爆肝解读!UIUC/Stanford/Princeton联合发布:AI Agent开发“四象限法则“,小白也能秒懂的智能体适配避坑指南!
文章解读了UIUC、Stanford等顶尖机构联合发表的《Adaptation of Agentic AI》综述,提出了"Agent Adaptation"统一四象限框架。该框架将Agent进化分为两大方向:Agent Adaptation(改模型内功)和Tool Adaptation(改工具外设),再根据信号来源细分为A1/A2/T1/T2四范式。文章深入分析了各范式的技术路线、权衡利弊,并针对
在 AI Agent 爆发的当下,我们经常迷茫于各种新技术:是该微调模型,还是优化 Prompt?是搞 RAG,还是上 Tool Use?
这篇由 UIUC、Stanford、Princeton 等顶尖机构联合发表的《Adaptation of Agentic AI》综述,可以说是目前关于 Agent 进化路线最系统、最深刻的总结。它并没有单纯地罗列技术,而是以极高的理论高度,提出了一个"Agent Adaptation(智能体适配)"的统一四象限框架,帮我们理清楚:
当 Foundation Model(基座模型)不够用的时候,我们到底是在改模型(Agent Adaptation),还是在改工具(Tool Adaptation)?
它不仅梳理了现有的技术流派(从 SFT 到 RL,从 Toolformer 到 Reflexion),更深刻地揭示了不同技术路线背后的 Trade-off。首次将"改模型"和"改工具"放在同一个维度下思考,明确了 Agent 进化的两个正交方向。提出的 A1 / A2 / T1 / T2 四范式,极大地降低了理解复杂 Agent 系统的认知门槛。针对 RAG 和 Code 两个高频场景的深度剖析,为实际的工程落地提供了直接的选型参考。
可以说,这是一张通往高阶 Agent 开发者的必读“地图”。
本文是系列解读的第一篇。
论文标题:Adaptation of Agentic AI
论文链接:https://arxiv.org/abs/2512.16301
发表机构:UIUC, Stanford, Princeton, Harvard, UC Berkeley, Caltech, UW, UCSD, Georgia Tech, Northwestern, ……
发表日期:2025/12/22
1. Introduction / 简介
1.1 研究背景与痛点:为什么 Agent 还需要"适配"?
即使是现在最强的 Foundation Models(基座模型)(比如 GPT-4, Claude 3.5 等),直接拿来做 Agent 还是不够的。
论文开篇就直击痛点:
虽然 LLM 催生了 Agentic AI systems 的兴起——也就是那些能感知环境、调用工具、管理记忆、执行多步计划的自主系统——但在实际应用中,它们依然面临很多尴尬的问题:
•Unreliable tool use(工具调用不可靠):明明给了工具,却不知道怎么用,或者用错了。
•Limited long-horizon planning(长程规划能力有限):步数一多,容易"迷路"。
•Domain-specific reasoning gaps(特定领域的推理差距):泛化能力强,但专精能力弱。
•Robustness issues(鲁棒性问题):在真实、动态的环境里容易"翻车"。
所以,作者提出了一个核心观点:
“Even highly capable foundation models often require additional adaptation to specialize for particular tasks or real-world scenarios.”
