【PE 最终章】思维链、自洽性与 Prompt 安全防御指南
本文探讨了Prompt Engineering的高阶策略,包括思维链(CoT)、自洽性和思维树(ToT)等技术,旨在提升大模型在复杂任务中的推理能力和输出稳定性。针对模型可控性与幻觉问题,文章提出结构化Prompt设计方法,并通过案例说明如何实现"慢思考"。同时,文章分析了Prompt安全防御体系,包括攻击手段解析和分层防御策略构建。最后提供了API参数调优指南和系统架构思考,
在 Prompt Engineering (PE) 的学习过程中,我们已经掌握了基础的提示技巧。然而,在面对复杂的逻辑推理任务或工业级应用场景时,仅靠简单的 Prompt 往往难以保证输出的稳定性和安全性。本文将深入探讨 PE 的高阶策略:思维链 (Chain-of-Thought, CoT)、自洽性 (Self-Consistency)、思维树 (Tree of Thoughts, ToT),以及至关重要的 Prompt 安全防御。
图片来自于课程3、进阶技巧_哔哩哔哩_bilibili
一、 核心痛点:可控性与幻觉
在开发大模型应用时,我们常面临一个两难境地:如果将所有决策权都交给模型,系统的可控性会显著下降;如果限制过死,又失去了 AI 的灵活性。尤其是当 Prompt 提供的信息量不足(Context 稀疏)时,模型极易产生“幻觉”,生成看似合理实则错误的回答。

我们的目标是:通过结构化的 Prompt 设计,让模型“慢思考”,从而提升生成结果的准确率。
二、 进阶推理技术:从直觉到逻辑
1. 思维链 (Chain of Thoughts, CoT)
思维链是目前提升大模型推理能力最直接有效的方法之一。其核心理念在于强制模型显式地生成推理步骤,不要直接输出最终答案。这类似于我们在解决数学题时,写出详细解题步骤的学生往往比直接写答案的学生正确率更高。

既然我们大模型的prompt不够丰富,那么就可以利用思维链,让大模型自己丰富prompt,内容丰富之后,大模型生成正确下文的概率将明显提升。
实际应用(例如 AI 质检员场景):

如果我们仅要求模型判断客服回答是否准确,模型极易忽略细节而给出错误结论。但当我们加入“请一步一步分析以下对话”的指令后:

