测试最终章:让大模型自动测试,让大模型去点点点,broser-use
大家都知道自动化测试,无论是selenium、playwright,还是其他,都是通过控制页面元素,比如css、xpath等来实现代码去自动点点点。
大模型出来之后,可以实现让大模型去写自动化测试代码,方便了很多。
那能不能不写代码,直接让大模型像人一样去点点点呢?
可以的!
但提前说好,现阶段实战的话,肯定是不如人那么好,但可以让它去测一下简单的功能,也省不少事。
一、安装
我用的是browse-use,下面说一下保姆级安装过程
步骤 1:安装 Python 3.11+(如未安装)
首先检查你的 Python 版本:
bash
python --version # 应该显示 Python 3.11.x 或更高
如果版本低于 3.11,请去 Python 官网下载安装包,安装时务必勾选 “Add Python to PATH”。
步骤 2:新建项目并安装 uv
uv是比pip好的一种安装工具
bash
创建并进入项目目录
mkdir browser-use-demo && cd browser-use-demo
安装 uv(推荐的新型 Python 包管理器,速度比 pip 快 10-100 倍)
pip install uv
为什么推荐 uv?因为 Browser Use 官方文档明确推荐使用 uv 进行安装和环境管理,两条官方指引的快速安装路径都基于 uv 实现。
步骤 3:通过 uv 创建虚拟环境
bash
创建 Python 3.11+ 虚拟环境
uv venv --python 3.11
#激活虚拟环境(往下看,根据你的系统选择)
macOS / Linux:
bash
source .venv/bin/activate
Windows:
bash
.venv\Scripts\activate
激活成功后,终端行首会显示 (.venv) 字样。
步骤 4:安装 Browser Use(主流程)
bash
安装核心包(稳定版)
uv pip install browser-use
#安装 Playwright 浏览器驱动
uv pip install playwright
#安装 Chromium 浏览器(这一步需要联网,大约下载 300MB)
安装这个时,因为源默认是国外的,所以能翻墙的就翻墙,不能的多试几次,我就是多试了几次成功的。当然也可以换成国内的源,但是我装的时候,上一步安装的browser-use是组新版本,国内源还没有,所以只能用默认源。
playwright install chromium
Linux 用户建议执行 playwright install --with-deps,会自动安装 Chromium 依赖的系统级库。
如果想一次性安装所有可选功能(如视频录制、CLI 终端界面、云服务集成等),可以改为:
bash
uv pip install "browser-use[all]"
可选功能分组参考官方文档说明。这一步我没安装。
步骤 5:设置 API Key
Browser Use 本身是开源免费的,但调用 AI 模型需要 API Key。在项目根目录创建 .env 文件:
bash
创建 .env 文件(macOS/Linux)
touch .env
或用记事本/VS Code 直接创建 .env 文件
在 .env 里写入你的 API Key(任选一种即可):
我用的:
# 指定模型为兼容 OpenAI 的模型
OPENAI_MODEL="qwen3.5-27b"
# 指定自定义的 API 地址 (这里以阿里云百炼平台为例)
OPENAI_BASE_URL="https://dashscope.aliyuncs.com/compatible-mode/v1"
# 填写你在阿里云百炼平台获取的 API Key
OPENAI_API_KEY="sk-XXXXXX3"
方案 A:DeepSeek(国内可用,价格实惠,强烈推荐)
text
DEEPSEEK_API_KEY=sk-xxxxxx你的密钥
方案 B:OpenAI
text
OPENAI_API_KEY=sk-xxxxxx你的密钥
方案 C:Browser Use Cloud(官方托管模式,附带 Stealth 浏览器)
