第5章 大模型概述
本文全面解析了大模型技术,从概念定义到核心技术原理,再到行业应用。大模型是指参数规模达数十亿以上的AI模型,基于Transformer架构,通过海量数据和算力训练而成,展现出强大的通用智能能力。文章详细介绍了大模型训练所需的GPU/NPU硬件、分布式并行训练框架(如DeepSpeed和Megatron-LM),以及Prompt工程、思维链(CoT)、检索增强生成(RAG)和AI Agent等高级应
深度解析大模型:从核心技术原理到行业落地全景指南
文章目录
一、 大模型概览:开启通用人工智能时代
什么是大模型?
大模型是指具有庞大的参数规模(数十亿以上)和复杂程度的人工智能模型,使用上亿级文本语料在大规模算力机器上并行训练而成。这些模型通常在各种领域,例如自然语言处理、图像识别和语音识别等,表现出高度的理解及生成能力,和极强的泛化能力。

人工智能发展历史,走入大模型时代
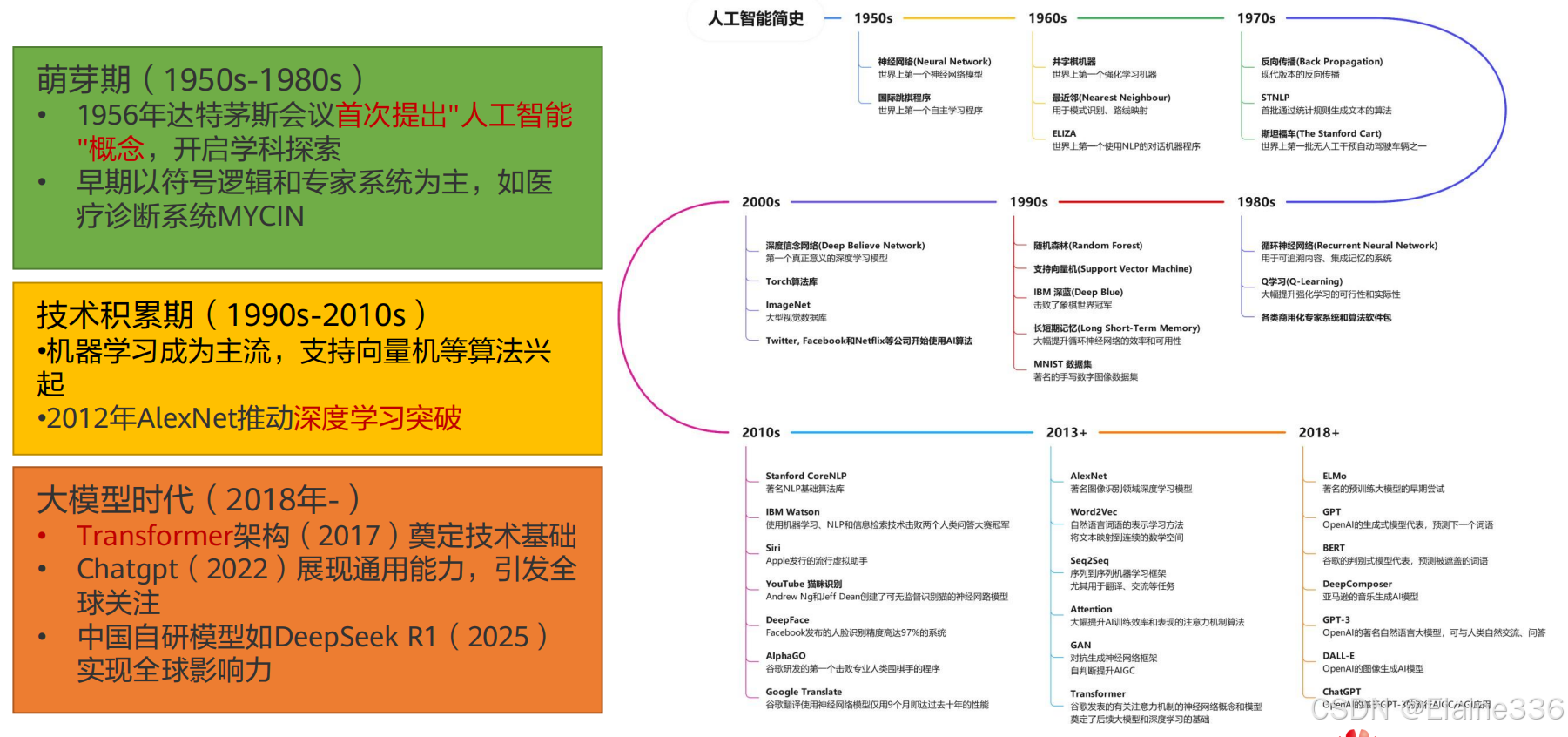
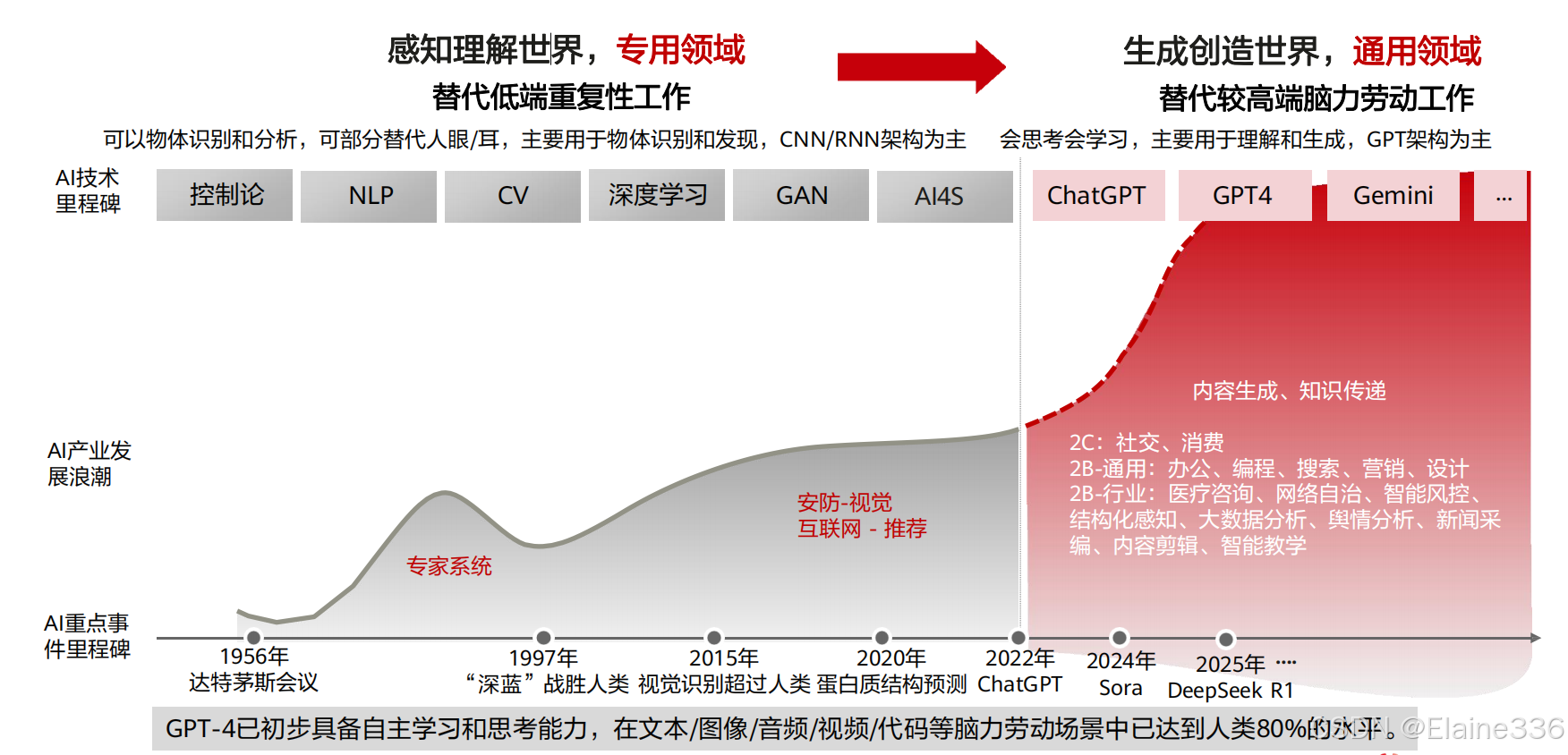
大模型时代——从专用到通用
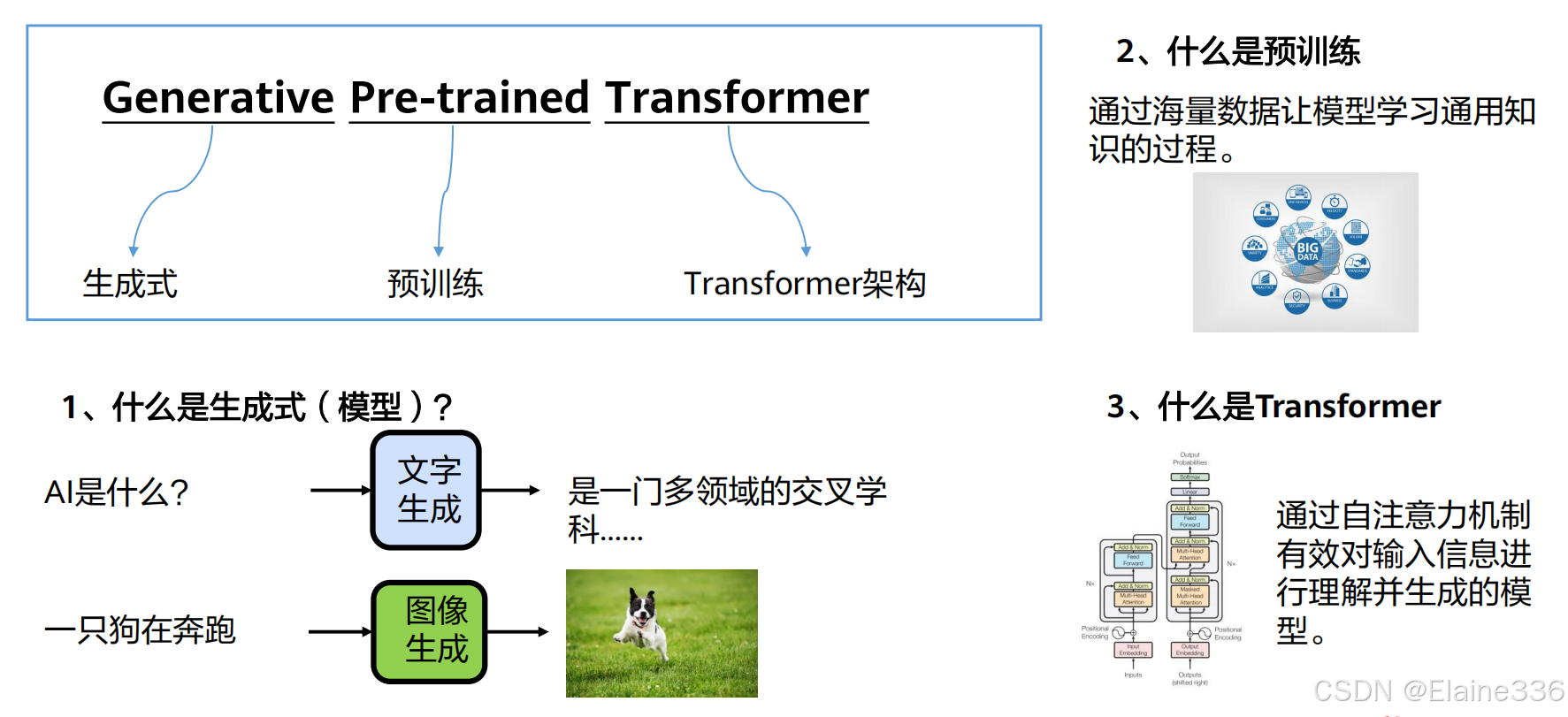
什么是GPT
人工智能模型的开发范式演变

二、 核心技术原理(上):如何炼就“最强大脑”?