(即使是能力很强的基座模型,通常也需要额外的适配,才能在特定任务或真实场景中"支棱"起来。)
这就是这篇论文的研究动机:我们需要一种系统的方法,去Adaptation(适配)这些系统,让它们从"能用"变成"好用"。
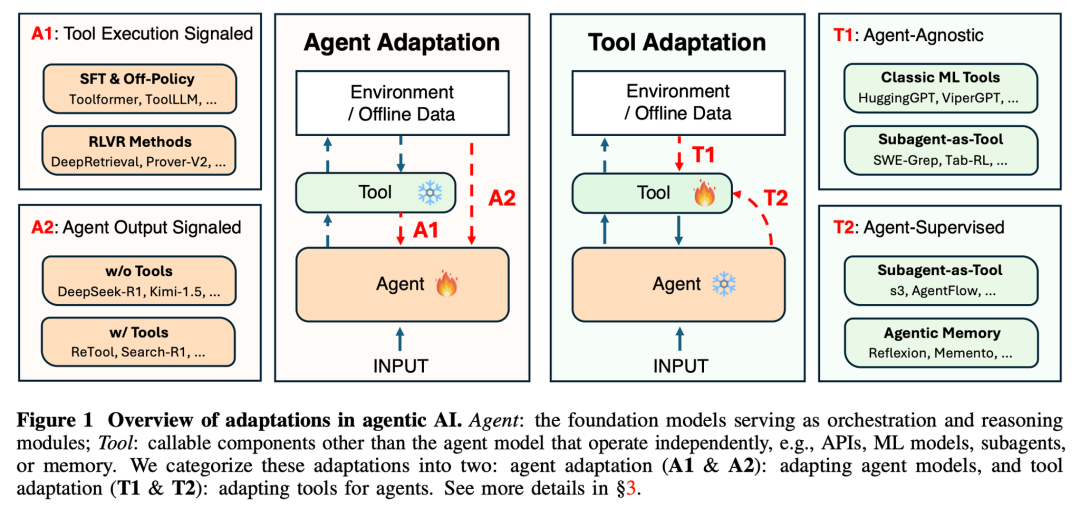
1.2 核心框架:Agent 适配的"四象限"
这篇论文最精彩的地方,在于它没有仅仅罗列一堆方法,而是提出了一个非常清晰的 Unified Framework(统一框架)。
作者把现在的适配方法分成了两个大方向(维度):
1.Agent Adaptation(代理适配):改内功。直接修改 Agent 的内部参数(比如 Fine-tuning 或 RL)。
2.Tool Adaptation(工具适配):改外设。Agent 不动,我们去优化它用的工具(Retriever、Planner、Memory 等)。
基于这两个方向,又根据"信号来源"的不同,进一步细分成了四个象限(Paradigms)。这部分是全篇的理论基石,非常值得细看:
🔥 Agent Adaptation(改 Agent)
这是我们最熟悉的思路,把模型本身通过训练变得更强。
•A1: Tool Execution Signaled Agent Adaptation(工具执行信号驱动)
◦思路:看结果说话。比如写代码,代码跑通了就是好,跑不通就是坏。
◦信号来源:Verifiable outcomes(可验证的结果),如代码沙盒的返回、API 的调用结果。
•A2: Agent Output Signaled Agent Adaptation(Agent 输出信号驱动)
◦思路:看思路和答案。比如通过人类反馈(RLHF)或者模型自己生成的推理链(CoT)来评价好坏。
◦信号来源:Evaluations of its own outputs(对输出的评估),比如 Final Answer 的正确性或 Preference scores(偏好打分)。
🛠️ Tool Adaptation(改工具)
这是通过优化环境来适应 Agent,也是这篇论文特别强调的一个趋势。
•T1: Agent-Agnostic Tool Adaptation(与 Agent 无关的工具适配)
◦思路:造好轮子。训练一个通用的、强大的工具(比如一个通用的检索模型),谁来用都行。
◦特点:Independent of the frozen agent(独立于冻结的 Agent)。
•T2: Agent-Supervised Tool Adaptation(Agent 监督的工具适配)
◦思路:量身定做。Agent 觉得这个工具不好用,我们就根据 Agent 的反馈来调整这个工具。
◦特点:Signals derived from the agent’s outputs(信号源自 Agent 的输出)。
1.3 关键结论与权衡(Trade-offs)
在选择这四种策略时,作者给出了非常务实的 Trade-offs(权衡) 分析,这对于我们做技术选型非常有参考价值:
- Cost and Flexibility(成本与灵活性)
•改 Agent (A1/A2):贵,但上限高。需要训练大模型,算力消耗大,但能从根本上改变行为。
•改工具 (T1/T2):便宜。只优化外部组件,成本低,但在 Agent 本身能力太弱时可能"带不动"。
- Generalization(泛化性)
•T1 (通用工具):通常在不同任务间泛化性最好,因为是基于广泛数据训练的。
•A1 (看执行结果):容易 Overfit(过拟合) 到特定的环境里(比如只会做这几道代码题),除非小心地加正则化。
- Modularity(模块化)
•T2 (定制工具):非常灵活,工具升级不需要重训 Agent。
•A1/A2 (改 Agent):可能会有 Catastrophic forgetting(灾难性遗忘) 的问题,学了新任务,忘了旧任务。
1.4 本章小结
第一章实际上为全文奠定了一个基调:Agentic AI 的进化,不仅仅是把 Model 越做越大,更在于如何灵活地"适配"任务。
接下来的章节(我们将会在后续报告中解读),论文将会详细拆解这四个象限里的具体技术(比如 SFT, RLVR, Toolformer, Reflexion 等等),并给出具体的应用案例。

2. Background / 背景知识
在深入探讨具体的"适配"方法论之前,论文在第二章先为我们铺垫了两个核心概念的地基:
1.Agentic AI Systems(代理 AI 系统):到底什么是 Agent?它由哪些零件组成?
