AppWorld:一个全新的交互式编码代理基准,专治“简单API调用”不够用
AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents
AppWorld:一个全新的交互式编码代理基准,专治“简单API调用”不够用
最近看到一篇来自Stony Brook University和Allen AI的论文《AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents》(arXiv 2407.18901),提出一个非常硬核的新基准——AppWorld。它专门针对当前LLM代理(agent)在工具使用(tool use)上的痛点:现有基准大多只考几个简单的API调用,缺乏真正的交互性、复杂控制流和环境适应能力。
这篇论文的核心贡献是构建了一个高度可控的“数字世界”,里面有9个日常App(类似Amazon、Venmo、Gmail、Spotify等),457个API,模拟了约100个虚构用户的真实数字生活。然后基于这个世界,构造了750个复杂任务,要求代理通过迭代写代码、调用API、观察结果、再调整代码来完成日常场景。
最让我感兴趣的是他们如何精心设计和构建这个基准,细节做得非常扎实,远超大多数靠众包或LLM自动生成的基准。下面就重点聊聊他们到底是怎么做的。
1. AppWorld Engine:一个高质量、可控的App模拟器
要测交互式编码代理,首先得有一个稳定、可重现、功能丰富的执行环境。他们花了大精力(6万行代码)造了AppWorld Engine:
- 9个日常App:Amazon、Venmo、Gmail、Spotify、Phone(短信+联系人)、Notes、Files、Calendar、Clock。API设计高度模仿真实App的功能,比如下单会清空购物车、会发确认邮件、需要登录认证、搜索支持分页等。
- 457个API,1470个参数,所有API都有详细文档(参数类型、约束、返回JSON schema)。
- 底层是一个SQLite数据库(101张表,72.6万列),所有App操作本质上是对数据库的读写。
- 执行方式:提供类似Jupyter的交互式shell,代理可以写Python代码,状态化执行(变量可复用),直接调用API函数或发REST请求。
- 关键特性:
- 真实性:跨App联动、权限控制、错误提示、分页等都模拟得很细。
- 可控性:可以完全冻结和重置数据库状态 + 系统时间(用freezegun),保证每次运行环境完全一致。
- 可靠性:写了1780个单元测试,覆盖率98%,文档部分自动生成,避免人为错误。
数据库是怎么填充的?他们没直接手写SQL(太容易出错),而是开发了一套工具:用API本身“在过去时间点”批量调用来生成数据。比如让100个虚构用户互相转账、发邮件、加歌到播放列表等,确保关系(室友、家人、同事)和活动时间一致。少数需要精确语义的文本(如健身笔记内容)手动写,其余用ChatGPT生成但严格审查。最终数据库约37万行,极其真实。
2. 如何生成750个复杂任务?—— Task Scenario + Task Generator
他们没有一个个手写750个任务,而是设计了250个Task Scenario(任务模板),每个生成3个变体,共750个任务。
举例模板:
“我上次在Amazon买的{last-color}{apparel}很喜欢,请在同样尺码下重新购买。优先{preferred-color},没有的话用原来颜色。”
通过Task Generator模块自动实例化多个任务,每个Generator包含三部分:
-
Setup程序(最核心)
- 输入:任务模板 + Base DB + 基础日期时间
- 选定“主管人”(Supervisor,即任务执行的对象)
- 填充模板占位符(比如apparel=T-shirt)
- 在Base DB的副本上做任务特定修改,确保每个任务同时满足四大属性:
- Well-defined(可解):任务前提成立(如主管人确实买过T-shirt,最后一单还在售)
- 有Distractors(干扰项):加很多类似但无关的订单、邮件、播放列表,逼代理必须仔细查找和推理
- 有Hurdles(障碍):比如默认支付卡已过期,必须换另一张;或库存不足需选择替代方案
- 形成Contrast Set:同一模板的不同任务覆盖不同情况(如一种任务优先色有货,另一种没货),测试代理的鲁棒性
-
Evaluation程序
- 不比较执行轨迹(因为正确解法可能多种多样),而是基于最终数据库状态做程序化断言。
- 计算数据库diff(哪些行增删改),检查:
- 必须发生的关键变化(如新下了一单,且商品是T-shirt)
- 只允许某些可选变化(如购物车可以清空也可以恢复原状)
- 禁止任何未允许的“附带损害”(collateral damage,如误删愿望单、误退款)
- 平均每个任务8个断言,最多22个。15%是问答任务,有固定答案。
-
Validation Solution
- 写一个完整参考代码解法(允许使用少量内部知识,如笔记格式的正则)
- 端到端验证:从任务初始状态运行参考解 → 必须通过所有Evaluation断言
- 保证任务确实可解,且未来改动不会破坏
这种生成方式非常聪明:既保证了任务多样性、难度和可评估性,又通过程序化方式保持高质量。
3. 任务难度到底有多高?
