AI - Custom Agent 实战:当 Sequential / Loop / Parallel 都不够用了,该怎么办?
Custom Agent 实战
Custom Agent 实战:当 Sequential / Loop / Parallel 都不够用了,该怎么办?
- 一、什么是 Custom Agent?
- 二、为什么要用 Custom Agent?
- 三、Custom Agent 的核心:_run_async_impl
- 四、实战:StoryFlowAgent——“故事写作流水线”Orchestrator
- 五、项目结构 & 环境准备
- 六、第一步:定义 LLM 子 Agent
- 七、第二步:在 Custom Agent 里面组装 Loop + Sequential
- 八、第三步:在 _run_async_impl 中写完整工作流逻辑
- 九、第四步:root agent 启动 Web UI
- 十、第四步:实例化 StoryFlowAgent 并用 Runner 跑起来
- 十一、把 StoryFlowAgent 模式抽象一下
- 十二、什么时候该上 Custom Agent,而不是继续堆 WorkflowAgent?
在 ADK 里,我们已经实战过:
- 《AI - 使用 Google ADK 创建你的第一个 AI Agent》LlmAgent:一个模型 + 一段提示词,做一件事
- 《AI - SequentialAgent 实战:用 ADK 把「写代码 → 审查 → 重构」串成一条流水线》SequentialAgent:按顺序跑子 agent
- 《AI - LoopAgent 实战:用 ADK 做一个 “写作-批改-再写” 的迭代写作智能体》LoopAgent:在一组子 agent 上循环
- 《AI - ParallelAgent 实战:用并行工作流做一个「多主题 Web 调研」Agent》ParallelAgent:把子 agent 并行跑
多数业务场景,其实用这些预定义的 Workflow Agent 就够了。
但总有一些更“奇葩”的流程,比如:
- 先按顺序跑一堆步骤
- 跑完之后,根据中间结果做 if / else 分支
- 某些条件下又要重新从头再跑一遍某些步骤
- 中途还要去掉某些步骤、插入外部 API 调用……
这时候,就轮到 Custom Agent 出场了。
一、什么是 Custom Agent?
官方文档定义非常直接:
Custom Agent = 一个继承自 BaseAgent 的类,
在里面自己实现 _run_async_impl(Python)这个核心异步方法。
这句话拆解一下:
- 你写一个 Python 类 class MyAgent(BaseAgent): …
- 在里面实现一个方法:
async def _run_async_impl(
self, ctx: InvocationContext
) -> AsyncGenerator[Event, None]:
...
在这个方法里你自己决定:
- 什么时候调用哪些子 agent(self.xxx_agent.run_async(ctx))
- 怎么读取和写入 ctx.session.state
- 怎么用 if / for / while 写复杂控制流
- 想不想调用外部 API、数据库、本地代码库……
强调:Custom Agent 是一种 “高级用法”,在用它之前最好已经熟悉了 LlmAgent 和几种 WorkflowAgent。
二、为什么要用 Custom Agent?
几个典型理由:
-
复杂条件分支
- 比如:“如果 tone_check_result == “negative” 就重写故事,否则直接结束”。
- 这种跨好几步、基于状态做判断的逻辑,很难用纯 Sequential/Loop/Parallel 表达。
-
复杂状态管理
- WorkflowAgent 本身只表达“顺序/循环/并行”;
- 你如果需要对 ctx.session.state 做很多细粒度控制(缓存结果、多次决策),Custom Agent 更适合。
-
外部系统集成
- 想在中途访问数据库、REST API、调用你自己的 Python 代码库……
- 可以直接在 _run_async_impl 里写这些逻辑,让 LLM 和你自己的代码真正混在一个流程里。
-
动态选择下一个子 Agent
- 比如“根据前面步骤的结果动态选择哪个 Agent 接手”;
- 这已经超出固定拓扑(纯顺序、纯循环、纯并行)的能力范畴了。
-
独一份工作流
- 只属于你这个业务的流程,套不进任何一个标准模板。
一句话总结:
当你发现自己要写「if 某某结果,再跑这个 agent,否则跑另一个」,
基本上就可以考虑 Custom Agent 了。
三、Custom Agent 的核心:_run_async_impl
在 Python 版 ADK 里,Custom Agent 的灵魂就是这个签名:
async def _run_async_impl(
self, ctx: InvocationContext
) -> AsyncGenerator[Event, None]:
...
