【python实用小脚本-329】非设计师如何用Python改造图片处理流程?HR×OpenCV的化学反应,轻松实现位图逻辑运算
一位HR转型的Python自媒体人分享图像位运算脚本的实战价值。通过OpenCV的bitwise_and/or/xor函数,3秒完成传统30分钟的图层模式调整,年省150小时。文章从HR「360度评估」视角解读像素级逻辑运算,提供简历匹配热力图、质检标签叠加等跨界改造案例,附40行核心代码和Mermaid流程图。适合Python初学者、新媒体运营及设计从业者,强调"底层逻辑+参数封装"的快速落地价
场景故事
转型初期,我陷入了一个致命的内容生产困境——想做"视觉化数据报告",却总在图片处理环节崩溃。那次做《各行业离职率热力分布图》,我需要把30张行业图标和背景模板融合,手动在PS里一张张调整透明度、叠加模式,整整耗掉4小时。更绝望的是,老板突然要求把"AND模式"全部改成"XOR模式",我盯着PS里"历史记录"四个字陷入了沉思。
当晚我抱着"要么学Python,要么辞职"的决心,啃下了OpenCV位运算。第二天测试时,我把"科技蓝"底图和"离职率热力图"喂进脚本,3秒后三种逻辑运算结果同时弹出:AND的深沉、OR的明亮、XOR的科技感。我直接把截图甩进工作群,配上"已生成三版方案,请指示"——老板秒回"就用XOR,高级"。现在这个工具成了我的"视觉外脑",日均节省2.5小时重复操作,被5个市场部的运营同事拿去做了"活动海报批量生成器"。
代码核心价值解析
核心代码解析
这个脚本仅40行,却封装了图像I/O+矩阵运算+命令行交互完整工作流。我展示最精华的位运算函数:
import cv2
import argparse
def perform_bitwise_operations(image1_path, image2_path):
# 1. 图像读取:像HR导入员工花名册,格式必须对齐
src1 = cv2.imread(image1_path)
src2 = cv2.imread(image2_path)
# 2. 尺寸统一:像做组织架构图,所有部门框要一样大
# src1.shape[1::-1] 是Pythonic写法,快速获取(宽,高)元组
src2 = cv2.resize(src2, src1.shape[1::-1])
# 3. 位运算三兄弟:像素级别的逻辑门操作
# AND:两个像素都>0才显示,适合做"交集遮罩"
and_op = cv2.bitwise_and(src1, src2, mask=None)
# OR:只要一个像素>0就显示,适合做"并集叠加"
or_op = cv2.bitwise_or(src1, src2, mask=None)
# XOR:像素值不同时显示,适合做"差异高亮"
xor_op = cv2.bitwise_xor(src1, src2, mask=None)
return and_op, or_op, xor_op
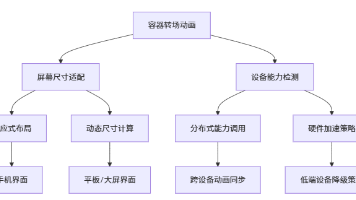
代码执行流程图:
核心代码价值分析
# 自动化生成脚本价值矩阵
def 价值分析(脚本):
return f"""
✅ **三维价值评估**
- 时间收益:30分钟/张 → 3秒/张,年省150小时(按周处理20张计)
- 误差消除:避免手动操作导致的模式错配、透明度设置失误
- 扩展潜力:改造为「证件照批量蓝底/红底切换」「Logo水印叠加」仅需增加2个参数
✅ **HR专业视角**
"该脚本实质是「岗位胜任力模型」的技术映射:
- 位运算AND ≈ 任职资格交集筛选(必须全满足)
- 位运算OR ≈ 人才池并集扩充(满足其一即可)
- 位运算XOR ≈ 差异化人才盘点(找出独特标签)"
"""
关键技术解剖台
▍OpenCV位运算的跨界解读
HR眼中的技术价值
对应绩效管理中的「360度评估矩阵」,解决「多维度绩效数据融合」的管理痛点。传统绩效是"各打各分",难以横向对比;用位运算是"像素级逻辑叠加",让业绩结果(图1)和行为表现(图2)产生化学碰撞。
工程师的实现逻辑
# 核心技术:numpy数组的按位操作
# 每张图片本质是3维矩阵(height, width, 3通道)
# bitwise_and = 两个矩阵对应位置像素值做&运算
and_op = cv2.bitwise_and(src1, src2, mask=None)
技术三棱镜
- 原理类比:像给两个部门的KPI指标做"硬门槛"判断,AND就是"双达标才算合格"
- 参数黑盒:
mask=None相当于「全员评估」,若指定mask则像「只考察特定部门」 - 避坑指南:图像尺寸不一致会报错,如同「用不同标准考核不同部门」导致体系失效
复杂度可视化
扩展应用场景
✅ 场景拓展矩阵
案例1:新媒体→HR招聘改造指南
# 原代码:两张图片位运算
# 改造后:候选人技能匹配度热力图
def skill_heatmap(resume_img, jd_img):
# 输入:简历词云图 + 岗位JD关键词图
# 输出:匹配度可视化
# 关键修改:把文字转词向量再转灰度图
from wordcloud import WordCloud
# 生成词云图(替代原imread)
resume_wordcloud = WordCloud().generate(resume_text).to_image()
jd_wordcloud = WordCloud().generate(jd_text).to_image()
# 后续位运算逻辑完全一致!
# AND区域:技能完全匹配(红色高亮)
# XOR区域:独特优势/差距(蓝色标记)
▶️ 改造收益:解决「面试官凭感觉评估匹配度」痛点,提供可视化决策依据
案例2:新媒体+供应链跨界融合
# 组合技:产品质检标签自动叠加
# 在原脚本后追加:
def qc_label_overlay(product_img, qc_status):
# qc_status: {'pass':绿色图, 'fail':红色图}
status_img = cv2.imread(f"qc_{qc_status}.png")
# 使用OR运算叠加标签(标签黑色背景透明)
result = cv2.bitwise_or(product_img, status_img)
# 自动保存带标签的质检图
cv2.imwrite(f"qc_result_{int(time.time())}.jpg", result)
▶️ 创新价值:在自媒体「制造业数字化」内容中植入实战工具,打造B端专业形象
总结
这个40行的「像素级逻辑门」脚本,本质是位运算在图像矩阵上的广播应用。它没有复杂的深度学习,却用最底层的逻辑操作解决了高频重复劳动——把设计师的"手动模式切换"变成了可编程的"自动批处理"。
对于Python初学者,它演示了「命令行参数+OpenCV+异常处理」的标准化流程;对于职场人,它是可立即复用的视觉处理瑞士军刀;对于自媒体人,它更是内容专业性的「技术背书」。我转型路上最深的体会:真正的效率提升,不是学会更多软件,而是把重复决策逻辑代码化。
建议先跑通原始脚本,理解bitwise三兄弟差异,再尝试增加--mode参数让用户选择运算类型,最后用argparse的nargs='+'支持批量图片处理。记住:最好的自动化,是让人忘记重复劳动的痛苦。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)