2025大模型行业发展总结与2026趋势预测:从竞赛到落地!
AI大模型竞赛已进入周级节奏,技术优势不再是护城河。智能成本持续下降,推动生成式AI应用即将大规模爆发。AI正从Chatbot向Agent转变,但面临多步复合误差挑战。传统行业专业领域因"认知负载结构性超载"而快速采纳AI。2026年将迎来AI应用爆发期,关键是从Bolt-on模式转向AI-First产品理念,将60分模型做成生产级产品。
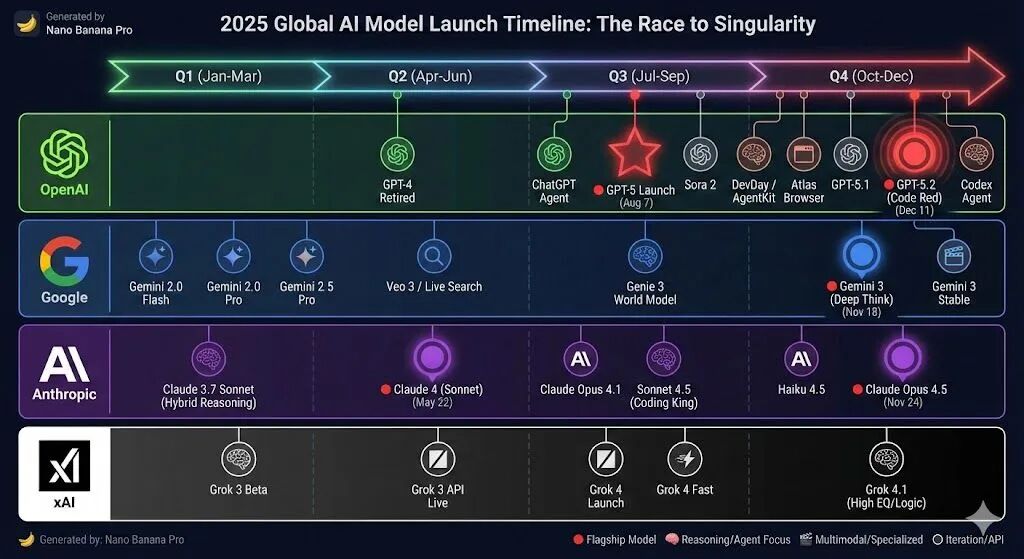
过去一个月有点跟不上AI发展的节奏。11月17日 xAI Grok 4.1在LMArena登顶,第二天就被Gemini 3 Pro超了。Anthropic跟着一周后的11月24日就发Claude Opus 4.5。OpenAI感受到Gemini 3的威胁后马上启动"Code Red",三周内12月11日发布了GPT 5.2。
各类Benchmark排行榜的第一把交椅的轮换,从12个月的窗口期,缩短到不到3周。
上周和一个做Agent的创业者聊,他说现在最大的焦虑不是技术不够好,而是"下个月模型又变了,我的护城河还在吗?" 整个行业都很焦虑。过去几年一直在AI应用一线摸爬滚打,我个人倒是感觉很充实。
2025年就剩几天了,借机对AI的一些想法做个总结,顺便也对过去一年写的文章做个分类梳理。
一、2025年的几个观察
1. 竞赛进入周级节奏
 by Nano Banana Pro
by Nano Banana Pro
2025年是各大厂大模型发布最密集的一年。尤其是过去一个月,xAI、Google、Anthropic和OpenAI四家公司前后脚发布了最新的旗舰模型,每次新的模型后都“不出意外”地登顶各类排行榜。
Benchmark排行现在更像一个市场工具,结果就是各家在榜单上交替当第一。Gemini 3在benchmark上超GPT-5.1后,Sam Altman发"Code Red",把GPT-5.2从12月下旬提前到12月9日,然后又冲到榜单第一。
但实际的竞争在转向。LLM技术优势不再是护城河,嵌入用户工作流的深度和实际价值才是。每次新模型发布后很多的所谓"评测",都是各自的一些局部场景。从全局分布看,差异并没有想象中的大。
Benchmark dominance不能当作真正的领先指标。
2. 智能成本持续下降
Pre-training → Post-training → Test-Time Computing。智能从昂贵的训练阶段,转移到相对便宜的推理阶段。Test-Time Computing让模型在推理时"think longer"来提升质量,通过更复杂更长的COT就能达到更好的效果。