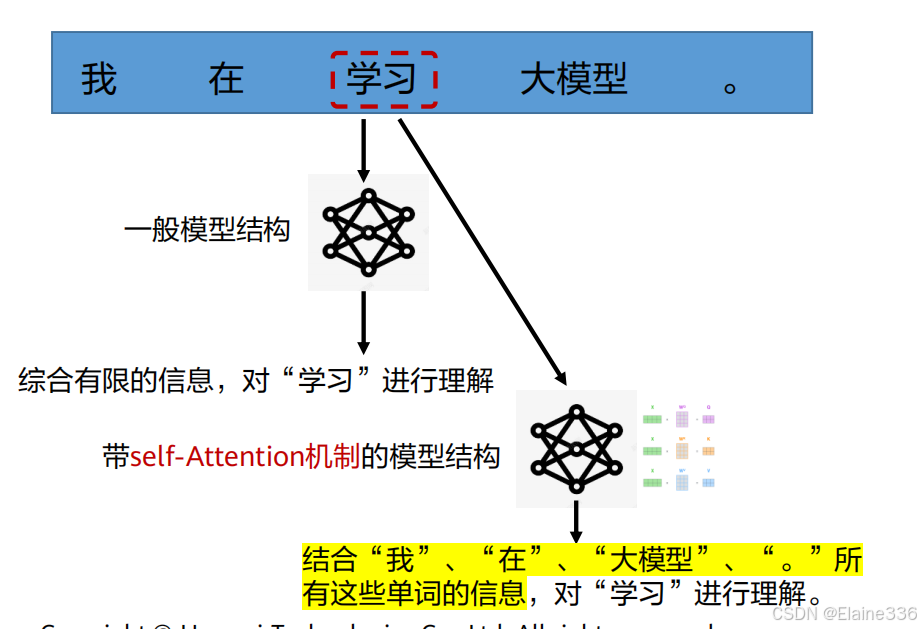
大语言模型核心结构:Transformer结构
- Transformer结构通过集成并优化self-Attention机制,可以同时处理句子中的所有词,捕捉到更多的上下文信息,从而让LLM拥有更强大的语言处理能力。
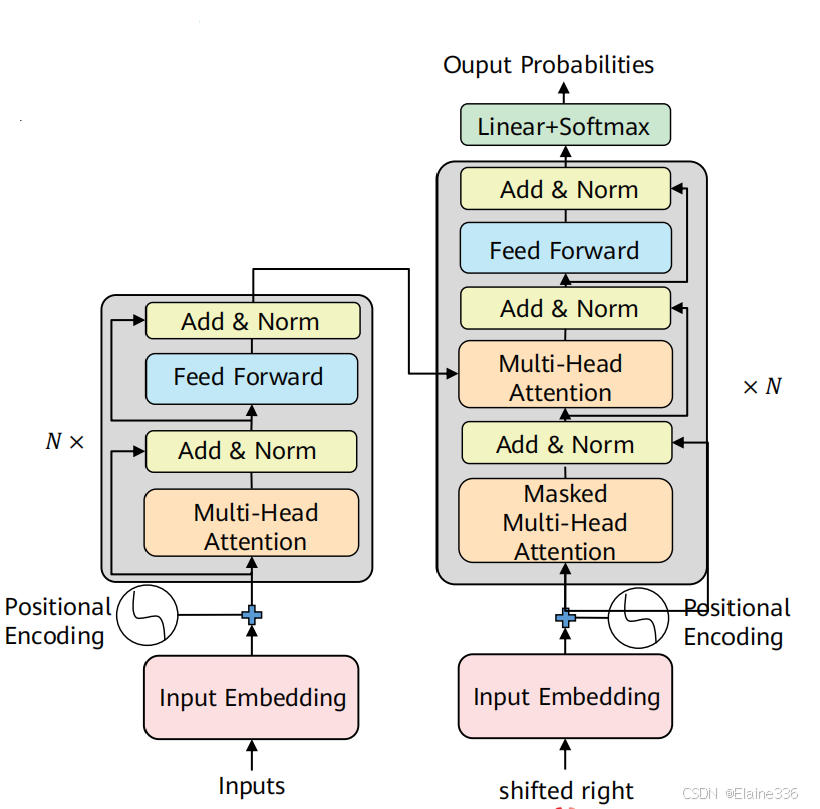
AI计算芯片:GPU与NPU概览
- GPU(Graphics ProcessingUnits,图形处理器):拥有成百上千个小核心,擅长同时处理大量相似任务,天然契合需要大规模密集运算的AI训练。
- NPU(Neural-Network Processing Units,神经网络处理器):在电路层模拟人类神经元和突触一条指令完成一组神经元的处理,在处理神经网络任务时往往比GPU更节能,但是存在灵活性相对较低,生态不够完善以及成本较高的缺点。
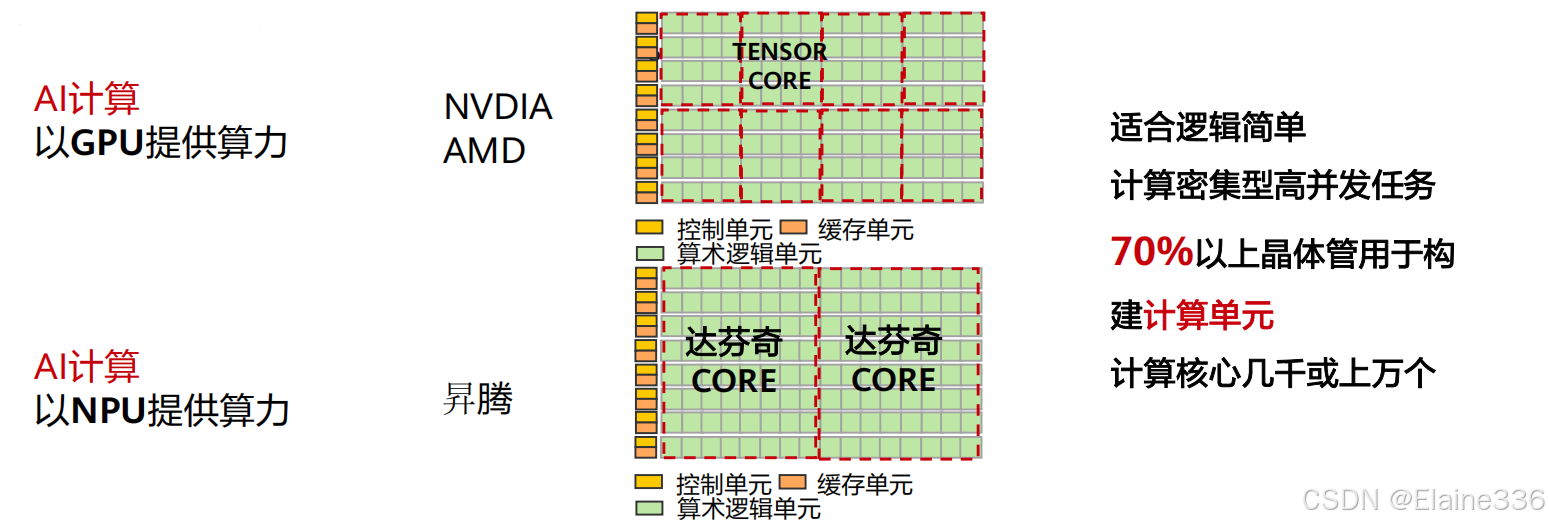
分布式训练框架背景
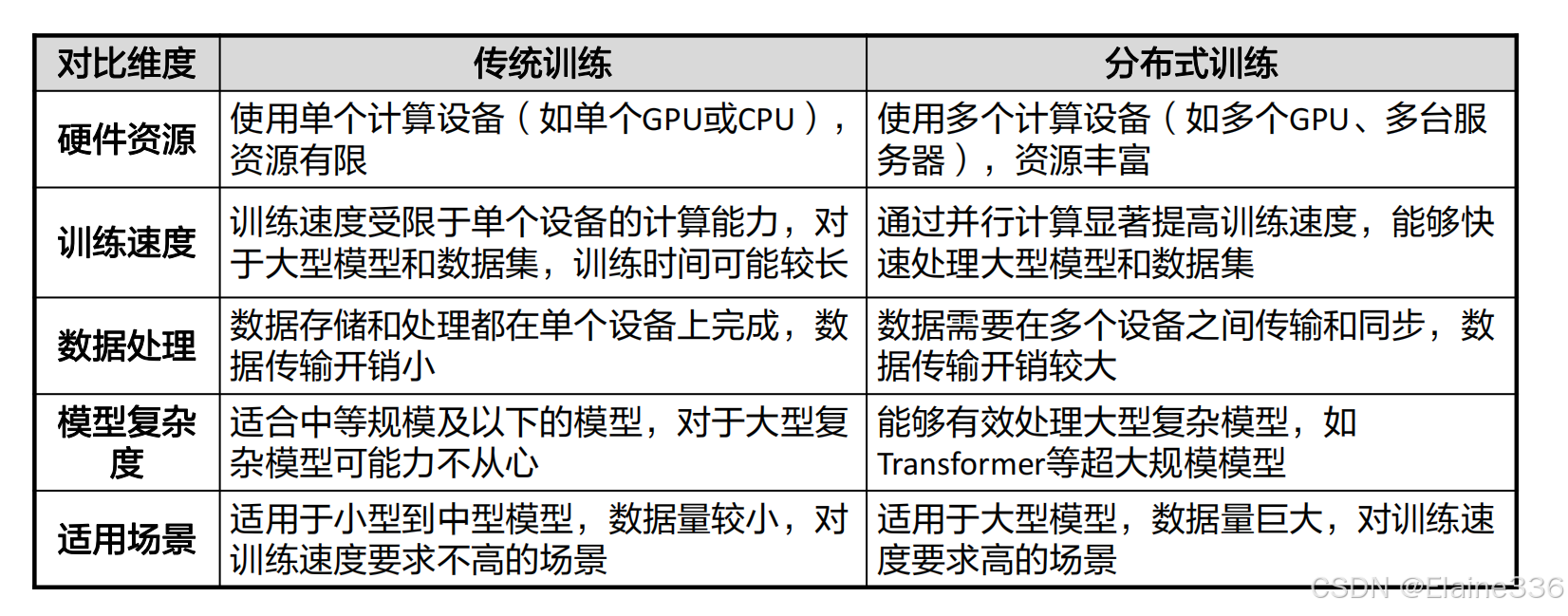
- 传统训练 VS 分布式训练
为什么要分布式训练
加速训练
- 大模型训练需要大量算力和时间,如果用一般的机器,训练大模型时长可长达几年甚至几百年
- 分布式训练提供了并行计算的可能,因此能大幅缩短计算时间
大模型训练
