从SIP到Kamailio
目录
一.概述
使用SIP协议,它提供了一个搜索机制,如果一个用户希望建立和其他用户的会话,SIP必须能够查找到对方用户正在使用的当前主机(hosts)。这个搜索机制可以被proxy服务器、重定向服务器使用,他们在接收、以及响应一个请求的时候,会基于这个用户得位置信息来判定这个消息应该发送到哪里。
SIP提供了一个位置服务,就是通过对特定地区提供地址绑定来实现,具体实现方式是:这些地址绑定转换输入的SIP或SIP URI,比如sip:bob@biloxi.com,转换成一个更接近目标用户的URI,比如sip:bob@engineering.biloxi.com。也就是说,一个proxy会把输入的URI转换到位置服务中用户实际位置,来得到最终用户的位置。
注册服务为特定地区的位置服务创建绑定关系,详情见第二部分“注册”内容。可以供后续proxy服务器转发请求或者响应使用。
二.注册
注册服务为特定地区的位置服务创建绑定关系,用来建立包含一个或者多个联系地址的address-of-record(AOR) URI。当一个proxy接收到一个请求,这个请求的Request-URI和address-of-record的记录匹配,此时proxy就可以转发请求到AOR中登记的联系地址中去。
1.举例
例如,Carol,有一个address-of-record”sip:carol@chicago.com”,将会在区域chicago.com的注册服务器上注册。她的注册服务信息将会被chicago.com区域的proxy服务器使用,用来路由和转发到Carol的address-of-record请求到她的SIP终端。
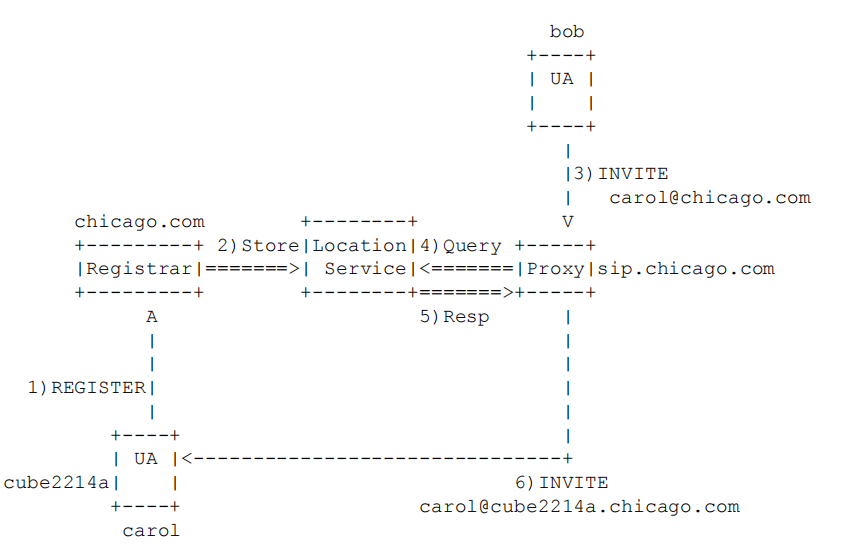
在上面这幅图中:
bob是主叫,他发起一个呼叫,目标是carol@chicago.com。
carol是被叫,那他就在通话前需要向网络注册自己的当前位置。
chicago.com是SIP服务域,它里面有注册服务器(负责接收和处理用户(如carol)的register请求,更新用户的位置信息)和位置服务(存储由注册服务器更新的“用户-当前位置”的绑定信息)。
Proxy是SIP代理服务器,处理SIP请求(比如bob的invite),并且通过查询位置服务来找到被叫用户的真实地址,然后进行转发。
Cube2214a:代表carol用户当前所在的网络地址或物理设备(一个特定的IP电话、软客户端)
整个过程可以分为两个阶段,首先是Carol的注册
①REGISTER
carol向它的归属域chicago.com的注册服务器发送一个REGISTER请求。请求中包含它的公共地址(carol@chicago.com)以及当前的实际联系地址(如 carol@cube2214a.chicago.com的IP和端口)
②Store|Location
注册服务器收到请求后,验证Carol的身份,然后将 carol@chicago.com绑定到其当前位置 cube2214a的信息,存储到位置服务数据库中。这个过程就是“注册”,使得网络知道Carol在哪里。
③响应返回
注册服务器会向carol返回一个200 OK响应,告知注册成功。
第二个阶段是Bob呼叫Carol
④Query
此时,Bob想要呼叫Carol,它不知道carol的具体位置,只知道它的SIP地址carol@chicago.com。Bob会向chicago.com域的代理服务器发送一个INVITE请求。
⑤Resp
代理服务器收到INVITE之后,需要找到carol,向位置服务发起查询,询问carol@chicago.com当前的实际地址是什么。位置服务告诉其结果,carol在cube2214a。
⑥INVITE
获得实际地址后,代理服务器转发INVITE请求给carol当前所在的设备cube2214a。此时,invite请求中的目标地址就变成了具体的carol@cube2214a.chicago.com。
2.构造一个register请求
REGISTER sip:chicago.com SIP/2.0
