【AI课程领学】第五课 · 循环神经网络(课时3) 拓展:Seq2Seq、注意力、RNN + CNN 与时间序列实战
【AI课程领学】第五课 · 循环神经网络(课时3) 拓展:Seq2Seq、注意力、RNN + CNN 与时间序列实战
【AI课程领学】第五课 · 循环神经网络(课时3) 拓展:Seq2Seq、注意力、RNN + CNN 与时间序列实战
【AI课程领学】第五课 · 循环神经网络(课时3) 拓展:Seq2Seq、注意力、RNN + CNN 与时间序列实战
文章目录
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可扫描博文下方二维码 “
学术会议小灵通”或参考学术信息专栏:https://ais.cn/u/mmmiUz
详细免费的AI课程可在这里获取→www.lab4ai.cn
前言
在前两课里,我们主要关注“单个 RNN 链条”本身的结构。
本篇开始,我们讨论 RNN 如何在更复杂系统里使用,包括:
- 编码器–解码器(Seq2Seq)
- Seq2Seq + Attention 的基本思想
- RNN + CNN 的组合(如视频/遥感时序)
- 用 RNN 做时间序列预测的一个简单示例(PyTorch)
一、Seq2Seq:从固定长度向量到“序列到序列”
问题:翻译、摘要、对话等任务中,“输入序列”和“输出序列”长度都不固定,且彼此不同。
Vanilla RNN 无法直接应对这种变长映射。
解决方案:Encoder-Decoder(Seq2Seq)结构:
- Encoder:用一个 RNN(如 BiLSTM)把输入序列编码成一个向量(或一系列向量)
- Decoder:用另一个 RNN,根据编码结果一步步生成输出序列
最朴素的形式:
- Encoder 扫完输入序列,得到最终隐藏状态 h T h_T hT
- Decoder 用 h T h_T hT 初始化自己的隐藏状态,开始自回归生成输出
这就是经典的“编码成一个语义向量 → 再解码成目标语句”。
二、Seq2Seq + Attention:解决“信息瓶颈”
问题:如果只用 Encoder 的最后一个隐藏状态作为“语义摘要”,长序列信息会严重压缩,导致翻译长句效果差。
Attention 的核心思想:
- 解码时,不是只看一个向量,而是对 Encoder 所有时间步的隐藏状态做一个“加权平均”,权重由当前解码状态动态决定。
形式上,对于 Decoder 的第 t t t 个时间步:
-
计算当前解码隐藏状态 s t s_t st 与所有编码隐藏状态 h 1 , . . . , h T h_1,...,h_T h1,...,hT 的相似度
-
得到一组注意力权重 α t , 1 : T α_{t,1:T} αt,1:T,然后做加权和:
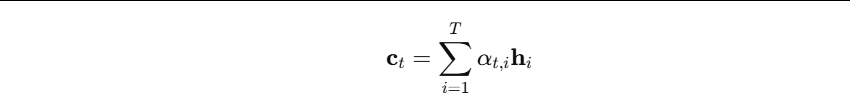
-
c t c_t ct 就是当前时间步的“上下文向量”。
-
在此基础上,Decoder 再用 ( s t , c t ) (s_t,c_t) (st,ct) 预测下一个词。
-
这就是后来 Transformer 的直接前身。
三、RNN + CNN:时空建模的组合
在很多任务中:
- 空间维:用 CNN 提取特征(图像/遥感/视频帧)
- 时间维:用 RNN 建模序列依赖(逐时间步 CNN 特征输入 RNN)
一个典型例子:视频分类 或 时序遥感影像分类/预测。
流程:
- 每一帧图像 → CNN → 得到特征向量 f t f_t ft
- 将 f 1 , … , f T {f_1,…,f_T} f1,…,fT 作为序列喂给 LSTM/GRU
- 最后一个隐藏状态用来做分类/回归
伪代码结构:
class CNN_RNN_Model(nn.Module):
def __init__(self, cnn_backbone, feature_dim, hidden_size, num_classes):
super().__init__()
self.cnn = cnn_backbone
self.rnn = nn.LSTM(input_size=feature_dim, hidden_size=hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x): # x: (B, T, C, H, W)
B, T, C, H, W = x.shape
x = x.view(B*T, C, H, W)
feat = self.cnn(x) # (B*T, feature_dim)
feat = feat.view(B, T, -1) # (B, T, feature_dim)
out, (h_n, c_n) = self.rnn(feat) # (B, T, hidden)
last_hidden = h_n[-1] # (B, hidden)
logits = self.fc(last_hidden)
return logits
对于遥感任务:例如每个像元在多时相的 patch 上跑 CNN 做 feature,再用 RNN 处理时序。
四、RNN 做时间序列预测:一个简单实战例子
- 假设我们有某个环境变量的时间序列(如月平均 PM2.5、气温、水位等),想要根据过去 L L L 个时间步预测下一个时间点值。