- 大模型提高了许多CV、NLP任务的精度
- 训练大模型是近几年的业界趋势
• 传统训练(单人搬砖):
一个人(单台机器)搬所有砖(任务),累且慢
• 分布式训练(团队搬砖):
分工:10个人(10台机器)同时搬,每人负责一部分
同步:定期汇总成果
加速:原本10天的活,1天就能干完
训练并行模式:数据并行
⚫ 数据并行
每个AI芯片上拷贝一份模型;每个AI芯片计算不同数据的梯度
总体batch size = AI芯片数量 * 每个AI芯片上的batch size
计算量/ AI芯片:梯度
通信量/ AI芯片:同步梯度
可通过数据并行的方式实现常见中小模型的训练
通俗理解:把训练数据分成多份,每块AI芯片用同样的模型训练不同的数据,最后汇总学习成果。
类似“多个学生分章节复习同一本书,最后互相分享笔记”。
训练并行模式:模型并行
模型并行:把模型分布在不同的AI芯片上,几个AI芯片共同维持一个模型。
解决大模型难以在单卡上存储以及训练的问题
根据如何切分模型,可分为横向模型并行和纵向模型并行
通俗理解:由于模型太大,一块AI芯片上装不下了,把大模型拆成几块,放到各块AI芯片上,每个AI芯片负责计算模型的不同部分,最后拼出完整结果。类似“一个工人做不了整个汽车的构建工作,几个工人分别组装汽车的不同零件,最后组合成整车”
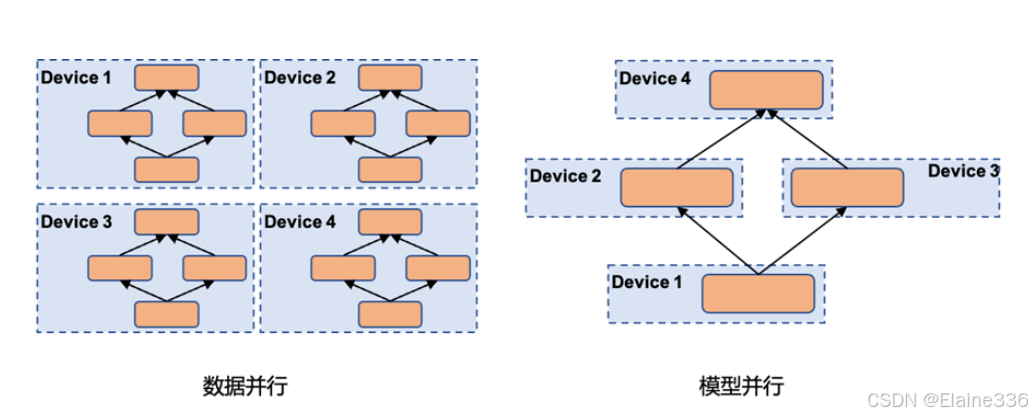
模型并行的时候,如何切分呢?
