【大模型与信息抽取】EventRL: Enhancing Event Extraction with Outcome Supervision for Large Language Models
具体来说,当涉及到事件提取时,两种类型的错误-事件类型的错误预测和事件参数角色的错误预测-通常与正确的样本仅在文本中有一个单词的差异。:提出的EventRL框架在三种不同的配置中进行了评估,每种配置都使用了不同的奖励函数,旨在优化模型在事件提取中的性能:EventRL(Arg-F1)使用Argument-F1作为反馈,EventRL(Avg-F1)旨在平衡 Trigger-F1 和 Argumen
前言:本文提出了EventRL,一种强化学习方法,旨在增强大型语言模型(LLM)的事件提取(EE)。EventRL利用具有特定奖励函数的结果监督来解决LLM中普遍存在的挑战,例如:指令遵循和幻觉,表现为事件结构的不匹配和未定义事件类型的生成。此外,评估EventRL与现有方法,如:FewShot优化(FSP)和监督微调(SFT)在各种LLM,包括GPT-4,LLaMa和CodeLLaMa模型。研究结果表明,EventRL通过提高识别和结构化事件的性能,特别是在处理新事件类型方面,显着优于这些传统方法。
1.介绍
事件提取任务中,模型经常遇到:事件结构的不匹配和未定义事件类型的生成的挑战,如下图所示。事件结构中的不匹配指的是不准确性,如错误地包含了不相关的参数。例如:“攻击”事件错误地包含了不存在的“实体”角色。未定义事件类型的生成是指模型对任务指令中未预定义的事件类型的预测。例如:在与选举相关的文本中,模型可能无法预测“投票”事件类型,而该类型在任务说明中未定义。这些问题可以被看作是事件提取领域内的指令遵循和幻觉问题的表现。最近的研究尝试使用监督微调(SFT)方法来解决这些挑战,但其性能远远不能令人满意。其潜在的原因是事件提取需要对抽象概念和关系进行过多的识别,并且这表明需要更多地关注于增强对事件理解的高级理解。

SFT方法在事件提取中的一个主要限制是它们无法准确识别事件结构中的错误,例如:不正确的参数包含或预测指南中未定义的事件。这个问题可能源于对负对数似然(NLL)损失的依赖,该损失虽然对于一般语言建模有效,但在捕获事件提取的复杂性方面不足。具体来说,当涉及到事件提取时,两种类型的错误-事件类型的错误预测和事件参数角色的错误预测-通常与正确的样本仅在文本中有一个单词的差异。