- ctx: InvocationContext
- 里面最重要的就是 ctx.session.state:
- 一个 dict,用来在多个步骤之间传数据
- 还有当前会话信息、调用分支等。
- 里面最重要的就是 ctx.session.state:
- 返回 AsyncGenerator[Event, None]
- 也就是说,你要 yield Event 给 runner:
- 大部分时候,这些 event 来自子 agent:
async for event in self.some_sub_agent.run_async(ctx):
# 你可以在这里做日志、过滤、改写……
yield event
你可以在这个方法里做三类事:
- 调用子 Agent
async for event in self.story_generator.run_async(ctx):
yield event
- 读写 Session State
story = ctx.session.state.get("current_story")
ctx.session.state["review_status"] = "pass"
- 写任意控制流
if ctx.session.state.get("tone_check_result") == "negative":
# 再跑一遍 story_generator
else:
# 什么都不做
这就是 Custom Agent 比工作流 Agent 更强的地方:你直接写 Python 控制整个流程。
四、实战:StoryFlowAgent——“故事写作流水线”Orchestrator
官方文档用一个很典型的例子来示范 Custom Agent:StoryFlowAgent。
我们要做一个「写故事 + 批改 + 检查语法和语气」的多步骤流水线:
- StoryGenerator:根据 topic 写一个小故事
- Critic:评审故事,给出改进建议
- Reviser:根据建议改写故事
- GrammarCheck:检查语法
- ToneCheck:判断故事整体语气(positive/negative/neutral)
- 如果语气是 negative,就重新生成一个新故事(而不是在旧故事上继续改)
这一看就不是简单的 “A→B→C” 或 “一直循环直到 XX”,有一个重要的条件分支:
如果 tone_check_result == “negative” 就再跑一遍 StoryGenerator,否则直接收工。
这个“先跑一堆,再根据状态决定是否重新生成”的逻辑,就非常适合用 Custom Agent。
五、项目结构 & 环境准备
建议目录结构是这样:
story_flow_agent_demo/
├─ agent.py # 定义所有 Agent + Custom Agent
└─ .env # 配置 google API Key 或 proxy gateway
└─ run_demo.py # 用 InMemoryRunner 跑起来(可选)
设置 python 虚拟环境安装依赖包:
python -m venv .venv
source .venv/bin/activate # Windows 用 .venv\Scripts\activate
pip install google-adk google-genai
六、第一步:定义 LLM 子 Agent
先把 5 个 LlmAgent 定义好,它们本身就是普通的 ADK LlmAgent,没啥“custom”的东西。
# agent.py (片段 1)
import logging
from typing import AsyncGenerator
from typing_extensions import override
import os
from google.adk.agents import LlmAgent, BaseAgent, LoopAgent, SequentialAgent
from google.adk.agents.invocation_context import InvocationContext
from google.adk.events import Event
from google.adk.models.lite_llm import LiteLlm
from google.adk.agents.callback_context import CallbackContext
from google.adk.models.llm_request import LlmRequest
import litellm
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# 使用 LN 代理,这样提供方由网关自动推断
litellm.use_litellm_proxy = True
endpoint = os.getenv("AI_GATEWAY_ENDPOINT")
tenant_key = os.getenv("AI_GATEWAY_TENANT_KEY")
agent_model = os.getenv("AGENT_MODEL")
if not agent_model:
raise ValueError("环境变量 AGENT_MODEL 未设置!请设置 AGENT_MODEL 环境变量。")
if not endpoint:
raise ValueError("环境变量 AI_GATEWAY_ENDPOINT 未设置!请设置 AI_GATEWAY_ENDPOINT 环境变量。")
if not tenant_key:
raise ValueError("环境变量 AI_GATEWAY_TENANT_KEY 未设置!请设置 AI_GATEWAY_TENANT_KEY 环境变量。")
proxy_model = LiteLlm(
model=agent_model,
api_base=endpoint,
api_key=tenant_key
)
def log_before_model(
callback_context: CallbackContext, llm_request: LlmRequest
):
"""在每次 LLM 调用前打日志,方便观察 Agent 执行顺序。"""
step = callback_context.state.get("_step", 0) + 1
callback_context.state["_step"] = step
logger.info(
f"=== Step {step}: Agent '{callback_context.agent_name}' 即将调用 LLM ==="
)
return None
# --- 1. 定义 5 个基础 LLM Agent ---
story_generator = LlmAgent(
name="StoryGenerator",
model=proxy_model,
before_model_callback=log_before_model,
instruction=(
"你是一名故事作者。"
"接下来用户会提供一个主题或一句话,请将其视为故事题材。"
"无论后续对话如何变化,如果需要重新生成故事,都必须始终围绕"
"用户最初提供的那个主题写一篇大约 50 词的短篇故事。"
),
input_schema=None,
output_key="current_story", # 写入 state["current_story"]
)
critic = LlmAgent(
name="Critic",
model=proxy_model,
before_model_callback=log_before_model,
instruction=(
"你是一名故事评论家。请审阅给定的故事:{{current_story}}。"
"请用 1-2 句给出有建设性的改进意见,"
"重点关注故事情节或人物塑造。"
),
input_schema=None,
output_key="criticism", # 写入 state["criticism"]
)
reviser = LlmAgent(
name="Reviser",
model=proxy_model,
before_model_callback=log_before_model,
instruction=(
"你是一名故事润色者。请根据以下内容进行修改:{{current_story}},"
"并参考评论中的意见:{{criticism}}。请只输出修改后的完整故事。"
),
input_schema=None,
output_key="current_story", # 覆盖 state["current_story"]
)
grammar_check = LlmAgent(
name="GrammarCheck",
model=proxy_model,
before_model_callback=log_before_model,
instruction=(
"你是一名语法检查助手。请检查以下故事的语法是否正确:{current_story}。"
"如果有问题,请只输出建议修改的地方和修改意见列表;"
