【AI课程领学】第五课 · 循环神经网络(课时1) 循环神经网络基本组件与操作(含 PyTorch 示例)
【AI课程领学】第五课 · 循环神经网络(课时1) 循环神经网络基本组件与操作(含 PyTorch 示例)
·
【AI课程领学】第五课 · 循环神经网络(课时1) 循环神经网络基本组件与操作(含 PyTorch 示例)
【AI课程领学】第五课 · 循环神经网络(课时1) 循环神经网络基本组件与操作(含 PyTorch 示例)
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可扫描博文下方二维码 “
学术会议小灵通”或参考学术信息专栏:https://ais.cn/u/mmmiUz
详细免费的AI课程可在这里获取→www.lab4ai.cn
前言
- 在图像任务里,我们已经见过 CNN 会利用“空间结构”;而在时间序列、文本、语音、轨迹等任务中,时间顺序与上下文依赖 是核心。
- 循环神经网络(Recurrent Neural Network, RNN)就是为此而设计的一类结构。
这一篇我们搞清楚 4 件事:
- 时序数据在深度学习里的标准数学表示
- Vanilla RNN 的基本计算公式与结构
- RNN 的几种典型输入输出形式(many-to-one、many-to-many 等)
- 用 PyTorch 动手实现一个最小 RNN 例子(序列分类)
一、时序数据在深度学习中的表示方式
- 假设我们有一段长度为 T T T 的序列,每个时间步的特征向量维度为 d d d,用数学符号记为:
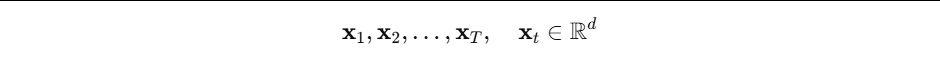
在深度学习框架里,一般再加一个 batch 维度,得到形状: - PyTorch 默认 RNN 输入:(
seq_len, batch_size, input_size) - 也可以设置
batch_first=True则为:(batch_size, seq_len, input_size)
举例:对 32 条长度为 10 的时间序列,每个时间步是 8 维特征:
seq_len = 10batch_size = 32input_size = 8
如果使用 batch_first=True,输入张量形状就是:(32, 10, 8)。
二、Vanilla RNN 的基本结构与公式
- 最基础的 RNN 可以理解成一个“带记忆的全连接层”:
- 在每个时间步 t t t,RNN 接收当前输入 x t x_t xt和上一时刻隐藏状态 h t − 1 h_{t−1} ht−1,输出当前隐藏状态 h t h_t ht:
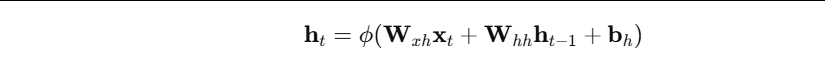
其中: - W x h W_{xh} Wxh:输入到隐藏的权重矩阵
- W h h W_{hh} Whh:隐藏到隐藏(递归)的权重矩阵
- ϕ ϕ ϕ:非线性函数(tanh 或 ReLU 等)
- h 0 h_0 h0:初始隐藏状态(通常设为 0)
因为 h t h_t ht 依赖 h t − 1 h_{t-1} ht−1,而 h t − 1 h_{t-1} ht−1 又依赖 h t − 2 h_{t-2} ht−2……
所以 RNN 在理论上能够捕捉到“很长时间跨度”的依赖。
输出层 常见两种做法:
- 只用最后一个隐藏状态做预测:
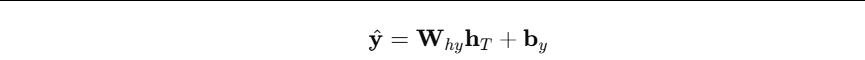
- 对每个时间步都做预测:
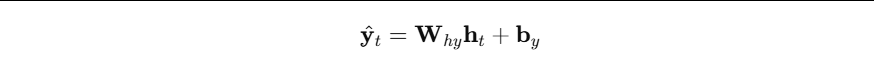
分别对应下面要讲的多种输入-输出形式。
三、RNN 的几种典型输入输出形式
RNN 非常灵活,不同任务可以选择不同结构:
1. Many-to-One(多步输入 → 一个输出)
- 比如情感分类:输入是一整句文本,输出是“正面/负面”。
- 实现:通常取最后一个时间步的隐藏状态 h_T 接一个全连接分类层。
2. One-to-Many(一个向量 → 一段序列)
- 比如音乐生成:输入风格向量,输出整段旋律。
- 实现:可以用一个初始输入重复喂给 RNN,逐步预测下一个输出。
3. Many-to-Many(对齐)
- 比如序列标注:每个时间步都要预测一个标签(词性标注、命名实体识别)。
- 实现:每个
h_t接一个分类头。
4. Many-to-Many(不对齐)
- 比如翻译:输入英文序列,输出中文序列,长度可能不同。
- 通常用 Encoder-Decoder + Attention(下一课会展开)。
四、用 PyTorch 实战:一个最小 RNN 序列分类例子
我们用一个 toy 例子来感受 RNN 的使用流程:
- 任务:给定一段 0/1 序列,判断其中 1 的总数是否大于某个阈值(比如一半),输出二分类标签。
- 虽然任务简单,但非常适合演示「序列 → 向量 → 分类」的流程。
4.1 准备数据
import torch
from torch.utils.data import Dataset, DataLoader
import random
class BinarySequenceDataset(Dataset):
def __init__(self, num_samples=1000, seq_len=10):
self.data = []