2.Adaptation(适配):当我们说"适配"时,通常指哪些手段?(这里主要回顾了传统的 Prompt 和 Fine-tuning)。
这一章看似基础,但作者对 Planning(规划) 和 Memory(记忆) 的分类非常有洞察力,并且明确界定了本文的研究范围。
2.1 Agentic AI Systems / 代理 AI 系统
什么是 Agentic AI?
作者给出的定义是:能够感知(Perceiving)、推理(Reasoning)、行动(Acting),并通过与环境交互不断改进(continuously Improving through interaction with their environment)的自主 AI 系统(autonomous AI system)。
这类系统不再是简单的"问答机器",而是为了解决复杂的、开放式的任务而生。
📝Note: 本文主要聚焦于 Single-agent systems(单智能体系统)。虽然现在 Multi-agent 很火,但单智能体是基础。搞懂了单体如何感知、规划和行动,是理解多智能体协作的前提。
一个典型的 Agentic AI 系统,核心是一个 Foundation Model(基座模型,通常是 LLM),它是大脑。但光有大脑不够,还得有"三头六臂"。论文将这些扩展组件归纳为三个关键模块:
1) Planning Module(规划模块)
这是 Agent 的"战略指挥部",负责把一个大目标拆解成一步步可执行的小行动。作者根据 Feedback Integration(反馈集成) 的程度,敏锐地将规划分为两类:
•Static Planning(静态规划):
◦代表技术:Chain-of-Thought (CoT), Tree-of-Thought (ToT)。
◦特点:一条路走到黑,或者预先想好几条路。
•Dynamic Planning(动态规划):
◦代表技术:ReAct, Reflexion。
◦特点:Incorporate feedback(整合反馈)。根据环境的反馈或者之前的行动结果,动态调整计划。这对于长程任务至关重要。
Q: 为什么 Dynamic Planning 是 Agent 的分水岭?
A: 很多人做 Agent 发现效果不好,往往是因为只用了 CoT(静态)。但在真实世界里,第一步往往会出错(比如 API 调不通),如果不能根据错误(Feedback)动态修正计划(Dynamic),整个任务链条就会断裂。Reflexion 的核心价值就在于此。
2) Tool Use(工具使用)
这是 Agent 的"手和脚",让它能突破模型内部知识的限制(Internal knowledge limitations)。
•常见工具:Web Search, APIs, Code Execution。
•关键技术词汇:Model Context Protocols (MCPs), Browser Automation Frameworks。
3) Memory Module(记忆模块)
这是 Agent 的"记事本",用于保持 Long-term consistency(长期一致性)。
•Short-term memory:记当前任务的上下文。
•Long-term memory:跨会话持久化存储,积累经验。
•关键技术:RAG (Retrieval-Augmented Generation)。
特别注解:关于 Memory 的归类
虽然 Memory 是 Agent 的一部分,但在这篇论文的框架里,作者做了一个很有趣的区分:
如果 Memory 是一个外部的、可优化的组件(比如一个 Retriever 或者一个可更新的数据库),作者把它归类为 Tool Adaptation (T2)。
也就是说,“记忆"被视为一种可以被优化的"工具”。
2.2 Adaptation / 适配
如果说 Foundation Model 是“通才”,那么 Adaptation 就是让它变成“专才”的过程。
作者将现有的适配机制主要归为两大类:Prompt Engineering 和 Fine-Tuning。
Prompt Engineering(提示工程)
•定义:一种Lightweight(轻量级)的适配形式。
•核心机制:Without modifying underlying parameters(不修改底层参数)。通过设计Input Context(指令、示例、约束)来引导模型行为。
•优势:高效、易迁移(Easily transferable)。
