每周技术加速器:UltraRAG:突破传统RAG架构的创新与实践
欢迎来到我们的 「每周技术加速器」 专栏!
每周五,我们都会围绕一个前沿技术主题,展开一场深度的内部技术分享会。不仅是为了团队内部的碰撞与成长,也希望通过这样的形式,将我们的思考与实践记录、沉淀、分享给更多同行者。
本周,我们探讨的主题是:基于 Mcp 的 Rag 架构革新:ultra Rag 的实践与思考
本次技术分享会围绕 UltraRAG 展开讨论。UltraRAG 并非在“生成效果”层面进行局部优化,而是试图回答一个更上层、更长期的问题:
RAG 是否可以像分布式系统一样,被清晰地分层、标准化和模块化,从而具备可演进性?UltraRAG 给出的答案是肯定的。
从“能用的 RAG”到“架构级 RAG”
在大模型应用逐步走向生产化的今天,RAG(Retrieval‑Augmented Generation)已经不再是一个“是否需要”的问题,而是一个“如何设计、如何演进、如何规模化”的架构问题。
许多团队已经将 RAG 成功落地,但在进入真实业务和长期演进阶段后,往往会遇到一系列更本质的困惑:
●为什么系统功能不断叠加,却越来越难以修改和演进?
●为什么一次简单的检索或生成策略调整,都会牵动大量代码?
●为什么 RAG 难以像数据库、消息队列那样,沉淀为稳定、可复用的基础设施?
这些问题的根源,并不在模型效果本身,而在于RAG 的架构层次是否成立。
本次技术分享会围绕 UltraRAG 展开讨论。UltraRAG 并非在“生成效果”层面进行局部优化,而是试图回答一个更上层、更长期的问题:
RAG 是否可以像分布式系统一样,被清晰地分层、标准化和模块化,从而具备可演进性?
UltraRAG 给出的答案是肯定的。
作为首个基于 MCP(Model Context Protocol)的模块化 RAG 框架,UltraRAG 尝试通过协议化接口、分层架构与配置驱动机制,将 RAG 从“应用代码的一部分”,提升为“可长期演进的系统架构”。
在进入具体技术细节之前,先给出贯穿全文的三条核心架构判断:
协议决定架构上限
配置是系统的控制面
RAG 正在走向工具化与实时化的基础设施阶段
从传统 RAG 说起:清晰流程下的结构性困境
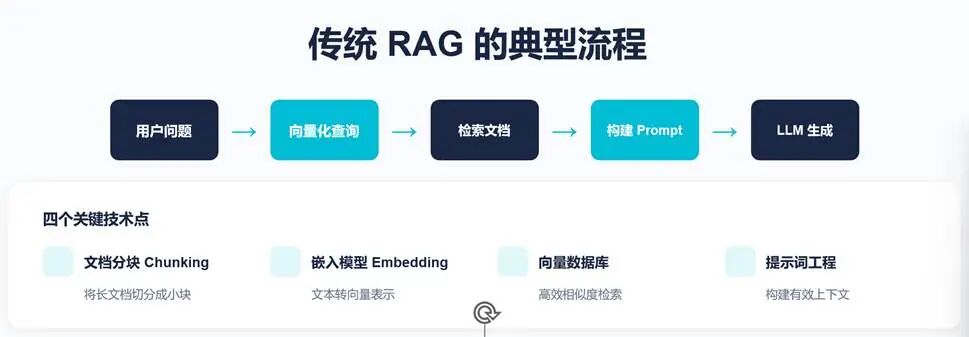
1. 传统 RAG 的基本范式
从流程上看,传统 RAG 的整体逻辑非常清晰:
1.用户提出问题
2.问题向量化(Embedding)
3.向量数据库相似度检索
4.构建 Prompt
5.大语言模型生成答案
在这一过程中,通常涉及四个关键技术模块:
●文档分块(Chunking):将长文档切分为可检索的最小单元
●嵌入模型(Embedding):将文本映射到向量空间
●向量数据库(Vector DB):进行高效相似度搜索
●提示词工程(Prompt Engineering):组织上下文以引导生成
从“白板设计”的角度看,这一技术路径并不复杂。但在工程实践中,问题往往从这里开始显现。
2. 传统 RAG 框架的五大典型问题
在大量工程实践中,传统 RAG 框架逐渐暴露出一系列结构性问题,可以归纳为以下五个方面。
(1)组件强耦合,开发复杂度高
以 LangChain 等框架为代表,检索器、生成模型与业务逻辑往往在代码中直接绑定。一旦需要更换检索策略或模型后端,通常就需要修改核心代码。
其根本原因在于:缺乏统一的抽象层,组件之间高度耦合。
(2)配置分散,难以统一管理
模型参数、检索参数、Prompt 模板往往散落在不同代码位置,缺乏声明式配置机制,直接导致:
●参数不可追溯
●实验难以复现
●配置无法版本化管理
(3)调试困难,缺乏可观测性
在多数传统框架中,RAG 更像一个“黑箱”:
●实际检索到了哪些文档?
