RAG 检索分不清“李逵”和“李鬼”?手把手微调垂直领域 Rerank 模型,让干扰项归零!
摘要: Embedding模型在召回文档时,常因语义相似但内容无关的“干扰项”导致大模型错误回答。为解决该问题,可采用**Rerank模型(Cross-Encoder)**进行精细化排序,其通过全注意力机制实现Query与Document的深层交互,显著提升精度。微调Rerank需高质量数据,重点挖掘“硬负例”(表面相关但实际无关的文档),并结合硬件优化Batch Size、Epochs和学习率等
Embedding 召回回来的文档,大模型经常对着“干扰项”一本正经地胡说八道。
比如用户问 “企业研发费用加计扣除申报流程”。 Embedding 可能会召回 “高新技术企业认定管理办法”。
为什么?因为它们都包含“企业”、“研发费用”、“管理”这些高频词。Embedding 模型(Bi-Encoder)只看大概轮廓,觉得它俩长得简直一模一样。
这时候,我们需要引入 RAG 里的“神探”——Rerank 模型。
今天,结合我最近在政务领域的真实调优案例(在 3090 卡上调优),手把手带大家走一遍 Rerank 微调的全流程。
一、 核心原理:为什么 Rerank 更精准?
要微调 Rerank,首先必须理解它与 Embedding 模型的本质区别。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
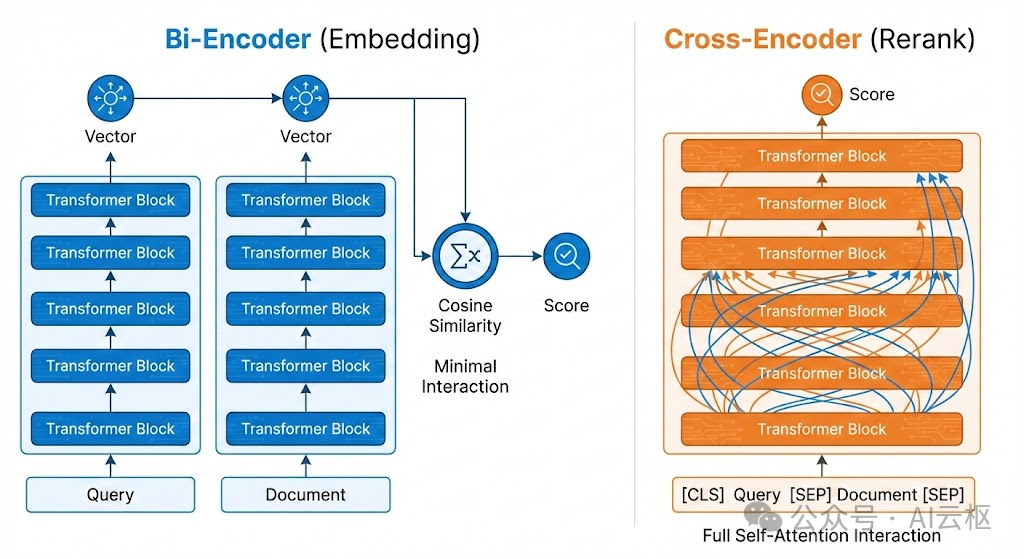
1. Bi-Encoder (Embedding)
Embedding 模型采用 双塔架构 (Bi-Encoder)。Query 和 Document 分别独立输入模型,计算出各自的向量,最后通过计算余弦相似度来衡量相关性。
•局限性: 这种方式导致 Query 和 Document 之间没有深层的 token 级交互,只能捕捉表层的语义相似度。
