大模型在酒店分销房型匹配与标准化中的工程化落地
从大模型匹配信息表中提取第一阶段已经完成的数据,分批次进行提取特征,包含床型,等级,景观。为了提高准确性,判断的逻辑完全在代码层面进行,大模型只做提取特征工作。大模型在语义理解上确实有优势,但直接把“是否匹配”的判断交给模型,结果往往不可控,也不适合高频、批量的线上业务。保证调用大模型匹配前,使用系统相似度进行预先匹配,过滤出高度相似房型。3. 大模型返回结果后,将匹配本地房型的相关信息(id、匹
前言
在酒店分销场景中,房型匹配一直是个绕不开的问题。不同供应商对同一房型的命名、床型、等级和景观描述差异很大,靠规则或者正则堆不完,靠人工维护又不现实。
大模型在语义理解上确实有优势,但直接把“是否匹配”的判断交给模型,结果往往不可控,也不适合高频、批量的线上业务。因此,这套方案并没有把大模型当作裁决者,而是作为辅助工具,只负责做它擅长的事情——理解文本、提取信息。
整体上采用两阶段处理:先用大模型做语义层面的初步匹配,缩小范围;再由大模型提取核心特征,最终是否匹配完全由代码规则决定。对于实在无法匹配的房型,引入标准化流程补齐本地数据,以提升整体覆盖率。
这是一套在真实业务约束下,对准确性、可控性和落地成本做权衡后的实践方案。
大模型房型匹配与标准化
模型:DeepSeek-chat。项目基于 DeepSeek 的 Chat 模型。该模型在推理能力上虽非最优,但具备更快的响应速度。
核心数据表说明:
|
表名 |
说明 |
|
t_supply_match_roomtype_ai_auto |
大模型匹配信息表 |
|
t_supply_match_roomtype_ai_prompt |
供应商专属提示词表 |
|
t_supply_match_roomtype_candidate_ai_auto |
大模型初匹配表[记录] |
|
t_supply_match_roomtype_final_ai_auto |
大模型核心特征提取表[记录] |
|
XXX |
本地房型表 |
房型匹配整体架构
本流程分为两个阶段:第一阶段为初步匹配,第二阶段为大模型提取核心特征。规则校验完全由代码执行,结果转换及大模型调用均有重试机制。具体配置请参见代码实现。
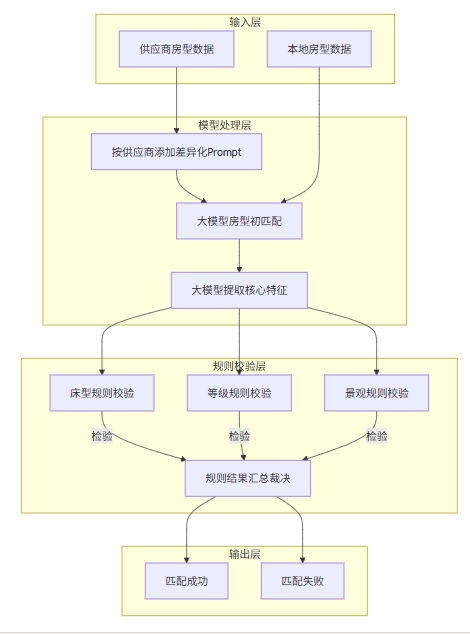
第一阶段
流程说明
匹配单位说明
系统以酒店作为最小匹配单位。每次匹配仅在同一酒店维度内进行:
1. 拉取匹配本地酒店下的供应商房型集合
2. 同时拉取对应的本地酒店房型集合
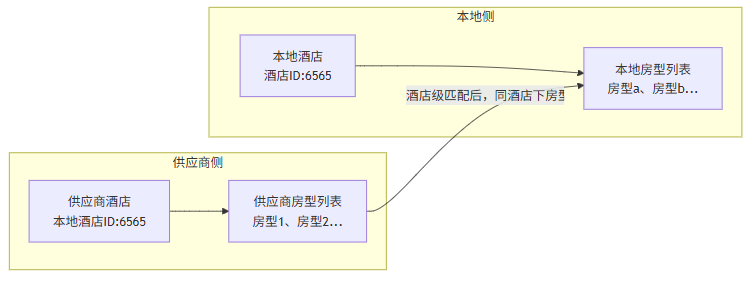
注意拉取供应商侧房型数量,可能会出现一酒店下上百个房型导致token超出限制,可以进行分批处理。但本地酒店也有这种现象,但目前尚未解决。
1. 在获取房型数据后,系统将根据 supplier_id 从供应商提示词规则表中加载对应的差异化 Prompt 规则。