纵着切(纵向并行):以模型层为单位,将不同层分配到不同的AI芯片上。
横着切(横向并行):将模型的同一个模型层进行切分,存放在不同的AI芯片上。

混合及自动并行
混合并行(Hybrid Parallel)
涵盖数据并行和模型并行的并行模式
Pytorch中需要用户手动切分参数
例:假设有16块NPU,用黑色方框表示,蓝色方框表示一个minibatch,根据模型如何被分割,不同的并行模式可以用下图表示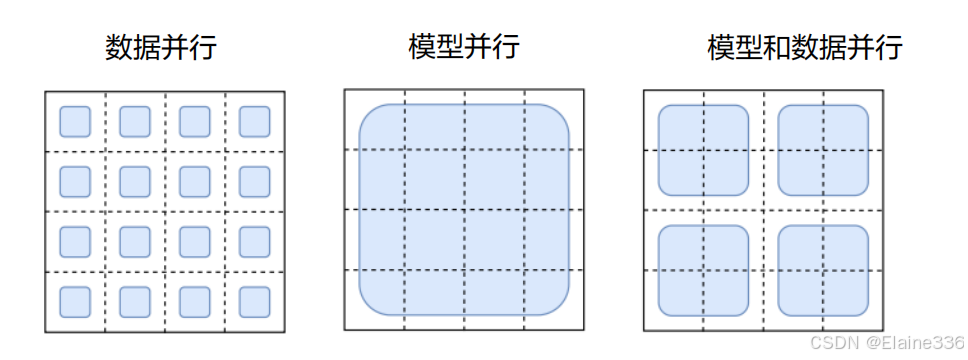
自动并行(Auto Parallel)
融合了数据并行和模型并行,但无需用户手动切分参数
但在MindSpore中,可以自动通过计算开销和通信开销对训练时间建模,并最小化该训练时间以得到合理的数据、模型切分方式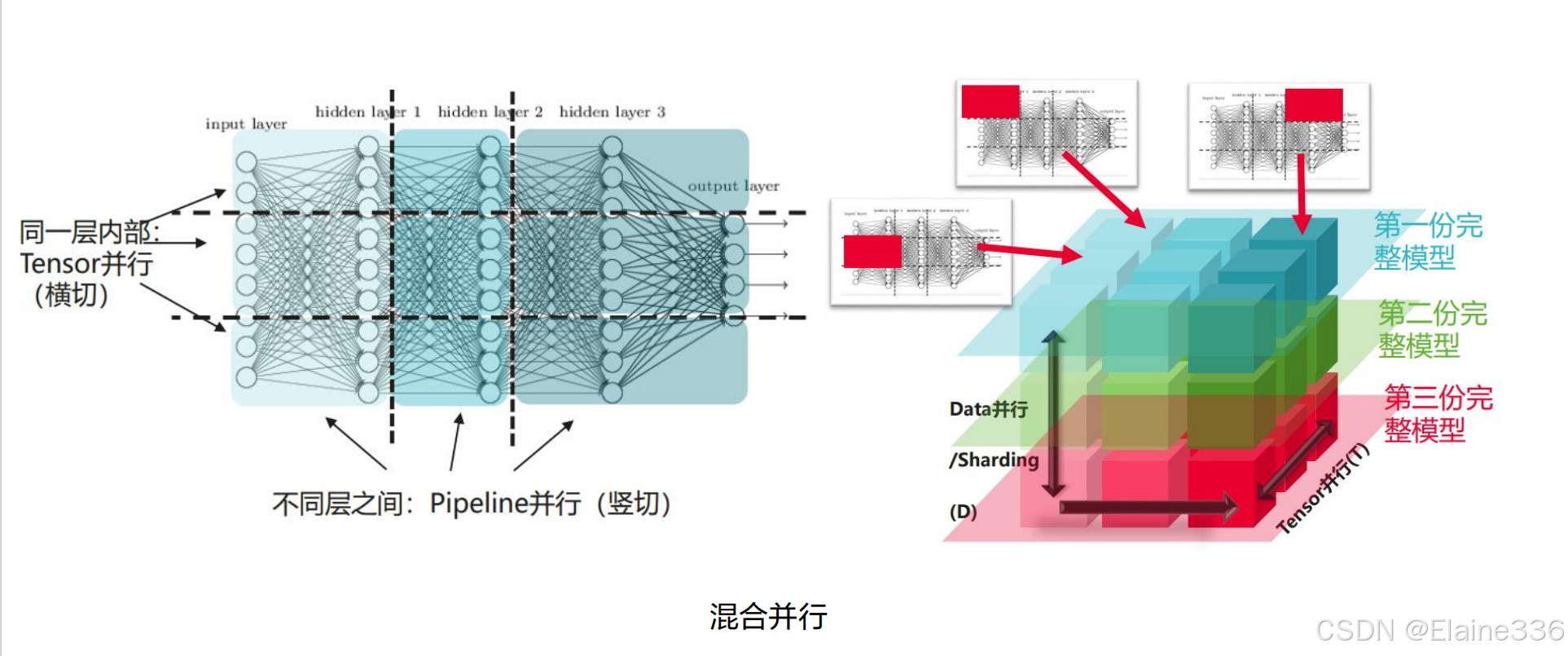
主流分布式并行框架:DeepSpeed
DeepSpeed
微软开发,提高大模型训练效率和可扩展性:
◼ 加速训练手段:数据并行(ZeRO系列)、模型并行(PP)、梯度累积、动态缩放、混合精度等。
◼ 辅助工具:分布式训练管理、内存优化和模型压缩等,帮助开发者更好管理和优化大模型训练任务。
◼ 快速迁移:通过Python Warp方式基于PyTorch来构建,直接调用即完成简单迁移。
主流分布式并行框架:Megatron-LM
Megatron-LM
NVIDIA开发,提高大模型分布式并行训练效率和线性度:
◼ 加速训练手段: 综合数据并行(Data Parallelism),张量并行(Tensor Parallelism)和流水线并行(Pipeline Parallelism)来复现GPT-3 。
◼ 辅助工具:强大的数据处理&Tokenizer,支持LLM & VLM等基于Transformer结构。
三、 核心技术原理(下):大模型的高阶使用技巧
什么是Prompt?