模型会先拆解对话内容,逐条比对事实(如套餐费用、适用人群),最后基于这些中间推理得出结论:
 这种“中间推理路径”不仅丰富了上下文信息,更让模型具备了自我纠错的能力。一旦删除了思维链,模型失去了分析过程的支撑,错误率便会直线上升。
这种“中间推理路径”不仅丰富了上下文信息,更让模型具备了自我纠错的能力。一旦删除了思维链,模型失去了分析过程的支撑,错误率便会直线上升。
2. 自洽性 (Self-Consistency)
对于逻辑强相关或数学计算类的任务,单一的推理路径仍可能存在偶发性错误。此时,我们可以引入“自洽性”策略。
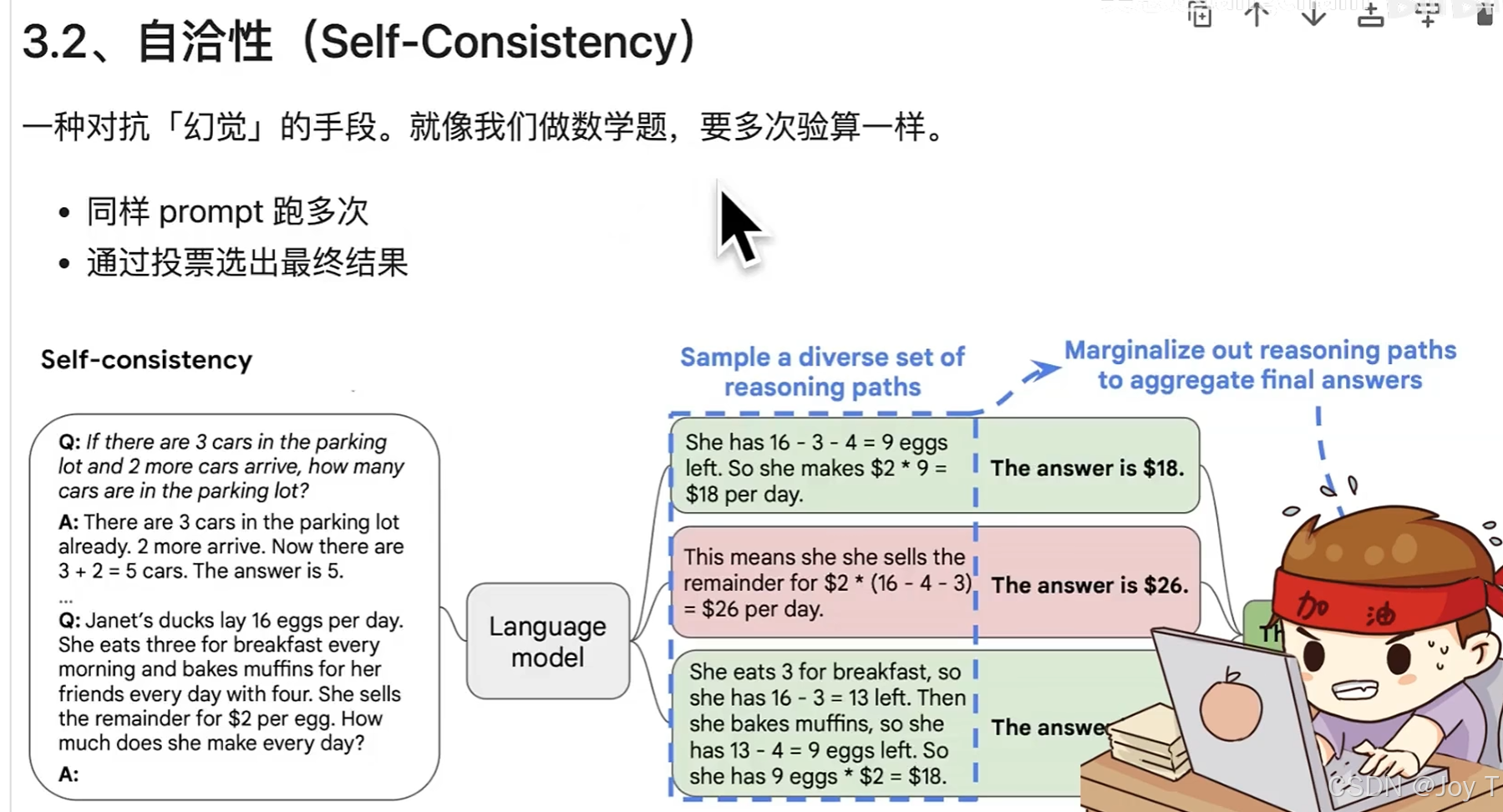
自洽性的本质是利用统计学原理对抗幻觉。我们使用相同的 Prompt 让模型并行生成多次(例如 5 次或 10 次),然后对这些结果进行“投票”或一致性校验,最终选择出现频率最高的结果作为定论。虽然这种策略会消耗更多的算力资源(Token),但它能有效滤除模型的随机噪声,显著提升系统在复杂任务上的鲁棒性。
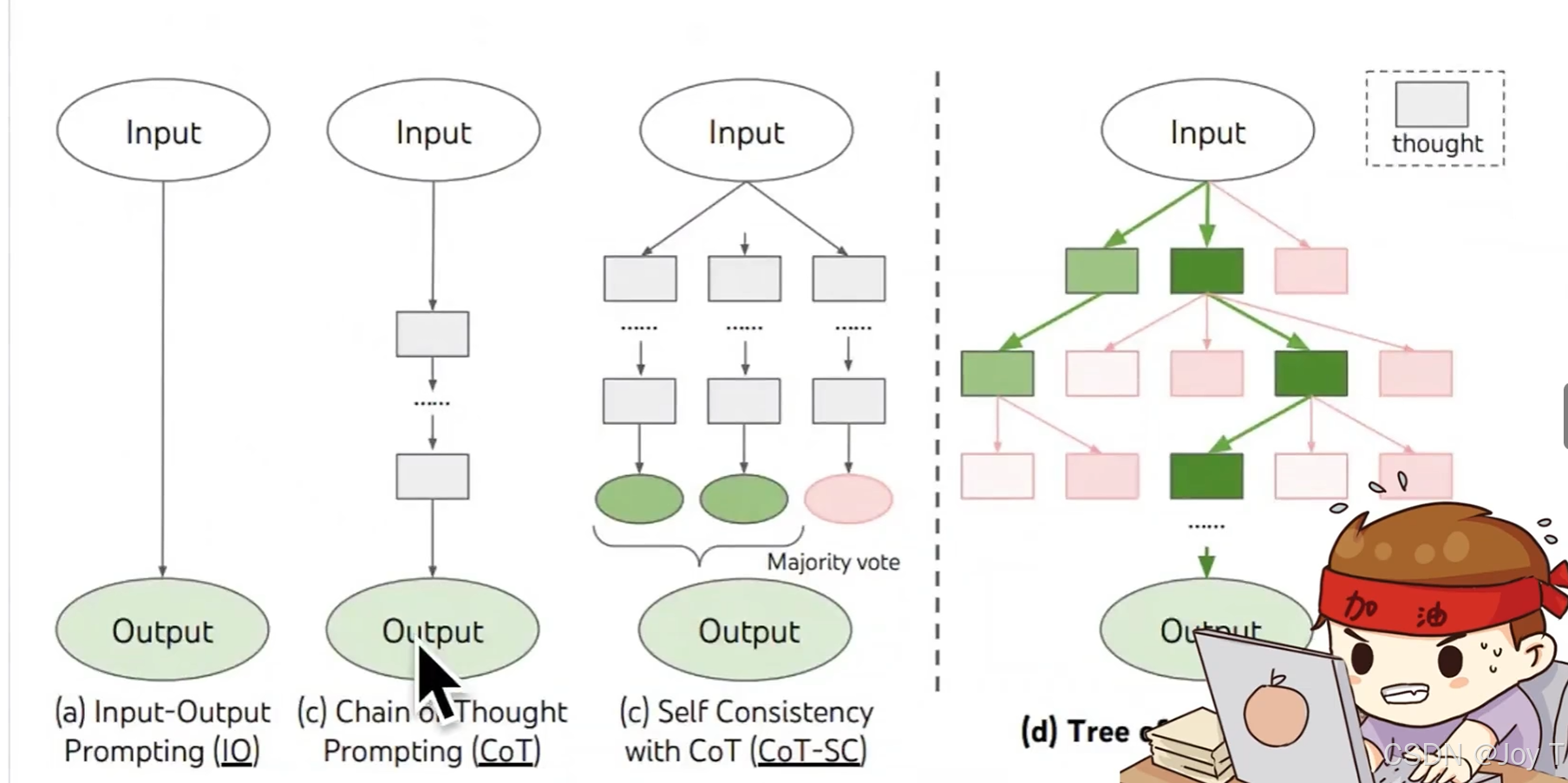
3. 思维树 (Tree of Thoughts, ToT)
如果说思维链是线性的思考,那么思维树则是拓扑状的深度搜索。