2. Cross-Encoder (Rerank)
Rerank 模型采用 交叉编码架构 (Cross-Encoder)。
•输入形式: 将 Query 和 Document 拼接成一个长序列输入模型:[CLS] Query [SEP] Document [SEP]。•优势: 利用 Transformer 的 全注意力机制 (Full Self-Attention),Query 中的每一个 token 都能注意到 Document 中的每一个 token。•效果: 模型能精确捕捉逻辑关系(如否定、因果、条件限制),因此精度远高于 Bi-Encoder。•微调的本质: 就是让 Cross-Encoder 这个“高精度的判别器”,学习特定垂直领域的正负样本分布边界。
第一步:数据工厂挖掘硬负例
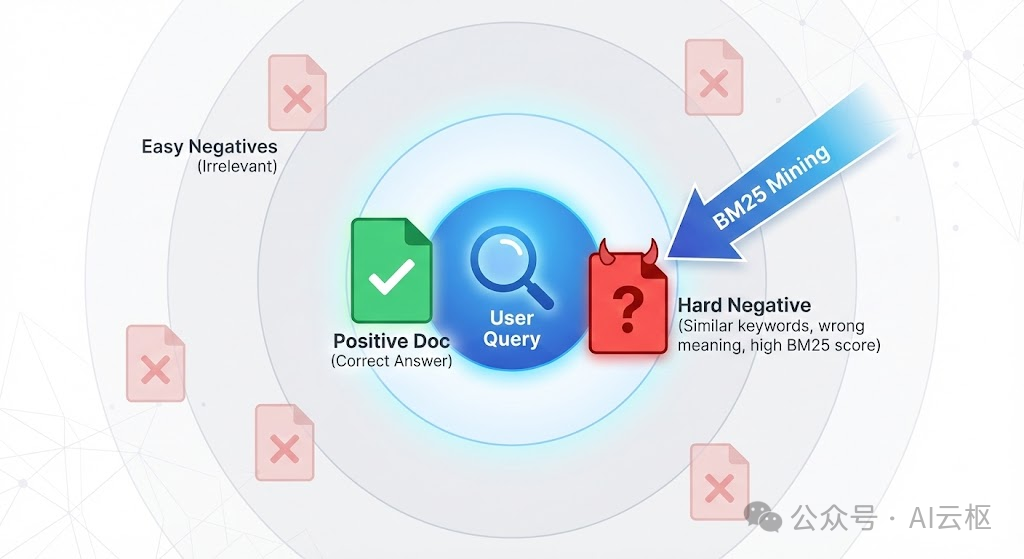
Rerank 微调,数据质量 > 模型参数。
随便找点不相关的文档做负例(随机负例)是没用的,模型学不到东西。我们需要挖掘 “硬负例”:那些字面上含有关键词,但实际上文不对题的文档。
我封装了一个自动化脚本,利用 LLM 生成问题 + BM25 挖掘干扰项。
代码示例:数据生成``
def build_dataset():
corpus = load_documents_recursive(INPUT_DIR)
if not corpus:
print("未找到有效文档,请检查路径。")
return
# 构建 BM25 索引
print("正在构建 BM25 索引 (用于挖掘硬负例)...")
# 简单的分词,实际生产可以用更复杂的
tokenized_corpus = [list(jieba.cut(doc)) for doc in corpus]
bm25 = BM25Okapi(tokenized_corpus)
all_data = []
# 生成流水线
print(f"开始生成 Q-A 对及挖掘负例 (预计耗时较长)...")
