AI学习笔记整理(38)——自然语言处理的基于深度学习的语言模型
词嵌入作为语言模型的输入表示层,将文本中的单词或子词(如通过BPE分词)映射为高维向量(例如512维或1024维),这些向量在空间中通过相对位置编码语义相似性(如“猫”和“狗”的向量接近),从而为模型提供语义基础。词嵌入与语言模型的集成体现在技术演进中,早期NLP系统将词嵌入作为独立预处理步骤,而现代大语言模型(LLM)将嵌入层深度集成到端到端架构中,嵌入向量随模型训练联合优化,成为理解与
自然语言处理的预研模型
早期统计语言模型基于概率统计,主要包括N-gram模型,如Unigram(N=1)、Bigram(N=2)和Trigram(N=3),通过计算词序列的条件概率来预测下一个词,但受限于词序长度和数据稀疏问题。
基于深度学习的语言模型利用神经网络捕捉长距离依赖,主要包括:
- 循环神经网络(RNN) 及其变体如LSTM和GRU,通过循环结构处理序列数据,但存在梯度消失和训练慢的问题。
- Transformer架构 引入自注意力机制,并行处理序列,显著提升效率和性能,成为现代模型的基础。
大规模预训练语言模型通过海量数据预训练并在下游任务微调,实现卓越性能,主要包括:
- 自回归模型:如GPT系列(GPT-2、GPT-3),从左到右生成文本,擅长文本生成和对话系统。
- 双向编码模型:如BERT及其变体RoBERTa、ALBERT、DeBERTa,通过掩码语言建模理解上下文,适用于文本分类、问答等任务。
- 统一文本到文本模型:如T5,将所有NLP任务转化为文本生成问题,增强通用性。
- 其他重要模型:XLNet结合自回归和双向优势;ELECTRA通过对抗训练提高效率;StructBERT强化语言结构学习。
语言模型与词嵌入的关系
Word Embedding,或者说“词嵌入”,可以想象成是一种特殊的翻译技术。它的工作原理是将我们日常使用的词语“翻译”成计算机能够理解的数字形式。不过,这种翻译并不是简单地把一个词对应到一个数字,而是将每个词转换成一个数字列表(或者说,一个向量)。这样做的目的是让计算机不仅能认识这些词,还能理解这些词之间的关系和差异,比如“国王”和“王后”的关系,或者“苹果”这个词在讨论电脑品牌时和讨论水果时的不同含义。
词嵌入作为语言模型的输入表示层,将文本中的单词或子词(如通过BPE分词)映射为高维向量(例如512维或1024维),这些向量在空间中通过相对位置编码语义相似性(如“猫”和“狗”的向量接近),从而为模型提供语义基础。早期方法如Word2Vec或GloVe生成静态嵌入,而现代Transformer架构(如GPT或BERT)采用动态嵌入,根据上下文调整向量表示(例如“苹果”在“水果”和“手机”中的不同含义)。
在训练过程中,词嵌入是语言模型学习语言结构的基础,模型通过大规模语料库的自监督任务(如预测下一个词)优化嵌入向量,使其不仅保留词汇统计模式,还编码句法和语义规律。