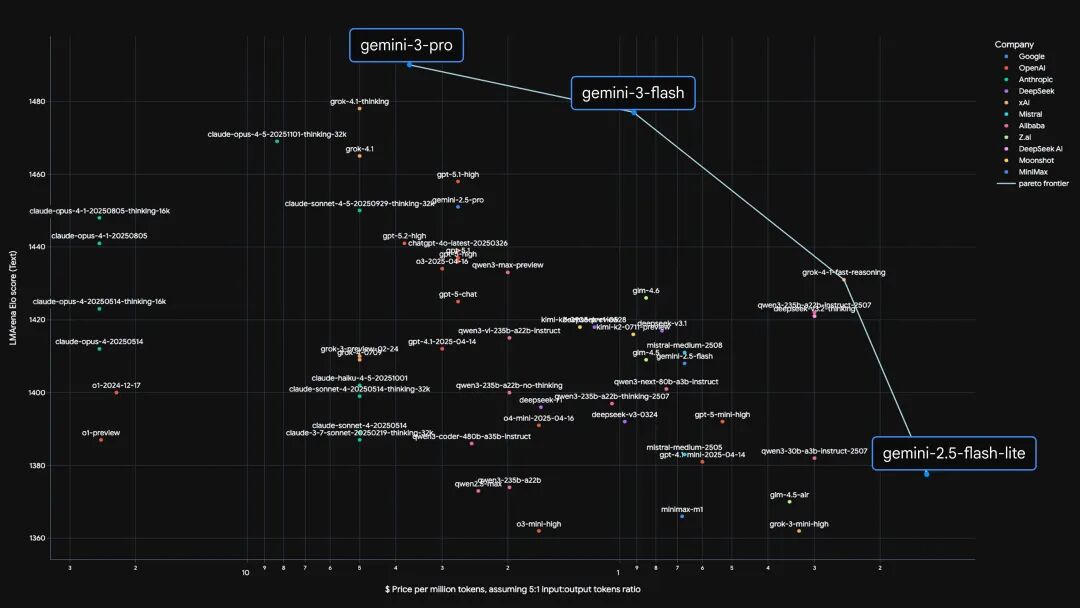 Source: Gemini 3 Flash: frontier intelligence built for speed, Google
Source: Gemini 3 Flash: frontier intelligence built for speed, Google
上面的Pareto frontier on performance vs. cost图可以很好地跟踪大模型效果和成本变化趋势,可以看到过去几年模型的效果快速提升,但成本在持续下降。以2025年的价格变化为例,几家的定价数据对比(2025年初 → 2025年末):
- Claude Opus: 75 → 25(降幅:67%/67%)
- GPT-5系列: 15 → 14(降幅:65%/7%)
- Gemini Flash: 2 → 3(降幅:50%/-50%)
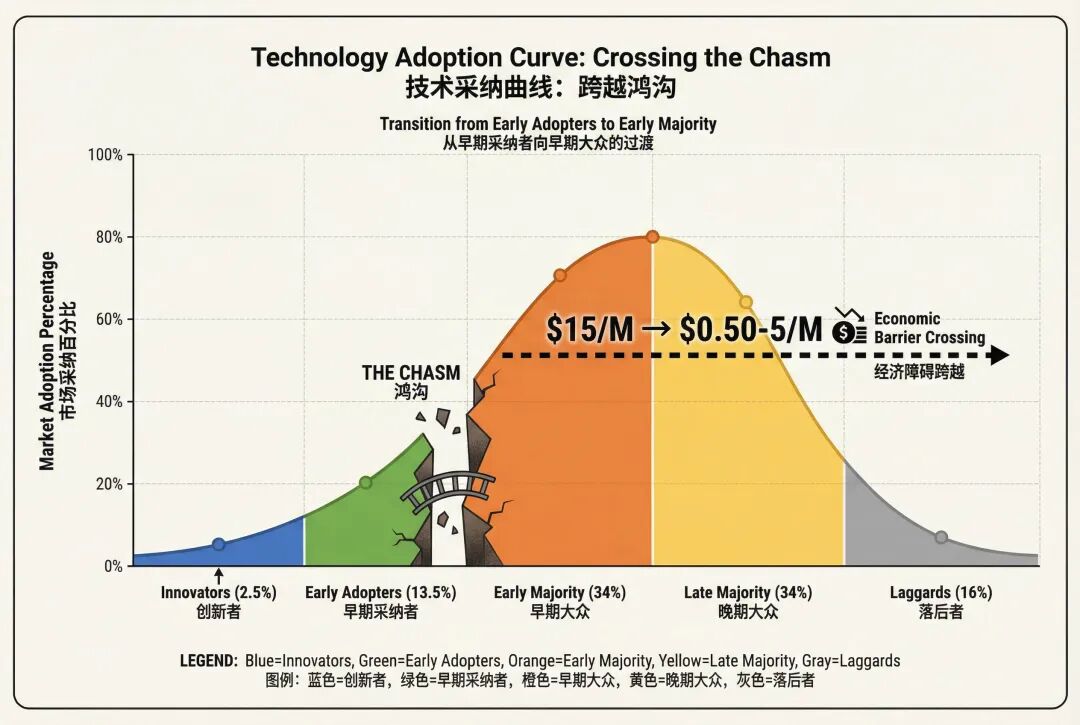 by Nano Banana
by Nano Banana
对于每一次重大科技变革,成本下降到一定程度是大规模普及的前提。当前token的成本对大多数场景来讲已经足够便宜了,根据Technology Adoption Cycle, 生成式AI应用的大规模爆发即将跨越Early Adopters到Early Majority的鸿沟。
2026年应该会看到生成式AI技术的大规模采纳加速。
3. 从生成到行动(Chatbot -> Agent)
 参考OpenAI的AGI Level,2025正从Level 2(Reasoner)向Level 3(Agents)跨越。
参考OpenAI的AGI Level,2025正从Level 2(Reasoner)向Level 3(Agents)跨越。
以Coding Agent为代表的各类Agent成了2025年AI应用场景最靚的仔儿,AI Coding方向的ARR已经达到上百亿美金。无论是Claude Code,GPT Code-x,AntiGravity还是Cursor等目前都已经可以多步骤重构、写测试、自己调bug。从年初的chatbot、copilot,已经成为程序员的co-worker。
尽管2025年在医疗、法律、金融、客服等场景有非常多的AI Agent公司出现了爆发式增长,但Level 3从技术层面面临一个突出问题:多步复合误差的指数放大。
即使单步准确率99%的agent,执行50步后整体准确率降至60%。95%准确率的agent在多Agent级联后会迅速崩溃。每一步的微小偏差在长链条中被指数级放大。
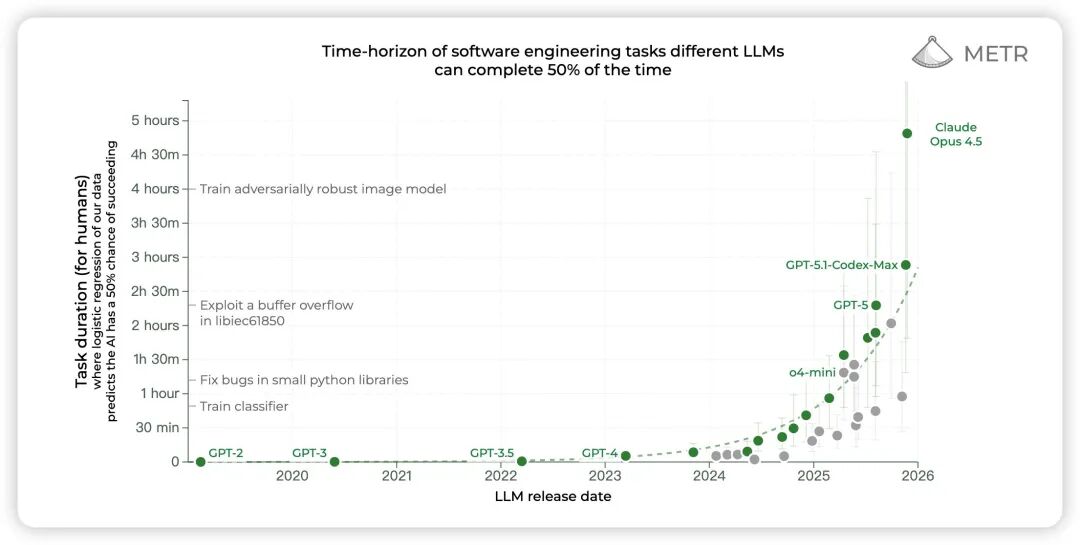 Source: METR
