【vLLM-模型特性适配】Minimax模型特性分析
本文分析了Minimax公司发布的大模型架构的创新技术及其应用。重点介绍了Lightning Attention结构,通过结合Linear Attention与分块计算实现线性复杂度,支持超长上下文处理(训练100万tokens/推理400万tokens)。文章还解析了CISPO算法如何优化PPO在长序列生成中的梯度裁剪问题,以及主流线性注意力模型(如Qwen3_next、Kimi Linear等
作者:昇腾实战派
本文档主要分析Minmax公司发布的大模型结构和创新点,以及应用了线性注意力的主流大模型。
一、minimax模型基本介绍
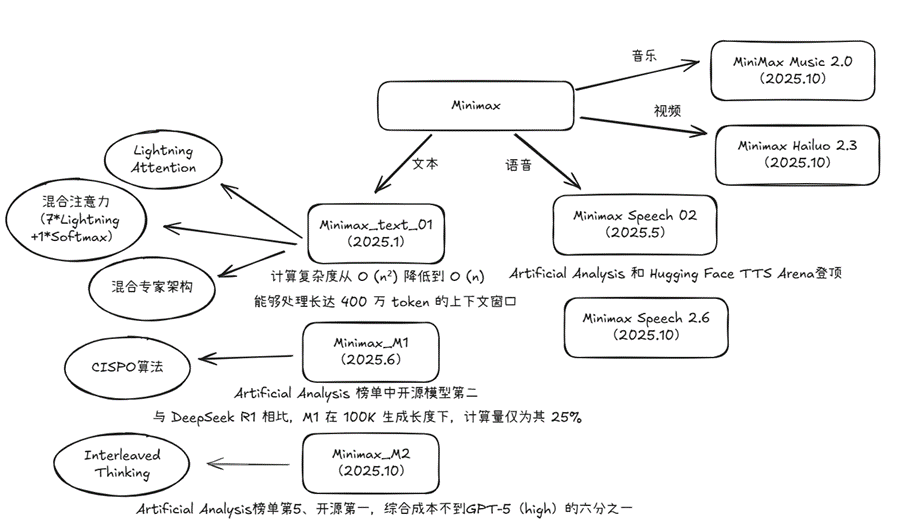
模型架构亮点
- Minimax_text_01 Lightning Attention:基于Linear Attention 的分块计算 ,实现线性复杂度。
- Minimax_M1 CISPO算法:解决长序列生成任务中重要梯度裁剪的问题。
- Minimax_M2 Interleaved Thinking:动态思考,提升agent泛化能力。
- 混合注意力机制:结合Lightning Attention、Softmax Attention和Mixture-of-Experts(MoE),兼顾长上下文和高效计算。
- 长上下文处理:训练时上下文长度达 100万tokens,推理时支持 400万tokens。
- 进阶并行策略:采用 LASP+、varlen ring attention、Expert Tensor Parallel(ETP)等技术,提升训练效率和推理性能。
二、Lightning Attention结构分析
Lightning Attention:基于Linear Attention结合Flash Attention分块处理实现并行计算的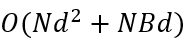