- Prompt:也称为提示词, 是与大模型进行交互的输入,也就是给大模型的指令。可以是一个问题、一段描述、甚至是带有一堆参数的文字。
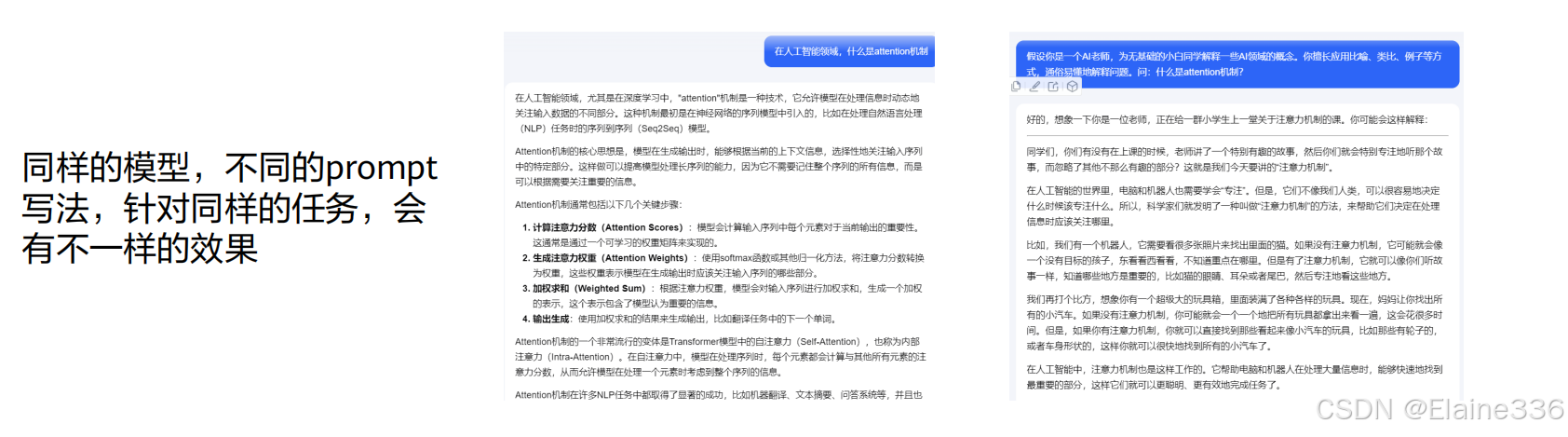
- 提示工程PromptEngineering(PE):大模型生成文本的过程可视为一个黑盒,同一模型下对于同一个场景,使用不同的prompt也会获得不同的结果。prompt工程是指在不改变模型的前提下,通过设计和优化prompt的方式,引导大模型生成更加准确、可靠、符合预期的内容。
如何创建好的Prompt?——以CRISP原则为例


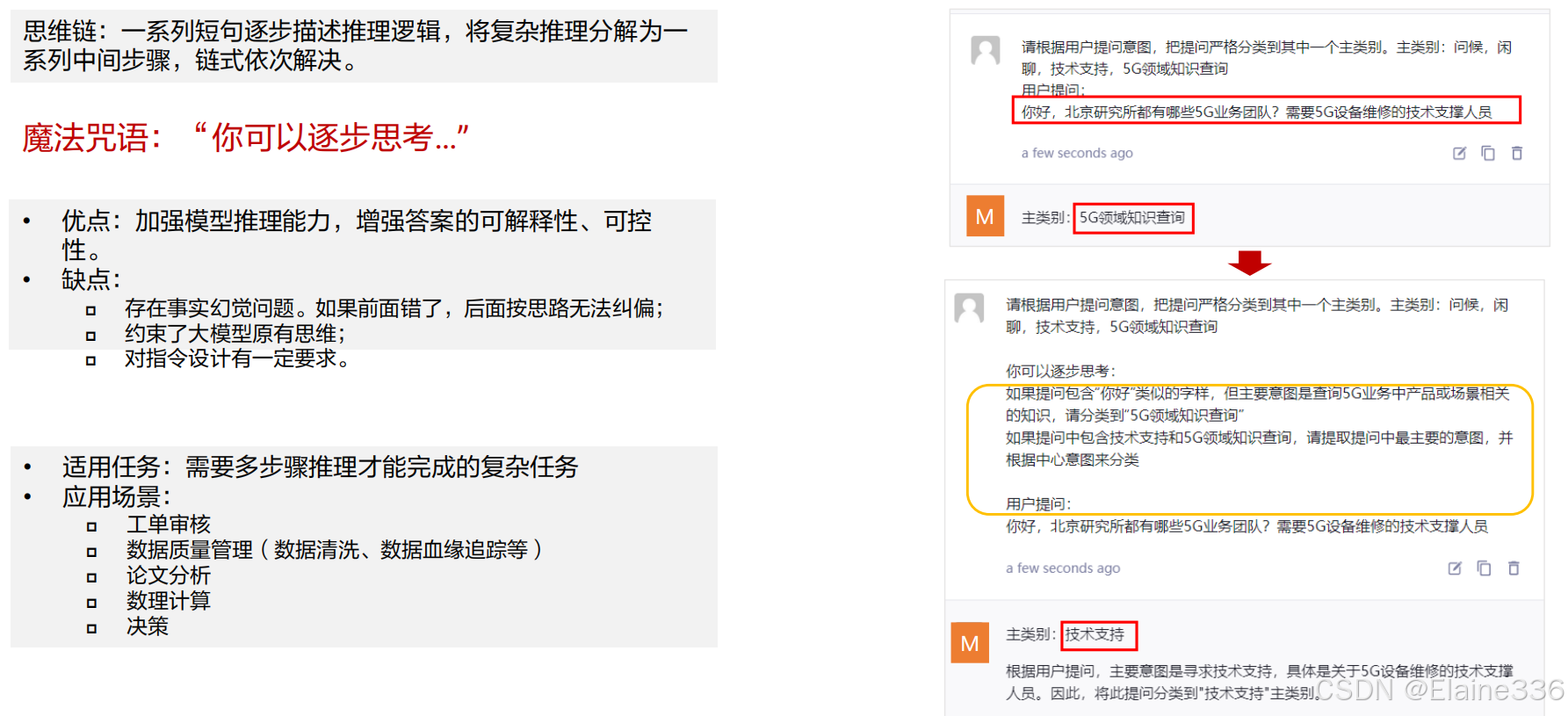
思维链CoT(Chain of Thoughts)
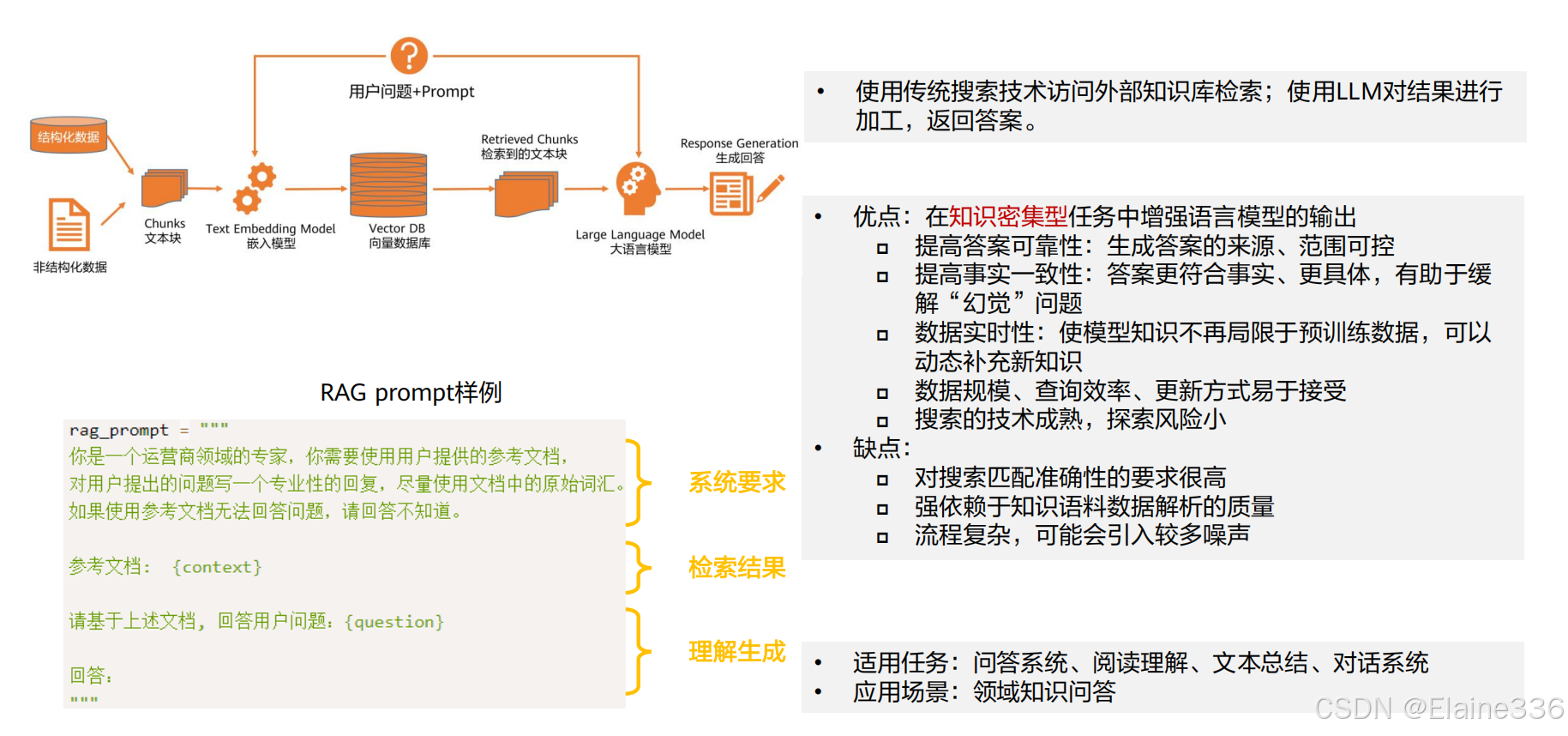
检索增强式生成(RAG)

AI Agent

AI Agent的基本结构
