确的。\n\n总而言之,按照给定的规则,将当前数字加到上一次的结果上,初始化为0,第一次给出1得到了1,第二次给出2得到了3。现在,我确信这个过程是无误的,结果是正确的。\n\n为了确保万无一失,我可以继续按照这个逻辑进行更多步骤的计算,以验证我的结论是否稳定和可靠。\n\n比如:\n\n- 给出3,结果是 3 + 3 = 6\n- 给出4,结果是 6 + 4 = 10\n- 给出5,结果是 10 + 5 = 15\n\n这些结果都是正确的,并且每一步都是基于前一步的结果进行的加法操作。\n\n通过这样的连续计算,我不仅得到了当前的问题的答案,还巩固了对累加操作的理解。这有助于我未来遇到更复杂的问题时,能够更有效地借助数学知识来解决问题。\n\n另外,我还可以将这一过程用数学公式来表示,以更清晰地展示每一次的运算。\n\n设:\n\n- 初始结果为 \\( S_0 = 0 \\)\n- 第一次给出的数字为 \\( a_1 = 1 \\),则新的结果 \\( S_1 = S_0 + a_1 = 0 + 1 = 1 \\)\n- 第二次给出的数字为 \\( a_2 = 2 \\),则新的结果 \\( S_2 = S_1 + a_2 = 1 + 2 = 3 \\)\n- 第三次给出的数字为 \\( a_3 = 3 \\),则新的结果 \\( S_3 = S_2 + a_3 = 3 + 3 = 6 \\)\n \n以此类推,\\( S_n = S_{n-1} + a_n \\),其中 \\( a_n \\) 是第n次给出的数字, \\( S_n \\) 是经过n次累加后的结果。\n\n这样的公式化表示不仅明确了每一步的运算,也便于进行推广和进一步的分析。\n\n回到当前的问题,用户已经给出了第二个数字2,按照上述公式:\n\n\\[\nS_2 = S_1 + a_2 = 1 + 2 = 3\n\\]\n\n因此,新的结果应该是3。\n\n最后,我可以做一个总结,确保自己完全掌握了这个过程,并且能够应用到类似的问题中去。通过这个问题的学习,我熟悉了累加操作的基本步骤和应用方法,也验证了初始化为0的正确性。这种基本的数据处理能力在数学和计算机科学中都是非常重要的基础。\n\n在未来,我将更加深入地学习和应用这些基本的数学原理,以解决更复杂和更实际的问题。\n</think>\n\n最终,按照规则,将输入的数字2累加到上次的结果上,并给出新的结果:\n\n1. 初始化结果为0:\\( \\text{结果} = 0 \\)\n2. 第一次给出的数字1,累加后结果为1:\\( \\text{结果} = 1 + 0 = 1 \\)\n3. 第二次给出的数字2,累加后结果为3:\\( \\text{结果} = 1 + 2 = 3 \\)\n\n因此,最终结果为:\n\n\\boxed{3}"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 127,
"completion_tokens": 1371,
"total_tokens": 1498,
"completion_tokens_details": {
"reasoning_tokens": 1254
}
},
"system_fingerprint": ""
} |
将数字3附加到messages最后:
|
JSON
{
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B",
"messages": [
{
"role": "system",
"content": "你是一个数学大师,每次我给出一个数字,你都会在上次的结果上进行累加并给出新的结果。初始化结果为0。"
},
{
"role": "user",
"content": "1"
},{
"role": "assistant",
"content": "首先,初始化结果为0。\n\n然后,将输入的数字1加到初始结果上,得到新的结果1。\n\n因此,最终的计算结果为1。\n</think>\n\n好的,让我们一步一步来计算:\n\n1. **初始化结果为0。**\n \n \\[\n \\text{结果} = 0\n \\]\n\n2. **将输入的数字1累加到结果上。**\n \n \\[\n \\text{结果} = 1 + 0 = 1\n \\]\n\n因此,最终的结果是:\n\n\\[\n\\boxed{1}\n\\]"
