开源SHTNet:基于球谐变换的轻量鲁棒多通道语音识别
新疆大学与清华大学团队提出SHTNet语音识别框架,通过球谐变换实现阵列几何解耦,显著提升多通道语音识别的鲁棒性。该框架包含球谐编码器、空间-频谱注意力融合网络和Rand-SHT训练策略,在AISHELL-4等数据集测试中展现优异性能:CER更低、计算量减少97.1%、跨阵列稳定性强(8通道降至2通道仅降2.32%),流式识别延迟仅15.5ms。研究成果发表于INTERSPEECH2025,代码已
 在多通道语音识别研究中,如何克服阵列结构与环境多样性带来的泛化问题一直是核心挑战。针对该问题,新疆大学与清华大学研究团队提出了一种基于球谐变换(Spherical Harmonic Transform, SHT) 的轻量鲁棒端到端语音识别框架——SHTNet,该成果已发表于语音领域重要学术会议INTERSPEECH 2025。
在多通道语音识别研究中,如何克服阵列结构与环境多样性带来的泛化问题一直是核心挑战。针对该问题,新疆大学与清华大学研究团队提出了一种基于球谐变换(Spherical Harmonic Transform, SHT) 的轻量鲁棒端到端语音识别框架——SHTNet,该成果已发表于语音领域重要学术会议INTERSPEECH 2025。
球谐变换简介
球谐函数变换为多通道语音处理提供了一种与阵列几何解耦的声场表示方法。它将分布在球面上的声压信号,依据球谐函数系(一组定义在球面上的正交完备基函数)进行分解,得到对应的球谐系数。这些系数表征了声场的空间角谱分布,其维度仅由球谐展开的阶数 N 决定((N+1)^2 维),与具体的麦克风阵列构型和通道数无关。因此,SHT 将阵列相关的阵元域信号转换成了几何不变的球谐域特征,为构建鲁棒且轻量的多通道系统(如多通道语音识别)奠定了关键基础。
球谐函数
![]()
,是定义在球面上的特殊函数。下图是前几个实球谐函数的可视化表示。蓝色部分表示函数为正的区域,黄色部分表示函数为负的区域。球面与原点的距离表示
![]()
在角方向
![]()
上的绝对值。n表示阶数(order),对应下图的行,m表示次数(degree),对应下图的列,
![]()
。
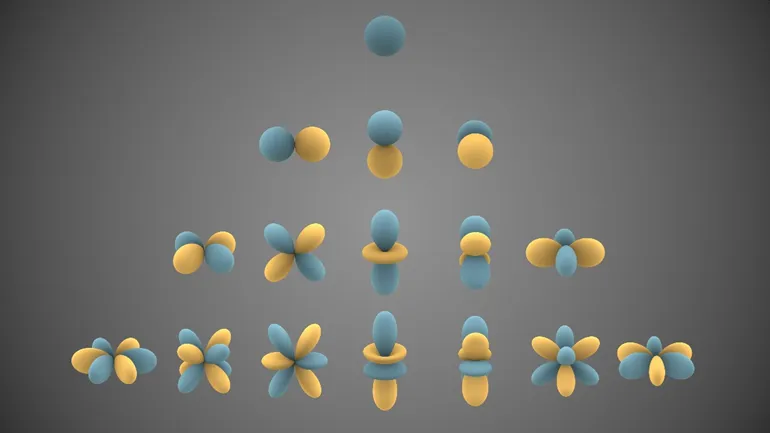
总体框架
SHTNet通过球谐变换将不同几何结构的麦克风阵列信号映射到统一的谐波域,实现对声场拓扑的解耦表示,从而消除对特定几何阵型的依赖。系统主要包括:
SHT Encoder:将不同阵列的麦克风信号,映射到统一的球谐域基函数上,得到一种与几何无关的空间表示;
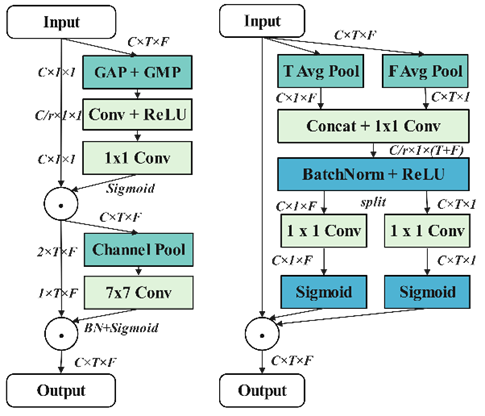