"如果没有明显错误,请只输出 'Grammar is good!'。"
),
input_schema=None,
output_key="grammar_suggestions",
)
tone_check = LlmAgent(
name="ToneCheck",
model=proxy_model,
before_model_callback=log_before_model,
instruction=(
"你是一名语气/情绪分析助手。请分析以下故事的整体语气:{current_story}。"
"只输出一个词:如果整体情绪偏正面则输出 'positive',"
"如果整体情绪偏负面则输出 'negative',否则输出 'neutral'。"
),
input_schema=None,
output_key="tone_check_result", # 这个结果决定是否要重写
)
这里有两个关键点:
- output_key
决定每个 Agent 把结果写到 session.state 哪个 key 里。后面 Custom Agent 就要根据这些 key 来做决策。 - 模板占位符 {current_story} / {{current_story}}
- {current_story}:ADK 会用 state[“current_story”] 的值替换
- {{current_story}}:会从 state[“current_story”] 读
这是官方推荐的把 state 注入到 prompt 的方式。
七、第二步:在 Custom Agent 里面组装 Loop + Sequential
接下来定义一个 StoryFlowAgent,继承 BaseAgent。在 init 里做两件事:
- 把 LlmAgent 实例保存为成员属性;
- 创建内部的 LoopAgent 和 SequentialAgent,并通过 sub_agents 告诉 ADK “我的直系小弟有哪些”。
# agent.py (片段 2,接上文)
class StoryFlowAgent(BaseAgent):
"""
自定义的故事工作流 Orchestrator:
- 先生成故事
- 再在 critic + reviser 之间循环
- 再做 grammar + tone 的顺序检查
- 最后根据 tone 决定要不要重写一遍故事
"""
# Pydantic 字段(让 BaseAgent 帮你管理这些属性)
story_generator: LlmAgent
critic: LlmAgent
reviser: LlmAgent
grammar_check: LlmAgent
tone_check: LlmAgent
loop_agent: LoopAgent
postprocess_agent: SequentialAgent
# 允许保存任意类型(LlmAgent 等)
model_config = {"arbitrary_types_allowed": True}
def __init__(
self,
name: str,
story_generator: LlmAgent,
critic: LlmAgent,
reviser: LlmAgent,
grammar_check: LlmAgent,
tone_check: LlmAgent,
):
# 1. 在 __init__ 里先构造内部的 workflow agents
loop_agent = LoopAgent(
name="CriticReviserLoop",
sub_agents=[critic, reviser],
max_iterations=2,
)
postprocess_agent = SequentialAgent(
name="PostProcessing",
sub_agents=[grammar_check, tone_check],
)
# 2. 把所有会被 orchestrator 直接调度的 agent 放进 sub_agents 列表
# 这对框架内部的生命周期管理 / introspection 很重要
sub_agents_list = [
story_generator,
loop_agent,
postprocess_agent,
]
# 3. 调用 BaseAgent.__init__,把这些属性交给 Pydantic 管理
super().__init__(
name=name,
story_generator=story_generator,
critic=critic,
reviser=reviser,
grammar_check=grammar_check,
tone_check=tone_check,
loop_agent=loop_agent,
postprocess_agent=postprocess_agent,
sub_agents=sub_agents_list,
)
这里有几个点值得你记一下:
-
Field 声明 + model_config
- BaseAgent 底层用的是 Pydantic,这样写有利于验证 / 自动赋值。
-
为什么还要传 sub_agents?
- 虽然你在 _run_async_impl 里是直接用 self.story_generator 这些属性;
- 但框架需要知道:这个 Custom Agent 的“直属 Agent 树”有哪些,小到日志 / 监控,大到未来的自动路由都可能用到。
-
内部复用 WorkflowAgent
-
你完全可以在 Custom Agent 里再套 WorkflowAgent:
- loop_agent 用来在 critic/reviser 间循环;
- postprocess_agent 用来顺序执行 grammar_check / tone_check。
-
Custom Agent 不排斥 WorkflowAgent,反而是更高一层的 orchestrator。
-
八、第三步:在 _run_async_impl 中写完整工作流逻辑
现在是最关键的一步:我们自己描述整个工作流应该怎么跑——用标准的 async/await 和 if。
# agent.py (片段 3,接上文)
@override
async def _run_async_impl(
self, ctx: InvocationContext
) -> AsyncGenerator[Event, None]:
"""
真正控制整个故事工作流的地方。
"""
logger.info(f"[{self.name}] Start story workflow")
# 1) 生成故事初稿
logger.info(f"[{self.name}] Step 1: 调用 StoryGenerator 生成初稿")
async for event in self.story_generator.run_async(ctx):
# 这里只转发事件,不再打印详细 JSON,避免日志过多
yield event
# 如果没成功写入 current_story,就直接中止
if not ctx.session.state.get("current_story"):
logger.error(f"[{self.name}] 未生成故事,工作流中止。")
return
logger.info(f"[{self.name}] 初稿生成完毕")
# 2) 运行 critic + reviser 的循环(由 loop_agent 内部负责)
logger.info(f"[{self.name}] Step 2: 进入 CriticReviserLoop 进行评论和润色")
async for event in self.loop_agent.run_async(ctx):
yield event
logger.info(f"[{self.name}] 评论与润色完成")
# 3) 运行 grammar + tone 的顺序后处理
logger.info(f"[{self.name}] Step 3: 进行语法检查和情绪分析")
async for event in self.postprocess_agent.run_async(ctx):
yield event
# 4) 自定义条件逻辑:如果 tone 是 negative,就重生成故事
tone_result = ctx.session.state.get("tone_check_result")
logger.info(f"[{self.name}] 情绪分析结果: {tone_result}")
if tone_result.lower() == "negative":
logger.info(f"[{self.name}] Step 4: 情绪为负面,重新生成故事")
async for event in self.story_generator.run_async(ctx):
yield event
else:
logger.info(f"[{self.name}] 故事情绪不为负面,保留当前版本故事。")
logger.info(f"[{self.name}] Workflow finished.")