Source: METR
判断Agent能力的一个主要标准在场景内多步复杂长时间任务(long-time horizon tasks)的完成度。METR的最新数据Claude Opus 4.5已经可以自主完成人工需要近5个小时完成的任务了,而且这个时长的增长趋势一直在持续。
我经常和团队开玩笑,Agent现在90%的问题都是"工程问题"。解决方案不是追求"第一天100分",而是构建"动态成长"架构。让Agent在运行过程中接收信号、整合知识、持续进化。比如DAG式的任务分解,可验证性设计,状态隔离机制,Context Engineering,Tool Use, Skills,Observability, Redundancy, Rollback or Handover等等。
问题不是能不能做,是谁先做出production-ready的效果。
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

4. 试点到生产的断层(Pilot -> Production Gap)
MIT有个报告称95%的AI试点项目无法投产。尽管这是统计结果,但现实我认为也差不多是这个比例。
Demo很炫,POC通过了,业务部门很兴奋。然后项目就卡在"准备投产"阶段,一卡就是6-12个月,最后不了了之。
为什么?
一是隐形技术债务的指数级增长。试点用100条精选数据,准确率95%。生产用100万条真实数据,格式混乱、缺失值20%+,准确率崩到70%。
看到过一些实际案例。某零售公司的AI库存预测,试点时90%以上准确率。上生产后发现供应商数据延迟、促销数据未同步、库存盘点误差15%——预测准确率直接掉到60%以下,比人工还差。
二是现有业务系统集成复杂度爆炸。某银行AI信贷审批,试点时3秒返回结果。上了生产要调用12个老系统接口,平均响应时间45秒,超时率18%。为满足5秒SLA,重构整个数据架构,花了8个月。
组织层面的阻力更要命。技术部门说ready了,业务说工作流要重构、谁培训?财务说试点花了好几万投产还要几十万?法务说合规问题解决了吗?每个部门都有自己的屁股和顾虑。
这些问题在2026年会迎来转折。工程化工具链开始成熟,产品化思维取代项目制,Production-ready的标准开始量化,比如可解释性、可观测性、可靠性、可维护性等等。
实际生产环境比的不是"谁的模型最强",是"谁能把60-80分的模型做成生产级产品"。
5. 传统行业的快速AI采纳
 Source: Battery
Source: Battery
医生在用AI做临床笔记。律师在用AI检索判例。会计在用AI处理合规。
这些人通常最抗拒新技术,现在却是最快的adopters。这一点有点反常识。
为什么?