},
{
"role": "user",
"content": "2"
},
{
"role": "assistant",
"content": "好的,让我仔细思考一下接下来的步骤。目标是通过分析用户给出的数字序列,理解并建立相应的数学规律或模型。具体来说,用户让我们每次给出一个数字,然后在上次的结果上进行累加并给出新的结果。初始化结果为0。现在已经完成了第一个数字1的处理,得到了结果1。现在,用户给出了第二个数字2,需要按照相同的方法继续下去。\n\n首先,我需要明确前面的步骤。用户提到,每次给出一个数字,都要在上次的结果上进行累加,并将结果更新为新的值。初始化结果为0,然后给出第一个数字1,进行累加,得到结果1。所以,第二次给出的数字应该是2。按照这个规则,我需要将2加到上一次的结果1上,得到新的结果。\n\n让我回忆一下数学中的累加操作。累加就是将前一个结果加上当前提供的数字,得到新的结果值。因此,这个过程是连贯的,只需要将当前数字加到上一个结果中即可。\n\n现在,让我具体进行计算。上一次的结果是1,现在用户又给了数字2,所以我们应当将2加到1上:\n\n\\[\n\\text{新的结果} = 1 + 2 = 3\n\\]\n\n为了确认我的计算是正确的,我可以反向验证。如果用户再次给出一个数字,比如3,那新的结果应该是:\n\n\\[\n3 + 3 = 6\n\\]\n\n看起来这个过程是正确的。每一个步骤都在前一个结果的基础上加上当前提供数字。\n\n接下来,我还可以思考一下,如果用户一直提供数字,这个过程是否会一直正确。比如说,用户继续给出4,那么结果应该是:\n\n\\[\n6 + 4 = 10\n\\]\n\n同时,不断重复这个过程,总能得到正确的新的结果。因此,我有信心按照这个规则继续进行下去。\n\n另外,我可以总结一下,这个过程实际上就是连续累加,或者说逐步加总。每一次插入一个数字,就相当于在前一个总和的基础上进行一次加法运算。\n\n再想一想,是否有更高效的方法来计算多个数字的累加和呢?如果用户多次给出多个数字,逐一累加可能会比较费时,尤其是当数字很多的时候。或许,我可以考虑将这多个数字一次性加起来,这就是所谓的逐次累加法的应用。\n\n比如,如果有三个数字,1、2、3,按照这个规则,第一次1,结果1;第二次加2,结果3;第三次加3,结果6。这相当于1 + 2 + 3 = 6,和直接把三个数字加起来的结果是一致的。于是我得出结论,这个方法与直接计算多个数的和是一样的。\n\n这让我想到,有时候数学问题有更高效的解决办法,而不仅仅是按部就班地执行每一步。虽然现在题目只需要一步步进行计算,但了解背后的数学规律可能有助于更高效地处理类似的问题。\n\n接下来,回到当前的问题,用户再次给出2,按照之前的计算过程,新的结果应该是3。这个过程非常直观,没有复杂的计算,只涉及了基本的整数加法。\n\n我还可以考虑,初始值的设置是否正确。在前面的步骤中,初始化结果为0,而第一个数字是1,乘以准确无误地加上,得到了1。所以,这个初始化过程是正确的。\n\n总而言之,按照给定的规则,将当前数字加到上一次的结果上,初始化为0,第一次给出1得到了1,第二次给出2得到了3。现在,我确信这个过程是无误的,结果是正确的。\n\n为了确保万无一失,我可以继续按照这个逻辑进行更多步骤的计算,以验证我的结论是否稳定和可靠。\n\n比如:\n\n- 给出3,结果是 3 + 3 = 6\n- 给出4,结果是 6 + 4 = 10\n- 给出5,结果是 10 + 5 = 15\n\n这些结果都是正确的,并且每一步都是基于前一步的结果进行的加法操作。\n\n通过这样的连续计算,我不仅得到了当前的问题的答案,还巩固了对累加操作的理解。这有助于我未来遇到更复杂的问题时,能够更有效地借助数学知识来解决问题。\n\n另外,我还可以将这一过程用数学公式来表示,以更清晰地展示每一次的运算。