Via: SIP/2.0/UDP cube2214a.chicago.com:5060;branch=z9hG4bK776asdhds
Max-Forwards: 70
To: Carol sip:carol@chicago.com
From: Carol sip:carol@chicago.com;tag=54321
Call-ID: 817263817263@cube2214a.chicago.com
CSeq: 1 REGISTER
Contact: sip:carol@cube2214a.chicago.com:5060;expires=3600
Expires: 3600
Content-Length: 0
现在介绍一下这个请求和上面图里面的对应关系:
Request-URI:这个头域指明了登记服务所指明的位置服务所在的区域(比如sip:chicago.com)
Via:Carol设备的网络地址和端口,对应节点cube2214a
To:这个头域包含了被查询、增加、修改的address-of-record。to头域和Request-URI头域通常是不同的,因为这个由用户名组成。这个address-of-record必须是一个SIP URI或者SIPS URI.
From:这个头域包含了提交这个注册信息的用户的address-of-record资料。这个值和To头域的值相同,除非这个请求是第三方发起的注册请求。
Call-ID:UAC发出的给某个注册服务器(registrar)的所有注册请求都应该有相同的Call-ID头域值。如果相同的客户端用了不同的Call-ID值,注册服务器(registrar)就不能检测是否一个REGISTER请求由于延时的关系导致了故障。
Cseq:Cseq值保证了REGISTER请求的正确顺序。一个UA为每一个具备相同的Call-ID的REGISTER请求顺序递增这个Cseq字段。
Contact:REGISTER请求可以有一个Contact头域。这个头域可以有0个或者多个包含绑定地址信息的值。
3.处理register请求
注册服务器(registrar)检查Request-URI来决定是否它属于本注册服务器所管理的区域的Request-URI。如果不是,并且如果这个服务器同时也作为一个proxy服务器,那么这个服务器应当转发这个请求到指定的区域。
注册服务器(registrar)从REGISTER请求的To头域中解出address-of-record。
三.请求和响应的转发
1.proxy行为
SIP代理服务器是路由SIP请求到UAS的,并且路由SIP应答到UAC。一个请求可能通过多个proxy到达UAS。每一个都会作出路由决定,在发送给下一个节点前对请求做一点修改。应答会通过和请求相同的proxy路径,只是顺序是逆序的。
当接收到一个请求,做代理服务器之前,首先应该由一个部件决定是否自身需要响应这个请求(Request-URI)。
proxy对于每一个新的请求来说,既可以作为有状态的也可以作为无状态的模式来处理,接下来分两个部分进行说明。
2.有状态的处理模式
一个无状态的proxy在处理完一个消息之后就会丢弃这个消息的相关资料,有状态的proxy会保留这些信息(尤其是事务信息),保留每一个接收的请求和应答的相关信息,用于处理与这个请求相关的后续消息。
一个有状态的proxy可以选择”分支”一个请求,路由它到多个地点。任何被路由到多个地点的请求都必须当作有状态的处理。
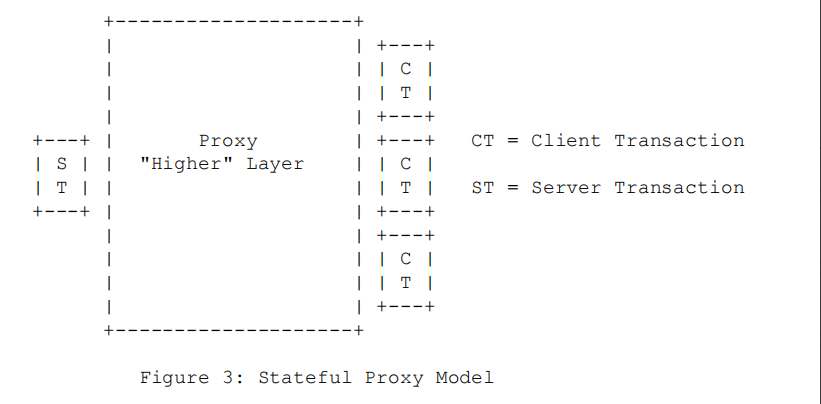
有状态的proxy为每一个接收到的新的请求创建一个服务端事务,后续请求的内容都是由这个服务端事务来处理。上图中,CT负责发送请求并处理来自下游的响应。 一个CT处理一个方向的请求(如INVITE)。ST负责接收请求并向上游(请求方)回送响应。一个ST处理一个方向的请求接收。(在状态代理中,每个进入的请求都会创建一对事务:一个 ST来处理接收到的请求 ,一个 CT来转发这个请求)
(1)请求转发
首先proxy会用Requset-URI中的信息计算出请求目的地,目的地集合中的每一个目的地都由URI来表达。