这些专业面对的不是"工作效率"问题,是"认知负载结构性超载"。医学知识每73天翻倍。律师要检索的判例库指数增长。会计准则复杂度远超出单个人类记忆容量。
SaaS工具只是将工作流数字化,并没减少认知负担。AI将"信息处理"从瓶颈转为自动化背景,让专业价值回归判断和决策。
2026年传统行业的扩散路径可能会不同。不是从技术岗位向非技术岗位渗透,更可能是从"信息密度最高、工作流最复杂"的专业知识领域向外扩散。
二、2026年的几个判断
从2月份春节期间的DeepSeek爆火开始,2025整个AI行业整体都是欣欣向荣。2026年将去向何处,沿Value Chain自下而上简单聊聊。兼听则明。
1. 基础设施层: 还不是AI bubble,电和卡的供不应求局势丝毫不会改变,甚至加剧
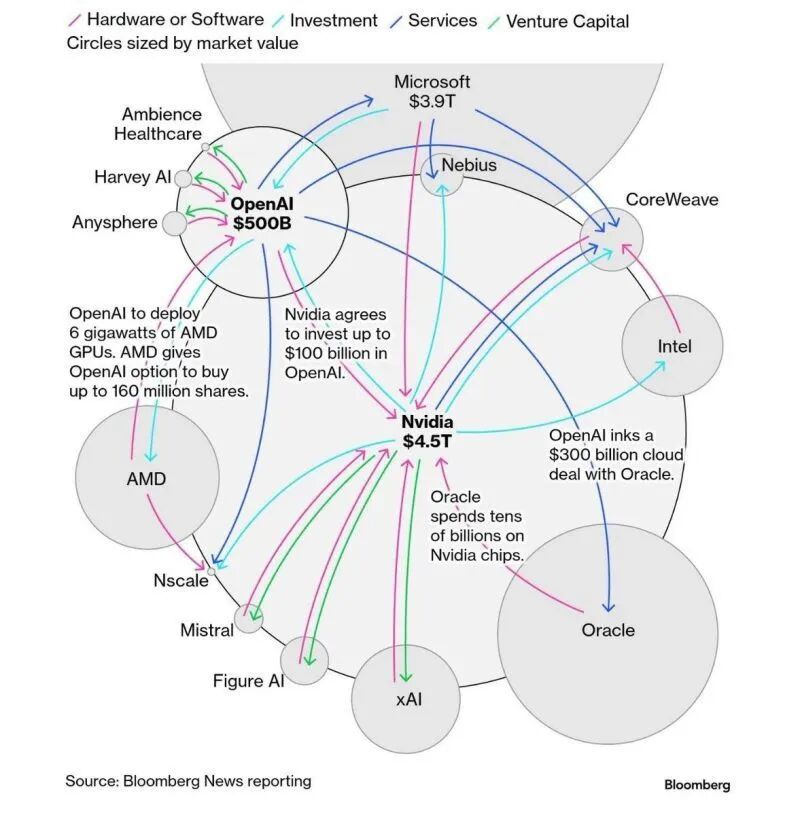 Sam Altman的1.4万美元算力规划和狮子大开口的融资需求,以及巨头们的循环绑定让市场开始担心AI Bubble。OpenAI、Google、Microsoft、Meta、xAI、Anthropic等等都在到处抢各种形式的电,抢建AI DC,抢GPU/TPU卡。
Sam Altman的1.4万美元算力规划和狮子大开口的融资需求,以及巨头们的循环绑定让市场开始担心AI Bubble。OpenAI、Google、Microsoft、Meta、xAI、Anthropic等等都在到处抢各种形式的电,抢建AI DC,抢GPU/TPU卡。
看起来疯狂,但2-3年内我认为还不是泡沫逻辑。这次AI Bubble的源起,主要是市场担心这么多算力基建,会不会像2000年互联网泡沫一样,需求不足而导致算力过剩。
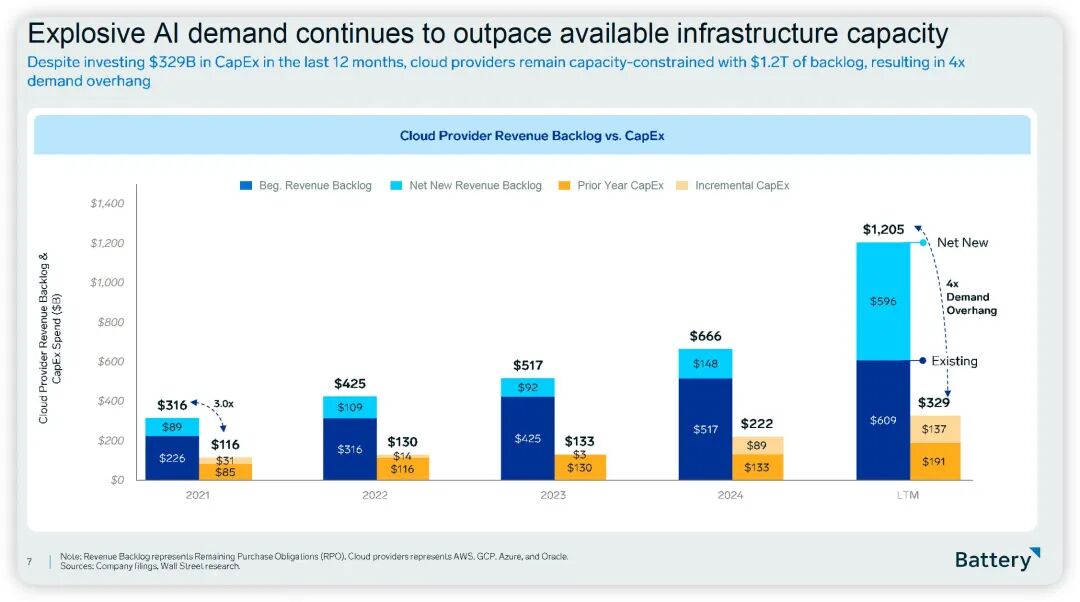 329B CapEx。1.2T订单积压。4:1供需缺口。
329B CapEx。1.2T订单积压。4:1供需缺口。
上面这张图说明了目前需求是超级旺盛的,供不应求。当前算力需求投入主要在训练阶段,但未来更大规模的算力需求在推理阶段。当Agent应用爆发时,推理请求会指数级爆炸式增长,而训练需求随着厂商的收敛和大模型能力的提升增长速度可能会变慢。
“负向滚雪球”
Altimeter Capital的Freda Duan提出了一个简化的理解框架,算起来很简单:
- 第一年训练成本:1
- 第二年训练成本:10 (Scaling Law)
- 第二年收入:2 (上一年成本的2倍)
- 现金流:2 - 10 = -8
因此,大模型厂商每一年都比上一年烧的钱更多,最后只有两种终局:
终局1: Scaling Law停了。模型规模触及物理瓶颈,或者训练10倍更大的模型不再带来10倍能力提升。成本增长停滞,而收入继续增长,这个时候利润率瞬间飙升。
终局2: 收入倍数暴涨。不再是2倍上一年训练成本,而是5倍、10倍,比如可能出现了killer app.