- Agent,是一个高度拟人的计算系统,借助大模型大脑,它能理解所处环境 发生的事情,核心在于自主性的增强,自动化完成连续任务。
- Agent 的典型基础架构: 规划Planning、记忆Memory、工具Tools、行动Action。
- 精简Agent: P(感知)→ P(规划)→ A(行动)
AI Agent核心技术点:工具的使用
在Agent中,如何使用工具,一直是人们关注的一个问题。
MCP(Model Context Protocol,模型上下文协议)是由Anthropic公司于2024年提出的开放协议,旨在标准化大语言模型(LLM)与外部工具、数据源的交互方式,实现“即插即用”的智能化协作。

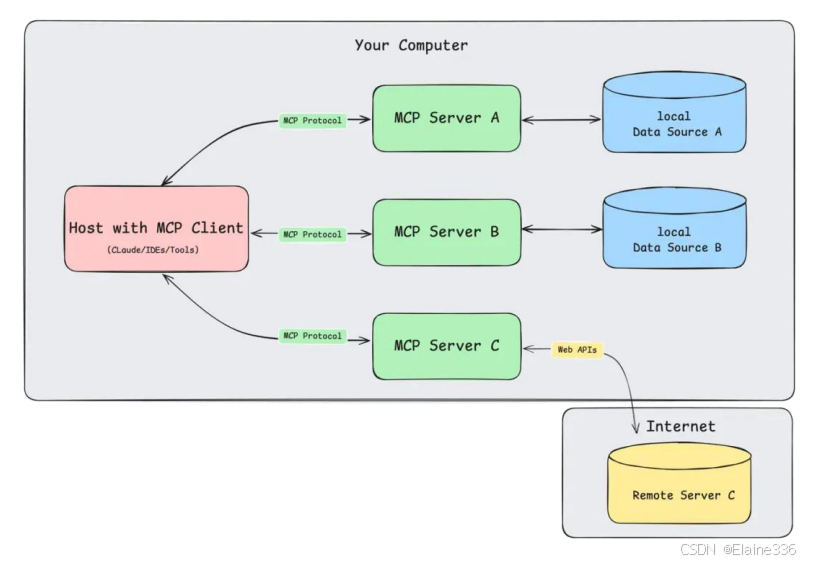
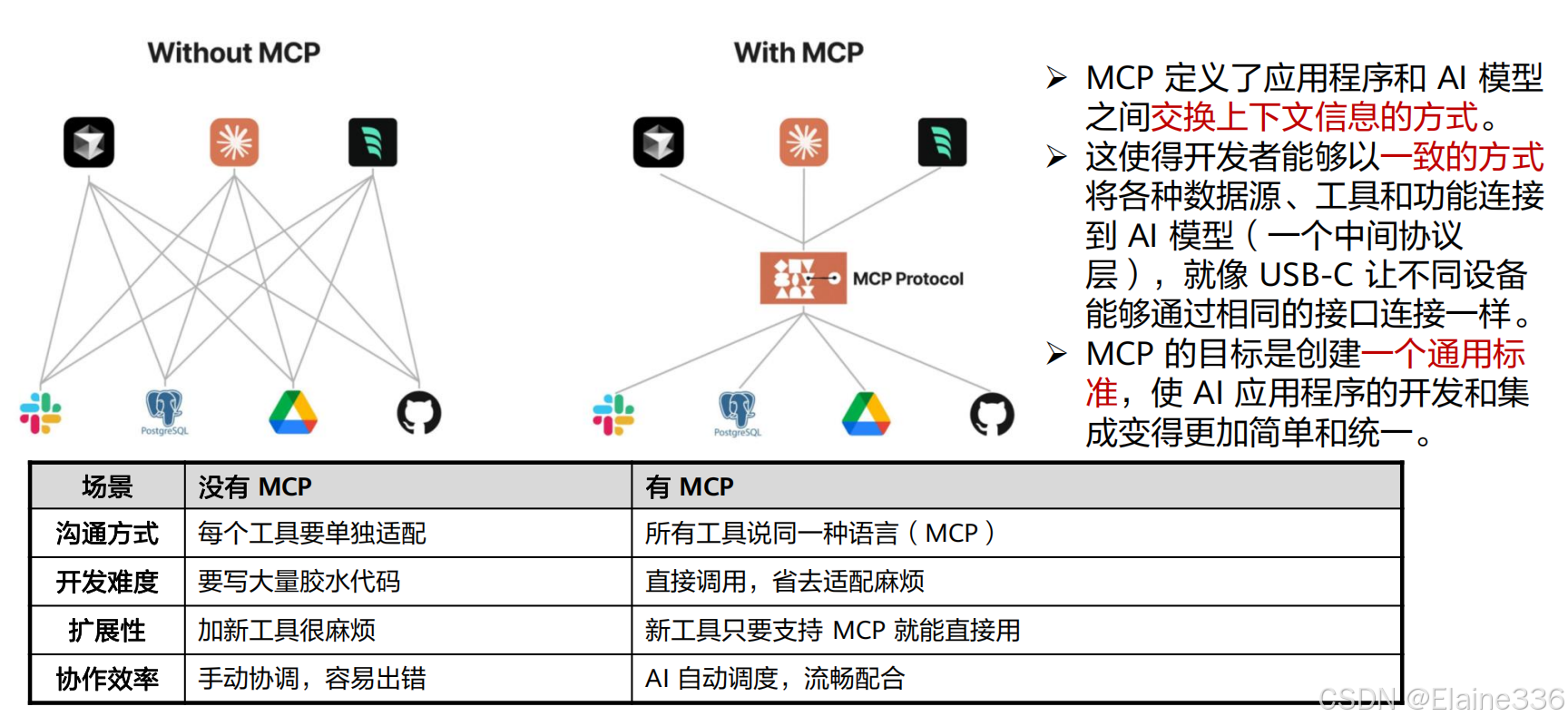
MCP的优势
四、 分层原理:大模型如何赋能千行百业?