空间-频谱注意力融合网络(Spatio-Spectral Attention Fusion Network, SSAFN):使用卷积块注意力模块(Convolutional Block Attention Module, CBAM)对空间特征建模,使用坐标注意力机制(Coordinate Attention)对频谱特征建模,并将二者融合。通过这种协同作用,SSAFN在不依赖传统波束形成算法的情况下,直接在球谐域内对空间声场特征和频谱特征进行融合,实现强大的语音增强效果;
Rand-SHT训练策略:训练时随机选择不同通道并根据新的几何阵型计算球谐系数,让模型对阵列变化更鲁棒。
下图展示了SHTNet总体框架,通过球谐变换(SHT)将信号转换到球谐域,随后进行增强和识别(ASR, Automatic Speech Recognition)。
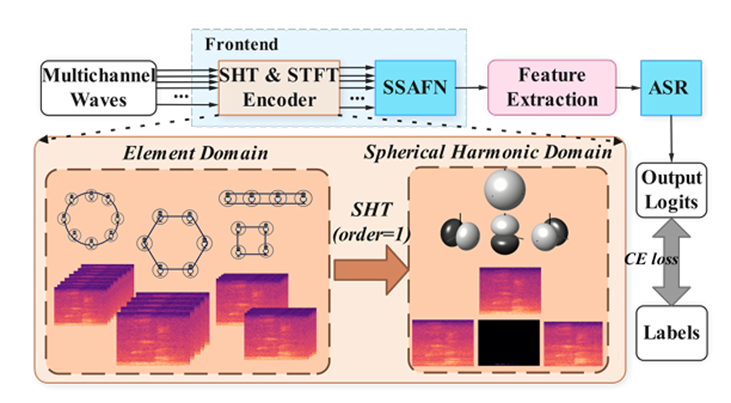
SHTNet总体框架
方法简介
1、SHT & STFT 编码器:将麦克风阵列信号从阵元域(即原始麦克风通道)通过球谐变换 (Spherical Harmonic Transform, SHT) 映射到球谐域。
-
阵元域 (Element Domain)表示:输入信号来自阵列中各个物理麦克风通道
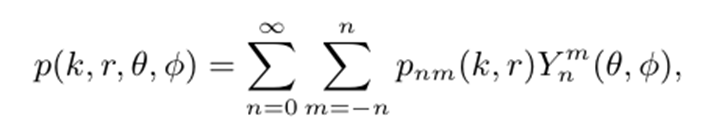
上式表示了在由径坐标
![]()
、顶角
![]()
、方位角
![]()
表示的空间坐标处,波数
![]()
的声压信号
![]()
,可以表示为一组球谐函数
![]()
的线性组合,
![]()
为球谐系数。当
![]()
时,系数
![]()
减小,因此可以忽略不计。因此,上式可以近似为适当的有限阶N。
-
球谐变换 (SHT): 利用球谐基函数将阵元域信号
,转换为与阵列具体几何形状无关的、表示空间声场的球谐系数
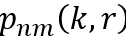
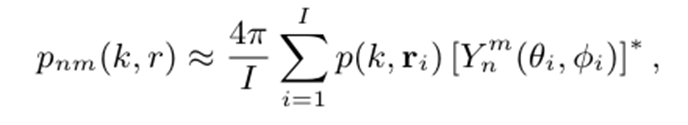
其中假设各麦克风离原点等距,
![]()
表示第
![]()
个麦克风的空间坐标,
![]()
表示第
![]()
个麦克风处的声压,
![]()
为总麦克风数。
2、空间-频谱注意力融合网络 (SSAFN):在球谐域内对空间和频谱信息进行高效融合与增强。
-
联合注意力模块 (JointAttention): CBAM(左图)+ CoorAttention(右图)
式中
![]()
是由球谐系数组成的三维张量,其中
![]()
是时间帧数,
![]()
是频点数,
![]()
,是球谐系数的个数。
-