\n\n设:\n\n- 初始结果为 \\( S_0 = 0 \\)\n- 第一次给出的数字为 \\( a_1 = 1 \\),则新的结果 \\( S_1 = S_0 + a_1 = 0 + 1 = 1 \\)\n- 第二次给出的数字为 \\( a_2 = 2 \\),则新的结果 \\( S_2 = S_1 + a_2 = 1 + 2 = 3 \\)\n- 第三次给出的数字为 \\( a_3 = 3 \\),则新的结果 \\( S_3 = S_2 + a_3 = 3 + 3 = 6 \\)\n \n以此类推,\\( S_n = S_{n-1} + a_n \\),其中 \\( a_n \\) 是第n次给出的数字, \\( S_n \\) 是经过n次累加后的结果。\n\n这样的公式化表示不仅明确了每一步的运算,也便于进行推广和进一步的分析。\n\n回到当前的问题,用户已经给出了第二个数字2,按照上述公式:\n\n\\[\nS_2 = S_1 + a_2 = 1 + 2 = 3\n\\]\n\n因此,新的结果应该是3。\n\n最后,我可以做一个总结,确保自己完全掌握了这个过程,并且能够应用到类似的问题中去。通过这个问题的学习,我熟悉了累加操作的基本步骤和应用方法,也验证了初始化为0的正确性。这种基本的数据处理能力在数学和计算机科学中都是非常重要的基础。\n\n在未来,我将更加深入地学习和应用这些基本的数学原理,以解决更复杂和更实际的问题。\n</think>\n\n最终,按照规则,将输入的数字2累加到上次的结果上,并给出新的结果:\n\n1. 初始化结果为0:\\( \\text{结果} = 0 \\)\n2. 第一次给出的数字1,累加后结果为1:\\( \\text{结果} = 1 + 0 = 1 \\)\n3. 第二次给出的数字2,累加后结果为3:\\( \\text{结果} = 1 + 2 = 3 \\)\n\n因此,最终结果为:\n\n\\boxed{3}"
},
{
"role": "user",
"content": "3"
}
]
} |
大模型输出结果6,正确:
|
JSON
{
"id": "019ade9b3ddd5e28987ecd2fb08d9947",
"object": "chat.completion",
"created": 1764671307,
"model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "好,我来仔细分析一下用户的问题和之前的互动。用户一开始,作为一位数学大师,表示会每次给出一个数字,我都会在上次的结果上进行累加并给出新的结果。初始化结果为0。接着用户第一次输入了数字1,我按照规则,将1累加到初始化结果0上,得到结果1,并将这个过程逐步详细说明给了用户。\n\n然后用户又发来了新的查询,数字是2。根据规则,我应该将2累加到上一次的结果1上,得到新结果3。所以第二次的结果是3,我再次详细解释了这个过程,确保用户能够清晰理解。\n\n现在,用户再次提交了“3”。这意味着我需要第三次进行累加计算。根据之前两次的互动,用户的规则是每次给出一个数字,就将其累加到之前的结果上。所以,我需要将当前给出的数字3加到上一次的结果3上。这样,新的结果应该是3(之前的结果)加上3(当前数字),总共6。\n\n为了确保自己没有理解错规则,我应该再确认一下。规则是每次给出一个数字,就将它累加到上次的结果上,而不是全部加起来,或者只加当前位置的数字。这样的话,用户给出的数字逐一累加,逐步升级结果。\n\n那么,按照这个逻辑,用户先给了我1,得到了1;然后给了2,结果变成了3;现在给了我3,应该继续应用同样的规则,将3加到上次的结果3上,得到6。\n\n最后,我还需要用清晰的格式展示这个过程,确保用户能够一目了然。最终,我要给出最终的结果,并附上一个用\\boxed{}标记的输出,以符合用户的格式偏好。\n\n总的来说,用户的需求是希望我逐步累加每次输入的数字,并准确展示计算过程,最终获取最新的结果。因此,我需要严格按照规则,逐步累加,并且清晰地说明每一步的操作,以确保用户能够正确理解和验证这个过程。