当目的地集合不是空的时候,proxy开始转发这个请求,由于有状态的proxy必须对目的地的集合的一个接收到应答和转发出去的原始请求进行匹配机制,他是通过proxy层在转发第一个请求创建的“response context”(应答上下文)来保障的。
①proxy把接收到的请求做一个拷贝,在拷贝好的请求中的Request-URI必须用目的地URI进行替换(这是proxy的本质步骤,通过这个机制能够把请求转发到目的地),把Max-Forwards域值减一。
②接下来如果希望这个请求会创建一个对话,也就是后续还会由请求经过proxy,那么这个proxy就要增加一个Record-Route头域,并且增加的头域值是在现存的头域之前。
③现在需要确定请求发送的目标地址、端口和传输协议。将选定的URI(Route或Request-URI)作为输入,按照RFC 3261附件[4]的步骤进行处理(确定目标URI:从Route头域(如果存在)或Request-URI中获取目标URI。 解析URI组件:提取URI中的host、port、transport参数和user部分),最终得到一个地址序列集合,每个元素包含(地址、端口、传输协议)三元组。代理必须依次尝试序列集合中的每一组元素,直到发送成功为止。如果某组发送失败或超时,继续尝试下一组。如果所有组都失败,代理按收到408(Request Timeout)响应处理。(每组尝试必须使用新的客户端事务,确保分支参数唯一性)
④接着在请求中增加一个via头域值,并且在其他via头域值之前增加。一个有状态的proxy会为这个请求创建一个新的客户端事务,指示事务层用上一步得到的地址、端口、协议进行发送。
(2)应答处理
当proxy收到一个应答的时候,它首先会尝试定位一个域这个应该匹配的客户端事务,如果没有匹配,那他就会作为无状态的proxy来处理这个应答。如果与应答匹配的客户端事务找到了,那么这个应答就会转给这个客户端事务进行处理。(他是通过via头域中的branch参数来匹配对应的客户端事务)
①收到响应的时候首先会寻找转发原始请求前创建的“应答上下文”,proxy从应答中移去via头域中最上面的值。如果在这个应答中没有这个Via头域值,那么应答的含义就是说这个应答不应当被这个proxy转发。
②接着合并认证头域,比如需要身份验证。那么proxy就必须从本应答上下文中的所有其他401(Unauthorized)和407应答中搜集WWWAuthenticate和Proxy-Authenticate 头域值。并且把这些信息增加到这个应答中。
③然后proxy把应答传递到跟这个应答上下文相关的服务端事务,proxy必须维持应答上下文知道所有相关事务都已终结。如果转发的应答是一个终结应答,proxy必须给依赖于这个应答上下文的所有客户端事务,产生CANCEL请求。
3.无状态的处理模式
如果是无状态的处理模式,proxy就是简单的转发。无论是请求还是应答,都是直接从通讯层处理,他也不会重发这些消息,他只是转发消息(它本身没有能力去分辨哪些消息是重发的,哪些是原始消息)。
(1)请求转发
①基于消息头域,从目的地集合中选择目的地,请求直接交给通讯层发送,不会创建客户端事务。
在请求发送时,客户端通讯层必须在Via头域中增加一个”sent-by”栏。这个字段包含了一个IP地址或者主机名,端口。如果端口不存在,缺省的值依赖于通讯协议。对于UDP,TCP和SCTP来说是5060,TLS是5061。
(sent-by:它包含的IP地址和包的源地址不同,服务器必须增加一个”received”参数到这个Via头域值中。这个参数必须包含收到的包的原地址。由于服务端必须把应答发送给收到请求的那个源IP地址,所以这个可以用来帮助服务端通讯层发送应答。)
②对于可靠传输协议,应答通常简单的通过连接发送,并且这个连接是收到对应请求的连接。因此,客户端传输层必须准备在发出请求的同一个连接上接收应答。在出现错误的情况下,服务端可能会尝试新建立一个连接来发送应答。为了能够处理这种情况,通讯层必须准备接收一个从源IP建立的新连接,这个连接的IP是请求发起的源IP,port是在”sent-by”字段中指定的port。