自注意力通道组合器 (refined Self-Attention Channel Combinator, rSACC): 利用自注意力机制自适应地加权组合球谐通道,增强目标语音信号。
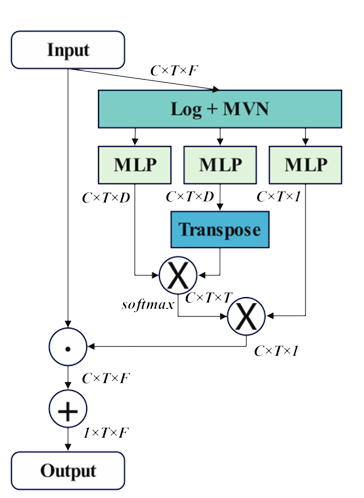
-
多头自注意力 (Multi-Head Self-Attention, MHSA) 后置滤波器: 对融合增强后的特征进行进一步处理,抑制残留噪声。
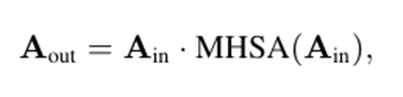
3、联合流式与非流式训练:基于 CUSIDE(分块、模拟未来上下文和解码)及 CUSIDE-Array 框架实现流式处理。将输入信号划分为带上下文(Context) 的分块 (Chunks) 进行处理。在联合训练过程中,流式模型和非流式模型共享网络参数。

4、Rand-SHT 策略:在训练过程中,随机选取
![]()
个麦克风(其中
![]()
,
![]()
为总麦克风数)。基于这组随机选出的麦克风及其重构的阵列几何位置,重新计算球谐系数。增强模型对麦克风数量变化、阵列几何差异以及部分麦克风失效等情况的鲁棒性。
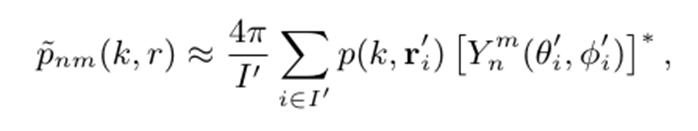
实验结果
我们在多个数据集上进行了验证,包括 AISHELL-4(会议语音)、AliMeeting(跨场景测试)、XMOS(真实噪声环境),结果表明:
-
识别率更高:平均 CER(字符错误率)优于多种主流方法
-
计算量更小:相比神经波束形成方法,前端计算量减少 97.1%
-
跨阵列更稳定:从 8 通道降到 2 通道,性能仅下降 2.32%,远优于同类技术
-
流式识别更快:延迟降低 62%,前端加入而引入的单句平均延迟仅 15.5ms
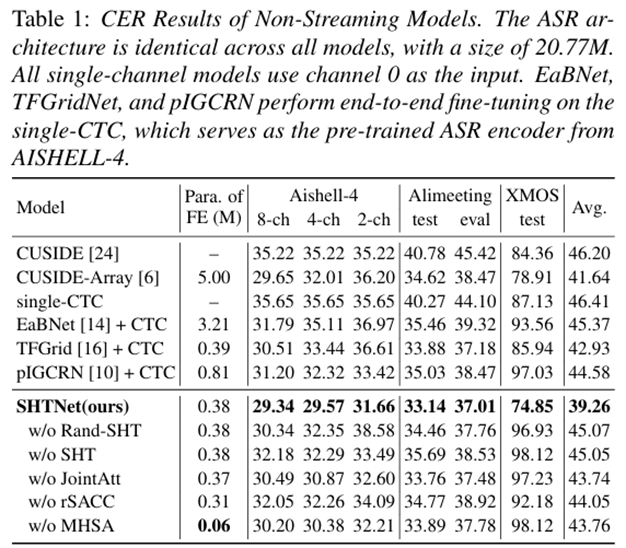
对比实验与消融实验结果(非流式)
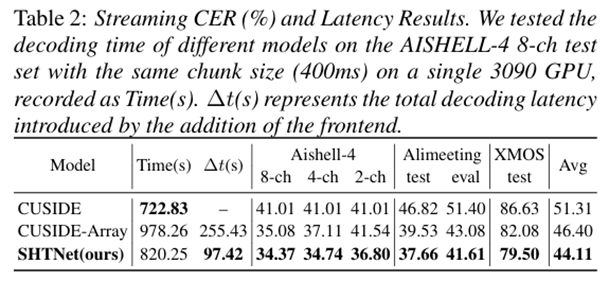
流式实验结果对比展示
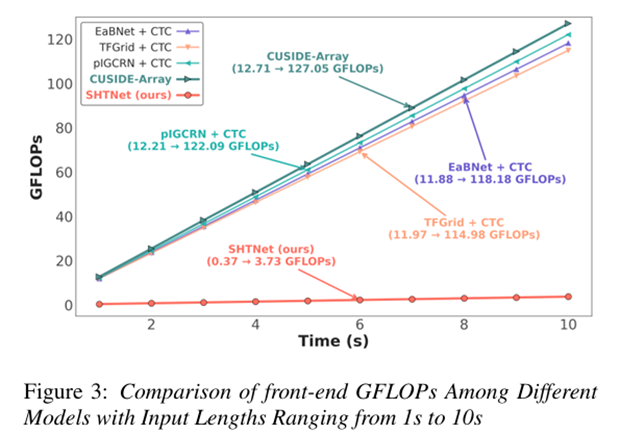
不同模型前端计算量对比图
未来展望
SHTNet 展示了“轻量+鲁棒”的巨大潜力,未来我们还将探索:
-
嵌入式部署优化:让它更好地跑在移动端和嵌入式设备上
-
数据高效学习:减少标注数据需求,提升跨领域适应性
-
多说话人识别:让系统在多人同时讲话的复杂场景中依然鲁棒
已开源代码:
https://github.com/thu-spmi/CAT/blob/master/egs/shtnet/README.md
欢迎开发者测试并在实际应用中反馈意见。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)