●为什么选择这些内容?
●最终传入模型的 Prompt 具体是什么形态?
这些中间状态往往缺乏系统性的记录与可视化手段。
(4)扩展性受限
新增功能或能力通常意味着:
修改框架核心代码
这种非插件式架构,使得框架扩展成本高、生态难以形成。
(5)多模态支持薄弱
多数 RAG 框架在设计之初仅面向文本场景,对于图像、表格等复杂模态支持不足,往往需要通过“拼凑式”的方式进行补偿。
3. 核心矛盾的本质
上述问题虽然表现各异,但本质高度一致:
现有 RAG 框架大多是代码驱动、组件紧耦合的系统,缺乏统一协议与声明式抽象层。
这也自然引出了一个关键问题:
是否可以构建一个 低代码、模块化、易扩展、可复用 的 RAG 架构?
UltraRAG 正是对这一问题的系统性回应。
UltraRAG:以配置与协议重构 RAG 架构
1. UltraRAG 的定位
UltraRAG 是首个基于 MCP 架构的模块化 RAG 框架。其目标并非提供更多内置能力,而是重新定义 RAG 系统的组织方式:
●使用 YAML 配置 描述 RAG Pipeline
●使用 标准协议 连接检索、生成与工具
●使用 模块化设计 实现组件解耦
可以将其核心理念概括为一句话:
用配置描述系统行为,用协议连接系统能力。
2. UltraRAG 的核心特性
UltraRAG 具备以下五个显著特性:
●低代码:核心流程通过 YAML 声明完成,显著降低工程复杂度
●模块化:Retriever、Generator、Parser 等组件完全解耦
●多模态原生支持:文本、图像、表格统一建模与处理
●插件式扩展:新增能力无需修改框架核心代码
●标准化接口:基于 MCP 协议,实现工具级互操作
3. 从“代码耦合”到“配置解耦”
在传统 RAG 模式下:
●更换 Retriever 通常需要修改代码
●参数调优往往需要反复阅读与调整实现逻辑
而在 UltraRAG 中:
●Retriever 与 Generator 均通过配置独立声明
●后端类型、模型选择与超参数一目了然
●配置文件可进行版本管理、复用与对比
在这一模式下,配置本身即系统行为的完整描述。
UltraRAG 的关键技术:MCP 与三层架构
1. MCP:架构级协议,而非性能优化手段
MCP(Model Context Protocol)的核心目标,并非追求单点性能提升,而是实现:标准化、解耦与互操作
其作用可以类比 HTTP 在 Web 体系中的地位。
MCP 主要带来三方面价值:
●工具解耦:各类 Server 可独立运行、独立演进
●统一接口:基于 JSON-RPC,接入与集成成本极低
●插件化扩展:新增工具仅需实现 MCP 接口
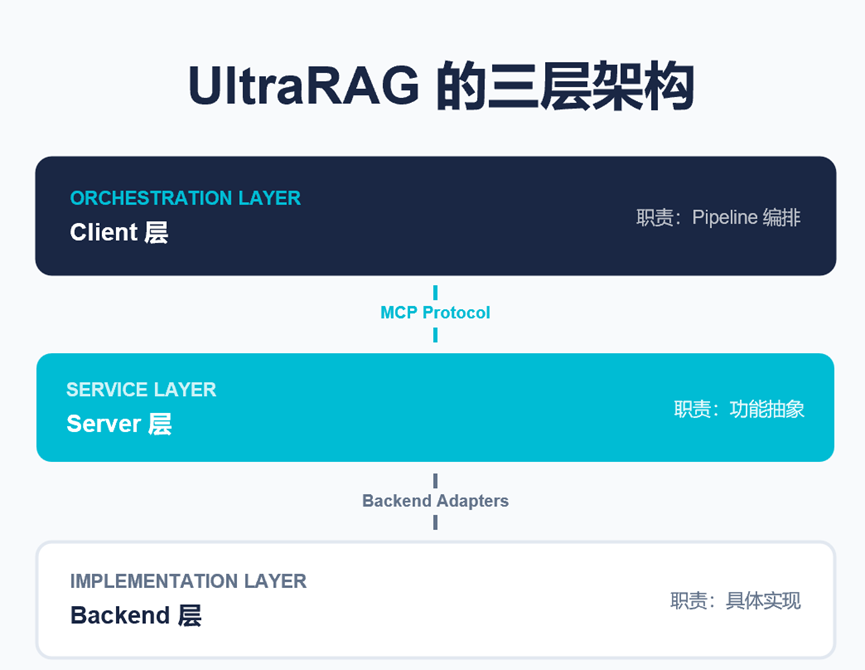
2. UltraRAG 的三层架构设计
基于 MCP,UltraRAG 构建了清晰的三层体系结构:
●Client 层:负责读取 YAML 配置并编排 Pipeline
●Server 层:通过 MCP 暴露标准化能力接口
●Backend 层:具体实现(如 FAISS、vLLM、MinerU 等)
这一设计的核心原则在于:
上层仅依赖接口,而不依赖具体实现。
各组件可像积木一样被自由替换与升级。
3. 配置驱动的系统价值
配置驱动并不只是减少代码量,而是带来三种系统级能力:
-
可追溯性:配置即系统文档
-
可复现性:一个 YAML 对应一次完整实验
-
可版本化:天然适配 Git 等版本管理工具
同时,YAML 的模板与继承机制,使得配置复用与组合成本极低。
4. 多模态能力与 MinerU 的集成
UltraRAG 的多模态能力并非后期补丁,而是源于架构层面的原生设计。
通过与 MinerU 的深度集成,系统能够:
-
解析文档中的图像、表格与公式
-
将表格转为 HTML、公式转为 LaTeX
-
支持 100+ 语言的 OCR
-
自动识别文档阅读顺序
这使 UltraRAG 在处理论文、财报与技术文档等复杂场景时具备显著优势。
