【AI课程领学】第五课 · 循环神经网络(课时4) 训练技巧:梯度截断、BPTT、Padding、Teacher Forcing 与工程实践
【AI课程领学】第五课 · 循环神经网络(课时4) 训练技巧:梯度截断、BPTT、Padding、Teacher Forcing 与工程实践
【AI课程领学】第五课 · 循环神经网络(课时4) 训练技巧:梯度截断、BPTT、Padding、Teacher Forcing 与工程实践
【AI课程领学】第五课 · 循环神经网络(课时4) 训练技巧:梯度截断、BPTT、Padding、Teacher Forcing 与工程实践
文章目录
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可扫描博文下方二维码 “
学术会议小灵通”或参考学术信息专栏:https://ais.cn/u/mmmiUz
详细免费的AI课程可在这里获取→www.lab4ai.cn
前言
RNN 真正难的其实不是“结构本身”,而是 训练:
- 序列长 → 梯度消失/爆炸
- 样本长短不一 → 需要 padding、mask
- 文本生成类任务 → 训练和推理阶段不一致,需要 teacher forcing 等技巧
- 工程上还要考虑 batch 组织、效率与 GPU 占用
本篇我们分模块讲:
- BPTT(通过时间的反向传播)与梯度截断
- 可变长序列的 padding 与 pack_padded_sequence
- Teacher Forcing 与 scheduled sampling
- RNN 训练时的一些工程实践建议(学习率、初始化等)
一、BPTT 与梯度截断
1.1 BPTT 是什么?
- 对于 RNN,损失不仅依赖最后一个时间步,而是整个序列:
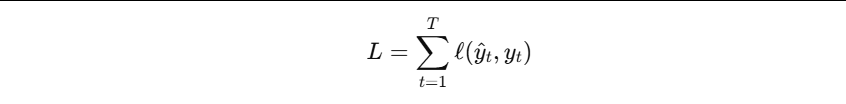
参数同时作用于所有时间步,因此反向传播需要沿时间方向展开: - 这就是 Backpropagation Through Time(BPTT)。
当序列很长时,梯度会沿着时间维不断被链式法则“乘来乘去”,非常容易:
- 梯度消失(训练很慢甚至无效)
- 梯度爆炸(参数更新不稳定)
1.2 梯度截断(Gradient Clipping)
- 解决梯度爆炸的常用做法:在每一步更新前,限制梯度的范数不超过某个阈值。
PyTorch 中一行搞定:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=5.0)
- 放在
loss.backward()和optimizer.step()之间即可。
二、可变长序列:Padding 与 pack_padded_sequence
真实数据中,序列长度通常不一样:
- 文本:有的句子 5 个词,有的 50 个词
- 时间序列:观测长度不一致
- 遥感时序:有缺测/遮挡
2.1 Padding:统一长度
做法:
- 找到 batch 中最长序列长度
max_len - 其它序列在结尾补 0,使形状一致
但补 0 会引入无效时间步。我们希望在计算时忽略这些 padding 部分,否则会干扰梯度与隐藏状态。
2.2 PyTorch 中的打包序列:pack_padded_sequence
PyTorch 提供了一套专门工具处理变长序列:
nn.utils.rnn.pack_padded_sequencenn.utils.rnn.pad_packed_sequence
基本流程:
- 准备
padded_sequences(统一长度)以及真实长度列表lengths - 用
pack_padded_sequence打包 - 把 pack 结果喂给 RNN/LSTM/GRU
- 用
pad_packed_sequence恢复(如果需要)
示例:
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
# 假设 x_padded: (batch, max_len, input_size), lengths: (batch,)
# 注意:pack_padded_sequence 要求序列按长度降序排序,或者设置 enforce_sorted=False
x_padded = ...
lengths = ...