线性复杂度(B为分块长度)

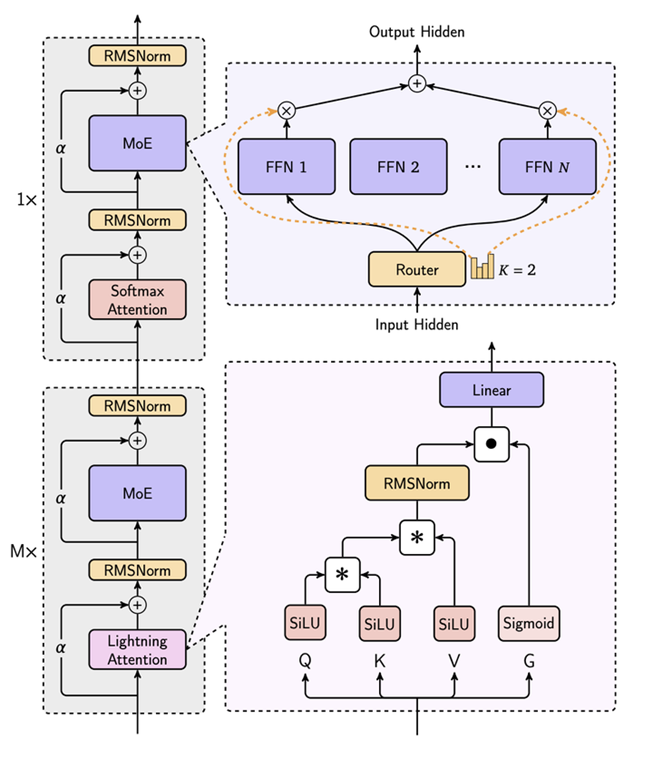
模型结构如下:
其中每8层中有7个是基于Lightning Attention的线性注意力,有一层是传统的SoftMax注意力。
Linear Attention
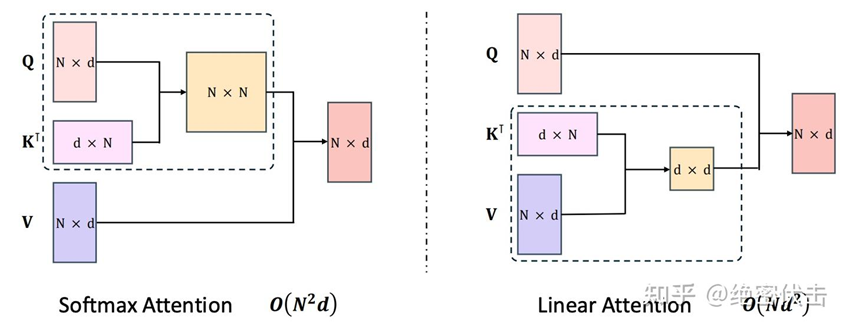
线性注意力机制(Linear Attention)目标是将注意力矩阵的计算复杂度从O(N^2)降低到O(N)。
标准的Attention计算过程如下: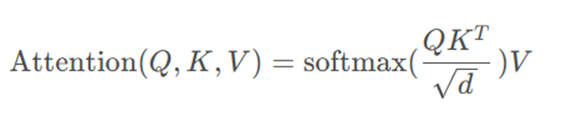
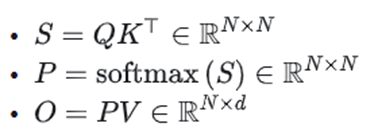
计算复杂度为O(N^2 d)
Linear Attention的做法:先计算K^T V,再与Q相乘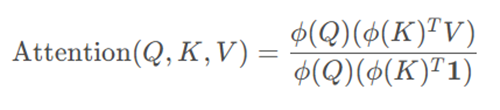
ϕ(.)是特征映射函数
FlashAttention
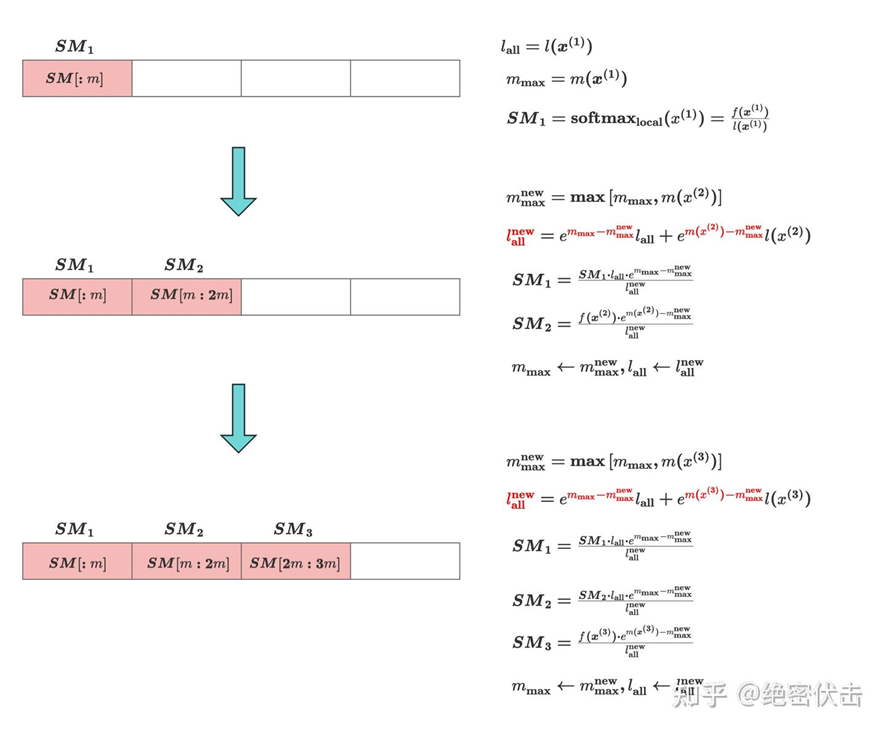
FlashAttention核心原理是通过将输入分块,并在每个块上执行注意力操作,从而减少对高带宽内存(HBM)的读写操作。
假设注意力权重具有 “局部性”(即每个 Query 主要关注附近的 Key 位置,而非全局),因此可将 Key 序列划分为多个局部窗口,仅在窗口内计算归一化分母。例如,将序列分为长度为 w 的窗口,每个 Query 仅与窗口内的 Key 计算点积,此时每个窗口的归一化分母计算复杂度为O(W),全局复杂度降至O(nW)。若 w 固定(如 w=64),则整体接近O(n)。
Softmax 分块计算
Lightning Attention
Lightning Attention]可以理解为Linear Attention 的分块计算