OpenAI、Anthropic、Gemini的story可能都类似——terminal year会有profit explosion,但在那之前每年都是deeper hole。
理解了这个逻辑,就能理解为什么当前Capex投入还不是泡沫,是AI竞争的必然走向。电力、GPU卡、存储等基础设施的战略卡位,是巨头们甚至国家层面为这场不容失败的马拉松式竞争做准备,不能简单只看短期收益。
那什么情况下会变成泡沫?关键看两个指标:
一是应用层的revenue转化速度。如果2026-2027年AI应用ARR增长不及预期(比如没有出现killer app,企业采纳率卡在10-20%),推理需求起不来,算力过剩会成为现实。
二是模型公司的盈利时间表。OpenAI预计2029年实现盈利,Anthropic可能更晚。如果这个时间表不断推迟,或者中间某家头部公司倒下,市场信心会崩塌。
2026年还在"投入期",泡沫风险可能在2027-2028年。从现在算起的窗口期就这2-3年。
2026重点关注三种关键基础设施资源的需求和供应变化:
- GPU vs TPU
未来2~3年内,Nvidia在AMD(GPU)、Google(TPU)、AWS(Trainium)以及OpenAI(Stargate)等一众对手群殴中保持不倒,尽管可能份额会被蚕食,但仍然会牢牢地占据市场垄断地位。
Nvidia的Blackwell架构(B系列)、Grace Blackwell(GB200 NVL72)正在重新定义算力密度,比如GB200 NVL72在训练LLM时的能效比上一代提升约5倍,未来的Rubin系列性能会进一步提升。
专用ASIC芯片同样在进化。Google TPU v6号称在Gemini 3训练中的能效比Blackwell高30%,AWS Trainium2专为Transformer优化,推理成本号称比B200低40%。OpenAI自研推理芯片Stargate预计2027年Q2量产,只覆盖推理场景。
Gemini 3大获成功后,据称明年Google TPU的芯片需求暴涨,预测可能会交付200 ~ 300万颗(TPU v8)。专用芯片的固定架构风险始终存在:如果Transformer被新架构替代,这些ASIC芯片的巨额投资可能打水漂。相比之下,NVIDIA的"通用性溢价"依然是最安全选择。
- 电力成为新瓶颈
2026年,单个AI数据中心的电力需求已达GW级。
美国电网正在重构。Virginia州Loudoun County作为全球最大数据中心聚集地,正面临电力容量压力;微软已与Constellation Energy签约重启Three Mile Island核电站1号机组,预计2028年投产,20年合同期内提供835MW电力专供其数据中心;Meta在2024-2026年间正在签订多个可再生能源购电协议(PPA),总容量预计超过2.4GW,覆盖Texas、Arizona等多个州;Anthropic计划在Louisiana、Oracle计划在Texas布局GW级数据中心。传统电网改造周期往往长达5-8年,远远跟不上AI算力部署的速度。
未来几年AI DC的选址逻辑首先要考虑"电力优先"。相比核电、风电、太阳能等新电力形式,眼下谁能有马上可供AI DC使用的电和数据中心,谁就可能会在2026年收到巨头们更多的橄榄枝。比如很多矿厂转型AI DC,也有很多Neo Cloud厂商通过各种租赁提供算力服务。
美国接下来两三年AI增长的首要瓶颈首先是电力。
- 存储与网络的连锁紧缺
大模型训练需要PB级存储和数百GB/s读写带宽。推理阶段的瓶颈更隐蔽——当数十亿用户同时调用模型,KV-cache存储和网络带宽会先于GPU崩溃。以Claude Opus 4.5为例,其200K context window在大规模并发下需要巨量内存支撑。
HBM3e供应紧张。SK海力士、三星、美光的产能已被预定到2027年Q2。这直接限制了GPU出货——NVIDIA不是造不出B200,是配不齐HBM3e。每张B200需要192GB HBM3e,HBM内存成本占GPU总成本的近一半。