- 平均用1.8个App,最多6个
- 平均调用9.5个API,最多26个
- 平均代理代码50行,最多134行
- 需要循环、条件判断、异常处理、根据环境反馈调整策略
实验结果:
- GPT-4o + ReAct 在Normal测试集上只有48.8%完全正确,Challenge集30.2%
- GPT-4-Turbo差一大截(32.7%/17.5%)
- 开放模型更低
- 加上“scenario-based”鲁棒性评估(同一场景所有变体都正确才算),GPT-4o掉到32.1%/13.0%
说明当前最强模型在真正需要交互式编码 + 复杂控制流 + 环境适应的任务上,还差得很远。
总结:为什么这个基准值得关注?
AppWorld不是简单堆任务,而是从底层模拟器到任务生成、评估体系都做了极致的工程化设计(总共10万+行代码,14个月开发)。它真正填补了“复杂多App交互编码代理”这一块的空白,难度高、可控性强、评估客观公正。
对研究者来说,这是一个能切实推动交互式代理能力上限的新挑战;对工程人员来说,里面的很多设计思路(可控环境、状态diff评估、程序化任务生成)也值得借鉴。
论文地址:https://arxiv.org/abs/2407.18901
代码开源:https://github.com/stonybrooknlp/appworld
强烈推荐对Agent、Tool Use、LLM编码能力感兴趣的同学读一读原论文,细节远比我这里讲的更丰富!
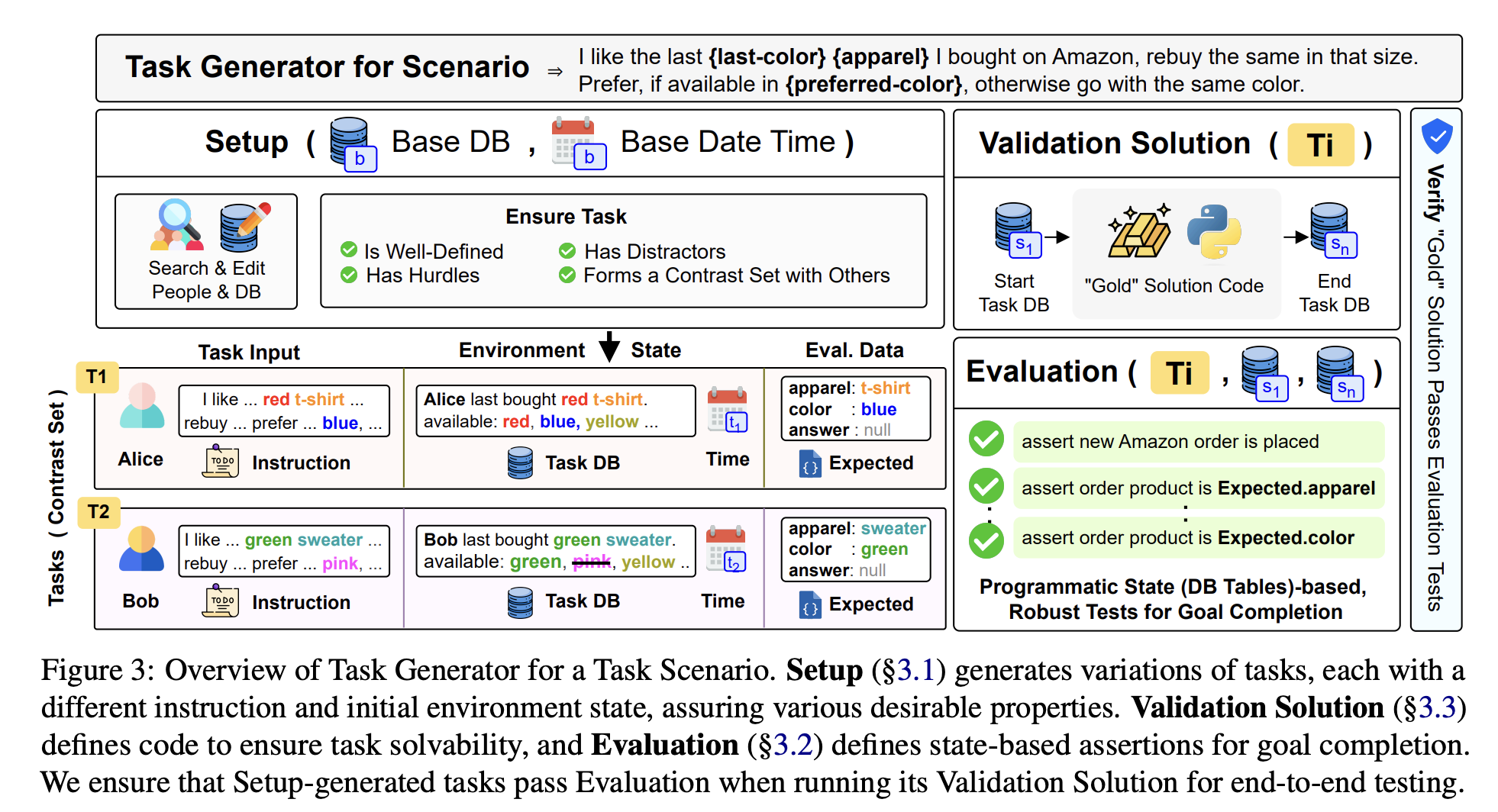
AppWorld基准的任务生成算法详细解释
AppWorld论文中最精妙的的部分就是任务生成算法(Task Generation Algorithm)。他们没有手动编写750个任务,而是设计了一种半自动化、程序化的生成 pipeline,通过Task Scenario(任务模板) + Task Generator(任务生成器模块) 来批量产生高质量、多样化的任务。这确保了任务的自然性、难度一致性和可控性,同时避免了众包或纯LLM生成带来的噪声和不一致。
