Panoptic Captioning: An Equivalence Bridge for Image and Text(NeurIPS 2025)
本文提出全景字幕新任务,旨在生成图像的全面文本描述。针对现有MLLM的局限性,研究设计了PancapEngine数据引擎(通过多检测器识别实体并生成高质量数据)和PancapChain方法(分四阶段生成字幕:实体定位、标签分配、补充发现、最终生成)。同时提出PancapScore评估指标(涵盖五个语义维度)和SA-Pancap基准测试(含人工标注测试集)。实验采用LLaVA架构,结果显示该方法能有
研究方向:Image Captioning
1. 论文介绍
本研究提出了一种名为全景字幕的新任务,旨在寻求图像的最小文本等效表示 。通过将其构建为生成图像全面文本描述的任务,迈出了实现全景字幕的第一步。
由于MLLM在解决全景图像描述任务方面的性能有限,本文提出了一个高效的数据引擎PancapEngine来生成高质量数据,并提出了一种新方法PancapChain来改进全景字幕。
1)具体而言,PancapEngine首先通过一个精细的检测套件检测图像中的各类实体,然后使用实体感知的提示生成所需的全景字幕。
2)此外,PancapChain明确地将具有挑战性的全景字幕任务分解为多个阶段,并逐步生成全景字幕。
3)还提出了一个全面的评价指标PancapScore和一个人工策划的测试集,用于可靠地评估模型。

将全景字幕任务表述为生成一个全面的文本描述(见上图左上角),全面性捕捉基本语义元素(例如,中心的狗),同时为了简洁性排除不太关键或微妙的细节(例如,地面上的微小颗粒)。
与目前通过纯文字模糊指定位置的字幕工作(例如,BLIP-2的简短字幕和ShareGPT4V的详细字幕)不同,我们的全景字幕以其文本的全面性脱颖而出。通过使用边界框准确定位实体实例。
上图(底部)显示我们的全景字幕器因更好的全面性,在从字幕进行图像“重建”方面表现得更好。
上图(右上方)显示现有的MLLMs和我们的方法在全景字幕方面的表现
2. 方法介绍
2.1 任务定义
在这项工作中,我们将全景字幕生成定义为给定图像的综合文本描述生成任务,该描述包含所有实体实例、它们各自的位置和属性、实例间的关系,以及全局图像状态。
具体来说,我们将全景标题中的语义内容分为五个维度,详细说明如下:
语义标签:分配给图像中每个实体实例的类别标签,将“实体”定义为可数对象(如人和动物)以及非形态区域(如草、天空和道路)。
位置:实体实例的空间位置,以边界框的形式表示。
属性:描述实体实例外观、状态或质量的特性或属性。属性维度涵盖广泛的语义内容类型,例如颜色、形状、材料、纹理、类型、文本渲染。
关系:图像内不同实体实例之间的连接或互动。关系维度涵盖了多种语义内容类型,例如位置关系(如A在B后面)、部分-整体关系(如A是B的一部分)以及动作关系(如A踢B)。
全局图像状态:图像的整体特征,提供对其内容的全面理解。
2.2 评估指标 PancapScore
包括标注、定位、属性、关系和全局状态这五个维度F1的分数
给定一张图片,PancapScore使用真实字幕作为参考,评估生成的全景标题的质量。首先从标题中提取所有语义内容,并将它们分为五个维度。基于提取的语义内容,PancapScore通过实体实例匹配来评估语义标签和实例定位。然后,PancapScore以问答的方式评估属性、关系和全局状态,并最终综合考虑所有五个维度获得总分。
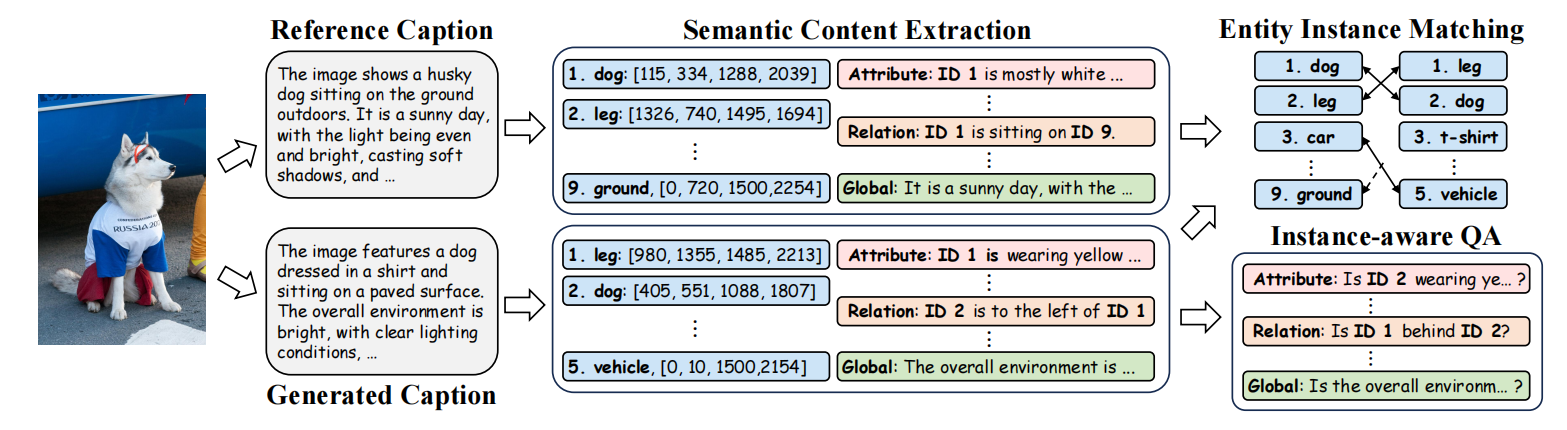