高速网络设备同样面临供应压力。NVIDIA不只卖GPU,更在卖"整套方案"——Blackwell + ConnectX-8网卡 + Spectrum-X交换机 + CUDA软件栈。这是完整的生态壁垒,竞争对手短期内无法复制。
2. 模型层:现有技术路线OpenAI、Google和Anthropic交替领先,Neo Labs可能突破新技术范式
交替领先成为常态
GPT、Claude、Gemini三家25天内密集发布,Benchmark榜首周级更替。从技术路线的发展趋势看,这也不是偶然,是当前技术范式的必然。
Pre-training + RL范式下,三家know-how已无法拉开代际,再加上业界秘方开始走向信息透明,人才流动更加充分,每家背后都有金主或者现金牛业务。
技术竞争进入明牌博弈阶段。要真正拉开差距,需要下一代范式突破。
三家巨头开始战略分化
Anthropic: 专注2B,放弃2C。Coding和Agent能力非常强,个人尤其喜欢提出的MCP和Agent Skills机制。这个战略bet显然是聪明的,否则在与OpenAI和Google正面竞争中可能会很早出局。
OpenAI: 还在AGI的追梦路上狂奔,但由于开销太大也开始想着挣钱或者IPO了。2C断档领先,目前ChatGPT拥有约9亿月MAU,而Gemini App MAU大概6.5亿,MAU/DAU ChatGPT远远领先Gemini。Altman最近的一次访谈中也公开提出,明年OpenAI的重要方向是Enterprise,从Enterprise赚钱来持续推进AGI和ChatGPT的发展。
**Gemini:**更聚焦多模态方向,多模态能力很强。这次Gemini 3发布后,迅速在其Gemini APP、Search、Notebooklm、Google Map, Youtube等10亿级应用上应用,持续渗透G家所有C端产品。同时,基于Google Cloud, 通过Gemini Enterprise持续攻打Enterprise市场。
3条技术路线齐头并进
Pre-training:快到头了,可用的互联网高质量数据可能就5-6T,已经用得差不多。尽管最近Gemini 3的效果看Pre-training尚能饭否,但边际收益开始递减,同时也越来负担不起了。每一年都比上一年烧得更多。
Post-training:从RLHF(Reinforcement Learning from Human Feedback)到RLVR(Reinforcement Learning from Verifiable Rewards),再到Test-Time Computing,这条路线的核心是"让模型在推理时更聪明"。
- RLHF通过人类反馈对齐模型输出,是GPT-3到ChatGPT的关键突破
- RLVR用可验证的奖励信号替代人类标注,降低对齐成本,提升数学/代码等可验证任务的表现
- Test-Time Computing(o1系列)让模型在推理时"慢思考",通过更长的CoT(思维链)和search提升复杂任务表现
这条路线仍有提升空间,但属于渐进式。头部几家在这个路线上的know-how和人才密度相差不多,很难拉开代际差距。成本相对Pre-training是数量级的下降,是当前竞争的主战场。
Online Learning:LLM目前还没有形成数据飞轮,最主要的原因是无法实时有效地把用户反馈直接融入进模型。落地过程中经常被业务方问到的一个问题是,为什么这次的人工专家反馈模型下次还不会呢?
类似于人类的反思学习能力,目前LLM在这个方向还没真正突破。如果突破了,模型可以在推理时学习,从用户交互中持续改进而无需重新训练,真正具备了自学习的能力,这将会是范式级跃迁。
这个方向,OpenAI、Google、Anthropic这些巨头都有投入,但最先突破的说不定是大神IIya的SSI、前OpenAI CTO Mira的ThinkingMachines等Neo Labs,这些NeoLabs没有太多的历史包袱和路径依赖。
2026年个人最期待Online Learning方向的实质性突破。