Lightning Attention 的核心优化在于:通过近似或简化注意力权重的计算方式,在保留关键依赖关系的同时,将复杂度降至O(〖Nd〗^2+NBd),实现线性或近线性复杂度。
实现细节:通过滑动窗口或固定窗口划分 Key,对窗口外的 Key 直接赋予极低权重(如设为负无穷,使其在 Softmax 中被忽略),从而避免全局计算。

注意力计算中的左乘积定义为:

最终实现的时间复杂度为: O(〖Nd〗^2+NBd)
MiniMax-01系列与GPT-4o和Claude-3.5-Sonnet等最先进模型的性能相当,同时上下文窗口长20 - 32倍,在处理更长上下文方面具有卓越能力。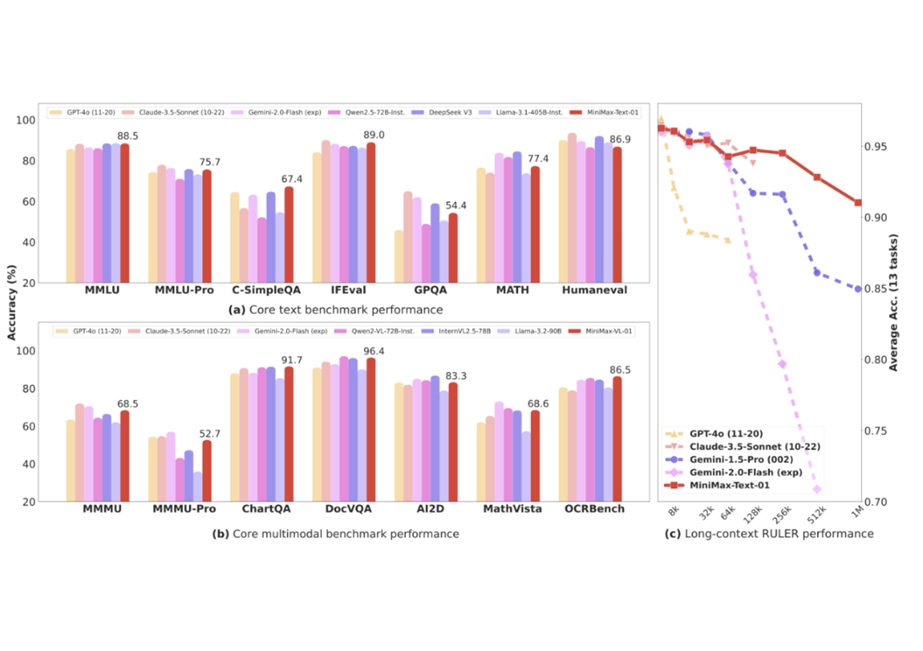
在处理长输入的时候有非常高的效率,接近线性复杂度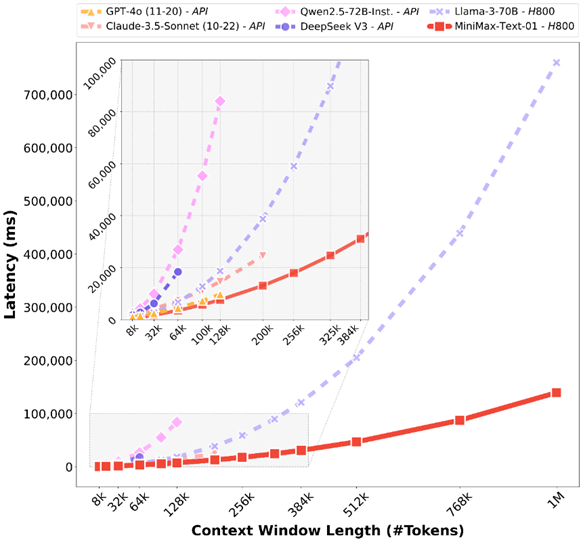
三、主流线性注意力大模型分析
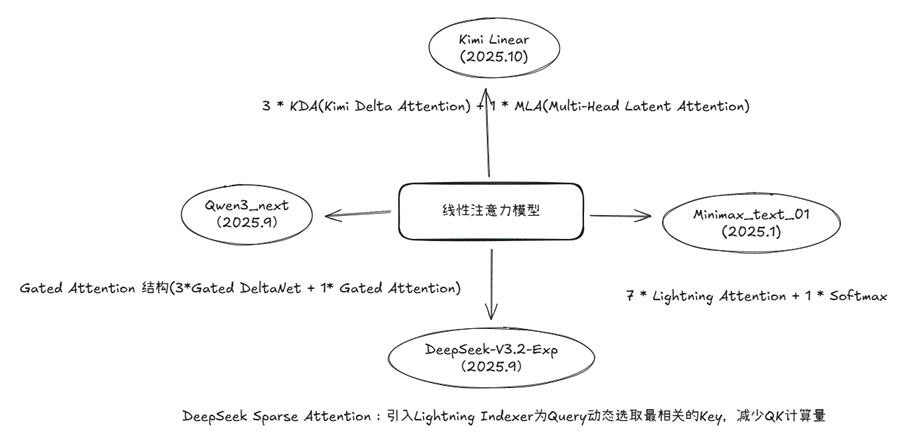
Qwen3_next
混合注意力:将标准注意力替换为 Gated DeltaNet (75%)和 Gated Attention(25%) 的组合,从而实现超长上下文长度的有效上下文建模。
Gated Attention :引入可学习的门控参数(类似 LSTM 或 GRU 中的门控)动态调控注意力权重的计算,过滤掉无关或低重要性的 token 交互,仅保留高相关性的注意力连接。
Gated DeltaNet 是一种结合门控机制与 “Delta 注意力”(Delta Attention)的混合架构,更侧重长序列建模中的效率优化,尤其在缓存复用和增量计算上有突出设计。
高稀疏度混合专家(MoE):在 MoE 层中实现了极低的激活比率,大幅减少了每个token的 FLOPs,同时保持了模型容量。