大模型分层原理概述
L0通用大模型
- 基于海量通用数据进行训练,具备广泛的通识知识,但是对于行业知识和任务场景know-how缺乏深入了解。
L1领域大模型
- 基于L0的通用大模型,用垂直行业的领域数据进行增量训练,将通用大模型的能力迁移到垂直行业。
L2场景大模型
- 针对特定的应用场景,利用人工标准数据,对领域大模型进行微调,获得应用场景的knowhow认知。同时,基于一些应用技术,如提示工程、思维链、Agent框架、RAG(检索增强生成技术)等,提升领域大模型的场景应用能力。
模型分层:外部视角
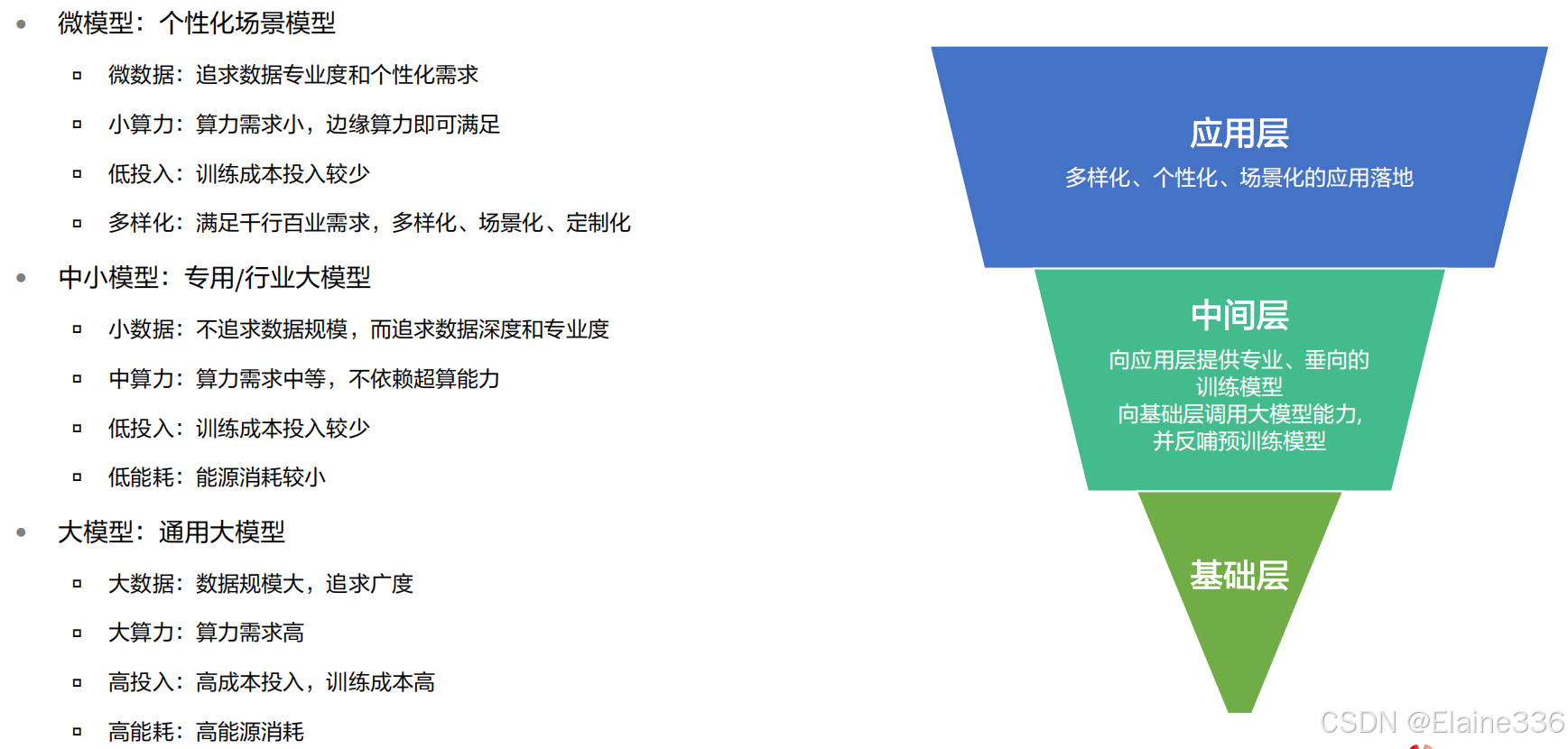
模型分层:盘古大模型的分层思考

大模型落地行业面临的挑战
大模型落地行业面临的几个挑战:
- 通用性强,但专业性弱。落地行业需要具备专业知识,明白行业工作流程,给 出专业准确的回答。
- 知识虽多,但是技能不足。目前通用大模型,多为通用语言大模型,而企业场 景复杂,需要模型能说会唱,能想会算。
- 数据是企业的核心资产之一,大模型可以有效存储和挖掘知识,但是训练和使 用大模型需要保障企业数据的安全合规。
本章小结
- 描述了大模型相关定义、发展历程
- 讲解了大模型关键技术原理
- 讲解了大模型分层的原理和对应的应用场景
文章内容均引用华为云HCCDA-AI内容:若有侵权,联系即删

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 19
19 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)