# 为了演示,如果你想快速测试,可以把 corpus[:50] 限制数量
for idx, doc in tqdm(enumerate(corpus), total=len(corpus), desc="Generating"):
# 生成 Query
query = generate_query_via_llm(doc)
if not query: continue
# 挖掘硬负例
tokenized_query = list(jieba.cut(query))
scores = bm25.get_scores(tokenized_query)
# 取 Top-K
top_indexes = sorted(range(len(scores)), key=lambda i: scores[i], reverse=True)[:BM25_TOP_K]
hard_negatives = []
for neg_idx in top_indexes:
candidate = corpus[neg_idx]
# 排除原文本身,且去重
if candidate != doc and candidate not in hard_negatives:
hard_negatives.append(candidate)
# 凑够数量就停
if len(hard_negatives) >= (NEG_COUNT - 1):
break
# 如果硬负例不够,用随机负例凑
while len(hard_negatives) < NEG_COUNT:
rand_doc = random.choice(corpus)
if rand_doc != doc and rand_doc not in hard_negatives:
hard_negatives.append(rand_doc)
# Rerank 格式标准
item = {
"query": query,
"pos": [doc],
"neg": hard_negatives[:NEG_COUNT] # 确保数量一致
}
all_data.append(item)
第二步:参数调优策略
一些教程直接告诉你“Batch Size 设为多少多少”。这是不负责任的。 在实战中,硬件环境不同、数据长度不同,参数必须动态调整。或者可以直接上超参调优。
1. Batch Size:探底线,测极限
Rerank 模型计算量极大。Batch Size 的大小直接决定了训练速度和梯度的稳定性。
•调优策略(压力测试): 不要猜。写一个简单的 Loop,从 BATCH_SIZE = 1 开始,成倍增加(1, 2, 4, 8, 16…),或者以 8 为单位递增,直到报错 OOM 。•实战案例: 在我的 RTX 3090 (24G) 上,微调 bge-reranker-large:•Set 32 -> 轻松跑通。•Set 48 -> OOM 炸显存。•Set 40 -> 显存占用 22297MiB (93% 负载)。
•结论: 在不 OOM 的前提下,Batch Size 越大越好,训练越稳。
2. Epochs:看 Loss,防过拟合
不要死板地设为 3 或 5。
•调优策略: 观察验证集 Loss。如果 Loss 不再下降,或者 Gap(区分度)开始变差,说明模型开始“背题”了。•经验值:•数据 < 1000 条:建议 5~10 Epochs(多学几遍)。•数据 > 10000 条:建议 1~2 Epochs(见多识广)。
3. Learning Rate:保守起见
•策略: Rerank 模型本身很聪明,微调是“修剪”不是“重塑”。•推荐范围:1e-5 ~ 3e-5。过大会导致模型坍塌(所有打分都一样)。
第三步:训练代码
这是经过优化的训练脚本,支持自动加载上面的 JSONL 数据。
代码示例:模型训练
def train_rerank():
# 1. 初始化模型
print(f"加载基座模型: {MODEL_NAME} ...")
# num_labels=1 会自动使用 BCEWithLogitsLoss (适合打分任务)
model = CrossEncoder(MODEL_NAME, num_labels=1, max_length=MAX_LENGTH)
# 2. 准备数据
train_samples = load_dataset(TRAIN_FILE)
val_samples = load_dataset(VAL_FILE)
if not train_samples:
raise ValueError("训练集为空!")
# SentenceTransformers 需要用 DataLoader 封装
train_dataloader = DataLoader(train_samples, shuffle=True, batch_size=BATCH_SIZE)
# 3. 准备评估器
# 既然有验证集,就用验证集;如果没有,从训练集切一点
eval_data = val_samples if val_samples else train_samples[:50]
evaluator = CEBinaryClassificationEvaluator.from_input_examples(eval_data, name='Rerank-Eval')
# 计算预热步数
warmup_steps = int(len(train_dataloader) * NUM_EPOCHS * 0.1)
print(f" 开始使用 SentenceTransformers 训练...")
print(f" - 混合精度 (AMP): 关闭 (最稳模式)")
print(f" - Batch Size: {BATCH_SIZE}")
model.fit(
train_dataloader=train_dataloader,
evaluator=evaluator,
epochs=NUM_EPOCHS,
warmup_steps=warmup_steps,
output_path=OUTPUT_DIR,
save_best_model=True,
show_progress_bar=True,
optimizer_class=torch.optim.AdamW,
optimizer_params={'lr': LEARNING_RATE},
use_amp=False
)
# 5. 双重保险:强制保存一次
print(f"正在保存最终模型到: {OUTPUT_DIR} ...")
model.save(OUTPUT_DIR)
print("训练完成!")

第四步:效果评测
训练完别急着上线,一定要看 Gap (区分度)。 我们需要关注:模型是否真的把“干扰项”的分数压下来了?