稳定性优化:包括 零中心化和权重衰减层归一化 等技术,以及其他稳定增强措施,以实现稳健的预训练和后训练。
多token预测(MTP):提升预训练模型性能并加速推理
Kimi Linear
Kimi Delta Attention (KDA):通过更细粒度的门控机制扩展了 Gated DeltaNet。
模型结构:3 * KDA(Kimi Delta Attention) + 1 * MLA(Multi-Head Latent Attention)
Delta Attention:对于新增输入的 token,仅计算其与历史序列的 “差异(Delta)” 部分,而非重新计算全部注意力。
DeepSeek-V3.2-Exp
DeepSeek Sparse Attention (DSA):引入一个轻量级的 Lightning Indexer,专门负责为每个 Query Token 动态地选取 Top-K 个最相关的 Key。
不显著牺牲性能的前提下,大幅提升训练与推理中的效率。
Lightning Indexer:为每个查询 token 快速计算与之前所有 token 的“相关性分数”,称之为Index Score,决定哪些 key-value 需要参与注意力计算。
Linear/Sparse Attention在应用时的问题:
混合注意力机制指标不容易量化,不利于工程优化
FlashAttention、MoE等技术的发展,线性注意力优势降低
当前Linear/Sparse Attention结构在算力利用上面有局限性,会受到存储精度、Prefix Cache等因素的限制。
当Context Length足够长时,Linear/Sparse Attention结构的优势才会体现出来,目前的算力下并没有突出优势。
四、CISPO算法分析
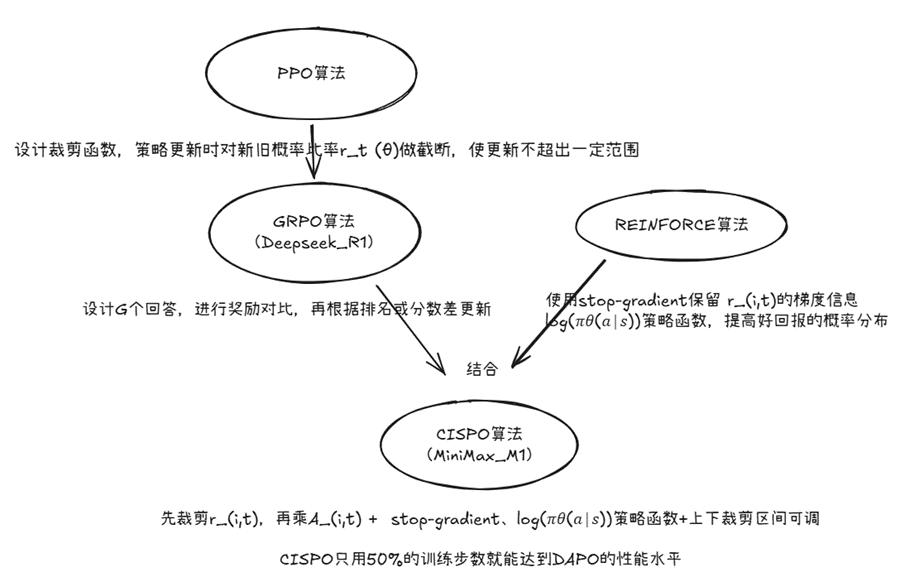