③对于非可靠的传输协议,客户端通讯层必须准备从发送请求的那个原始IP地址上接收应答。(因为应答会送到原始地址去),并且端口号是在”sent-by”字段的端口好。进一步说,和可靠传输一样,早某些情况下,应答会发往不同的地方。
(2)应答转发
先检查最上Via头域的sent-by参数,如果地址与代理自身匹配,从响应中移除该值,转发响应到下一个via头域值,如果地址不匹配,直接丢弃消息。
四.从SIP到kamailio
kamailio是SIP协议的具体实现,接下来通过源码内容说明它的从注册到请求和响应转发的过程。
1.注册
现在假设A,B之间要进行通话,B首先要在网络中注册自己的当前位置,A呼叫的时候proxy服务器才能通过域名查到它的地址信息。注册的时候会在服务域下绑定自己的地址。urecord结构体是用来存储注册联系人信息的,这个结构体里面有domain域名,还有ucontact_t结构体,ucontact_t就是已注册联系人的主要数据结构,它里面包含str received(IP+port+协议,也就是B注册时的信息)。
在注册模块下,save.c有save函数,这个函数用来保存register请求的联系人。通过提取msg信息,cscf_get_public_identity函数从to头域提取URI部分,pu=to->uri;return pu;
比如,To:sip:B@b.com;tag=abc123 提取的URI是sip:B@b.com,里面有用户名和域名,查询的时候就可以先用域名定位到具体的结构体,然后查找具体的信息。
2.有状态的请求转发和响应转发

(1)上图描述了整个请求和响应的转发过程,uas,uac都是在cell T这个结构体里的,是有状态的时候事务模块统一创建的。retr_buf这个结构体里面有dest_info dst结构体,他就是用来存储目标地址信息的,它里面有union sockaddr_union to,(dst.to)也就是把消息发送到哪里的目标地址。
(2)调用t_relay_to就是有状态请求转发入口,收到请求消息之后,首先会调用t_newtran,创建一个事务cell T,在这个函数里面会通过init_rb函数设置t->uas.response.dst,也就是ST后续转发响应发送的目标地址,他用update_sock_from_via提取via中的port和host,把提取到的内容用sip_resolvehost把提取到的内容进行DNS解析成地址和port,接着用hostent2su把地址和port转成dst.to。这样ST收到响应之后转发的目标地址就确定了,并且也创建了ST。
(3)接着会通过lookup()查询目标的具体信息,在usrlocation中找到联系人(也就是找到B,B已经在它的域名下注册过了自己具体的联系地址)。lookup函数会根据Request-URI查找用户的注册位置,用域名去找对应的联系人,把找到的信息(host+port+协议)存储在$du里面,后续可以通过读取$du来设置CT具体的转发联系地址。
(4)接着走到t_forward_nonack->add_uac->prepare_new_uac->uri2dst,经过一系列跳转,创建了uac,代理在上面已经通过lookup查找到了目标地址,通过uri2dst提取host,port,DNS解析成地址,sip_hostport2su转成dst.to确定了发送地址。在add_uac的时候有参数t,所以CT和ST之间是通过事务cell传递的。这样uac也就知道请求发送的目标地址信息,请求可以成功转发给B。
(5)B收到invite请求之后,回复200 OK响应。Reply_received是SIP响应处理入口,首先会调用t_check根据branch找到对应事务和分支,uac=&t->uac[branch_id],这样就找到了发送请求的uac,接着调用relay_reply进行转发,这样也就走到了ST,relay_reply第一个参数是cell *t,CT和ST之间用事务匹配,在这个函数里面uas->rb=&t->uas.response,也就是在创建ST就设置好的,这样可以直接匹配A的地址,进行响应发送。
至此,整个有状态的请求和响应转发过程就完成了
3.无状态的请求和响应转发