2. 将该供应商专属规则与公共 Prompt 模板进行合并,生成最终用于本次匹配的大模型输入 Prompt,图示如下。
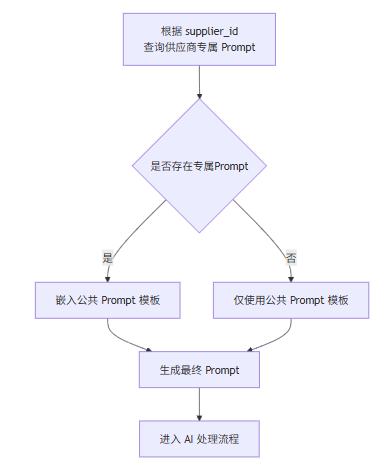
3. 大模型返回结果后,将匹配本地房型的相关信息(id、匹配分数、匹配原因等)统一更新至大模型房型匹配信息表。
保证调用大模型匹配前,使用系统相似度进行预先匹配,过滤出高度相似房型。减少token使用量
第二阶段
流程说明
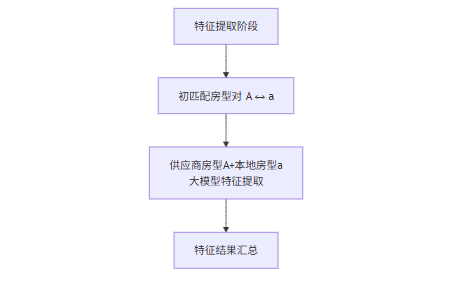
从大模型匹配信息表中提取第一阶段已经完成的数据,分批次进行提取特征,包含床型,等级,景观。后续也是依据这三个核心特征进行裁决房型是否匹配。为了提高准确性,判断的逻辑完全在代码层面进行,大模型只做提取特征工作。
批次提取规则
在特征提取阶段,系统以房型来源维度进行批次调用大模型,降低上下文干扰:
● 对同一批次内的供应商房型(如 A / B / C)进行一次统一的大模型调用;
● 对应地,再对该批次内的本地房型(如 a/ b / c)进行一次统一的大模型调用。
=>
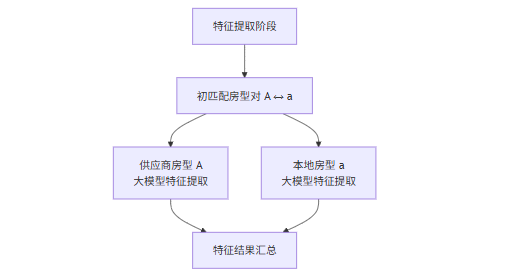
核心特征校验
提取完成后,进入三个并行的代码校验分支,任何一个分支校验失败均视为“匹配失败”。
床型(Bed Type)校验
● 对床型文本进行统一标准化(术语统一、大小写处理、去空格)。
● 匹配三类逻辑场景,避免因描述差异或顺序不同导致的误判
○ 普通床型:严格全等;
○ OR 逻辑:本地床型任一选项与供应商床型全等即通过;
○ AND 逻辑:拆分床型按集合比较,忽略描述顺序差异。
等级(Grade)校验
● 采用严格全等校验。
● 供应商等级与本地等级完全一致,目前未做模糊匹配。
景观(View)校验
● 对景观描述进行统一清洗与同义词归一(Queen->Double)。
● 采用包含关系校验:供应商景观覆盖本地景观要求,会造成房型不产单。
● 在完全匹配失败时,仅作为兜底进行高阈值相似度判断,防止微小文本差异导致误杀。
使用
将待大模型匹配的供应商房型插入到t_supply_match_roomtype_ai_auto表中。然后即可调用
以下字段为该表进行匹配的必需字段:
|
字段名 |
说明 |
|
supplier_id |
供应商唯一标识,用于区分供应商规则、Prompt 模板 |
|
sp_hotel_id |
供应商侧酒店 ID,用于定位 |
|
hotel_id |
本地酒店 ID,作为房型匹配的单位 |
|
sp_roomtype_id |
供应商房型 ID,供应商侧房型唯一标识 |
|
sp_roomtype_name_en |
供应商房型英文名称,作为大模型匹配的核心语义输入 |
|
sp_bedtype_desc |
供应商床型描述(注:允许为空,但必需要保证供应商房型中含有床型) |