然而,在NLL损失方面,这些错误仅导致微小的差异,未能反映其对事件提取性能的显著影响。这种差异特别重要,因为预测事件类型的错误可能导致提取所有相关参数时出现一连串错误,从而大大降低整个提取过程的准确性。因此,虽然NLL损失可能会轻微惩罚这些错误,但其实际后果要严重得多。
一个潜在的解决方案是将模型在识别和构建事件方面的性能反馈整合到其训练过程中,这种被称为结果监督的方法,是从以前解决数学问题的工作中得到的启发。通过纳入基于结果的反馈,该模型可以调整和完善其策略,以便更准确地识别和构建事件,解决其在理解和提取文本中的事件方面面临的具体挑战。
为此,文中引入了新的强化学习框架EventRL,旨在通过直接响应模型输出的准确性来增强事件提取。它利用结果绩效作为反馈来惩罚错误,指导模型调整其策略以获得更好的绩效。探索了三种事件特定的奖励函数:Argument-F1、Average-F1 和 Product-F1。此外,为了提高训练的稳定性,引入了 Teacher-Force Threshold (阈值) 和 Advantage Clipping strategies (优势裁剪策略),以减轻策略退化和防止灾难性遗忘。主要贡献可概括如下:
- 将结果监督引入到事件抽取的LLM中,重点关注任务结果,以提高事件的理解和抽取。
- EventRL,这是一种通过具有定制奖励函数的强化学习实现结果监督的新方法,为EE提供更精确和有针对性的训练方法。
- 使用不同大小的LLM进行的广泛实验表明,EventRL的性能显着优于标准SFT方法。值得注意的是,EventRL在处理不可见事件方面表现出显着的改进,并显着减少了事件结构和类型定义中的错误,从而验证了结果监督在提升EE中LLM功能方面的有效性。
2.方法
如图2所示,EventRL从SFT阶段开始,以建立对事件提取的基本理解。然后,它进一步实施结果监督,利用基于结果的奖励函数,通过强化学习指导模型训练。为了确保稳定和有效的学习,EventRL采用了稳定策略,包括 Teacher-Force 阈值 和 Advantage Clipping,缓解策略退化和防止灾难性遗忘。
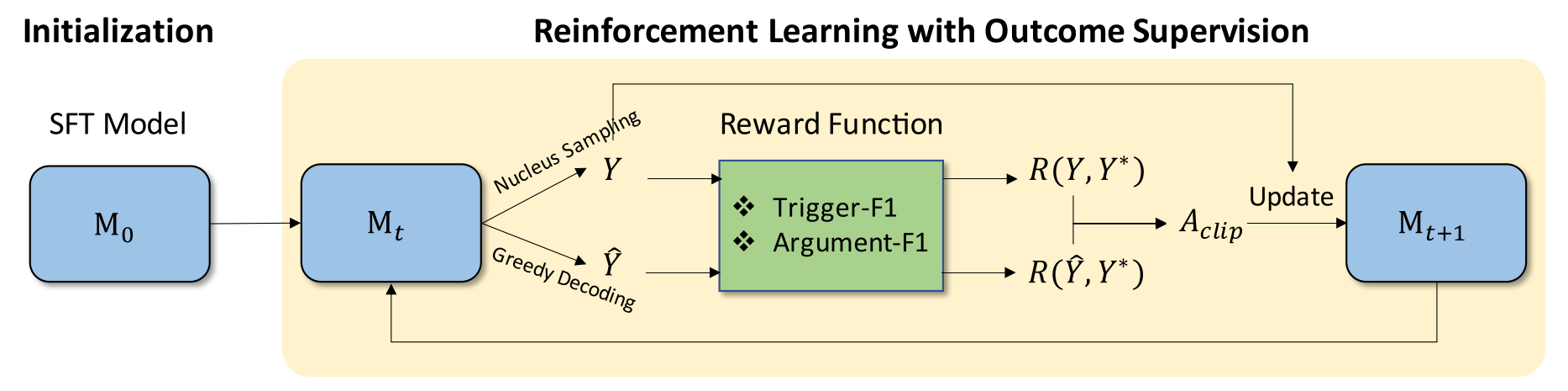
2.1 初始化