CISPO(Clipped IS-weight Policy Optimization)是2025年由MiniMax-AI团队提出的一种强化学习算法,专为大型语言模型(LLM)的RLHF任务设计。CISPO旨在解决PPO在长序列生成任务中的痛点,如梯度阻塞(gradient clipping导致贡献丢失)和熵崩塌(entropy collapse,导致生成多样性下降)。通过创新设计,CISPO实现了更高的训练效率(约2x加速)和性能提升(在数学推理任务中准确率+10%)。
个人理解:PPO/GRPO算法中,当一个token超出正常值太多会被裁剪掉,在梯度更新时不会迭代,CISPO算法在GRPO基础上参考REINFORCE算法增加了logπ,梯度更新时仍然保留了一些反馈,同时设计G个回答并正则化突出优势回答。这种结构更适应于复杂推理场景。
PPO算法
PPO算法(Proximal Policy Optimization, 近端策略优化算法)为了避免策略更新太猛导致训练不稳定,利用一个裁剪函数,对策略更新时的新旧概率比率r_t (θ)做截断,保证更新不要超出一定范围。
PPO目标函数更新策略: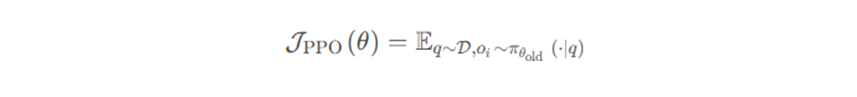
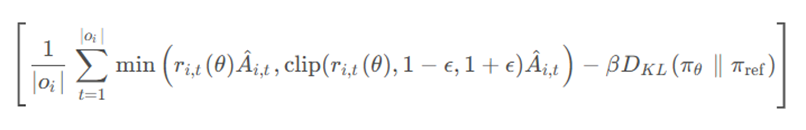
重要性采样权重比率: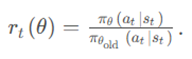
的更新范围是(1-ε,1+ε),ε的取值一般为0.1~0.2
A ̂_(i,t)表示token的优势函数,由奖励模型和批判模型共同计算得到,衡量第 t 个token对最终回报的贡献差异。
PPO的缺点:长序列高比率token易触发裁剪,导致梯度为0,丢失关键贡献。
问题例子:在推理模型训练中,我们希望模型出现"Aha"这种表示顿悟的token,此时:
旧策略中"Aha"的概率很低=0.01(本来的概率)