text
BROWSER_USE_API_KEY=your-cloud-api-key
✅ 一份完整的 .env 文件可配置多个 Key,Browser Use 会自动识别。
五、验证安装(Hello World)
确认环境无误后,创建第一个脚本 hello.py:
这个脚本我没用到,你们自己试试,记得改成可用的模型。
python
import asyncio
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from browser_use import Agent
load_dotenv()
async def main():
# 初始化 LLM(以 OpenAI 为例)
llm = ChatOpenAI(model="gpt-4o")
# 创建 Agent
agent = Agent(
task="打开 GitHub,找到 browser-use/browser-use 仓库,告诉我 star 数量",
llm=llm,
)
# 运行任务(max_steps 控制最大执行步骤数)
await agent.run(max_steps=15)
if __name__ == "__main__":
asyncio.run(main())
运行脚本:
bash
python hello.py
如果一切正常,你会看到 Agent 自动打开浏览器、搜索 GitHub、进入项目页面、读取数据,最后在终端输出 star 数量。
二、使用
让大模型写了个脚本,你们用的话,记得用自己配置的模型,从上述中.env读取的
import asyncio
import os
from dotenv import load_dotenv
# 使用 browser-use 官方封装的 ChatOpenAI 类
from browser_use.llm import ChatOpenAI
from browser_use import Agent, BrowserProfile, BrowserSession
load_dotenv()
async def main():
# 1. 从环境变量读取 Qwen 配置,初始化 browser-use 的 LLM
llm = ChatOpenAI(
model=os.getenv("OPENAI_MODEL", "qwen3.5-27b"),
base_url=os.getenv("OPENAI_BASE_URL", "https://dashscope.aliyuncs.com/compatible-mode/v1"),
api_key=os.getenv("OPENAI_API_KEY"),
temperature=0.7,
)
# 2. 配置浏览器(显示窗口,方便观察)
browser_profile = BrowserProfile(headless=False)
browser_session = BrowserSession(browser_profile=browser_profile)
# 3. 创建 Agent
agent = Agent(
task="""
1. 访问www.mooctest.net
2. 测试登录功能,这是正确的用户名和密码:testuser\12345tttt@11
3。如果有bug,整理成表格保存到我的电脑桌面
""",
llm=llm,
browser_session=browser_session,
use_vision=True,
)
# 4. 执行任务
result = await agent.run(max_steps=25)
print("抓取结果:")
print(result)
if __name__ == "__main__":
asyncio.run(main())
如下图,启动后,大模型会自己打开浏览器,打开网站,识别哪些是输入账号的,哪些是输入密码的,哪些是登录按钮,还可以要求他把发现的bug输出出来。还是有一定的作用的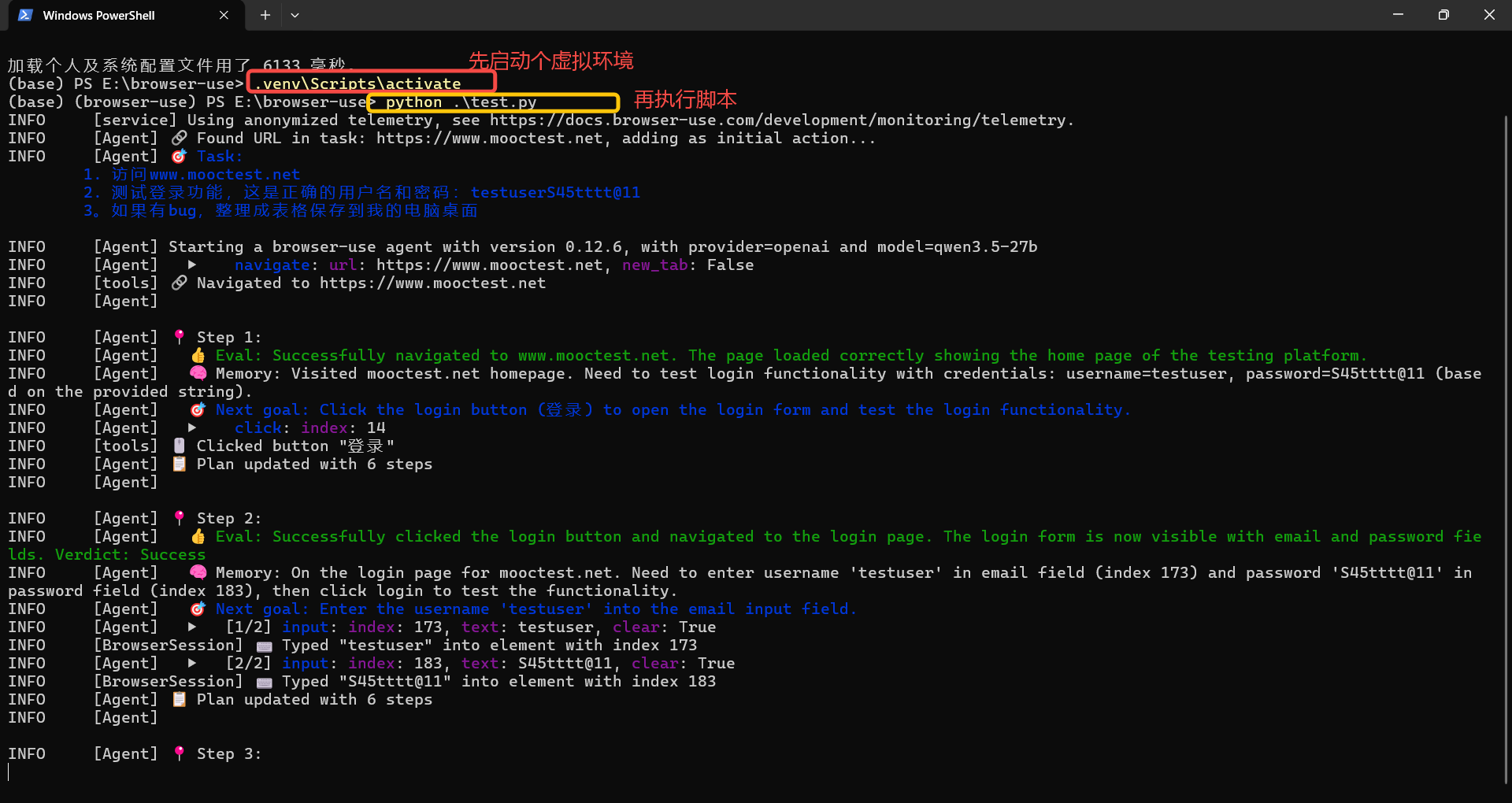

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)