这段逻辑就是:
-
跑 StoryGenerator,在 state 里写 current_story。
- 如果没写成功,直接返回(中止流水线)。
-
跑 loop_agent(Critic + Reviser 循环),继续修改 current_story。
-
跑 postprocess_agent(Grammar + Tone),写入 grammar_suggestions 和 tone_check_result。
-
自己看一眼 ctx.session.state[“tone_check_result”]:
- 如果是 “negative”,再跑一遍 StoryGenerator(重新写一个故事,覆盖 current_story);
- 否则不动。
注意最后一步:
「根据 tone 的检查结果,决定要不要再生成一次故事」
这就是 Custom Agent 的核心价值:工作流中间插了一个“看状态再决定下一步”的 if 分支,而不仅仅是顺序/循环/并行。
九、第四步:root agent 启动 Web UI
给 root agent 赋值
# agent.py (片段 4,接上文)
# --- 创建 StoryFlowAgent 实例 ---
story_flow_agent = StoryFlowAgent(
name="StoryFlowAgent",
story_generator=story_generator,
critic=critic,
reviser=reviser,
grammar_check=grammar_check,
tone_check=tone_check,
)
root_agent = story_flow_agent # 为了兼容 ADK 工具,根 Agent 的变量名必须为 `root_agent`
就可以执行命令:
adk web --port 8001
等 adk web servier 启动起来后就可以访问 Web UI:http://127.0.0.1:8001 进行会话。
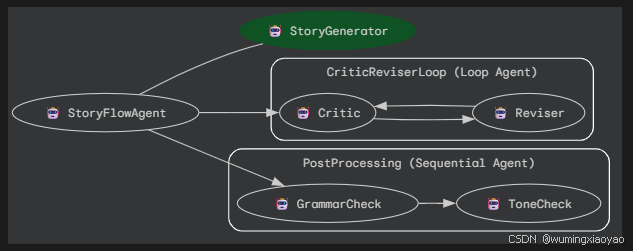
生成 2 次故事
用户输入:“请用中文帮我写一篇关于小蝌蚪找妈妈,结局悲观的故事”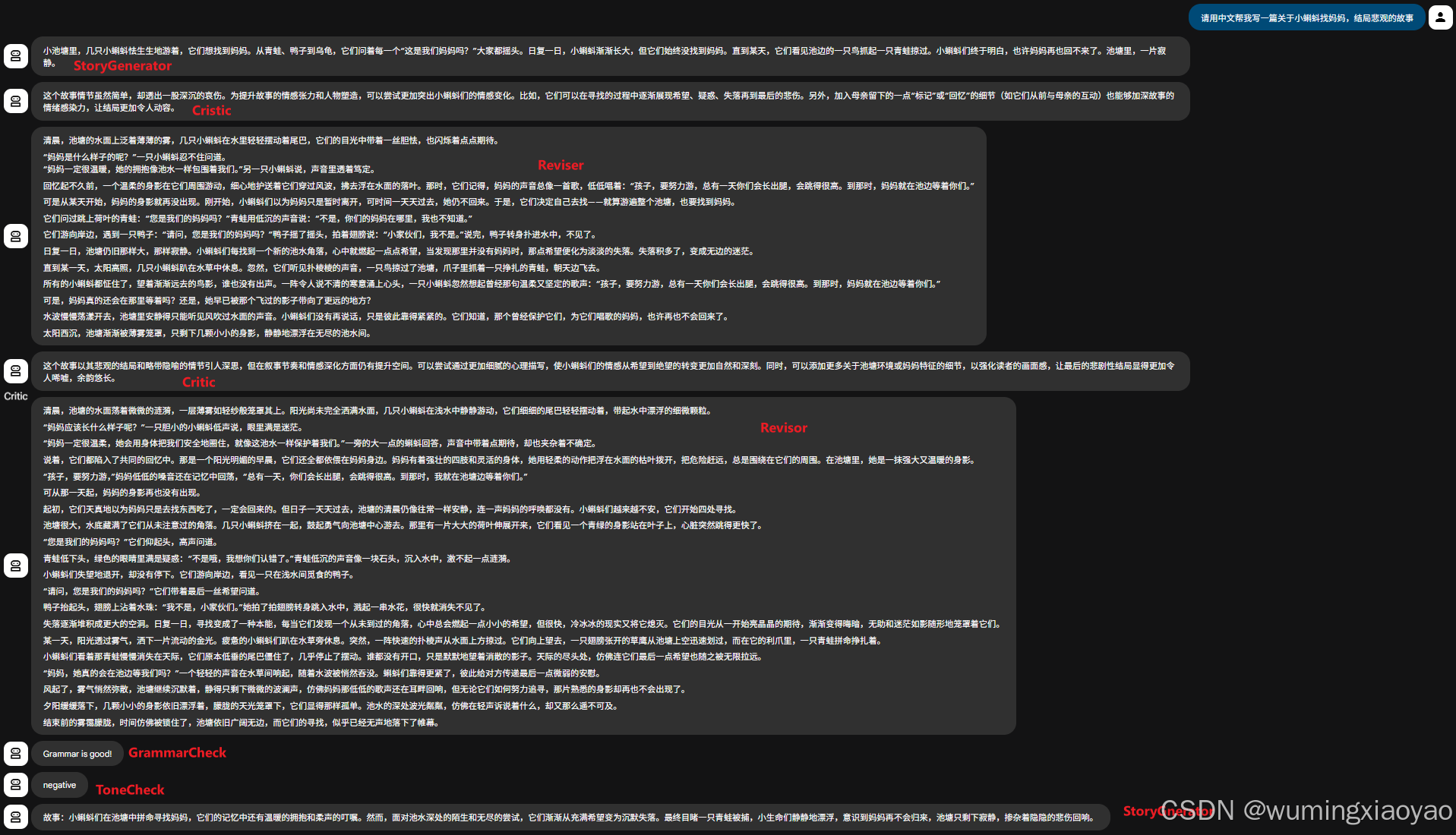
由于故事悲观,所以会再重新生成一篇
生成 1 次故事
用户输入:“请用中文帮我写一篇关于小蝌蚪找妈妈,结局乐观的故事”
由于故事乐观,所以不会再生成一遍故事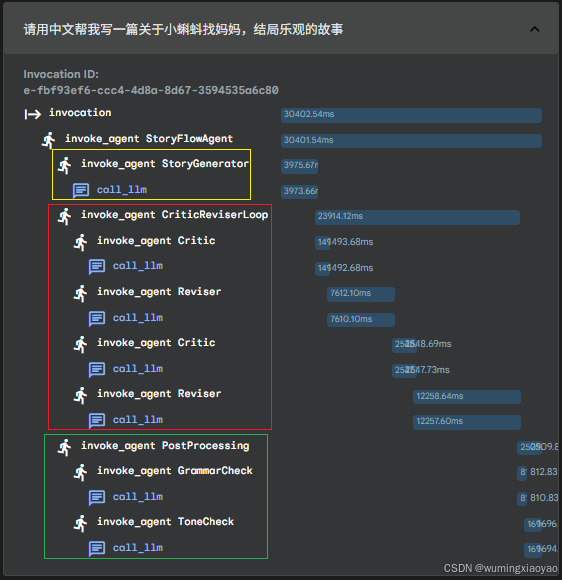
十、第四步:实例化 StoryFlowAgent 并用 Runner 跑起来
最后一块拼图:创建自定义 Agent 实例,配一个内存 SessionService + Runner,跑一轮看看效果。
run_demo.py 文件
await tell_story(“用中文写一只喜欢编程的小狗的故事”)
# run_demo.py for custom_agent / StoryFlowAgent
import asyncio
from pathlib import Path
import logging
from dotenv import load_dotenv, find_dotenv
from google.adk.sessions import InMemorySessionService
from google.adk.runners import Runner
from google.genai import types
# 1. 先加载 .env,确保 agent.py 里能拿到网关和模型配置
try:
_env_path = Path(__file__).parent / ".env"
if _env_path.exists():
load_dotenv(dotenv_path=_env_path)
else:
found = find_dotenv(usecwd=True)
if found:
load_dotenv(found)
else:
load_dotenv()
except Exception:
# dotenv 是可选的,即便失败也继续
pass
from agent import root_agent
APP_NAME = "story_app"
USER_ID = "u1"
SESSION_ID = "s1"
async def main() -> None:
# 2. 创建 SessionService + 初始会话
session_service = InMemorySessionService()
# 这里可以根据需要预置一些 state,目前先留空
initial_state = {}
session = await session_service.create_session(
app_name=APP_NAME,
user_id=USER_ID,