(1)上图描述了无状态的请求和响应转发过程,和有状态的区别是他不会创建事务来存储状态,他只会根据查询到的URI(请求转发)或者via头(响应转发)的内容确定目标地址,进行转发。
(2)调用forward_request是无状态的请求入口,同样的,proxy服务器也会根据域名查询到联系人的具体地址,把找到的信息(host+port+协议)存储在$du里面,后续可以通过读取$du来设置转发联系地址。
需要注意的是forward_request参数列表是(struct sip_msg msg,str dst,…..)这里的dst并不是dest_info结构体,而是host主机名,因为找到其他含有str *dst参数的函数,在函数里&u->host,u是一个sip_uri结构体变量,里面有host就是主机名。所以说这个dst是URI中的host。
(3)接着走到forward_request_mode,已经得到了转发目标的host,port。通过dns_sip_resolve2su把他们转成sockaddr_union结构,存入dst.to,这样发送目标地址确定了,就可以进行转发。
(4)现在B收到请求之后,返回一个响应,调用do_forward_reply,代理收到响应之后会先看第一个via头是否和自己匹配(匹配的详细过程在补充的问题里面),接着还要判断是否有第二个via头,没有的话就错误,无法转发。会调用update_sock_struct_from_via(&dst.to, msg, msg->via2)从via2中提取转发目标,在处理响应转发的逻辑中,端口选择上:if(via->rport && via->rport->value.s)如果有rport参数,优先使用它。主机名选择上:if(via->received)name = &(via->received->value);如果有received参数,使用它,如果没有就使用via的host(else name=&(via->host))。接着解析主机名:proto = via->proto;he = sip_resolvehost(name, &port, &proto);如果是IP地址,直接转换;如果是主机名,进行DNS查询。将获得的hostent结构转换为dst.to,hostent2su(to, he, 0, port);这样就把确定了响应的转发目标地址。
至此,整个无状态请求和响应的转发过程就完成了。
五.补充的问题
1.一个ST(服务器事务)和多个CT(客户端事务)之间是不是共用一个branch,如果不是的话,在创建了多个CT的时候,via中的branch参数怎么更新,在哪个函数中更新。
现在A和B之间要进行通话,假设A要呼叫B的多个设备
A → 代理 → B(手机)
↘ B(固话)
↘ B(平板)
一个ST(服务器事务):处理A的请求
多个CT(客户端事务):分别呼叫B的多个设备
ST就会创建多个CT,所以一个ST可能对应多个CT。首先需要知道的数据结构:cell T里面有一个字段是int nr_of_outgoings,它的含义是分支数量,也就是CT数量(他有最大默认值,MAX_BRANCHES_DEFAULT,每个事务的最大分支数,默认值为12)。
在add_uac函数里面,首先会通过branch=t->nr_of_outgoings,假设有两个CT,那就可以用这种方式获得新CT,也就是第三个CT的索引(2),后续t->nr_of_outgoings=(branch+1),会对CT的数量进行加一更新。
在t_forward_nonack中,函数调用顺序add_uac->prepare_new_uac->t_calc_branch->branch_builder,由于在add_uac先通过branch = t->nr_of_outgoings;获得了新CT的索引,然后再调用prepare_new_uac的,所以在branch_builder里面,通过int2reverse_hex(&begin,&size,branch),