for _ in range(num_samples):
seq = [random.randint(0, 1) for _ in range(seq_len)]
# 标签:如果 1 的数量 > seq_len/2 则为 1,否则为 0
label = int(sum(seq) > seq_len / 2)
self.data.append((seq, label))
self.seq_len = seq_len
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
seq, label = self.data[idx]
# 转成 float tensor,形状:(seq_len, 1)
x = torch.tensor(seq, dtype=torch.float32).unsqueeze(-1)
y = torch.tensor(label, dtype=torch.long)
return x, y
train_ds = BinarySequenceDataset(num_samples=2000, seq_len=10)
train_loader = DataLoader(train_ds, batch_size=32, shuffle=True)
- 注意这里我们返回的是
(seq_len, 1),后面会设置batch_first=False,让 RNN 的输入为(seq_len, batch, input_size)。
4.2 定义一个简单 RNN 分类模型
import torch.nn as nn
class SimpleRNNClassifier(nn.Module):
def __init__(self, input_size=1, hidden_size=32, num_layers=1, num_classes=2):
super().__init__()
# batch_first=False,输入维度:(seq_len, batch, input_size)
self.rnn = nn.RNN(
input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
nonlinearity="tanh",
batch_first=False
)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
# x: (seq_len, batch, input_size)
out, h_n = self.rnn(x)
# out: (seq_len, batch, hidden_size)
# 取最后一个时间步的隐藏状态
last_hidden = out[-1] # (batch, hidden_size)
logits = self.fc(last_hidden)
return logits
4.3 训练循环
import torch.optim as optim
import torch.nn.functional as F
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = SimpleRNNClassifier().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
for epoch in range(10):
model.train()
total_loss, correct, total = 0.0, 0, 0
for x, y in train_loader:
# x: (batch, seq_len, 1) → 转为 (seq_len, batch, 1)
x = x.permute(1, 0, 2).to(device)
y = y.to(device)
logits = model(x)
loss = F.cross_entropy(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item() * y.size(0)
preds = logits.argmax(dim=1)
correct += (preds == y).sum().item()
total += y.size(0)
print(f"Epoch {epoch+1}, loss={total_loss/total:.4f}, acc={correct/total:.4f}")
- 你会看到,哪怕是最基础的 RNN,这个 toy 任务也能很快达到接近 1.0 的分类精度。
五、小结与预告
本篇主要建立了 RNN 的“基本词汇”:
- 时序数据的张量形状与 batch 组织方式
- Vanilla RNN 的前向计算公式
- 多种输入输出结构(many-to-one、many-to-many 等)
- 用 PyTorch 实现了一个最小 RNN 序列分类模型
下一篇(课时2)我们会系统整理循环神经网络的经典结构:
- 简单 RNN 为什么容易梯度消失?
- LSTM 的门结构公式与直觉
- GRU 的简化思想
- 双向 RNN 在序列标注、文本任务中的优势

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)