session_id=SESSION_ID,
state=initial_state,
)
print(f"✅ session created: {session.id}, initial_state={session.state}")
# 3. 创建 Runner
runner = Runner(
agent=root_agent,
app_name=APP_NAME,
session_service=session_service,
)
async def tell_story(topic: str) -> None:
"""发送一个故事主题,打印完整故事与最终 state。"""
user_content = types.Content(
role="user",
parts=[types.Part(text=topic)],
)
reply = ""
async for event in runner.run_async(
user_id=USER_ID,
session_id=SESSION_ID,
new_message=user_content,
):
if event.content and event.content.parts:
for part in event.content.parts:
if getattr(part, "text", None):
reply += part.text
# 注意:这里不在 is_final_response 时提前 break,
# 这样可以让自定义的 StoryFlowAgent 把后续步骤(评论、润色、检查)都跑完,
# 日志中才能看到完整的执行过程。
print("\n👤 用户主题:", topic)
print("🤖 生成故事:\n", reply)
# 4. 示例:让用户主题驱动整个 StoryFlowAgent
await tell_story("用中文写一只喜欢编程的小狗的故事")
print("\n=== 最终 Session State ===")
final_session = await session_service.get_session(
app_name=APP_NAME,
user_id=USER_ID,
session_id=SESSION_ID,
)
#print(final_session.state)
if __name__ == "__main__":
asyncio.run(main())
运行:
python run_demo.py
你会看到:
✅ session created: s1, initial_state={}
INFO:agent:[StoryFlowAgent] Start story workflow
INFO:agent:[StoryFlowAgent] Step 1: 调用 StoryGenerator 生成初稿
INFO:agent:=== Step 1: Agent 'StoryGenerator' 即将调用 LLM ===
19:18:36 - LiteLLM:INFO: utils.py:3422 -
LiteLLM completion() model= OpenAI_gpt-4o-xxxx; provider = litellm_proxy
INFO:LiteLLM:
LiteLLM completion() model= OpenAI_gpt-4o-xxxx; provider = litellm_proxy
INFO:agent:[StoryFlowAgent] 初稿生成完毕
INFO:agent:[StoryFlowAgent] Step 2: 进入 CriticReviserLoop 进行评论和润色
INFO:agent:=== Step 2: Agent 'Critic' 即将调用 LLM ===
19:18:39 - LiteLLM:INFO: utils.py:3422 -
LiteLLM completion() model= OpenAI_gpt-4o-xxxx; provider = litellm_proxy
INFO:LiteLLM:
LiteLLM completion() model= OpenAI_gpt-4o-xxxx; provider = litellm_proxy
INFO:agent:=== Step 3: Agent 'Reviser' 即将调用 LLM ===
19:18:41 - LiteLLM:INFO: utils.py:3422 -
LiteLLM completion() model= OpenAI_gpt-4o-xxxx; provider = litellm_proxy
INFO:LiteLLM:
LiteLLM completion() model= OpenAI_gpt-4o-xxxx; provider = litellm_proxy