•代表系统:CAMEL、AutoGen、MetaGen、ChatDev。
Fine-Tuning(微调)
•定义:通过更新核心模型的Internal parameters(内部参数)来实现适配。
•核心机制:让模型内化(Internalize)新的知识、推理模式或行为倾向。
•Granularities(粒度):全量 vs 高
◦Full fine-tuning:改所有参数。灵活但贵。
◦PEFT (Parameter-Efficient Fine-Tuning):只改一小部分。
▪关键技术:LoRA (Low-Rank Adaptation)。这是目前的工业界标准,平衡了效率和性能。
•Paradigms(范式):不仅仅是 SFT
◦除了我们熟知的SFT (Supervised Fine-Tuning)这种"模仿学习",作者特别强调了基于反馈的微调方法,这也是Agent 进化的关键:
◦Preference-based(基于偏好):
▪关键技术:DPO (Direct Preference Optimization)。让模型对齐人类(或自动化)的偏好信号。
◦RL-based(基于强化学习):
▪关键技术:PPO (Proximal Policy Optimization)、GRPO (Group Relative Policy Optimization)。
▪核心洞察:通过与Evaluative environments(可评估环境)交互来优化行为。
Deep Dive:为什么 Agent 适配越来越依赖 RL (PPO/GRPO) 而不是 SFT?
A:SFT 只能教 Agent “怎么做是对的”(Imitation),但很难教 Agent “怎么做是好的"或者"从错误中恢复”。
Agent 的任务通常是多步的,中间一步错了可能全盘皆输。RL (Reinforcement Learning)允许 Agent 在环境中试错,根据最终结果(Reward)来调整策略,这对于培养 Agent 的Planning和Robustness至关重要。尤其是GRPO,近期在推理模型(如 DeepSeek-R1)中大放异彩,证明了RL 在提升推理能力上的巨大潜力。
3. Overview of Adaptation Paradigms / 适配范式概览
在这一章,作者正式抛出了那个统一的分析框架。为了把事情说清楚,作者先做了一件非常"学术"但又极具工程价值的事情:定义符号(Mathematical Notations)。
只有统一了语言,我们才能把五花八门的 Agent 优化方法(比如 RAG、ReAct、Toolformer)放到同一个维度下来比较。
让我们跟随作者的思路,从数学符号开始,一步步拆解这四大适配范式。
3.1 Mathematical Notations / 数学符号体系
在开始讲具体方法前,我们先建立一套"数学词典"。作者把 Agent 系统里的核心要素抽象成了三类:Targets(改谁)、Data Sources(数据从哪来) 和 Objectives(目标是什么)。
1. Adaptation Targets(适配目标:改谁?)
•Agent (\mathcal{A}):
◦系统的核心大脑,参数为 \theta。
◦适配手段:更新参数(Parameter updates)、优化 Prompt(Prompt refinement)。
•Tool (\mathcal{T}):
◦扩展 Agent 能力的外部组件(Retrievers,Planners,Executors)。
◦关键洞察:作者特别把 Memory Module(记忆模块) 也归类为 \mathcal{T}。 这是一个非常独特的视角——记忆被视为一个动态的、可更新的数据库,本质上和工具一样,是服务于 Agent 的。
2. Adaptation Data Sources(数据源:信号从哪来?)
•Offline Data (\mathcal{D}):离线数据。比如人类标注的 Demo、合成的轨迹日志。
•Environment (\mathcal{E}):在线环境。Agent 与环境实时交互产生的反馈信号。
3. Adaptation Objectives(适配目标:优化的终点)
•Objective Function \mathcal{O}(\cdot):衡量表现的函数。
◦离线时:通常是 SFT Loss(监督微调损失)。
◦在线时:通常是 Success Rate(任务成功率)或 Reward(奖励)。
Q:为什么把 Memory 归类为 Tool?