技术启示与 RAG 的演进方向
1. 三条关键技术启示
(1)协议优于框架
长期来看,定义标准协议比构建封闭框架更具生命力。
(2)配置优于代码,但需明确边界
通用、确定性的系统行为适合配置化,特殊逻辑仍需通过代码实现。
(3)可观测性是生产级 RAG 的关键能力
RAG 系统不仅要“能跑”,还需要“可解释、可调试、可优化”。
2. 从离线索引到 MCP-based 实时 RAG
RAG 技术正经历从离线索引向实时工具调用的重要转变。
传统 RAG 模式依赖预构建向量索引,存在知识更新滞后与维护成本高的问题。
基于 MCP 的实时 RAG 模式中,模型可以直接通过工具调用实时文档服务:
-
无需预建索引
-
知识始终保持最新
-
维护成本显著降低
在这一趋势下,文档网站本身将逐步演进为 MCP Server。
3. 面向未来的三个发展趋势
-
Agent-based RAG:由 Agent 动态决策何时、如何检索
-
知识图谱融合:结合向量语义能力与关系推理能力
-
个性化 RAG:根据用户行为动态调整检索与生成策略
这些趋势共同指向一个方向:
RAG 正在从静态系统,演进为动态、智能、可演进的知识基础设施。
Demo演示
UR-v2 的使用流程主要包括以下三个阶段:
-
编写 Pipeline 配置文件
-
编译 Pipeline 并调整参数
-
运行 Pipeline
此外,还可以通过可视化工具对运行结果进行分析与评估。
数据:使用 ultrarag 提供的10条样例数据

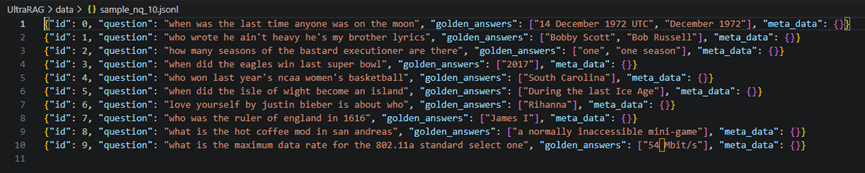
嵌入编码:MiniCPM-Embedding-Light
生成答案模型: Qwen3-8B
最终准确率:10%
Step 1:编写 Pipeline 配置文件
在examples文件夹中创建并编写 Pipeline 配置文件:
-
servers: benchmark:servers/benchmark retriever:servers/retriever prompt:servers/prompt generation:servers/generation evaluation:servers/evaluation custom:servers/custom pipeline: -benchmark.get_data -retriever.retriever_init -retriever.retriever_embed -retriever.retriever_index -retriever.retriever_search -generation.generation_init -prompt.qa_rag_boxed -generation.generate -custom.output_extract_from_boxed -evaluation.evaluate
UR-v2 的 Pipeline 配置文件需要包含以下两个部分:
-
servers:声明当前流程所依赖的各个模块(Server)。例如,检索阶段需要使用 retriever Server。
-
pipeline:定义各 Server 中功能函数(Tool)的调用顺序。本示例展示了从数据加载、检索编码与索引构建,到生成与评测的完整流程。
Step 2:编译 Pipeline 并调整参数
在运行代码前,首先需要配置运行所需的参数。UR-v2 提供了快捷的 build 指令,可自动生成当前 Pipeline 所依赖的完整参数文件。 系统会读取各个 Server 的 parameter.yaml 文件,解析本次流程中涉及的全部参数项,并统一汇总生成到一个独立的配置文件中。执行以下命令:
printf("hello world!");执行后,终端将输出如下内容:
系统会在examples/parameters/文件夹下生成对应的参数配置文件。打开文件后,可根据实际情况修改相关参数,例如:
benchmark:
benchmark:
# key_map:定义数据字段的映射关系,将数据集中字段名映射为标准字段
key_map:
gt_ls: golden_answers # 答案字段名
q_ls: question # 问题字段名
limit: -1 # 限制加载样本数量,-1 表示加载全部
name: nq # 数据集名称(如 Natural Questions)
path: data/sample_nq_10.jsonl # 数据文件路径
seed: 42 # 随机种子,保证实验可复现
shuffle: false # 是否打乱样本顺序,false 表示按原顺序加载
custom: {} # 自定义 Server,此处为空(当前函数无参数)
evaluation:
# metrics:指定评测指标,可按需增删
metrics:
- acc # 准确率(Accuracy)
- f1 # F1 值
- em # Exact Match
- coverem # 覆盖率式 Exact Match
- stringem # 字符串级匹配
- rouge-1 # Rouge-1 指标
- rouge-2 # Rouge-2 指标
- rouge-l # Rouge-L 指标
save_path: output/evaluate_results.json # 评测结果保存路径
generation:
backend: vllm # 推理后端,可选 vllm / openai / hf
backend_configs:
hf: # HuggingFace 本地推理配置
batch_size: 8
gpu_ids: 2,3
model_name_or_path: openbmb/MiniCPM4-8B
trust_remote_code: true # 允许加载带自定义代码的模型
openai: # OpenAI API 推理配置
api_key: '' # OpenAI API 密钥
base_delay: 1.0 # 重试间隔时间(秒)
base_url: http://localhost:8000/v1
concurrency: 8 # 并发请求数
model_name: MiniCPM4-8B
retries: 3 # 最大重试次数
vllm: # vLLM 推理引擎配置
dtype: auto # 自动选择精度(如 fp16/bf16)
gpu_ids: 2,3 # 指定 GPU ID
gpu_memory_utilization: 0.9 # GPU 显存利用率上限
model_name_or_path: openbmb/MiniCPM4-8B
model_name_or_path: Qwen/Qwen3-8B
trust_remote_code: true
sampling_params: # 采样参数(影响生成多样性)
chat_template_kwargs:
enable_thinking: false # 是否启用思维链模式
max_tokens: 2048 # 最大生成长度
temperature: 0.7 # 温度系数(越高越随机)
top_p: 0.8 # nucleus sampling 阈值
system_prompt: '' # 系统提示词(可留空)
prompt:
template: prompt/qa_boxed.jinja
template: prompt/qa_rag_boxed.jinja # 使用的 Prompt 模板路径(Jinja 格式)
retriever:
backend: sentence_transformers # 向量化后端,可选 sentence_transformers / infinity / openai
backend_configs:
infinity: # Infinity-Emb 推理配置
bettertransformer: false
device: cuda