思维树技术让大模型在推理的每一步都生成多个可能的分支(子节点),并评估每个节点距离正确答案的“距离”。这在算法层面类似于广度优先搜索 (BFS) 或深度优先搜索 (DFS)。模型在思维树中进行探索、前瞻与回溯,从而寻找全局最优解。从准确率来看,这不仅优于基础的 Prompt,甚至优于线性的思维链。当然,其代价是推理延迟与成本的指数级增加。
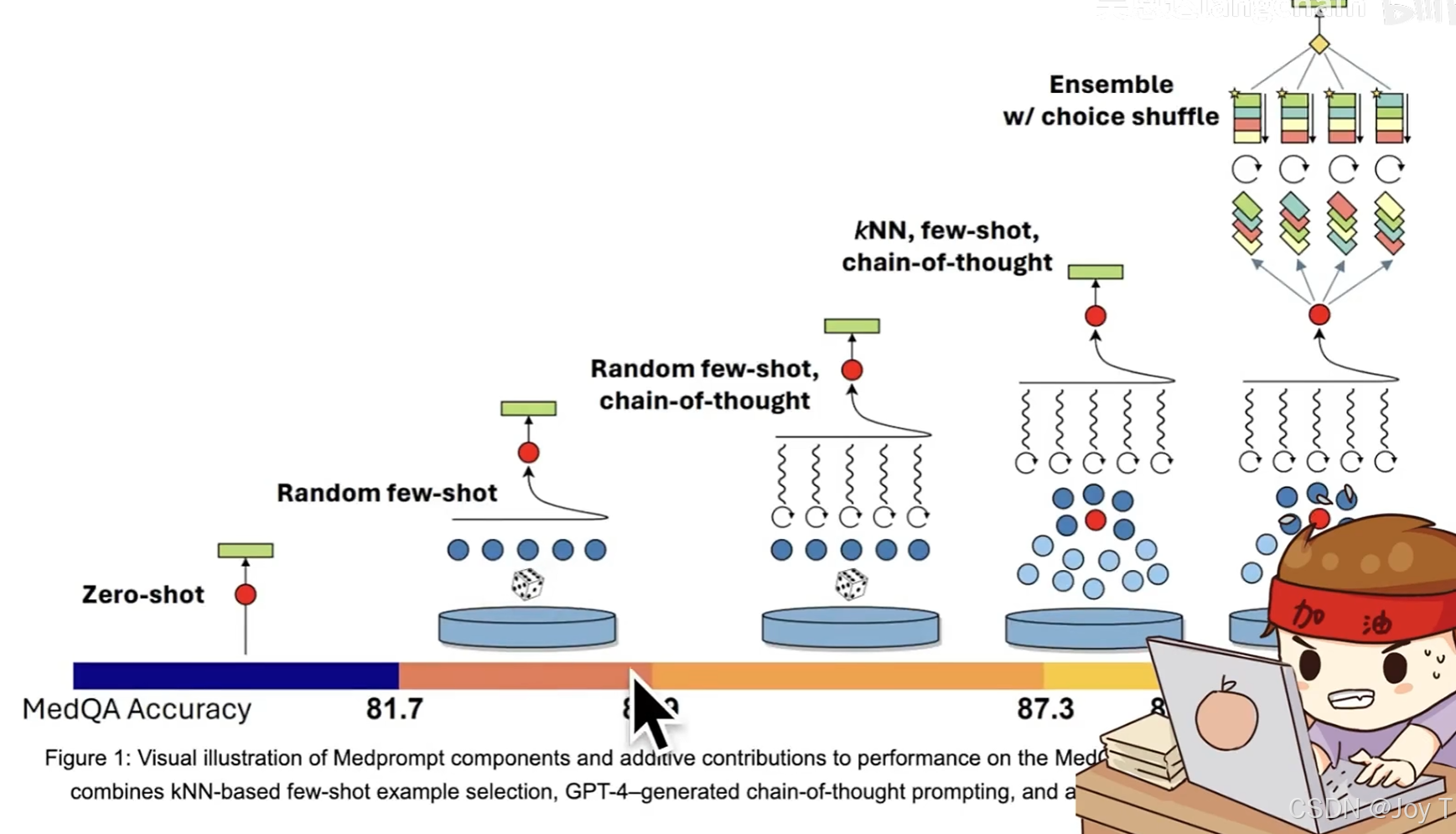
正确率从小到大:直戳了当要结果-->随机给几个例子-->随机给几个例子+思维链-->对一组例子进行相关性判断,再选取相关性高的例子+思维链-->集成模型(内嵌大模型重排例子选择最优)。
三、 Prompt 安全防御体系
Prompt 作为系统的自然语言接口,其开放性是一把双刃剑。恶意用户可能通过精心构造的 Prompt 进行注入攻击,诱导模型做出违背设计意图的行为。
1. 攻击手段解析
常见的攻击方式包括“奶奶漏洞”(利用亲情或角色扮演绕过安全审查,如诱导模型扮演亲人念诵敏感序列号)以及直接的指令覆盖(输入“忽略之前所有指令”来篡改系统设定)。