代码示例:对比评测
def compare_models():
for i, case in enumerate(test_cases):
# 限制只展示前 5 条 + 后 2 条,防止刷屏(如果数据很多)
if i >= 5 and i < len(test_cases) - 2:
continue
query = case['query']
pos = case['pos']
neg = case['neg']
# 截断长文本用于显示
pos_display = (pos[:40] + '...') if len(pos) > 40 else pos
neg_display = (neg[:40] + '...') if len(neg) > 40 else neg
# 构造输入对
pair_pos = [query, pos]
pair_neg = [query, neg]
# 基座打分
scores_base = base_model.predict([pair_pos, pair_neg])
score_pos_base = scores_base[0]
score_neg_base = scores_base[1]
gap_base = score_pos_base - score_neg_base
# 微调打分
scores_ft = ft_model.predict([pair_pos, pair_neg])
score_pos_ft = scores_ft[0]
score_neg_ft = scores_ft[1]
gap_ft = score_pos_ft - score_neg_ft
# 打印报告
print(f"\n[Case {i+1}] 提问: {query}")
print(f" 正确: {pos_display}")
print(f" 干扰: {neg_display}")
print("-" * 40)
# 格式化输出基座结果
status_base = "危险" if gap_base < 1.0 else "尚可"
if score_neg_base > score_pos_base: status_base = "排序错误"
print(f"基座模型 | 正例: {score_pos_base:7.4f} | 负例: {score_neg_base:7.4f} | Gap: {gap_base:7.4f} [{status_base}]")
# 格式化输出微调结果
status_ft = "优秀" if gap_ft > gap_base else "持平"
if score_neg_ft > score_pos_ft: status_ft = "翻车"
print(f"微调模型 | 正例: {score_pos_ft:7.4f} | 负例: {score_neg_ft:7.4f} | Gap: {gap_ft:7.4f} [{status_ft}]")
# 结论判定
if score_neg_ft < score_neg_base - 1.0:
print(" 结论: 成功识别并压制了干扰项!")
elif gap_ft > gap_base + 1.0:
print(" 结论: 显著拉开了正负例差距!")
真实评测结果
为了直观展示效果,我们绘制了微调前后模型对 正例(蓝色) 和 硬负例(橙色) 打分的对比图:
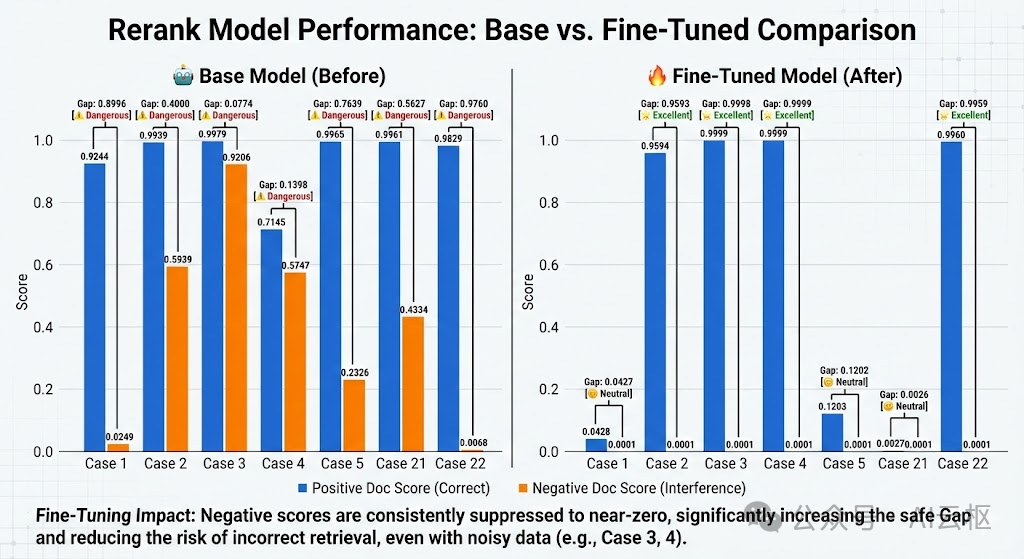
请注意观察橙色柱状图(干扰项得分)的变化!