例如,Transformer的注意力机制依赖嵌入向量计算词元间的关联权重,从而处理指代、因果等复杂关系。
词嵌入与语言模型的集成体现在技术演进中,早期NLP系统将词嵌入作为独立预处理步骤,而现代大语言模型(LLM)将嵌入层深度集成到端到端架构中,嵌入向量随模型训练联合优化,成为理解与生成文本的关键。这种集成使LLM能够模拟维特根斯坦的“语言图像论”,即通过嵌入向量的结构映射语言与世界的关系。
尽管词嵌入是语言模型的基础,但两者存在本质区别:词嵌入专注于词汇的分布式表示,而语言模型旨在学习完整的语言概率分布以实现生成或分类;此外,语言模型规模更大,能处理上下文依赖和长程依赖,而传统词嵌入模型更轻量,侧重局部词汇关系。
RNN、LTSM、GRN模型的作用和构建
1)RNN模型的作用和构建
RNN(Recurrent Neural Network), 中文称作循环神经网络, 它一般以序列数据为输入, 通过网络内部的结构设计有效捕捉序列之间的关系特征, 一般也是以序列形式进行输出。其核心作用是通过内部隐藏状态在时间维度上传递信息,从而捕捉序列中的时序依赖关系。这种“记忆”能力使RNN能够建模动态序列数据,适用于需要理解上下文关联的任务。
RNN的核心作用体现在其序列建模能力上, 具体应用包括:在自然语言处理(NLP)中用于文本生成、情感分析和机器翻译,通过捕捉单词间的依赖关系提升语义理解;在语音识别中处理声学特征序列以识别语音内容;以及在时间序列预测中(如金融或天气预测)利用历史数据趋势进行未来值估计。
参考链接:https://www.cnblogs.com/flyup/p/18903402
RNN的关键特点是隐藏状态的循环传递,即当前时刻的输出不仅依赖于当前输入,还依赖于之前所有时刻的信息,这种机制使RNN能够建模序列的时序依赖性。一个隐含层神经元的结构示意图如下: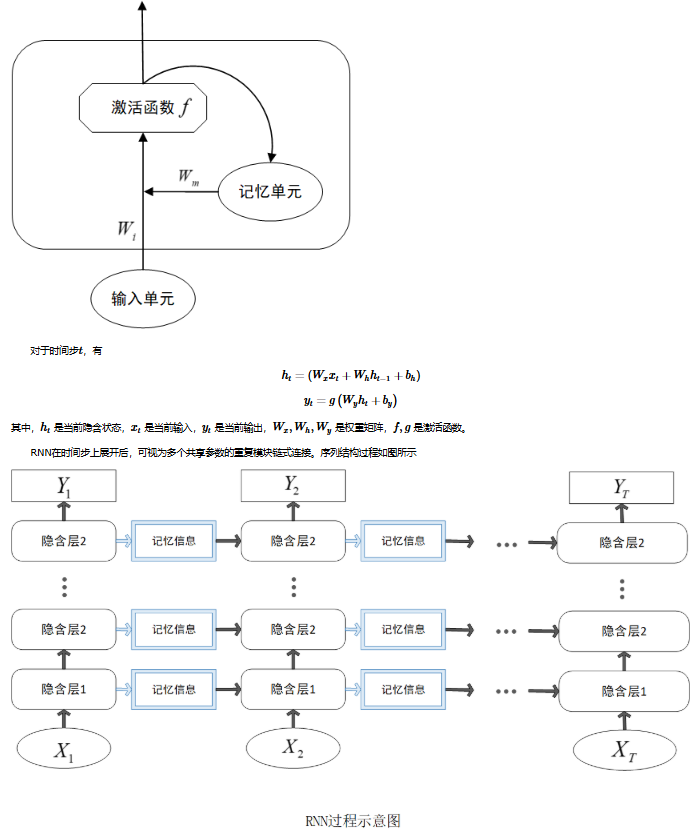
-
主要优势
参数共享:所有时间步共享同一组权重,大幅减少参数量。
记忆能力:隐藏状态能够“记忆”,存储历史信息。
灵活输入输出:支持多种序列任务(如一对一、一对多、多对多)。 -
局限性
梯度问题:传统RNN难以训练长序列(梯度消失/爆炸)。
计算效率:无法并行处理序列(因时间步需顺序计算)。
2)LSTM模型的作用和构建
参考链接:https://blog.csdn.net/hongshanqu/article/details/154881942
https://zhuanlan.zhihu.com/p/681877938
长短期记忆网络(LSTM)是循环神经网络(RNN)的一种特殊类型,LSTM 能更好地处理长距离依赖(如文本中的上下文关联、时间序列中的滞后效应),是处理语音识别、机器翻译等长序列任务的常用模型。
长距离依赖和上下文关联的例子:下围棋,棋手要记住前面下过的棋,而且前面下过的棋会影响当下的棋。如写小说(文本生成),写手要记住前面写过的情节,它们是当前情节的铺垫。音乐创作的前后乐段也需要前后呼应。