核心组件是Task Generator,论文中用Figure 3展示了其整体概览:一个流程图,包含Setup、Evaluation、Validation Solution等模块。下面我结合论文文本和Figure 3,逐步详细拆解这个算法。
1. 总体架构:Task Generator 的组成
每个Task Scenario(共250个)对应一个独立的Task Generator模块,这个模块包含三个主要程序(都是作者手写的Python代码,总计40K行):
- Setup 程序(核心生成部分,§3.1)
- Evaluation 程序(评估部分,§3.2)
- Validation Solution 程序(验证部分,§3.3)
生成流程是:Setup → 生成多个任务变体 → 用Validation Solution端到端测试 → 确保通过Evaluation。这形成了一个闭环,保证每个生成的任務都是可解的、难度合适的。
Figure 3的结构(从左到右):
- 左侧:输入(Task Scenario模板、Base DB、Base Date Time)
- 中间:Setup程序执行,输出多个Task变体(不同指令 + 不同初始状态)
- 右侧:Evaluation(状态断言)和Validation Solution(参考代码解法),绿色勾表示通过测试。
2. 核心算法:Setup 程序的详细步骤
Setup 是任务生成的核心算法。它为每个Scenario生成3个任务变体(总750=250×3)。
输入:
- Task Scenario:一个带占位符的自然语言模板,例如:
“I like the last {last-color} {apparel} I bought on Amazon, repurchase the same in that size. Prefer {preferred-color}, if available; otherwise, go with the same color.”