拼接,就会把索引加到原来的branch后面,拼接函数为int2reverse_hex。t_calc_branch,branch_builder这两个函数有branch参数,branch_builder中的branch是输出参数,branch_builder填充好之后,在t_calc_branch是生成函数,里面会填充为 i_req->add_to_branch_s,也就是对request里的branch进行了更新。
在构建消息build_req_buf_from_sip_req的函数中,branch.s=msg->add_to_branch_s,这样对整个branch就完成了索引的添加以及更新。
综上所述,ST和多个CT不共用branch,每个CT有自己唯一的branch。
通过branch_builder(…, branch_index, …)生成,更新branch参数,包含事务标识 + 分支索引。
生成:branch_builder()(在t_calc_branch()中调用),每个CT的branch参数在创建时生成,包含唯一的分支索引,用于后续的响应匹配。
2.tm里面的cell T是如何存储在hash表里的,如果写入,如何检索
cell T这个结构体里面有一个hash index是哈希索引(记录这个事务在哪个hash桶) ,t事务是存储在哈希表里面的(通过hash桶+链表的方式存储)。
写入过程:相关函数调用顺序:t_newtran->new_t->new_cell=build_cell(p_msg)
->insert_into_hash_table(new_cell,p_msg->hash_index)
在insert_into_hash_table函数里面,p_cell->hash_index = hash;(设置索引)。 clist_insert(&_tm_table->entries[hash], p_cell, next_c, prev_c);(把他插入到链表头部,也就是写入)
检索过程:相关函数调用顺序:t_check->t_check_msg->t_reply_matching,t_reply_matching,查找具体的事务先先通过hash index找到桶,hash_bucket = &(get_tm_table()->entries[hash_index]);通过clist_foreach(hash_bucket, p_cell, next_c)遍历事务链表。里面使用call-id、MD5进行匹配,还需要验证分支索引是否有效,如果上述这些都匹配成功,就设置当前事务,set_t(p_cell, (int)branch_id);*p_branch = (int)branch_id;p_cell就是当前的事务。
3.有状态的响应消息到达之后,tm如何来匹配事务(CT),找到对应的uac[index]
在收到响应的时候,相关函数的调用顺序是:t_check->t_check_msg->t_reply_matching,t_reply_matching函数就是获取与回复对应的事务。
首先需要知道branch参数的组成,它是由“MCOOKIE、hash_id、md5 value、branch_id”组成的。
在t_reply_matching函数中,首先会检查这个响应消息中的via是否存在branch参数,如果不存在,直接返回错误。通过看MCOOKIE是否为“z9hG4bk”(符合RFC3261),需要是有效的branch,然后提取其他三个部分。
用hash_index去找hash桶,(在条目“hash_index”处搜索哈希表列表),hash_bucket = &(get_tm_table()->entries[hash_index]);通过clist_foreach(hash_bucket, p_cell, next_c)遍历事务链表,检查每个事务。在这个函数里面使用call-id(为了安全检查)、MD5(确保是正确的事务)进行匹配,还需要验证分支索引(防止索引越界)是否有效,方法匹配,如果上述这些都匹配成功,就设置当前事务,set_t(p_cell, (int)branch_id);p_branch = (int)branch_id;p_cell就是当前的事务,p_branch是匹配的分支索引,通过T->uac[*p_branch]访问对应的CT