3. 应用层:目前的模型能力已满足大多数场景需求,2026 AI应用可能会爆发
Capability Overhang:模型能力已就位,应用价值待释放
Sam Altman在最近的一次访谈中关于AI应用提到的一个观点是"Capability Overhang"。他的原话是:“即使冻结模型在5.2,光是挖掘现有能力就能产生巨大增长。”
 Source: OpenAI
Source: OpenAI
OpenAI有一个大模型在具有经济价值的现实任务表现的新评估体系 - GDPVal,涵盖了美国 GDP 前九大产业中精选的 44个 职业领域。完整数据集包含 1,320 项专业任务,每项任务均由来自相关领域的资深专家精心设计并审核。
业界更应该关注AI对于实际生产力的影响,而不应再过度关注各种理论Benchmark。
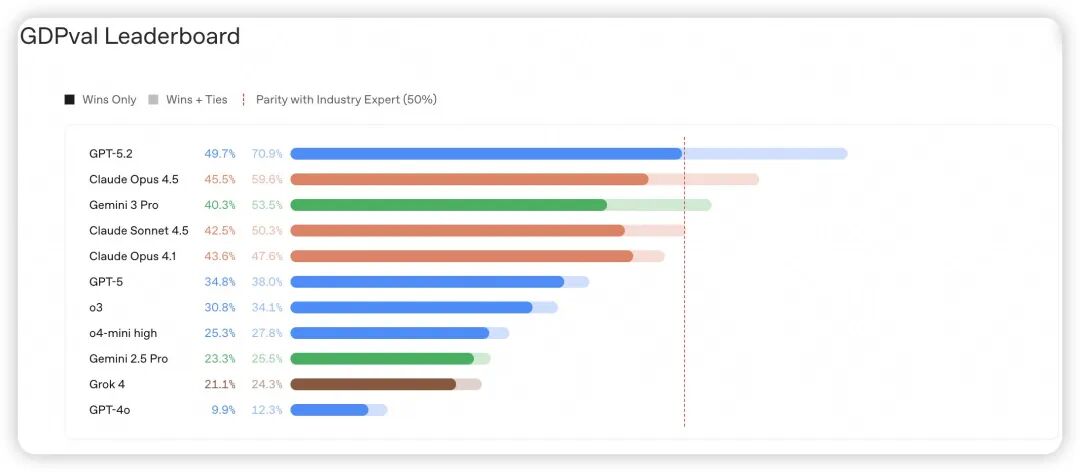 Source: OpenAI
Source: OpenAI
GPT-5.2在GDPVal的49.7%任务中超过专家表现,在70.9%任务中至少与专家持平,但大多数人用AI的场景是润色邮件、总结文档等GPT-5或更小模型就能胜任的基础任务。
这是当下核心矛盾——模型ready了,用户没ready。技术能力释放速度远滞后于技术本身进步速度。
这个overhang主要针对当前大多数应用场景。对于润色邮件、总结文档、客服问答等主流场景,当前的GPT-5.2、Gemini 3、Claude Opus 4.5已经远超需求。但巨头继续投入有两个原因:一是frontier场景——multi-step reasoning、long-horizon agent、复杂代码生成——能力天花板还在提升;二是AGI追求,OpenAI、DeepMind这些公司的终极目标不是"够用的AI",是"通用人工智能",这是完全不同的game。
对Builder来说,关键判断是:你在做应用,还是在追AGI?如果是前者,能力已经够了,焦点应该在工程和产品。如果是后者,那你需要的资源和时间窗口都不在一个量级。
当前市场验证:ARR数据证明能力已足够
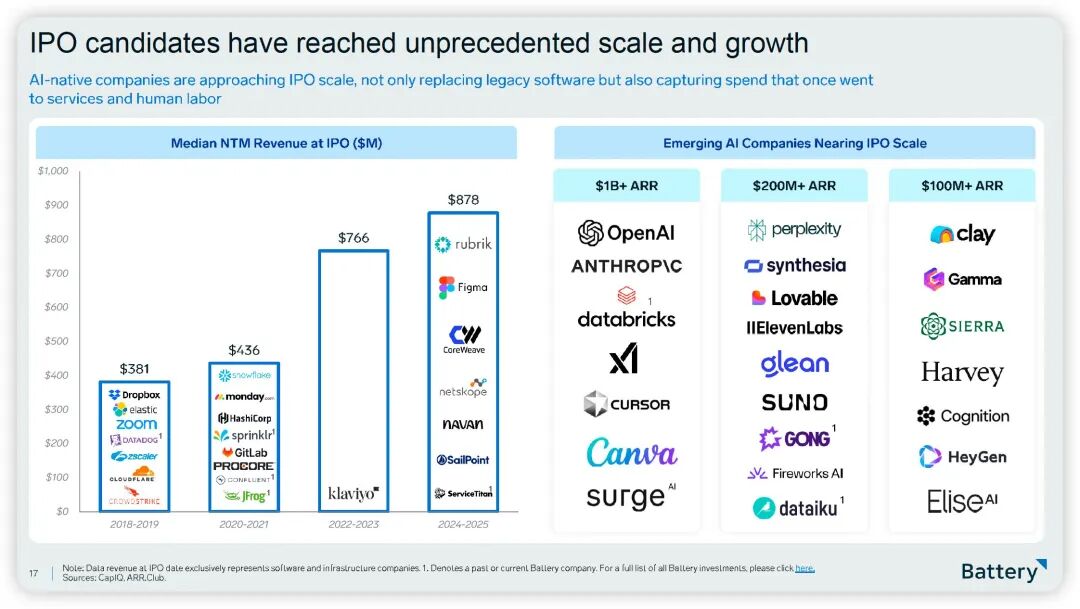 这些应用都基于当前已有的商品化模型,因此AI应用成功的关键不在是不是最新最强的模型能力,而在于工作流的嵌入深度。当前模型对绝大多数场景已充分满足需求,真正挑战在于能力向商业价值的转化。
这些应用都基于当前已有的商品化模型,因此AI应用成功的关键不在是不是最新最强的模型能力,而在于工作流的嵌入深度。当前模型对绝大多数场景已充分满足需求,真正挑战在于能力向商业价值的转化。
产品设计的范式分化:Bolt-on vs. AI-First
市面上90%的"AI产品"都是Bolt-on——在老产品上贴个chatbot,加个"AI驱动"标签。Salesforce加Einstein,Zendesk加AI Agent,adoption rate惨不忍睹。用户打开一次就再也不用了。
Sam Altman在访谈中提到,在传统软件上简单加AI功能效果有限。Bolt-on的死穴在于价值感知模糊——用户已经有work around,AI功能可有可无。更要命的是老架构根本发挥不出能力,调用一次模型走三层API,响应5秒+,体验比人工还差。
真正起飞的都是AI-First thinking。Cursor不是"VS Code+Copilot",是重新想象:如果AI能实时理解整个codebase,编程该是什么样?Harvey不是"research tool+GPT",是重新定义律师工作流。核心问题是:What becomes possible when AI is free and instant?
Cursor从0到$1B ARR用了18个月,Harvey签下top 100律所中40+家。而传统软件加AI按钮的,adoption还在个位数挣扎,续约率直线下跌。这不是10%改进,是10x范式转变。
2026年的分水岭不在技术,在产品理念。Bolt-on只能capture 10%的价值,AI-First才能解锁全部模型潜力.