INFO:agent:=== Step 4: Agent 'Critic' 即将调用 LLM ===
19:18:49 - LiteLLM:INFO: utils.py:3422 -
LiteLLM completion() model= OpenAI_gpt-4o-xxxx; provider = litellm_proxy
INFO:LiteLLM:
LiteLLM completion() model= OpenAI_gpt-4o-xxxx; provider = litellm_proxy
INFO:agent:=== Step 5: Agent 'Reviser' 即将调用 LLM ===
19:18:51 - LiteLLM:INFO: utils.py:3422 -
LiteLLM completion() model= OpenAI_gpt-4o-xxxx; provider = litellm_proxy
INFO:LiteLLM:
LiteLLM completion() model= OpenAI_gpt-4o-xxxx; provider = litellm_proxy
INFO:agent:[StoryFlowAgent] 评论与润色完成
INFO:agent:[StoryFlowAgent] Step 3: 进行语法检查和情绪分析
INFO:agent:=== Step 6: Agent 'GrammarCheck' 即将调用 LLM ===
19:19:05 - LiteLLM:INFO: utils.py:3422 -
LiteLLM completion() model= OpenAI_gpt-4o-xxxx; provider = litellm_proxy
INFO:LiteLLM:
LiteLLM completion() model= OpenAI_gpt-4o-xxxx; provider = litellm_proxy
INFO:agent:=== Step 7: Agent 'ToneCheck' 即将调用 LLM ===
19:19:05 - LiteLLM:INFO: utils.py:3422 -
LiteLLM completion() model= OpenAI_gpt-4o-xxxx; provider = litellm_proxy
INFO:LiteLLM:
LiteLLM completion() model= OpenAI_gpt-4o-xxxx; provider = litellm_proxy
INFO:agent:[StoryFlowAgent] 情绪分析结果: positive
INFO:agent:[StoryFlowAgent] 故事情绪不为负面,保留当前版本故事。
INFO:agent:[StoryFlowAgent] Workflow finished.
👤 用户主题: 用中文写一只喜欢编程的小狗的故事
🤖 生成故事:
从前有一只小狗,名叫代码,最喜欢的事情就是看主人在电脑前敲键盘。一天,主人睡着了,代码趁机跳上了椅子,用爪子学着敲击键盘。没想到,它竟意外地写出了一个小程序!从此 ,它成了编程界的小明星!这个故事非常有趣,突出了小狗代码的独特技能和它意想不到的成功。不过,情节发展略显匆忙,建议加入更多铺垫和细节,比如描述代码与主人的互动,或者它是如何模仿和学习主人敲键盘的。此外,可以进一步展现代码的个性特征,如它初尝失败时的表情或者成长路上的趣味故事,这样角色会更加生动,情节更引人入胜。从前,有一只活泼又聪明的小狗,名叫代码。代码毛色光亮,眼睛大而灵动,每次看人时总像是在思考什么。它最喜欢的事情,就是趴在主人旁边,看主人在电脑前敲击键盘。它每次见到主人打开电脑,总会摇着尾巴跑上前,旁观得极其认真。
主人叫小林,是一名程序员。小林每天坐在书桌前,一边敲击键盘,一边念念有词:“这个逻辑得优化一下……哦,少了一个分号!”代码就趴在一边,歪着脑袋看着屏幕上那些密密麻麻的字符。虽然它看不懂,但它听得出主人说话的语气有时兴奋,有时皱眉。这让它感到好奇极了,它想知道,到底屏幕里的那些“跳动的字符”有什么神奇的力量,让主人如此专注。
有一天,小林写完一段代码后站起身去倒咖啡。他揉着酸痛的肩膀,打了个哈欠,困意涌了上来。不久,小林竟在沙发上睡着了。见状,趴在旁边的代码悄悄站了起来,偷偷看了眼睡熟的主人,又看了看敞开的电脑屏幕,眼神中闪过一丝期待。
“咚!”代码小心翼翼地跳到主人的椅子上,四只毛茸茸的爪子踩在键盘上,那张小脸凑得离屏幕好近。它回忆着主人平时敲键盘的模样,试探着用爪子轻轻压下一个键。“啪”的一声,屏幕上真的出现了一个字母!代码兴奋得耳朵一竖,再接再厉,开始用它两只前爪有些笨拙地“敲”键盘。
起初,屏幕上充满了乱码,横七竖八的符号像是在嘲笑它的努力。但代码并不气馁,它虽然看不懂这些符号的意义,但每敲下一行,它都会仰起头看看屏幕,仿佛在检查自己的“作品”。它甚至学着主人皱眉的表情,嘴里发出低低的呜咽声,仿佛在自言自语:“哪里不对呢?”