A: 在传统的认知里,Memory 似乎是 Agent 的一部分。但作者认为,Memory 是一个"被动"被查询和更新的模块。
当 Agent 需要信息时,它会像调用 Search Engine 一样去 Query Memory。因此,优化 Memory(比如优化存什么、怎么存),本质上和优化一个 Retriever(检索器)是一样的逻辑。这种归类大大简化了后续的分析框架。
3.2 Four Adaptation Paradigms / 四种适配范式
基于上面的定义,作者提出了全篇最核心的 Unified Framework(统一框架)。这个框架由两个维度交叉而成:
1.Optimization Target(优化谁):是改 Agent (\mathcal{A}),还是改 Tool (\mathcal{T})?
2.Optimization Signal(信号来源):信号是来自 Tool Execution(工具执行结果 yyy),还是来自 Agent Output(Agent 最终产出 ooo)?
这两两组合,就诞生了四个经典的范式:A1, A2, T1, T2。
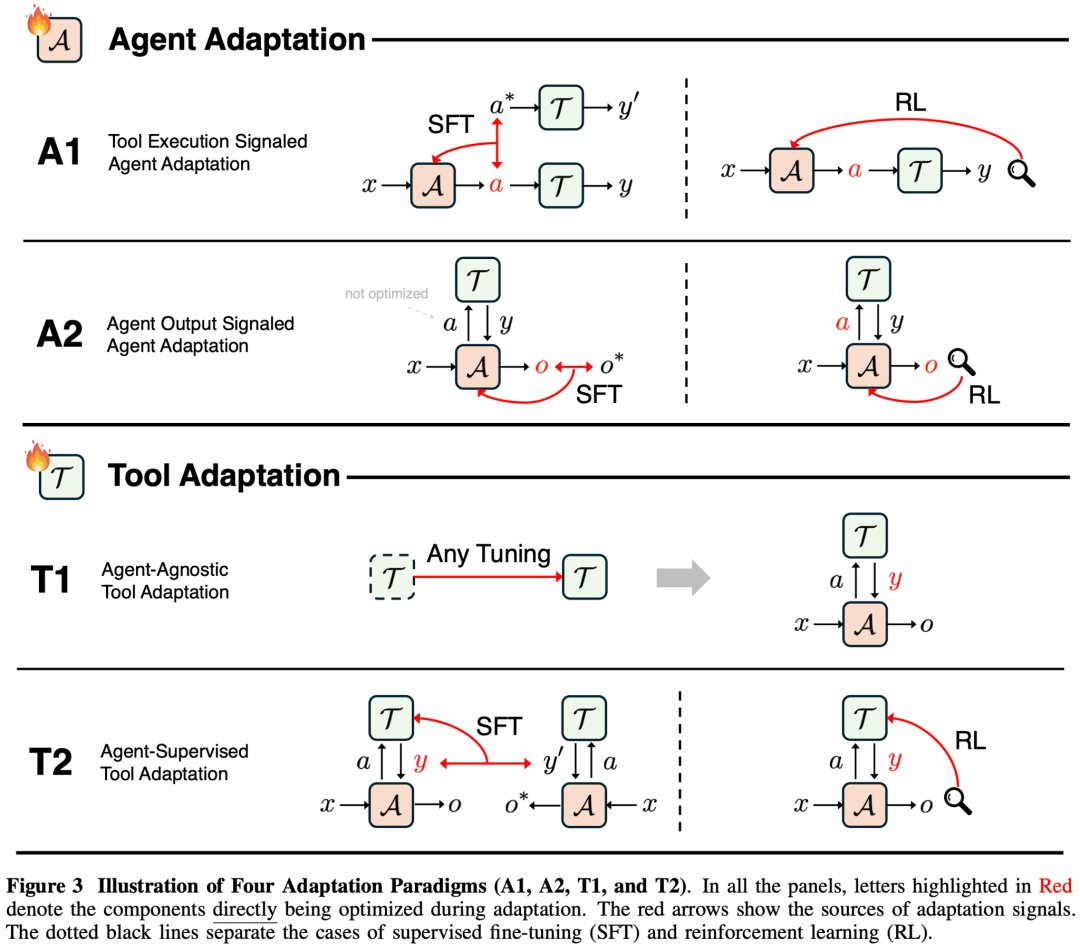
3.2.1 A1:Tool Execution Signaled Agent Adaptation(工具执行信号驱动)
核心逻辑:“结果导向,工具说了算。”
Agent 产生一个动作 a,工具 \mathcal{T} 执行后产生结果 y。我们直接用这个结果 y 的好坏来训练 Agent。
•流程:
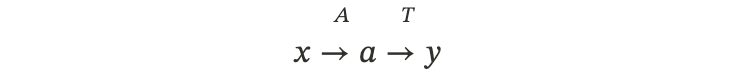
•优化目标:
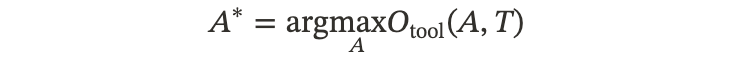
◦这里 \mathcal{O}_{\text{tool}} 衡量的就是 y 的质量(比如代码能不能跑通,检索回来的文档对不对)。