从循环神经网络RNN的结构看,前面网络的状态是一直后面传递的,前面的信息可以向后传递影响后面的运行。但是,有一个梯度消失现象,以前的状态信息不会传递太远,很快衰减消失。基于这个逻辑。LSTM网络架构就横空出世了。
LSTM 是一种特殊类型的 RNN,其设计目的是比标准 RNN 更好地处理这种长距离依赖性 。当信息通过每个 LSTM 单元时,可以通过门控单元添加或删除信息来更新单元状态 C(t)。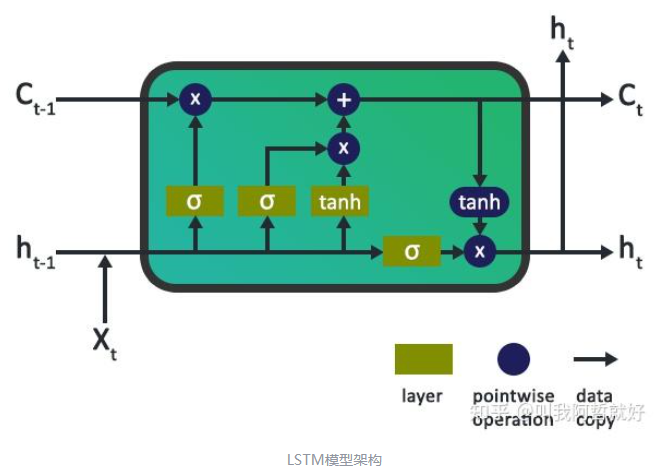
可以看出来,LSTM最大亮点就是为模型引入了所谓的门控单元。
LSTM 经典架构具有三种门控单元(后续诸多变体会引入其他的门控方式,但多是换汤不换药),三个门控单元主要负责控制进出存储单元或 LSTM 单元的信息流。
第一个门称为遗忘门,第二个门称为输入门,最后一个门称为输出门。
就像简单的 RNN 一样,LSTM 也有一个隐藏状态,其中 H(t-1) 表示前一个时间戳(上一时刻)的隐藏状态,Ht 是当前时刻的隐藏状态。除此之外,LSTM 还分别用 C(t-1) 和 C(t) 分别表示先前和当前时刻的单元状态。
在 LSTM 神经网络的单元中,第一步是决定是否应该保留上一个时间步的信息或忘记它。
输入门主要用于量化输入所携带的新信息的重要性。
输出门负责决定应该从当前时间步的细胞状态中输出多少信息到当前时间步的隐藏状态。输出门的计算过程涉及当前时间步的输入,前一时间步的隐藏状态以及当前时间步的细胞状态。
-
主要优势
- 长期依赖建模能力:LSTM通过遗忘门、输入门和输出门的协同作用,能够动态调节信息流,从而捕捉长距离的时序依赖关系,在文本生成、机器翻译等任务中保持语义连贯性。
- 梯度稳定性:门控机制缓解了梯度消失或爆炸问题,使模型在反向传播过程中能更稳定地更新参数,尤其适合处理长序列数据。
- 泛化能力:LSTM在多种序列数据上表现良好,如自然语言、语音和时间序列,具有较强的适应性。
-
局限性:
- 计算复杂度高:门控机制引入了大量参数,导致训练和推理速度较慢,对硬件资源要求较高。
- 并行化困难:LSTM需按时间步顺序处理序列,无法像Transformer那样实现高效并行计算,限制了其在超长序列上的扩展性。
- 过拟合风险与超参数敏感性:模型结构复杂,容易在小数据集上过拟合,且对隐藏层维度、学习率等超参数敏感,需依赖正则化技术(如Dropout)或数据增强来缓解。
- 可解释性差:门控机制的内部决策过程难以直观理解,增加了模型调试和应用的难度。
3)GRU模型的作用和构建
参考链接:https://blog.csdn.net/guoke_tg/article/details/150215396
GRU(Gated Recurrent Unit,门控循环单元)是循环神经网络(RNN)的重要变体,专为解决传统 RNN 的 “长序列依赖” 问题而设计。它在 LSTM 的基础上简化了结构,同时保留了处理时序数据的能力,在自然语言处理、时间序列预测等领域应用广泛。以下从结构细节、模型对比、应用场景、改进变体等方面补充 GRU 的深度知识。