练习了一段时间后,它渐渐找到了“节奏”。这时,屏幕上的代码似乎开始排列得整齐起来,虽然它并不知道成功的标准是什么,但它的直觉告诉它:似乎有点门道了!
正当它全神贯注地拍打键盘时,小林醒了。他揉了揉眼睛,却被眼前的场景惊呆了:他的小狗,正趴在他的电脑前“编程”!“代码!你这是干什么呢?”小林又惊又笑地看着屏幕,忍不住凑近查看。谁知,他突然后退了一步,满脸不可置信。“天啊!你……你真的写了个程序?!”
原来,小狗代码在这一通“乱敲”之下,竟意外写出了一段简单的小程序——一个由随机数字组成的小游戏!虽然简单,但居然能够运行。
从这天起,小林开始认真教代码编程。他发现,这只小狗不仅好奇心强,还十分聪明。比如,当小林演示如何写一个“打印小狗名字”的程序时,代码会迅速模仿,甚至学会优化代码。当某次程序运行失败时,代码委屈地低下头,耳朵也耷拉下来,直到小林安慰地摸摸它的脑袋,它才重新振作精神。
代码的独特才能很快被小林上传到网上。没过多久,它的“编程视频”火了,许多人都惊叹这只小狗的天赋,有些人甚至开玩笑说:“代码才是真正的程序员!”
后来,代码不仅成为编程界的小明星,还和主人一起参加过多个编程比赛,屡获好评。而作为回报,小林特意设计了一款专门适合狗狗用的小键盘,让代码在学习的路上更加得心应手。
从此,这只可爱的小狗代码,继续用自己的爪子敲击着键盘,探索着属于它的编程世界。在它看不懂的字符间,那份坚持和好奇,早已为它开创了一个属于自己的传奇。这个故事整体趣味十足,充满温馨和想象力,特别是在描写小狗代码模仿主人的编程行为以及与主人的互动时,增添了可爱的细节。不过,建议可以稍微加强逻辑性:例如,代码在模拟编程时为何能够输出逻辑缜密的小游戏,这部分可以增加一些细节描写和解释,比如暗示小林电脑中有一些智能化辅助工具,从而让观众更容易接受。此外,还可以在故事结尾增加几笔点出代码和小林在比赛中的具体场景,通过更细腻的描写来增强故事的感染力和立体感。从前,有一只活泼又聪明的小狗,名叫代码。代码毛色光亮,眼睛大而灵动,每次看人时总像是在思考什么。它最喜欢的事情,就是趴在主人旁边,看主人在电脑前敲击键盘。每当听到键盘“哒哒哒”的声音,它都会竖起耳朵,兴奋地盯着屏幕,摇着尾巴仿佛也参与其中。
主人小林是一名程序员,钟爱编程的工作,但长时间伏案使得他常感疲劳。每天,他都会对着屏幕上一串串字符念念有词:“这个算法需要优化……啊,少了个分号!”而代码则趴在旁边,目不转睛地看着屏幕,尽管完全看不懂那些跳动的字符,但它总能从主人的语气中察觉出不同的情绪:兴奋、犹豫或得意,这让它更加好奇——屏幕上的这些“有趣字符”到底藏着什么样的秘密呢?
有一天,小林写完一段程序后,站起身去倒咖啡。他揉着酸痛的肩膀,疲倦地打了个哈欠。没过一会儿,他靠在沙发上竟打起了盹。平日里陪在他身旁的代码看到机会来了,圆圆的眼睛闪着期待的光。它偷偷看了看熟睡的小林,又看了看主人没有锁屏的电脑,心中一阵新奇。
代码轻轻跳上椅子,两只小爪子按在键盘上。它试探着回忆平日里小林敲打键盘的模样,用爪子小心翼翼地碰下一颗按键。“啪!”屏幕上真的回应一般跳出一个字符,这让代码兴奋地甩了甩尾巴。“啪、啪、啪”,更多字符逐渐出现在屏幕上,但代码并不知道这看似简单的字符竟因小林的特殊设备而含有另一层意义。
原来,小林的电脑里安装了一款智能化编程辅助系统——他自己设计的一套“入门代码引导工具”,目的是为了帮助初学者更轻松地理解编程的逻辑。这工具附带了一个自动补全功能,能够根据输入的字符和语句自动预测程序结构。当小狗代码敲击键盘时,系统便自发地将这些字符整理补全成有一定意义的代码结构。因此,虽然代码的动作看似笨拙,但在系统的辅助下,最终输出了有逻辑的内容。
当屏幕开始逐渐展现出一个以随机数字为核心的小游戏界面时,代码仿佛也为自己的“作品”感到高兴,用鼻尖点了点屏幕,开心地“汪”了一声。但就在这个时候,小林醒了。他揉着惺忪的眼睛,看到这样一幅场景:它的小狗代码,居然正趴在他的椅子上,“编写”代码!他起初吓得一跳,随后忍俊不禁,“代码,你这是在干什么呢?”