输入和输出格式:在EventRL的学习阶段,采用了混合输入和输出格式,如图3所示。将用于事件定义的结构化 Python 数据类格式与用于任务描述的自然语言指令相结合。这允许精确的事件表示,同时保持用户友好的指令。输出是数据类实例的Python列表,以结构化和可编程的格式表示提取的事件。这种混合格式增强了模型准确处理和输出复杂事件信息的能力,弥合了结构化编码和自然语言理解之间的差距。

有监督的微调:SFT过程是一个重要的初始阶段,它建立了对模型中事件提取过程的基础理解。在SFT期间,使用由示例组成的标签数据集来训练模型,其中每个事件都用其对应的触发器和参数显式定义。
2.2 使用RL进行结果监督
问题表述:为了实施结果监督,利用强化学习。RL方法将事件提取视为一个顺序决策过程,其中模型在其策略的指导下,基于输入X生成预测Y,其中包括事件触发器及其自变量。该模型的参数被更新,以最大化预期回报,利用 advantage-based policy optimization 指导学习。更新规则如下:
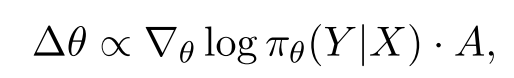
奖励函数:在EventRL框架中,奖励函数主要关注两个方面:触发器提取和参数提取。这些方面分别通过 Trigger-F1 和 Argument-F1 分数进行量化,作为奖励函数的基础。Trigger-F1分数评估模型准确识别和分类事件触发器的能力,而Argument-F1分数评估识别和分类与这些触发器相关的参数的精度。采用以下评估标准:如果触发器的事件类型正确,则触发器是正确的。类似地,如果参数的事件类型和角色匹配同时正确,则认为参数被正确识别。
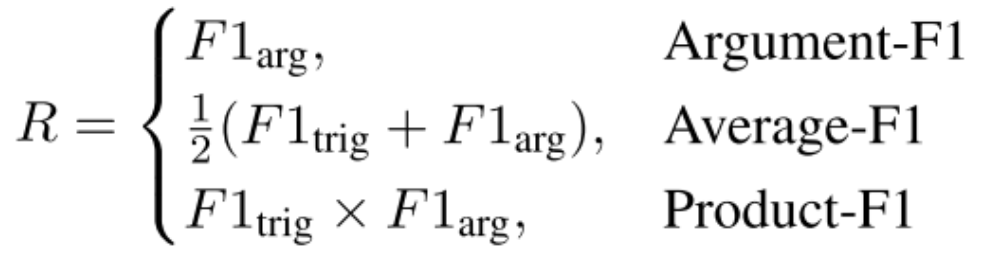
优势函数:为了计算优势,比较了两种不同的策略提取事件的回报:贪婪解码 (Greedy Decoding, GYY) 和 核采样 (Nucleus Sampling, Y)。当处理给定文本时,该模型生成两个输出:一个通过贪婪解码Y^,另一个通过核采样Y。然后,通过计算它们的奖励来评估这些输出。优势函数A通过测量其奖励的差异来量化核采样策略相对于贪婪解码的好处:
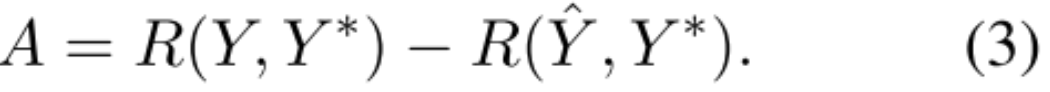
与基线方法相比,这种比较突出了探索性行动在改善事件提取结果方面的有效性。
2.3 EventRL中的稳定化策略