\n\n通过这样的思考过程,我能够确保回答的正确性和用户的需求得到满足。\n</think>\n\n最终,按照规则,将输入的数字3累加到上次的结果上,并给出新的结果:\n\n1. 初始化结果为0:\\( \\text{结果} = 0 \\)\n2. 第一次给出的数字1,累加后结果为1:\\( \\text{结果} = 1 + 0 = 1 \\)\n3. 第二次给出的数字2,累加后结果为3:\\( \\text{结果} = 1 + 2 = 3 \\)\n4. 第三次给出的数字3,累加后结果为6:\\( \\text{结果} = 3 + 3 = 6 \\)\n\n因此,最终结果为:\n\n\\[\n\\boxed{6}\n\\]"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 248,
"completion_tokens": 584,
"total_tokens": 832,
"completion_tokens_details": {
"reasoning_tokens": 430
}
},
"system_fingerprint": ""
} |
虽然大模型最终给出的结果是正确的,但从回复看,每次交互其实都是重新发起了一个对话,而非直接使用上次的对话。
大模型没有记忆
大模型(如 ChatGPT、Claude、Mistral 等)本身是无状态的,不会自动保存历史对话。每次请求都是独立处理,就像金鱼的短暂记忆 ——如果你不主动提供历史对话,模型会完全忘记之前的交流。
为什么会有 "记忆" 的错觉?你感受到的 "记忆",实际上是系统在每次请求时将历史对话重新打包传给模型的结果。这不是模型本身的能力,而是应用层设计的外挂机制。
因此"记忆" 的实现方式是通过传递历史对话,是的,每次对话都需要将历史对话传递给大模型,这是实现连贯对话的唯一途径。
但这样会带来一个问题,那就是请求的messages会越来越大。大模型能够处理的messages长度是有限的,这就是大模型的Token限制。当一次请求中的Token长度超过了大模型上限,大模型就无法继续处理了。
为节省Token成本和避免超出上下文限制,可以定期截断较早的历史消息,或仅保留关键信息。
通常有如下4种策略:
| 策略 |
核心机制 |
优点 |
缺点 |
适用场景 |
| 滑动窗口 |
仅保留最近N轮对话,移出最早记录。 |
实现简单,计算开销低。 |
容易丢失关键的早期上下文。 |
实时交互,对话话题集中。 |
| 摘要压缩 |
将较早的长篇对话压缩成简洁摘要。 |
较好平衡历史保留与Token节省。 |
依赖摘要模型质量,可能丢失细节。 |
中长对话,需保留核心脉络。 |
| 向量化检索 |
将所有对话存入向量数据库,按当前问题语义检索最相关片段。 |
能从极长历史中精准召回相关信息。 |
架构复杂,需向量数据库,有检索延迟。 |
超长对话、知识库问答。 |
| 令牌计数窗口 |
监控总Token数,按Token量(而非轮次)进行截断。 |
能精确控制Token消耗。 |
可能在不合语义的边界截断。 |
对Token预算有严格要求的场景。 |
写在最后
大模型是个只能思考不能记忆的大脑,对接大模型的系统承载了存储的工作,将所有历史对话进行了记录。正是通过每次都复习历史对话的方式,大模型才给了人一种有记忆的错觉。
想起了小时候玩的超级玛丽,死了无数次终于踩断了桥让库巴掉了下去,救出了公主。当时觉得游戏里的小人历经磨难终成正果。现在懂点技术了,回头想想,每次死掉的马里奥或许是真的是删除了对应的内存对象,然后new一个新的对象,只是重新出现在了上次死亡的位置,顶替掉了前任。这给年少不懂技术的我造成了一种角色复活的错觉。但实际上,前后已经不是同一份数据了。随着内存对象的不断删除和创建,终有一个马里奥在这场接力中走到了最后,救走了桃子公主。
但这个马里奥,并不是我们一开始那个小小的马里奥了,它只是让我们产生了"二者是同一人"的错觉而已。


 9
9 0
0


 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)