小林好奇地凑近屏幕查看,然而当看到屏幕上完整运行的小游戏界面时,他惊呆了。“天啊,我没看错吧?你……你写了个程序?!还能跑!?”屏幕上的程序虽然简单,玩法不过是显示一组随机数字供输入与反馈,但却流畅得让人难以置信。小林这才意识到,他的智能辅助工具帮助了这只小狗实现它的“创意”。
从这天开始,小林正式教代码编程。作为一只聪明的小狗,代码以敏锐的观察力和独特的直觉迅速掌握了基础知识。比如,小林教它如何打印“Hello World”,代码便能很快模仿出来,有 时甚至会打出例如“Hello, Doggy!”这样带点小创意的内容。小林笑个不停,干脆开玩笑说:“看起来,你真比我还天赋异禀!”
随着时间的推移,小林发现代码对编程的热忱超出了他的预期。偶尔当程序运行失败时,代码会露出疑惑的神情,耳朵垂得低低的,爪子挠着脑袋,一副“不明所以”的样子。每当这时,小林都会摸摸它的脑袋鼓励道:“没关系,不怕犯错,慢慢来。”这话似乎会让代码重新振作精神,尾巴会再次摇得像电风扇一样。
很快,小林将代码的编程视频上传到了网上。不到几天,小狗代码“敲键盘”的视频便火了起来,网友们纷纷被它的可爱和聪明迷住,甚至有人笑称:“它比某些人类程序员还强!”更让人惊喜的是,代码的视频吸引了一个国际编程比赛的主办方邀请,小林决定带它一起参加。
比赛那天,代码和小林一同出现在舞台上。小林负责主讲,而代码则被人特地安排了一台带有专属小键盘的电脑。比赛主题是开发一个简单而有趣的算法小游戏,在比赛限时内完成挑战。小林负责案例分析,而代码则不时用爪子轻敲键盘,调整细节。每当它敲击出一段合理的代码时,观众都会爆发热烈的掌声,许多人惊呼:“这是有史以来最独特的团队了!”
最终,代码和小林成功拿下大奖。从后台走出来时,小林对代码说道:“这奖杯有你一份,程序员小狗先生!”而代码则开心地汪了一声,尾巴摇得欢快极了。
从此,这只小狗和它的主人不仅成为编程界的明星,还激励了无数人敢于探索自己的潜力。而代码则继续跟随着小林,在闪烁的屏幕前,用它那毛茸茸的小爪子敲击键盘,创造属于它们的更多奇迹。美妙字符的背后,是一段跨越物种的默契与传奇。Grammar is good!positive
=== 最终 Session State ===
如果你多跑几次,或者修改 prompt,让故事倾向负面,
就有机会触发那条 “tone negative → 重生成故事” 的分支。
十一、把 StoryFlowAgent 模式抽象一下
通过这个例子,其实已经掌握了 Custom Agent 的标准套路:
-
先把所有“干活的 Agent”定义好
- 多数是 LlmAgent,也可以适当用 SequentialAgent / LoopAgent / ParallelAgent 做子工作流。
-
写一个继承自 BaseAgent 的类
- 在 init 里:
- 接收子 agent 实例
- 内部创建必要的 WorkflowAgent
- 把所有会直接调度的 agent 塞进 sub_agents 列表传给 super().init
- 在 init 里:
-
在 _run_async_impl 里实现完整流程
- 用 async for … in x.run_async(ctx) 逐步调用子 agent
- 在关键节点读写 ctx.session.state
- 该 if 就 if,该 for 就 for,该 while 就 while
- 必要时调用外部 API / 数据库 / 自己写的 Python 函数
-
用 Runner 像跑普通 agent 一样跑它
- 从调用方眼里,它就是一个“普通的 root_agent”,
- 只不过内部是你亲手定制的复杂工作流。
十二、什么时候该上 Custom Agent,而不是继续堆 WorkflowAgent?
可以用一个简单的判断方式:
- 如果你的需求只是在“顺序 / 循环 / 并行”这三个维度组合
→ 尽量用 SequentialAgent / LoopAgent / ParallelAgent 搞定。 - 如果你发现开始写“跨多个步骤的 if / else 条件、根据状态动态选择下一步”
→ 就可以考虑抽成一个 Custom Agent,让 _run_async_impl 来控制整体。
Custom Agent 给你的其实是一个“高级总导演”:
子 Agent 负责演戏(写、评、改、查错……),
WorkflowAgent 负责简单调度(排队、循环、并行),
Custom Agent 则负责 整场戏的剧本和分支逻辑。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 32
32 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)