经过训练后新策略中"Aha"的概率很高0.12(希望出现)
重要性采样权重r=12.0
这个token的优势:A = 80(因为使用“Aha”后一般可以得到正确答案)
此时r>>1+ε,公式中会取固定值1+ε,因此在梯度更新时相对于策略参数θ是常数,不会随着π_θ更新
GRPO(deepseek R1)算法:
设计G个回答,进行奖励对比,再根据排名或分数差更新

REINFORCE 算法
sg() 表示 stop gradient 停止梯度,即这里面的公式不参与梯度更新。
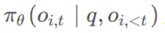
是新策略模型采样的概率,如果某个动作带来了好回报,那就提升它的概率,否则就降低它的概率。
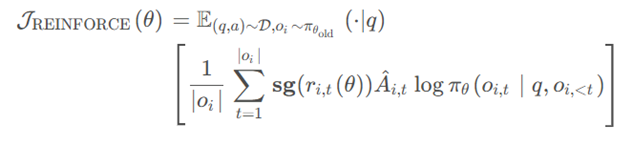
CISPO算法
CISPO的核心理念是:不再裁剪token更新,而是裁剪重要性采样权重。具体做法是在 REINFORCE 算法基础上引入了 GRPO 的组内相对优势。
传统方法:先计算r_(i,t)*A_(i,t),再裁剪整个乘积,高 r_(i,t)易触发阻塞,丢失高质量信号
CISPO:先裁剪r_(i,t),再乘A_(i,t) + stop-gradient停止r_(i,t)梯度更新 + 上下裁剪区间可调修复 Clip 的非线性阻塞
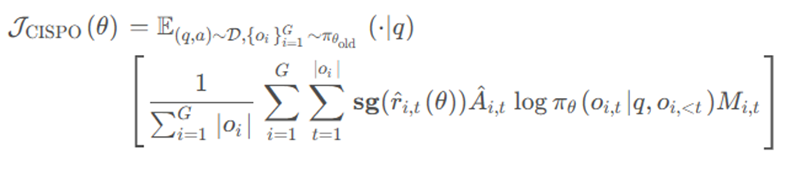
引入了一个掩码因子M,当 token 优化的跨度太大时,也将它裁剪掉。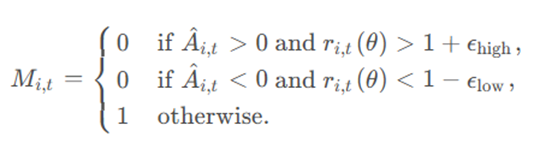
算法优势:
- 保留所有token的梯度贡献:特别是在长回答中,每个token都能参与梯度更新
- 减少方差:通过权重裁剪而非token裁剪来稳定训练
- 无需KL惩罚项

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)