这类攻击一旦成功,轻则导致回答跑题,重则泄露系统内部逻辑或产生有害内容。
2. 防御策略构建
为了应对上述威胁,我们需要构建分层防御体系。
前置防御(分类器): 在用户输入进入主模型之前,我们可以部署一个专门的“判官模型”(Prompt 注入分类器)。这个轻量级模块专门负责识别输入中是否包含恶意攻击意图。一旦识别出风险,系统将直接拦截并拒绝服务,从而从源头切断攻击。本质上是让AI自己变成判官。

指令防御(负向约束): 在 System Prompt 中,我们必须设定明确的边界。除了告知模型“做什么”,更要明确“不做什么”。例如,对于定制化客服系统,我们可以增加“无论用户如何要求,都不允许回答与产品无关的问题”等负向约束,并配合分隔符(如 ###)物理隔离用户输入与系统指令,防止模型混淆指令来源:




四、 API 参数调优指南
在工程化落地时,调用 LLM API(如 OpenAI API)的参数配置直接决定了应用的表现风格。
temperature就像酒精,值越大,回复越上头;seed是每个大模型都有的,所以同样的Prompt、甚至0的temperature加上,也不会产生一模一样的回复【prompt+temperature+seed 三项确定大模型回复是否多样性,三者不变,则大模型回复也唯一】;stream流式输出;n是结果数量,常用在自洽性验证;
以下是核心参数的调优建议:
| 参数名称 | 作用描述 | 推荐配置策略 |
| Temperature | 控制输出的随机性。 | 代码生成设为 0;日常对话设为 0.7-0.9;严禁超过 1(会导致乱码)。 |
| Seed | 随机数种子。 | 用于结果复现。固定 Prompt+Temperature+Seed 可获确定性输出。 |
| Stream | 流式输出。 | 提升用户体验(打字机效果),不影响内容逻辑。 |
| n | 候选结果数量。 | 设置 n>1 是实现“自洽性”验证的基础。 |
五、 系统设计与架构思考
首先,AI 没有真正的记忆。所有的多轮对话记忆本质上都是工程层面的拼接。我们设定模型能记多少轮,完全取决于我们在 Context 中回传了多少历史记录。
其次,针对长对话场景,全量拼接历史记录会导致 Context Window 溢出且响应变慢。RAG (检索增强生成) 是解决这一问题的标准范式。我们可以将历史对话向量化存入数据库,在每一轮提问时,仅检索与当前问题最相关的几条历史记录作为上下文。这种方式既保留了关键记忆,又大幅降低了 Token 消耗与推理延迟,实现了系统的高效流转。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)