- Base DB:预先生成的共享数据库(模拟100个用户的历史活动,~37万行)
- Base Date Time:基础日期时间(任务可能依赖当前日期,如“今天”)
算法步骤(论文第4-5页详细描述):
-
选择Supervisor(主管人):
- 从100个虚构用户中随机或根据Scenario要求选一个作为任务执行对象(Supervisor SiS_iSi)。
- Supervisor是任务的“主人”,所有操作都在其账号下进行(确保隐私和权限控制)。
-
填充模板占位符,生成具体指令 IiI_iIi:
- 选择有效的占位符值组合,例如 {apparel} = “T-shirt”, {last-color} = “blue”, {preferred-color} = “red”。
- 必须确保这些值“有效”(即在当前DB状态下有意义,后续会修改DB来保证)。
-
创建Task DB副本并进行任务特定修改:
- 复制Base DB得到 DisD_i^sDis(任务初始数据库状态)。
- (可选)调整当前时间 tist_i^stis(用freezegun冻结时间)。
- 在这个副本上执行一系列程序化修改,确保生成的每个任务同时满足四大关键属性:
- (1) Well-defined(定义良好、可解):
- 任务的所有前提假设必须在初始状态中成立。
- 示例:Supervisor必须有过去的T-shirt订单,且最近一单的商品还在售,且有指定颜色可用。
- (2) Has Distractors & Hurdles(有干扰项和真实障碍):
- 故意添加大量类似但无关的数据,迫使代理必须仔细搜索和推理。
- 示例:添加多笔T-shirt订单(不同颜色、尺寸),多个类似邮件/消息;默认支付卡过期(hurdle),迫使代理换卡。
- (3) Forms Contrast Set(形成对比集):
- 同一Scenario的3个变体覆盖不同条件,测试代理的鲁棒性。
- 示例:变体1:优先色(red)有货;变体2:只有原色(blue)有货;变体3:某种障碍不同。
- 注意:每个Scenario的需求独特,所以Setup代码是为每个Scenario量身定制的(不是通用模板),这也是为什么需要手写250个Generator。
- (1) Well-defined(定义良好、可解):
-
输出每个任务 TiT_iTi 的三部分:
- Task Input:Supervisor SiS_iSi + 指令 IiI_iIi(给代理的自然语言任务描述)。
- Environment State:Task DB DisD_i^sDis + 当前时间 tist_i^stis。
- Evaluation Data:预期变化 EiE_iEi(用于后续评估,不直接给代理)。
3. 为什么需要Evaluation 和 Validation Solution?
- Evaluation 程序:定义一组状态断言(平均8个,最多22个),检查最终DB diff 是否符合预期(必须变化 + 允许变化 + 无附带损害)。
- Validation Solution 程序:一个完整的参考代码解法(允许使用少量“内部知识”,如笔记结构的正则)。
- 端到端运行:从生成的Task DB起始,执行参考代码 → 必须通过所有Evaluation断言。
- 作用:确保任务确实可解;捕获未来改动(如API扩展)带来的bug。
Figure 3中用绿色勾和红色叉表示这个测试过程:只有通过了Validation → Evaluation的任務才被保留。
4. 算法的优势与工程细节
- 程序化保证质量:不像众包任务容易有噪声,这里所有修改都是通过可靠的API调用完成的,确保DB一致性。
- 多样性与难度控制:通过对比集和干扰项/障碍,强制代理需要交互式推理、处理异常、适应不同情况。
- 可扩展性:想加新任务只需写新Scenario的Generator。
- 工程量:250个Generator手写+调试,花了大量时间,但换来极高可靠性。
总结来说,这个任务生成算法是一个高度工程化的、闭环的程序化pipeline:从模板出发,通过定制化的Setup修改DB状态,生成满足严格属性的变体,再用参考解+状态评估验证。通过这种方式,AppWorld实现了“工业级”基准任务的批量生产,这也是它难度高、评估公正的关键原因。
如果你想看具体某个Scenario的Generator代码实现,可以去GitHub仓库(https://github.com/stonybrooknlp/appworld)查看,里面有详细示例!