•这种范式主要有两种实现路径:
1.SFT (Supervised Fine-Tuning):
•收集一堆"成功"的案例\mathcal{D}_{\text{succ}} = {(x, a^*)},直接让 Agent 模仿那个能产生好结果的动作 a^*。
•公式本质:\arg \max \log p_{\mathcal{A}}(a^*|x) (模仿专家动作)。
2.RL (Reinforcement Learning):
•Agent 自己去试,根据工具返回的 RewardR = \mathcal{O}_{\text{tool}}(y) 来更新策略。
•比如:DeepSeek-R1 (Code) 就是典型的例子,代码通过测试就给奖励。
3.2.2 A2: Agent Output Signaled Agent Adaptation(Agent 输出信号驱动)
核心逻辑:“不管黑猫白猫,抓到老鼠(最终答案对)就是好猫。”
Agent 调用工具只是中间过程,我们不直接评价工具用得好不好,而是看 Agent 最终生成的答案 o 对不对。
•流程:
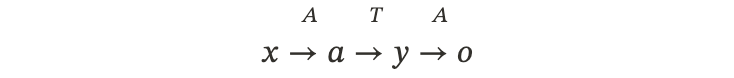
•优化目标:
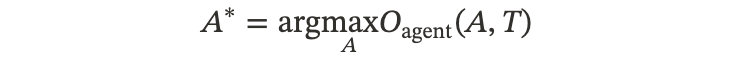
◦这里 \mathcal{O}_{\text{agent}} 衡量的就是 agent 输出的最终答案o 对不对。
•这一范式主要包含两种实现路径:
1.Supervised Fine-Tuning (SFT):
•场景:拥有包含问题 x、可选的中间工具输出 y、参考动作 a^* 和最终正确答案 o^* 的数据集 \mathcal{D}_{\text{ans}}。
•关键点:虽然信号来自最终输出,但为了防止 Agent “偷懒”(不学工具只猜答案),通常需要结合工具调用的监督。
核心洞察:为什么 A2 的 SFT 公式必须包含两部分?