Teacher-Force Threshold:阈值策略被用来减轻政策退化,特别是在某些样本上模型的性能明显低于标准的情况下。该策略涉及为模型的性能得分(通常使用贪婪解码的结果得分来测量)设置阈值。当模型在给定样本上的表现福尔斯τ时,学习过程被调整为“教师强迫”模式。在这种模式下,使用黄金事件Y_n而不是其自身生成的输出Y来临时引导模型,从而有效地提供更可靠的学习信号。
Advantage Clipping:EventRL中的优势裁剪是专门为解决灾难性遗忘的挑战而设计的,即模型在先前学习的任务上的性能随着关注新任务而恶化。当某些样本的优势值太低时,通常会出现这个问题,导致可忽略的更新,并导致模型在训练过程中忽略这些样本。该策略涉及为优势值设置下限。该下限确保每个样本,无论其初始优势值如何,都会对学习过程产生最小的影响阈值。优势裁剪过程被重新表述为仅关注下限。
![]()
3.实验结果
3.1 数据集和数据拆分策略
为了全面评估模型的性能,在ACE05数据集上进行了实验。这使能够测试模型在有效提取 可见 和 不可见 事件类型方面的能力。ACE05数据集包含33个事件类型,其中训练集、验证集和 held-in 测试集选择了7种事件类型。然后,选择了19种不同的事件类型来形成 held-out 测试集(不可见的事件类型),以确保对模型的泛化能力进行严格的评估。为了保持一个平衡的数据集,在训练集中为每个事件类型采样了50个实例,在验证集中为每个事件类型采样了10个实例,在held-in 和 held-out 测试集中为每个事件类型采样了20个实例。该策略确保模型在不同条件下进行训练和评估,从而全面了解其在不同事件类型中的性能。
3.2 对比方法
(1) Few-Shot Prompting(FSP):在GPT-4的特定版本上实现,该方法依赖于模型的内在功能,在任务执行之前提供一组示例。
(2) 监督微调(SFT):在特定数据集上直接训练模型,并通过NLL损失提供反馈。SFT实验主要在LLaMa变体 和 CodeLLaMa模型(7B、13B 和 34B)上进行。
(3) EventRL 与 提出的奖励函数:提出的EventRL框架在三种不同的配置中进行了评估,每种配置都使用了不同的奖励函数,旨在优化模型在事件提取中的性能:EventRL(Arg-F1)使用Argument-F1作为反馈,EventRL(Avg-F1)旨在平衡 Trigger-F1 和 Argument-F1,EventRL(Avg-F1)寻求最大化 Trigger-F1和 Argument-F1 的乘积。这些变体在LLaMa上进行了测试 和 CodeLLaMa模型,以研究其在事件提取中的有效性。。