代码
运行总是报错
pip install appworld # 安装包
appworld install # 解密并解压核心代码(必须)
AppWorld Engine 是怎么用代码实现的?——小白也能听懂的通俗讲解
你问的“AppWorld Engine”就是论文里那个超级厉害的虚拟手机世界(图2左边那部分)。它里面有9个假的日常App(亚马逊、Spotify、Gmail、Venmo转账等),你可以用代码去操作它们,就像真的在手机上点来点去一样。
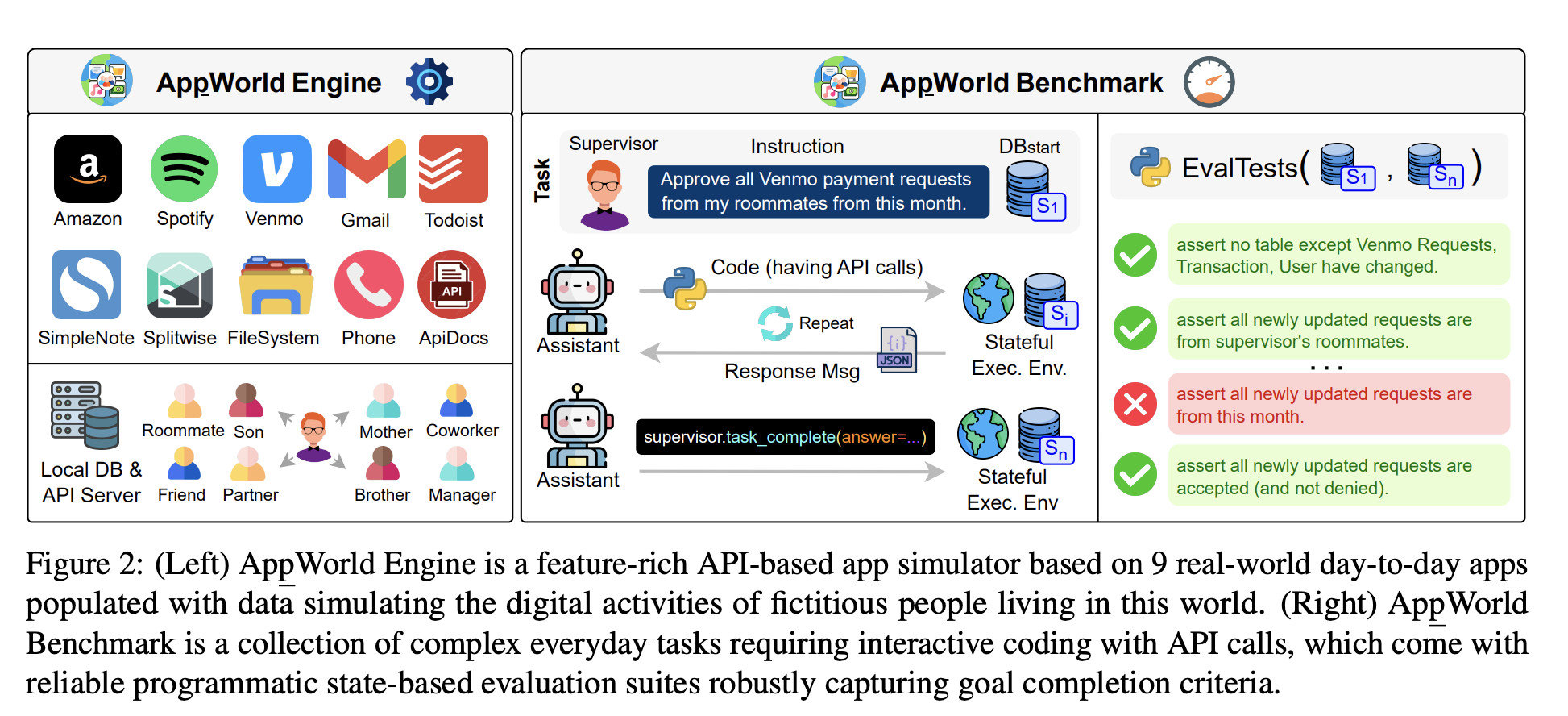
作者花了6万多行代码、14个月时间,把这个“假世界”做得特别真实、稳定、安全。下面我用最最通俗的话,一步步告诉你它到底是怎么用代码搭起来的。
1. 整体就像一个“超级智能的玩具手机”
想象你小时候玩的那种玩具手机,按按钮会发出声音、显示东西。但这个玩具手机超级高级:
- 里面有9个App,能真的“做事”(发邮件、买东西、放歌、转账)
- 所有数据都存在一个“笔记本”(数据库)里
- 你可以用写Python代码的方式来“按按钮”(调用API)
2. 核心部件:3个最重要的技术拼在一起
作者用了3个现成的强大工具,像搭积木一样拼成了AppWorld Engine:
① FastAPI(做“按钮”)
- 这是Python里很流行的做网站后台的工具。
- 作者用它把每个App的功能做成了“API接口”(就像一个个按钮)。
- 比如有一个接口叫
/spotify/login,你发个请求带密码,它就帮你登录Spotify。 - 总共做了457个这样的接口(按钮)。
② SQLite数据库(做“笔记本”记东西)
- 所有App的数据(你的歌单、购物车、邮件、转账记录)都存在一个SQLite文件里。
- 其实不止一个文件,好几个App各有自己的数据库文件。
- 当你“买东西”,其实是代码往数据库里加了一行“订单记录”。
- 当你“发邮件”,代码同时往发件人和收件人的邮件表里各加一行。
③ IPython(让你写代码操作这个世界)
- 这是一个可以一行一行执行Python代码的环境(就像Jupyter Notebook)。
- 最厉害的是:它有记忆!