如果只奖励最终答案 o(\log p(o*|x,a*,y)),模型可能会"偷懒"——它发现不用工具也能瞎猜对答案,或者完全不学怎么调用工具 a。
所以,作者强调,有效的 A2-style SFT 必须是混合的:
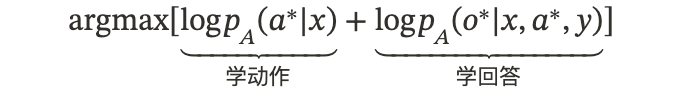
既要学"怎么调用工具",又要学"怎么利用工具结果生成答案"。
2.Reinforcement Learning (RL):
•场景:没有标准答案,或者只关注最终结果的质量(如用户满意度)。
•机制:Agent 获得的奖励 R = \mathcal{O}_{\text{agent}}(o)完全取决于最终输出 o 的质量。
•特点:Agent 需要通过试错(Trial and error)来探索出最佳的工具使用策略,以最大化最终的奖励。
3.2.3 T1: Agent-Agnostic Tool Adaptation(与 Agent 无关的工具适配)
核心逻辑:“造一把通用的好锤子。”
不管是谁来用,这个工具本身要足够强。Agent (\mathcal{A}) 是锁死的(Fixed),我们只训练 Tool (\mathcal{T})。
•典型场景:
◦训练一个通用的 Dense Retriever(稠密检索器)。
•优化目标:
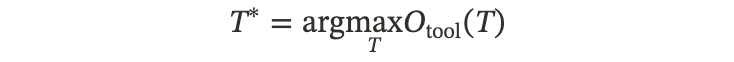
◦完全不看 Agent 的脸色,只看检索准确率(Recall, nDCG)。
3.2.4 T2: Agent-Supervised Tool Adaptation(Agent 监督的工具适配)
核心逻辑:“为这个 Agent 量身定制一把锤子。”
这是这篇论文非常强调的一个趋势。现在的 Agent(如 GPT-4)往往是闭源的、不可微调的(Closed-source)。那怎么提升性能?改工具来配合它!
•流程:Agent 不动,根据 Agent 最终的产出 o 好不好,反过来优化工具 \mathcal{T}。
•优化目标:
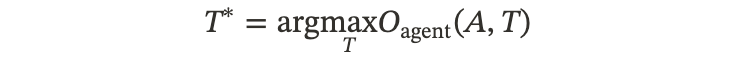
◦注意这里的下标是 \mathcal{O}_{\text{agent}},意味着工具好不好的标准,是看它能不能帮这个特Agent 答对问题。
•这一范式主要包含两种实现路径:
1.Supervised Learning(监督学习):
•核心思想:利用冻结 Agent 的反馈信号来指导工具改进。具体包含两种高阶技巧:
◦Quality-Weighted Training(质量加权):Agent 答得好的那些数据,给工具训练时的权重高一点。
◦
Output-Consistency Training(输出一致性):这有点像"蒸馏",强迫工具的输出能诱导 Agent 产生特定的好答案。
2.Reinforcement Learning (RL):
•核心思想:直接把 Agent 最终的产出质量作为 Reward。
•机制:让工具去探索什么样的输出(比如检索什么样的文档)能让 Agent 获得最高的奖励 R = \mathcal{O}_{\text{agent}}(o)。
Deep Dive:记忆(Memory)也是 T2?
前面提到 Memory 被归类为 Tool。在这里,Memory 的更新机制完美契合 T2 范式:
Agent 是固定的,它读写 Memory。我们通过优化"写入什么记忆"或"检索什么记忆"(即 Update(\mathcal{M}, o)),来让 Agent 未来的表现更好。
本质上,优化记忆,就是在一个固定的大脑旁,挂一个可学习的"外挂硬盘"。
3.3 Illustrative Examples / 典型案例解析
为了将抽象的四象限理论落地,作者选取了 Agentic AI 中最两个核心的应用场景——RAG(检索增强生成) 和 Code Execution(代码执行)——进行了深入的对比分析。
这两个场景极具代表性:RAG 代表了 Knowledge-intensive(知识密集型) 任务,而 Code Execution 代表了 Reasoning-intensive(推理密集型) 任务。
3.3.1 Scenario I: Retrieval-Augmented Generation (RAG) / 检索增强生成
在 RAG 系统中,Agent(Generator)需要从外部知识库中检索信息来回答问题。
Agent Adaptation (改模型):A1 vs A2
•A1:Tool Execution Signaled(关注检索质量)
◦机制:我们直接评价 Agent 发出的 “Search Query” 好不好,或者检索回来的 “Document” 对不对。
◦例子:Self-RAG。它训练模型去预测检索到的文档是否相关(IsRel)。如果模型能判断出"这个文档没用",它就获得了奖励。