3.3 结果
下表给出了不同LLM的综合性能比较,包括GPT4、LLaMa和CodeLLaMa变体,以及各种训练方法,如:SFT、FSP 和 提出的EventRL方法。该表报告了Trigger-F1 和 Argument-F1 及其平均值,其计算为每种方法的相应 Trigger-F1 和 Argument-F1 的平均值,包括训练期间观察到的事件(保持测试)和新的未观察事件类型(保持测试)。研究结果表明,EventRL在事件提取方面优于SFT和FSP方法。具体来说,当比较AVG评分时,EventRL表现出更好的整体性能。例如,在Held-in测试中,使用LLaMa-7B模型的EventRL(EST-F1)方法获得了60.72的AVG分数,超过了SFT方法的56.03。类似地,在保持测试中,具有LLaMa-7B的EventRL(EST-F1)达到40.84的AVG分数,与SFT的37.35相比。这表明EventRL在准确识别事件结构和预测事件方面的有效性。
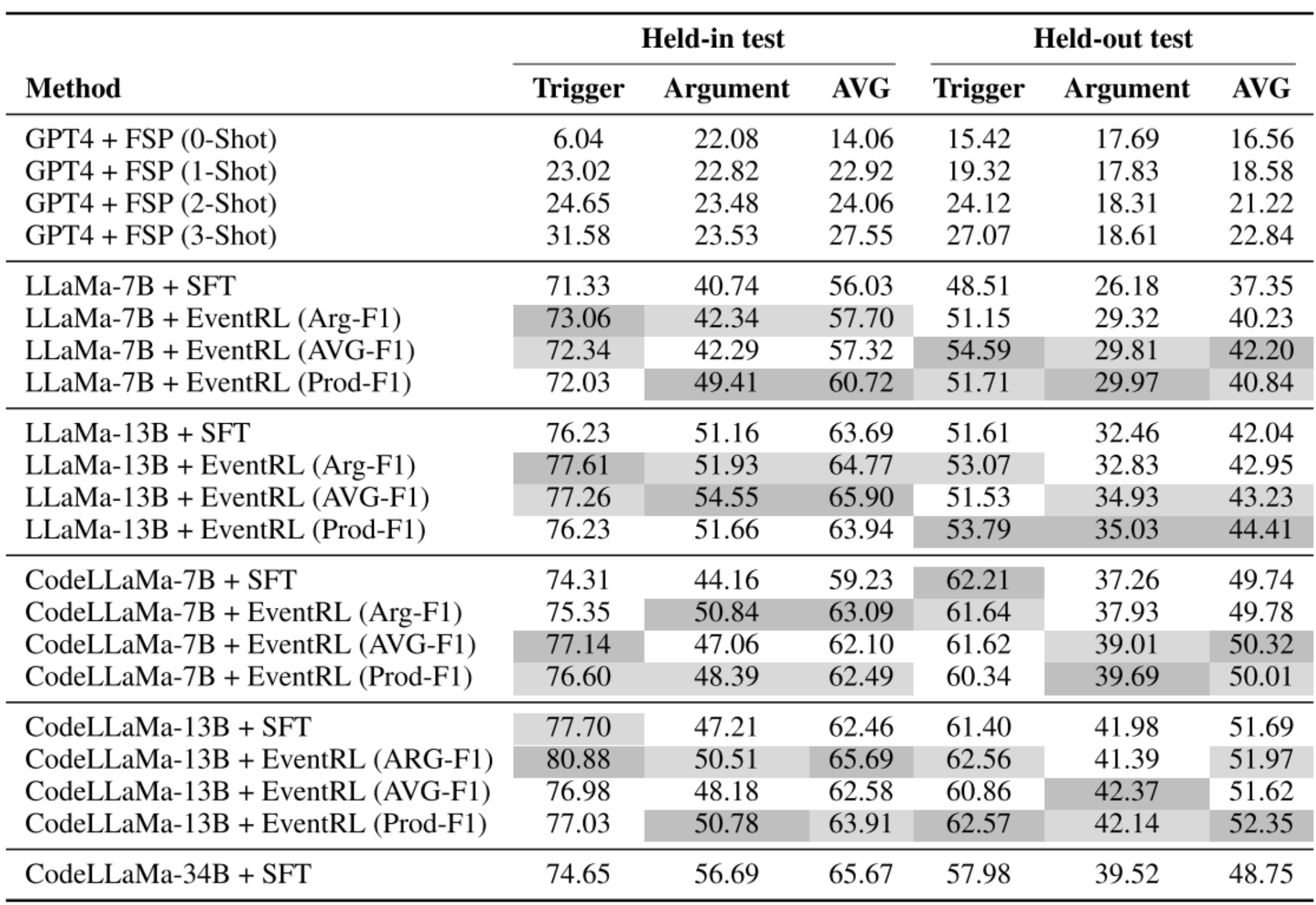
此外,EventRL显示出卓越的泛化能力,特别是在处理不可见的事件类型方面。使用LLaMa-13 B模型,EventRL(EST-F1)在Heldout测试中的平均值为44.41,优于SFT方法的42.04。这些结果突出了EventRL的鲁棒性及其比其他方法更好地适应新的、不可见的事件类型的能力。EventRL的成功可以归功于其专门的奖励函数(Arg-F1,AVG-F1和AVG-F1),这些函数提供了有针对性的反馈,用于改进模型对事件的理解和提取。这种量身定制的方法确保EventRL不仅在从文本中提取事件方面表现出色,而且还能有效地适应不同的模型大小和架构,包括LLaMa和CodeLLaMa变体。