目前大模型定时处理时间是每天凌晨一点钟,主要是减少白天平台高流量导致本地调用失败。
结果应用
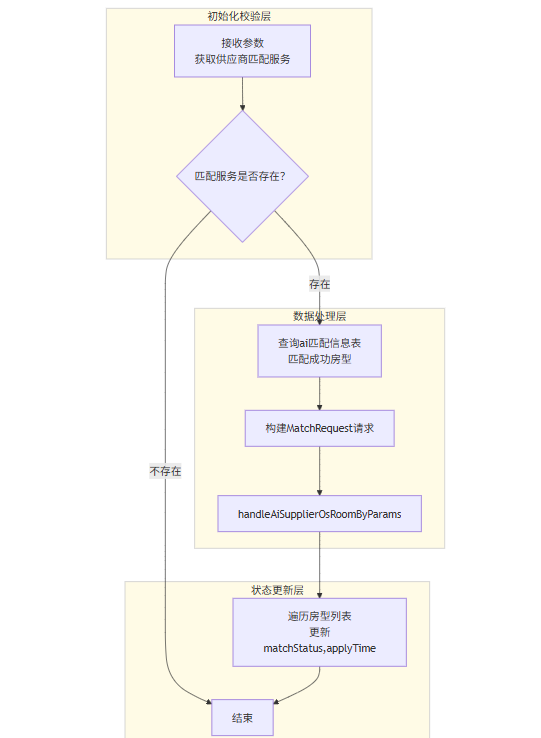
处理流程
1. 初始化校验
a. 根据 supplierId 获取匹配类型枚举
b. 获取对应的 SupplierOsInfoService
2. 业务处理
a. 查询当前供应商 AI 匹配成功的房型数据
b. 构建 MatchRequest,携带 supplierId、context 等参数
c. 调用 handleAiSupplierOsRoomByParams 执行房型应用逻辑
3. 状态更新
a. 将房型匹配记录状态更新为 已应用(matchStatus = 4)
b. 记录应用时间并批量更新数据库
房型标准化与插入
此功能是针对供应商没有匹配的房型进行新增,旨在提高匹配率。但盲目的新增会导致数据臃肿重复。
标准化流程
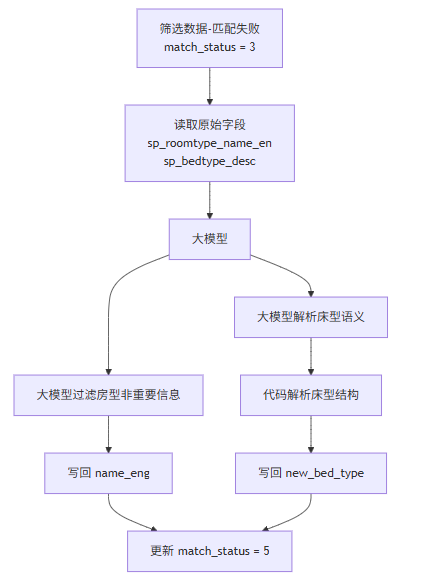
1. 系统从 t_supply_match_roomtype_ai_auto 表中筛选匹配状态为3(匹配失败)的记录;
2. 以供应商原始房型信息作为输入,包括:
2.1 供应商房型英文名sp_roomtype_name_en;
2.2 供应商床型描述sp_bedtype_desc;
3. 通过大模型对输入信息进行清洗,过滤非关键信息;
4. 由大模型解析床型信息,并结合代码逻辑进行结构化处理;
5. 将标准化后的结果回写至当前记录:
5.1 标准化房型名称写入 name_eng;
5.2 标准化床型描述写入 new_bed_type;
6. 更新匹配状态,将 match_status 由 3(匹配失败) 更新为5(已标准化)。
插入流程
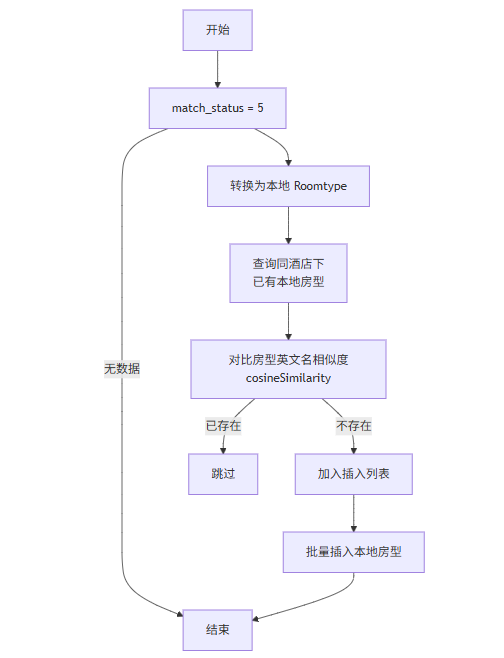
● 数据获取
系统根据供应商 ID 查询供应商房型匹配表中:
○ supplier_id = 指定供应商
○ match_status = 5(已标准化)
的房型记录,作为待入库数据。
● 2 数据转换
将供应商标准化房型数据转换为本地房型对象,主要包括:
● 3 本地房型去重校验
为避免同一酒店下房型重复,系统执行如下校验逻辑:
○ 按酒店维度查询本地已有房型数据
○ 对比新房型与已有房型的英文名称
○ 使用相似度算法进行判断
○ 相似度超过阈值[0.99]的房型视为已存在,不再插入
● 4 房型入库
通过去重校验的房型,将以批量方式插入本地房型表,完成标准化房型入库。
插入的标准化房型可能重复,也会导致垃圾数据。
私聊获取代码

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 29
29 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)