x_packed = pack_padded_sequence(
x_padded,
lengths=lengths.cpu(),
batch_first=True,
enforce_sorted=False
)
lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
packed_out, (h_n, c_n) = lstm(x_packed)
out, out_lengths = pad_packed_sequence(packed_out, batch_first=True)
- 优势:RNN 不会在 padding 部分多算无用步骤,隐藏状态不会被 padding“污染”,效率也更高。
三、Teacher Forcing:解决训练/推理阶段分布不一致
在 Seq2Seq 或生成式任务中(机器翻译、文本生成等),Decoder 在每一步的输入通常是:
- 训练时:真实标签(ground truth)
- 推理时:模型前一步预测的结果
这会导致一个问题:
- 模型在训练时总是“看到正确上下文”,而推理时却要面对自己“错误的历史预测”,产生分布不匹配,导致错误不断累积。
为缓解这一点,引入 Teacher Forcing:
- 训练时某些时间步用真实标签作为 Decoder 输入
- 其他时间步用模型预测的结果
- 使用一个概率
p_tf(teacher forcing ratio)控制两者之间的权衡
伪代码示意:
import random
def decode_with_teacher_forcing(decoder, encoder_out, y_targets, p_tf=0.5):
# y_targets: 真实输出序列
# 通常会有一个 <bos> 作为起始
inputs = y_targets[:, 0] # <bos>
hidden = decoder.init_hidden_from_encoder(encoder_out)
outputs = []
for t in range(1, y_targets.size(1)):
out, hidden = decoder(inputs, hidden)
outputs.append(out)
use_teacher = random.random() < p_tf
if use_teacher:
inputs = y_targets[:, t] # 用真实 token
else:
inputs = out.argmax(dim=-1) # 用模型预测值
return torch.stack(outputs, dim=1)
- 进阶:Scheduled Sampling 会随着训练进程逐步降低
p_tf,逐渐让模型更适应“自回归”场景。
四、RNN 训练的工程实践建议
4.1 输入归一化 & 初始隐藏状态
- 对于连续特征(如时间序列),建议先做标准化(mean-std)
- 初始隐藏状态通常设为 0;若任务需要,也可以学习一个全局初始向量
PyTorch 中如不指定,nn.LSTM 默认 h_0 和 c_0 都是 0。
4.2 学习率与优化器
- Adam/AdamW 是 RNN 的常用起点(如
lr=1e-3) - 对长序列/梯度不稳定任务,多尝试 小一点学习率 + 梯度裁剪
4.3 Dropout 与正则化
nn.LSTM、nn.GRU内部支持层间 dropout(非最后一层之间)- 序列任务中适当增加输入层、输出层的 dropout 可以提升泛化
例子:
lstm = nn.LSTM(
input_size=feature_dim,
hidden_size=hidden_dim,
num_layers=2,
dropout=0.2, # 仅在多层之间有效
batch_first=True
)
4.4 序列截断训练(Truncated BPTT)
对于极长序列(比如上千步),完整 BPTT 计算与显存消耗都很大。
Truncated BPTT 思想:
- 将长序列分成若干小片段(如 100 步一段)
- 前一段的最终隐藏状态作为后一段的初始状态
- 每一段单独做一次反向传播
简化示意:
hidden = None
for i in range(0, seq_len, chunk_len):
x_chunk = x[:, i:i+chunk_len] # (batch, chunk_len, input_size)
out, hidden = lstm(x_chunk, hidden)
loss = ...
optimizer.zero_grad()
loss.backward()
# 截断反向传播的“图”:
hidden = (hidden[0].detach(), hidden[1].detach())
optimizer.step()
- 这样就不会因为一次 BPTT 展开太久而导致显存过大。
五、综合示例:可变长序列 + LSTM + 梯度截断
- 下面给一个稍完整的例子,对“可变长序列二分类”进行训练:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
class VarLenLSTMClassifier(nn.Module):
def __init__(self, input_size=10, hidden_size=64, num_layers=1, num_classes=2):
super().__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x_padded, lengths):
# x_padded: (batch, max_len, input_size)
# lengths: (batch,) 实际长度
packed = pack_padded_sequence(
x_padded, lengths.cpu(), batch_first=True, enforce_sorted=False
)
packed_out, (h_n, c_n) = self.lstm(packed)
# 这里我们直接用最后一层的最终 hidden 作为表示
last_hidden = h_n[-1] # (batch, hidden_size)
logits = self.fc(last_hidden)
return logits
# 假数据
batch = 4
max_len = 7
input_size = 10
# 长度不同的序列
lengths = torch.tensor([7, 5, 6, 3])
x_padded = torch.randn(batch, max_len, input_size)
model = VarLenLSTMClassifier(input_size=input_size)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
y = torch.randint(0, 2, (batch,))
logits = model(x_padded, lengths)
loss = F.cross_entropy(logits, y)
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 5.0)
optimizer.step()
print("loss:", loss.item())
这个例子把:
- 可变长序列
pack_padded_sequence- LSTM 分类
- 梯度截断
整合到了一起,是实际项目中相当常用的模式。
六、小结
本篇我们重点解决了“RNN 实战中最常碰到的坑”:
- BPTT 与梯度消失/爆炸 → 用梯度截断、合适的结构(LSTM/GRU)
- 可变长序列 → padding + pack/pad 工具
- 生成任务的训练/推理不一致 → Teacher Forcing + Scheduled Sampling
- 极长序列 → Truncated BPTT
- 工程实践 → 归一化、优化器配置、Dropout、初始化等

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)