◦核心逻辑:只要过程(检索)对了,结果大概率是对的。
•A2:Agent Output Signaled(关注回答质量)
◦机制:我们不关心 Agent 搜到了什么(甚至搜错了也没关系),只关心它最后给用户的 Answer 对不对。
◦例子:RA-DIT。它直接根据最终答案的正确性来更新 LLM 的参数。
◦核心逻辑:黑盒优化。只要能答对,过程可以容忍噪声。
Tool Adaptation (改检索器):T1 vs T2
这是最能体现"适配"思想的地方。
•T1:Agent-Agnostic(通用检索器)
◦现状:这是目前的默认做法。我们用 BM25 或者预训练的 BERT/Contriever。
◦目标:最大化 Relevance(语义相关性)。Query 和 Doc 长得像就是好。
◦局限:它不知道下游是谁在用它。
•T2:Agent-Supervised(专用检索器)
◦创新:训练检索器的目标不再是"语义相关",而是"对 Agent 有帮助"。
◦案例:REPLUG。它把 LLM 当作一个黑盒打分器。对于同一个 Query,如果检索出文档 A,LLM 答对了;检索出文档 B,LLM 答错了。那么检索器就会被更新,倾向于检索文档 A——即使文档 A 在语义上可能不如 B 那么匹配。
◦Deep Insight:Utility > Semantics(效用大于语义)。这就是 T2 的核心哲学。
3.3.2 Scenario II: Code Generation with Execution / 代码生成与执行
在需要复杂推理(如数学、数据分析)的场景中,Agent 往往需要写代码并运行。
A1:Tool Execution Signaled(关注代码能否跑通)
•信号来源:Execution Feedback(执行反馈)。
•标准:代码能编译吗?不报错吗?通过 Unit Test 了吗?
•优势:反馈非常客观、硬核(Hard constraint)。
•案例:AlphaCode 或 DeepSeek-R1 (Code)。只要代码通过测试用例,就视为成功。
A2:Agent Output Signaled(关注最终推理结果)
•信号来源:Final Reasoning Outcome(最终推理结果)。
•标准:比如做数学题,代码怎么写不重要,重要的是打印出来的那个数字是不是答案。
•优势:容忍度高。有时候代码写得烂一点,或者用了一种奇怪的方法,只要算出对的数就行。
•案例:STaR (Self-Taught Reasoner)。模型生成 reasoning trace(包含代码),只要最终答案对,这就作为一条正样本训练自己。
Summary Table / 总结对比
| Paradigm / 范式 | Target / 优化对象 | Signal Source / 信号来源 | Philosophy / 核心理念 | Representative Works / 代表工作 |
| A1 | Agent / 智能体 | Tool Execution (Intermediate) / 工具执行(中间过程) | Process-oriented / 过程导向 | Toolformer,Self-RAG,WebGPT |
| A2 | Agent / 智能体 | Final Output (End-to-End) / 最终输出(端到端) | Outcome-oriented / 结果导向 | ReAct (SFT),RA-DIT,STaR |
| T1 | Tool / 工具 | Frozen / Pre-defined / 冻结/预定义 | General Purpose / 通用组件 | Contriever,BM25 |
| T2 | Tool / 工具 | Agent’s Success / 智能体的成功 | Specialized / Custom / 专用/定制 | REPLUG,ColBERT-QA |
阅读提示:
1.本文是系列解读的第一篇,主要介绍了论文提出的核心框架——Agentic AI Adaptation 的四象限分类体系 (A1/A2/T1/T2),理解 Agent 进化的基本概念、研究动机以及技术权衡。
2.请关注后续更新,我们将继续深入解读 Agent 适配(Agent Adaptaion)、工具适配(Tool Adaptation)等精彩内容。
3.本综述引用了大量里程碑式的研究工作。对于这些重要的子论文,我们后续也会推出专门的深度解读文章,帮助大家把书读厚再读薄。
那么,如何系统的去学习大模型LLM?
作为一名深耕行业的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献492条内容
已为社区贡献492条内容

所有评论(0)