- 你第一次写代码登录Spotify,拿到一个token变量,下一次代码还能继续用这个变量。
- 所以AI代理可以像人一样:先试试看、看到结果、再决定下一步写什么代码。
3. 最聪明的设计:三种方式玩,都一样方便
作者做了三种玩法,你可以选最舒服的:
最推荐:直接像调函数一样用(最简单)
apis.spotify.login(password="123456") # 登录
apis.spotify.list_playlists() # 列出歌单
apis.amazon.search_products(keyword="T恤") # 搜商品
看起来就像在调普通的Python函数,其实后台自动帮你转成网络请求去操作数据库。
老派方式:发HTTP请求(像真App那样)
requester.post("/spotify/login", json={"password": "123456"})
这和真实世界里App跟服务器通信一模一样。
内存超级快模式(默认)
所有东西都在同一个Python程序里跑,不走网络,速度飞快,几毫秒就出结果。
4. 怎么保证安全、不乱来?
因为AI可能会写出危险代码(比如删文件、死循环),作者加了很多保护:
- 不允许import os、sys这些危险库
- 不允许用time.sleep太久、exit退出等
- 代码运行有时间限制,超时就停
- API如果参数错、没权限,会直接报错,而不是悄悄失败
5. 时间和状态怎么控制?
- 用了一个叫freezegun的库,可以“冻结”时间。
- 比如某个任务要求“今天是周二”,就冻结成周二,保证每次跑都一样。
- 每次开始新任务,都把数据库恢复到一开始的状态,保证公平。
6. 一个完整的小例子(你也可以自己跑)
from appworld import AppWorld
# 打开一个任务的虚拟世界
with AppWorld(task_id="某个任务ID") as world:
# 第一步:看看我有哪些便签
world.execute("""
notes = apis.notes.list_notes()
for note in notes:
print(note['title'])
""")
# 第二步:找到健身计划,算出今天要运动多久
world.execute("""
# 假设上一步看到了标题,就找到那张便签内容
content = apis.notes.get_note(note_id=123)['content']
duration = int(content.split("minutes")[0].split()[-1])
print("今天要运动", duration, "分钟")
""")
# 第三步:找一个够长的歌单播放
world.execute("""
playlists = apis.spotify.list_playlists()
for p in playlists:
if p['total_duration'] >= duration:
apis.spotify.play_playlist(p['id'])
break
""")
每一次execute就是AI“想一会儿、写段代码、试试看”的过程。
总结:AppWorld Engine 就像……
一个用Python搭起来的超级逼真的玩具手机世界:
- 用FastAPI做了几百个“按钮”(API)
- 用SQLite当“内存”记所有东西
- 用IPython让你能一行一行写代码操作
- 还加了各种保护和重置功能,保证公平稳定
正是因为它搭得这么精细、真实,所以现在的顶级大模型(GPT-4o)也才只能对一半任务,说明AI离真正像人一样用App还差得远呢!
如果你想自己玩,超级简单:
- pip install appworld
- appworld download data
- appworld play # 打开浏览器就能手动试玩
有兴趣我可以一步步教你跑起来~
后记
2025年12月30日于上海,在grok fast辅助下完成。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献234条内容
已为社区贡献234条内容

所有评论(0)