GRU 的核心是门控机制,通过两个门控单元(更新门、重置门)控制信息的流动,最终输出一个 “隐藏状态”(hidden state)来保留时序信息。
- 更新门(Update Gate):决定保留多少旧信息和引入多少新信息,类似于LSTM中的遗忘门和输入门的组合。
- 重置门(Reset Gate):控制如何忽略或使用历史信息,帮助模型在处理新输入时“忘记”不相关的历史内容。
这种机制使GRU能够高效捕获序列数据中的短期和长期依赖关系,同时结构比LSTM更简单,参数更少,训练速度更快。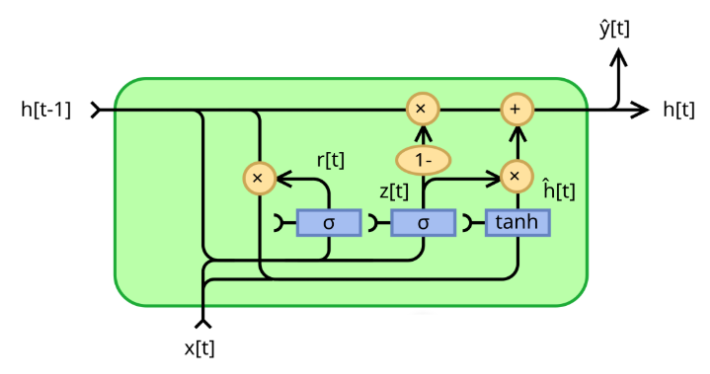
GRU 核心计算过程:
- 计算更新门(Z):决定保留多少过去的隐藏状态,取值范围 (0,1)。
- 接近 1 表示更多保留过去的隐藏状态
- 接近 0 表示更多采用新的候选隐藏状态
- 计算重置门(R):决定如何结合新输入和过去的隐藏状态,取值范围 (0,1)。控制过去的隐藏状态对候选隐藏状态的影响
- 候选隐藏状态(H_tilta):结合当前输入和经过重置门过滤的过去隐藏状态
- 更新隐藏状态(H):通过更新门平衡过去的隐藏状态和新的候选隐藏状态
- 输出(Y):根据当前隐藏状态计算输出
-
主要优势:
- 结构简化,GRU将LSTM的遗忘门和输入门合并为更新门,并省略了细胞状态,从而减少了参数数量,降低了模型复杂度
- 训练效率高,由于结构更简单,GRU在相同硬件条件下训练速度通常快于LSTM,适合需要快速迭代的场景;
- 在处理长期依赖关系时,GRU通过门控机制能有效抑制梯度消失问题,表现优于传统RNN,尤其在单步预测或资源受限任务中可能接近或超过LSTM性能。
-
局限性:
- 多步预测能力较弱,GRU在需要同时预测多个未来时间点的任务中可能不如LSTM稳定,其简化设计在捕捉长期依赖时效果有限;
- 对超参数敏感,GRU的性能可能高度依赖学习率、层数等设置,调参难度较大;
- 泛化能力挑战,在面对复杂序列模式或噪声数据时,GRU的泛化能力可能不足,例如在语音识别中对不同口音或方言的适应性较差;
- 计算瓶颈,尽管比LSTM高效,但GRU仍存在RNN固有的不可并行计算问题,在处理超长序列时计算开销较大。
RNN、LTSM、GRN在自然语言处理任务上优劣势比较
RNN、LSTM和GRU是处理序列数据的循环神经网络变体,在自然语言处理(NLP)中各有特点。以下从多个维度进行客观比较。
-
在处理梯度消失和爆炸问题方面, RNN、LSTM和GRU的表现差异显著:RNN由于反向传播时梯度通过链式法则反复相乘,容易出现梯度消失或爆炸,导致难以捕捉长距离依赖关系;LSTM通过门控机制(遗忘门、输入门、输出门)和细胞状态设计,能选择性保留或丢弃信息,有效缓解梯度问题;GRU作为LSTM的简化版本,使用重置门和更新门控制信息流,结构更轻量,同样能抑制梯度异常,但理论上比LSTM稍弱。