2.3 自动化数据引擎 PancapEngine
自动化数据引擎,以生成高质量的数据。首先使用一套精细的实体检测套件来检测图像中多种类别的实体。然后,我们采用最先进的MLLMs利用实体感知的提示生成全面的全景式字幕,通过不同MLLMs之间的字幕一致性确保数据质量。
实体检测套件:
1)首先使用类无关检测器OLN来检测实体实例,得到的区域集合记为R。
2)然后,通过图像标签模型RAM为各个区域分配语义标签。对于R中的每个区域,我们从图像中裁剪出该区域并输入到RAM中获取其语义标签。
3)此外,整合了两个专门的类感知检测器(Grounding-DINO和OW-DETR),识别被OLN遗漏的实例。将OLN检测到的所有实体类别进行汇总,并将这个汇总的类别集作为输入提示提供给Grounding-DINO和OW-DETR,以实现类感知的检测。类感知检测器得到的区域集合记为R′。
4)接着,将两个集合R和R′合并,并根据交并比(IoU)去除冗余区域。由于不同检测器产生的置信度分数范围各异,我们不使用非极大值抑制来移除冗余提议。
基于图像中检测到的实体实例,构建实体感知的提示,并指导MLLMs生成全景式字幕。
如果Gemini-Exp-1121生成的字幕与相应的Qwen生成的字幕一致性低,就将其丢弃。
2.4 SA-Pancap基准测试
选择SA-1B作为数据源。SA-Pancap基准测试包含9000张训练图像和500张验证图像,这些图像都配有自动生成的全景描述字幕;还有130张测试图像,配有人类策划的全景描述字幕。
2.5 PancapChain

通过四个阶段生成全景字幕A,即实体实例定位、语义标签分配、额外实例发现、全景字幕生成,分别表示为。
实体实例定位():对于图像
,我们从真实字幕A中提取实例的边界框,并构建一个图像-文本对{
}用于训练。
是由所有实例的边界框组成的定位文本,用逗号连接。
语义标签分配():基于定位文本,提出对定位的实体实例分配语义标签。为此,从真实字幕中提取实例的语义标签,每个标签与一个边界框相关联,然后构建一个图像-文本元组{
}用于训练。
是由所有实例的语义标签和边界框组成的实例文本,用逗号连接。
额外实例发现():由于一张图片包含众多实体实例,一次性识别所有实例并非易事。因此,引入了一个额外的阶段来检测在前两个阶段中被遗漏的实例。
具体来说,对于图像,我们构建一个用于训练的图像-文本元组{
},训练时将
随机分为
(已发现的实例的框和标签)和
(待发现的其它实例)两部分。
模型的输入包含图像 + ,但不包含
;模型需要基于图像和
预测缺失的实例(输出
);训练时把模型输出
与
(ground truth)比较。
全景观觉字幕生成():基于早期阶段识别的实体实例生成全景观觉字幕。构建一个用于训练的图像-文本元组{
},A是图像的真实全景观觉字幕。在推理时,首先汇总初始实例文本
和额外实例文本
,并将汇总后的实例文本包含在提示中以预测字幕
。
PancapChain的训练损失公式为:,其中L(⋅,⋅)表示遵循LLaVA的标准自回归损失。在这四个阶段中使用了不同的提示来指导模型训练。在推理过程中,我们的模型根据提示逐步生成字幕。
3. 实验
模型采用了通用的LLaVA架构,并使用预训练的ASMv2-13B检查点进行初始化。我们使用LoRA在我们的SA-Pancap训练集上对模型进行了两个周期的微调。对于PancapScore,我们使用Qwen2.5-14B作为LLM来提取语义内容和回答问题。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)