1. 核心胜利:语义陷阱被“降维打击”
测试 Case 2: “企业研发费用加计扣除申报流程”
•干扰项: 《高新技术企业认定管理办法》(都有“研发费用”,但一个是扣除,一个是认定)。•基座模型: 负例得分高达 0.5939。Gap 仅 0.4。•解读: 基座模型犹豫了,它觉得干扰项很有可能是对的,极易导致 RAG 检索出错。
•微调模型: 负例得分 0.0001。Gap 扩大到 0.9593。•解读: 微调后的模型像开了“天眼”,一眼识破“认定”和“扣除”的业务差异,直接把干扰项分数归零。
2. 意外之喜:无视“脏数据”格式干扰
测试 Case 3 & 4: 文档中包含大量 OCR 识别错误和换行符(如 改动市\n政燃气设\n施...)。
•基座模型: 彻底崩盘。Case 3 的 Gap 只有 0.07,Case 4 的正例得分甚至跌到 0.7。•解读: 通用模型对格式非常敏感,乱码直接干扰了它的判断。
•微调模型: 稳如泰山。Case 3 和 4 的正例得分均在 0.999 以上,负例 0.0001。•解读: 我们的模型学会了透过现象看本质,完全忽略了格式噪音,死死咬住了语义匹配。
3. 专家视角:如何看待“分数变低”? (Case 1 & 21)
细心的朋友可能发现了,在 Case 21(户外广告)中,微调后正例得分只有 0.0027。
•疑问: 0.0027 这么低,是不是模型坏了?•答案: 完全没坏,反而更强了。•Rerank 模型的唯一使命是 排序 (Ranking),而不是输出绝对概率。•虽然正例只有 0.0027,但负例是 0.0001。正例依然比负例高出 27 倍!•这说明模型变得极其**“高冷”和“严谨”**。经过大量硬负例的训练,它学会了:“只要不是 100% 完美匹配,我就不轻易给高分”。但在 RAG 系统取 Top-k 时,正确的文档依然会稳稳排在第一名。
评测结论
通过这组数据我们可以看到,微调后的模型达成了两个核心目标:
1.去噪: 将所有干扰项的得分压制到了 0.0001 的极限低值。2.鲁棒: 在乱码、格式错误等脏数据下,依然能保持 Gap > 0.99 的超强区分度。
总结与工程落地建议
在垂直领域的 RAG 系统建设中,通用 Rerank 模型往往面临领域适配性不足的问题。本次实战证明,通过构建高质量数据集并进行微调,可以有效解决这一痛点。
基于本次实践,我们将核心经验总结为以下三点工程建议:
•数据构建是核心: Rerank 模型的微调并不依赖海量数据,但对数据质量极度敏感。引入**“硬负例”**是提升模型鲁棒性的关键。仅依靠随机负例无法让模型学习到业务逻辑的细微边界。•激进的显存优化策略: 在工程实践中,不应拘泥于默认参数。在 RTX 3090 等消费级显卡上,建议通过压力测试找到 Batch Size 的物理极限(如本次的 BS=40)。更大的 Batch Size 能提供更稳定的梯度估计,显著提升训练效率和收敛效果。•正确的评估指标: 在 Rerank 任务中,绝对分值参考意义有限。应重点关注 Gap(正负例分差) 和 Top-k 排序的准确性。微调后的模型可能会整体压低分值以降低误判率,这属于正常现象,不应作为模型失效的判断依据。
微调 Rerank 模型是提升 RAG 检索精度的有效手段,希望本文提供的全流程代码和参数调试思路,能为各位在实际项目落地中提供参考。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献137条内容
已为社区贡献137条内容

所有评论(0)