-
在训练效率和计算复杂度上, RNN、LSTM和GRU各有优劣:RNN结构简单但训练慢且难以并行;LSTM参数量大(约为RNN的4倍),计算开销高,训练时间长;GRU参数更少(约为RNN的3倍),收敛速度快,更适合资源受限场景。三者均因序列依赖性无法完全并行化,长序列任务效率较低。
-
在捕捉长序列依赖能力方面, LSTM和GRU均优于传统RNN:LSTM通过独立门控和细胞状态,能长期维持信息,适合长文本建模;GRU通过更新门整合记忆机制,效果接近LSTM但参数更少。实际表现取决于任务和数据,二者差距通常较小。
-
在模型复杂度和过拟合风险上, RNN、LSTM和GRU的差异明显:RNN结构简单,但易过拟合;LSTM因参数多、结构复杂,过拟合风险较高,需正则化;GRU参数少、结构简单,泛化能力较强,过拟合风险较低。
-
在NLP任务中的适用场景方面, RNN、LSTM和GRU的选择需结合具体需求:RNN因梯度问题较少直接使用,多作为基线;LSTM适合长依赖任务如机器翻译、情感分析,但计算成本高;GRU因效率高,适合快速迭代或实时应用如文本生成、语音识别。需注意,Transformer等模型因并行优势,在NLP中已部分替代RNN类模型,尤其在大规模数据下表现更优。
RNN、LTSM、GRN在项目实战中差别
RNN、LSTM和GRU在项目实战中的核心差异体现在模型结构、训练效率、适用场景和实现复杂度等方面。以下结合关键维度进行对比分析。
-
模型结构与记忆机制: RNN、LSTM和GRU的核心区别在于信息处理方式。RNN通过简单循环连接传递隐藏状态,但缺乏显式的记忆控制,导致长期依赖难以捕捉;LSTM引入门控机制(遗忘门、输入门、输出门)和细胞状态,能选择性保留或丢弃信息,有效缓解梯度消失问题;GRU作为LSTM的简化版本,将遗忘门和输入门合并为更新门,并直接使用隐藏状态作为记忆载体,减少了参数量。
-
训练效率与资源消耗: 在训练效率方面,RNN参数量最少但易受梯度问题影响,需额外技巧(如梯度截断)稳定训练;LSTM因门控机制和双重状态设计,参数量较大,训练时间较长且更易过拟合;GRU通过结构简化降低了参数量和计算开销,训练速度通常快于LSTM,且对小规模数据更具鲁棒性。
-
适用场景与性能表现: 实际项目中,三者的适用性如下:
- RNN:适用于短序列任务(如几十步内的文本生成或简单时序预测),但长序列效果差;
- LSTM:在长序列依赖任务(如股价预测、机器翻译)中表现稳定,能捕捉长期上下文,但资源消耗高;
- GRU:平衡效率与性能,适合中等长度序列(如语音识别、情感分析),尤其在数据量有限时避免过拟合。
-
实现复杂度与调参难度: RNN实现最简单但调参困难(需精细控制梯度);LSTM结构复杂,门控参数需更多调优;GRU因结构简洁,实现更易上手且对初始超参数敏感度较低。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)