奖励函数的选择显著影响LLM在事件提取中的性能,AVG-F1和AVG-F1奖励表现出明显的优势。对于LLaMa-7 B模型,在Held-in测试和Held-out测试中,EST-F1奖励函数产生了最好的AVG得分,分别达到60.72和40.84。这表明,通过EST-F1奖励关注触发和论点表现的相互依赖性,增强了模型准确提取事件的整体能力。在较大的LLaMa-13 B模型的情况下,AVG-F1奖励功能在保持测试中获得了65.90的AVG分数,而AVG-F1功能在保持测试中表现出色,AVG分数为44.41。这一性能趋势也反映在CodeLLaMa车型上,在CodeLLaMa-13 B车型的测试中,F1-F1奖励再次证明了其有效性,特别是达到了52.35的平均分数。这些结果强调了仔细选择奖励函数以优化LLM的事件提取能力的重要性,事实证明,BMPF 1和AVG-F1奖励在促进对文本中事件的更深入理解和提取方面特别有益。
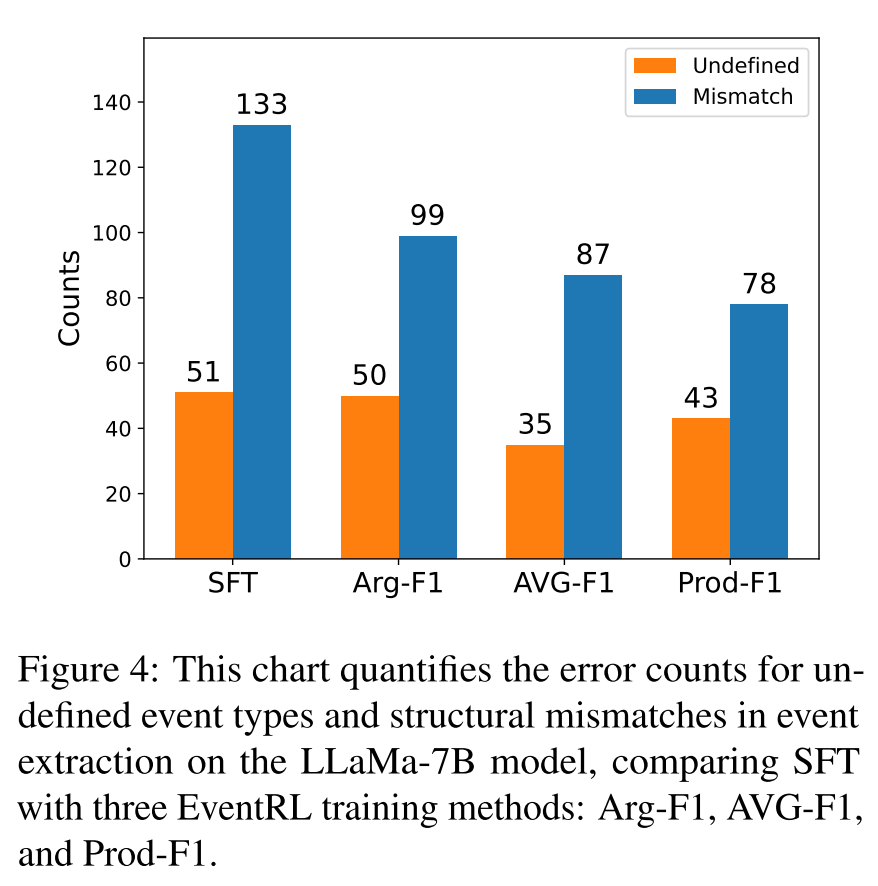
上图给出了在LLaMa7B模型上使用不同训练方法时事件提取中的错误类型的比较分析。SFT导致未定义事件类型错误的发生率非常高,总计133次,结构不匹配错误的发生率为51次。相比之下,EventRL(Arg-F1)将“未定义”错误减少到99个,将“不匹配”错误略微减少到50个。使用EventRL(AVG-F1)方法可以观察到更显著的改进,它将“未定义”错误减少到87个,将“不匹配”错误减少到最低计数35个,这表明在错误抑制方面取得了更好的平衡。EventRL(Prod-F1)也显示出改进,将“未定义”错误减少到78个,将“不匹配”错误减少到43个,尽管不如AVG-F1有效。这些数字突显了EventRL训练方法在减少事件提取的大型语言模型训练中的错误方面的有效性。
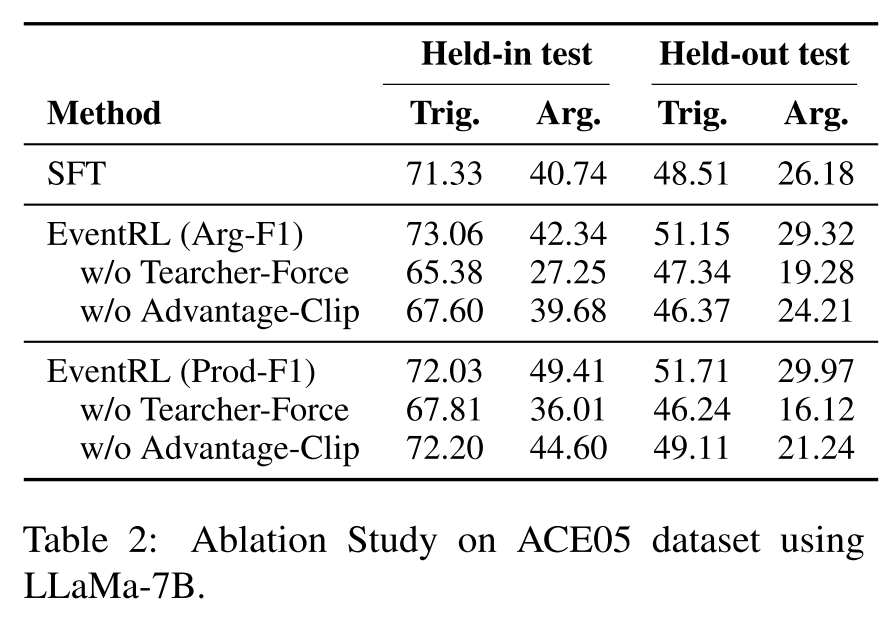
3.4 消融实验
4.总结
在这项工作中,证明了EventRL,一种强化学习方法,显着提高了LLM在事件提取中的性能。通过专注于结果监督和利用专门的奖励功能,EventRL有效地解决了事件提取中的指令遵循和幻觉的挑战,从而实现更准确和可靠的事件提取。该方法的成功是显而易见的,它的上级性能跨越各种模型的大小和架构,特别是在处理新的事件类型。还强调了选择适当的奖励函数的重要性以及代码数据增强对事件提取能力的积极影响。此外,研究结果表明,虽然增加模型规模可以提高性能,但需要平衡这一点与泛化能力,以避免过度拟合。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)