4.在收到响应之后,如果是无状态的响应转发,proxy 判断via 1是否指向自己
收到响应之后会调用do_forward_reply函数,在这个函数里面会调用check_self函数检查第一个via头是否为本机,如果不是的话,就是错误。
if(check_self(&msg->via1->host, msg->via1->port ? msg->via1->port : SIP_PORT,msg->via1->proto)他是检查给定的host(proxy.com),port(5060),proto(UDP)是否匹配本代理的地址 ,在check_self函数中会调用grep_sock_info(host, port, proto)进行匹配。
首先用list=get_sock_info_list(c_proto);来获得指定协议的socket列表,for(si = *list; si; si = si->next)遍历每个socket,在遍历每个socket的时候,会匹配端口;
接着si_hname_cmp函数实现了三种主机名匹配方式,第一种是:strncasecmp(host->s, name->s, name->len) 主机名字符串匹配(用于域名匹配);第二种是ip_addr_cmp(ip6, ip_addr)解析IPV6地址并匹配;第三种是memcmp(host->s, addr_str->s, addr_str->len)IPV4地址字符串进行匹配。
所以说匹配的顺序优先级是:先获得指定协议的socket列表,遍历socket列表的时候,先匹配端口,匹配成功之后,顺序优先级是:先尝试主机名字符串匹配,再尝试IPv6地址匹配,最后尝试IPv4字符串匹配。这样就能判断Via头是否指向自己,通过多种匹配方式确保能够正确识别各种格式的主机名和地址。
5.对于无状态的响应转发来说的, do_forward_reply如何根据VIA2确定下一跳地址
在do_forward_reply函数中,会调用update_sock_struct_from_via(&dst.to, msg, msg->via2)从via2中提取转发目标,在处理响应转发的逻辑中,端口选择上:if(via->rport && via->rport->value.s)如果有rport参数,优先使用它。主机名选择上:if(via->received)name = &(via->received->value);如果有received参数,使用它,如果没有就使用via的host(else name=&(via->host))。接着解析主机名:proto = via->proto;he = sip_resolvehost(name, &port, &proto);如果是IP地址,直接转换;如果是主机名,进行DNS查询。将获得的hostent结构转换为dst.to,hostent2su(to, he, 0, port);
举个例子:
①标准转发via头
Via: SIP/2.0/UDP proxy.com:5060;branch=z9hG4bKabc123
处理:
- 检查rport: 无
- 检查received: 无
- name = “proxy.com”
- port = 5060
- proto = PROTO_UDP
- 解析: proxy.com → 192.168.1.100
- 结果: 192.168.1.100:5060 UDP
②带NAT参数的via头
Via: SIP/2.0/UDP 192.168.1.100:5060;received=203.0.113.20;rport=12345
处理:
- 检查rport: 有 → port = 12345
- 检查received: 有 → name = “203.0.113.20”
- proto = PROTO_UDP
- 解析: 203.0.113.20是IP,直接使用
- 结果: 203.0.113.20:12345 UDP

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)