- 我们用正弦波 + 噪声模拟一个时间序列,使用 LSTM 做预测。
4.1 构造数据集
import torch
from torch.utils.data import Dataset, DataLoader
import math
import numpy as np
class SineWaveDataset(Dataset):
def __init__(self, total_len=1000, input_len=20):
self.input_len = input_len
t = np.arange(total_len)
# 构造一个非纯正弦:sin + 0.5*sin(0.5t) + 噪声
self.series = np.sin(0.02 * t) + 0.5*np.sin(0.01 * t) + 0.1*np.random.randn(total_len)
def __len__(self):
# 每个样本使用前 input_len 预测下一个
return len(self.series) - self.input_len - 1
def __getitem__(self, idx):
x = self.series[idx:idx+self.input_len]
y = self.series[idx+self.input_len]
x = torch.tensor(x, dtype=torch.float32).unsqueeze(-1) # (L, 1)
y = torch.tensor(y, dtype=torch.float32)
return x, y
dataset = SineWaveDataset(total_len=1500, input_len=20)
train_loader = DataLoader(dataset, batch_size=32, shuffle=True)
4.2 定义 LSTM 回归模型
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
class LSTMForecaster(nn.Module):
def __init__(self, input_size=1, hidden_size=64, num_layers=2):
super().__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers)
self.fc = nn.Linear(hidden_size, 1)
def forward(self, x):
# x: (seq_len, batch, input_size)
out, (h_n, c_n) = self.lstm(x)
last_hidden = out[-1] # (batch, hidden)
y_hat = self.fc(last_hidden) # (batch, 1)
return y_hat.squeeze(-1) # (batch,)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = LSTMForecaster().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
4.3 训练循环
for epoch in range(20):
model.train()
total_loss = 0.0
count = 0
for x, y in train_loader:
# x: (batch, L, 1) -> (L, batch, 1)
x = x.permute(1, 0, 2).to(device)
y = y.to(device)
y_pred = model(x)
loss = F.mse_loss(y_pred, y)
optimizer.zero_grad()
loss.backward()
# 序列较长时建议加梯度裁剪
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=5.0)
optimizer.step()
total_loss += loss.item() * y.size(0)
count += y.size(0)
print(f"Epoch {epoch+1}, MSE={total_loss/count:.6f}")
- 训练结束后,你可以抽取一段时间序列做可视化,对比真实值与预测值,通常能看到明显的平滑拟合效果。
五、小结
这一篇主要从“系统视角”来看 RNN:
- Seq2Seq:解决变长序列到序列的问题
- Attention:缓解 Encoder 压缩成单一向量的信息瓶颈
- RNN + CNN:处理时空数据(视频、遥感多时相)
- 时间序列预测:给出 LSTM 回归的实战代码骨架
下一篇(课时4)我们专讲 RNN 的训练技巧:
- 包括梯度截断、序列分段(BPTT)、mask/padding、teacher forcing、batch 组织方式等,让 RNN 在实际项目里更稳、更容易调。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 20
20 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)