当前AI应用的几条路径
路径一:垂直行业深度重构(Harvey、Glean模式)。核心在于对特定行业know-how的深度理解和全流程AI重构能力。护城河来自行业数据积累、流程专业知识沉淀、客户关系深度绑定三重壁垒相互强化。增长逻辑:“Land with AI, expand with workflow”——先用AI能力切入建立客户关系,再扩展至全流程优化重构。
路径二:新型生产力工具(Cursor模式)。核心不是优化现有流程,而是创造全新工作方式。护城河来自产品体验、网络效应、开发者生态。以Cursor为例,早期靠团队洞察和领域专业知识,成长期靠数据飞轮和产品快速迭代,而成熟期真正护城河来自工作流深度嵌入和集成深度。
路径三:AI基础能力应用化(ElevenLabs、Runway模式)。核心是将复杂AI能力封装成开箱即用产品,大幅降低使用门槛。护城河来自技术领先性、产品易用性、生态锁定效应,Growth路径是"API-first → Application → Platform"的演进逻辑。
2026年个人认为AI应用会大爆发。当前最领先的LLM Capability overhang快速释放,尤其是企业采纳率将快速爬升,突破30%?市场情绪将从"AI泡沫"质疑翻转为"AI价值重估"的共识。
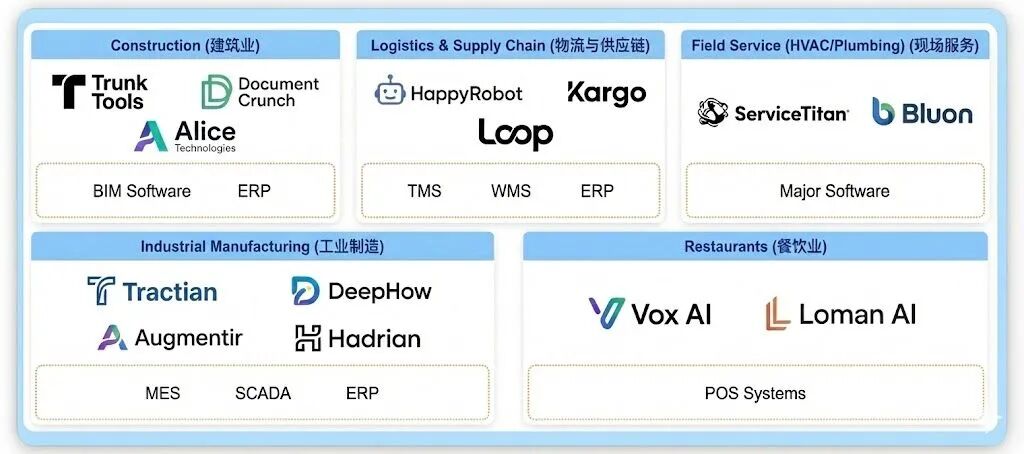 为啥有这个判断呢?很多AI应用在不太关注的领域已经发生了。
为啥有这个判断呢?很多AI应用在不太关注的领域已经发生了。
上图是一些所谓的“Blue-Collar AI"方向的一些Startups,有建筑业、物流与供应链、现场服务、工业制造、餐饮业等等。当最保守的群体成为最激进的采纳者,说明AI在部分解决真实而紧迫的生产力瓶颈。
根据个人过往多年AI应用落地的经验,更多是教训,AI应用落地有三个常见误区:
第一,不是AI有多强,而是对用户需求和工作流理解有多深——技术能力会趋同,场景洞察和用户痛点把握难以复制。
第二,不是功能有多酷,是能否真正改变习惯并形成依赖——炫酷demo吸引眼球,但只有深入日常工作流、成为不可或缺部分才能建立真正护城河。
第三,不是市场有多大,是能否在细分领域建立垄断地位——AI时代赢家很可能不是追求最大TAM的公司,而是在特定垂直领域建立绝对统治力的专精者。
还有一个需要提的点是,早期要敢于啃最难的高价值场景,长期看回报巨大且门槛高。
三、Builder的一些想法
2025年最大的收获:不是模型多强,是终于想明白护城河在哪。
“模型变了护城河还在吗?”,这问题得换个思路。Cursor、Harvey、Glean用的都是Claude和GPT,模型每3周换榜首,ARR还在狂飙。护城河不在模型,在把60分模型做成生产级产品的速度,在产品嵌入用户工作流的深度。
模型能力已经够了。 GPT-5.2在GDPVal的近50%任务中超过专家,Claude Opus 4.5自主完成5小时任务。你做的90%场景,当前主流模型就够用。95%项目死在试点到生产的gap——不是模型问题,是last mile的工程、数据、组织三重挑战。Agent现在90%是工程问题。2026年比的是谁先交付,不是谁用最新模型.
AI优先产品是门槛。 Cursor从0到10亿美金ARR用了18个月,传统IDE加AI功能的adoption还在个位数。Sam说"在传统软件上加AI就像给自行车装喷气发动机",说的就是这个。AI优先的核心问题是:如果AI免费且即时,什么会变得可能?这不是10%改进,是10倍范式转变.
技术窗口期很短。 Benchmark领先从12个月缩到3周,模型成本每年降50%,能力快速趋同。技术护城河的半衰期在急剧缩短。但另一面,成本和采纳曲线都在加速,2026年即将跨越早期采纳者到早期大众的鸿沟。最保守群体(医生、律师、蓝领)开始成为最激进采纳者,说明真实痛点在被解决。
几千亿美元投下去了,基础设施还在军备竞赛,模型层进入均势,应用层窗口刚打开。2026年验证的是商业可持续性。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献175条内容
已为社区贡献175条内容

所有评论(0)