model_warmup: false
pooling_method: auto
trust_remote_code: true
openai: # OpenAI Embedding API 配置
api_key: ''
base_url: https://api.openai.com/v1
model_name: text-embedding-3-small
sentence_transformers: # SentenceTransformers 本地配置
device: cuda
sentence_transformers_encode:
encode_chunk_size: 10000 # 每批编码文本数量
normalize_embeddings: false # 是否归一化嵌入向量
psg_prompt_name: document # passage 编码提示词名称
psg_task: null # passage 任务类型
q_prompt_name: query # query 编码提示词名称
q_task: null # query 任务类型
trust_remote_code: true
batch_size: 16 # 向量化批大小
corpus_path: data/corpus_example.jsonl # 语料库路径
embedding_path: embedding/embedding.npy # 向量保存路径
faiss_use_gpu: true # 是否启用 GPU 加速的 Faiss
gpu_ids: 0,1 # 指定 GPU 设备
index_chunk_size: 50000 # 每批构建索引的文档数
index_path: index/index.index # 索引文件保存路径
is_multimodal: false # 是否为多模态检索(图文混合)
model_name_or_path: openbmb/MiniCPM-Embedding-Light
model_name_or_path: Qwen/Qwen3-Embedding-0.6B # 向量化模型路径
overwrite: false # 是否覆盖已有 embedding / index
query_instruction: '' # query 前置指令(可为空)
top_k: 5 # 检索返回的 Top-K 文档数可以根据实际情况修改参数,例如:
-
将 template 调整为RAG模版 prompt/qa_rag_boxed.jinja;
-
替换检索器与生成器的 model_name_or_path 为本地下载的模型路径;
-
若在多 GPU 环境下运行,可修改 gpu_ids 以匹配可用设备
Step 3:运行 Pipeline
当参数配置完成后,即可一键运行完整流程。执行以下命令:
ultrarag run examples/rag_full.yaml系统将依次执行配置文件中定义的各个 Server 与 Tool,并在终端中实时输出运行日志与进度信息:
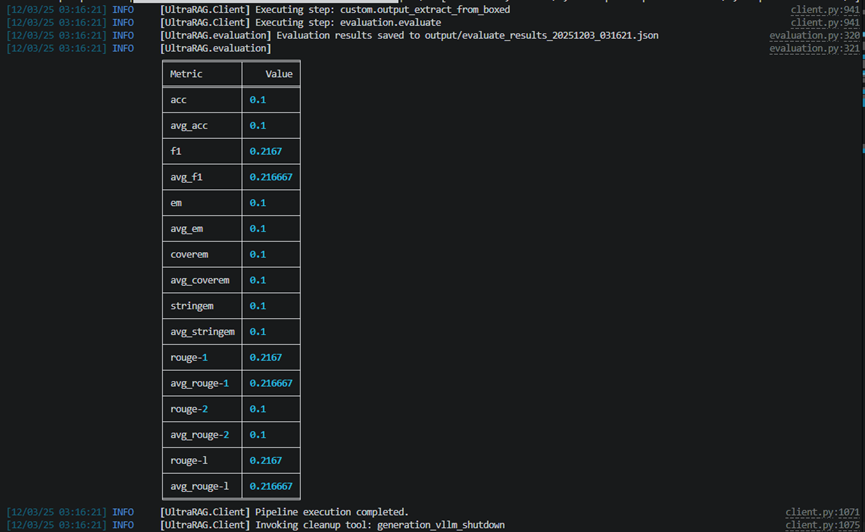
运行结束后,结果(如生成内容、评测报告等)将自动保存在对应的输出路径中,如
/output/memory_nq_demo_rag_20251203_031625.json
可直接用于后续分析与可视化展示
可视化测评
在运行完成 yaml 文件后,系统会在 output 文件夹下自动生成一份 memory 日志文件,例如:
/output/memory_nq_demo_rag_20251203_031625.json 。
只需执行以下命令,即可启动 Case Study 可视化网站
-
python ./script/case_study.py \ --data output/memory_nq_demo_rag_20251203_031625.json \ --host 0.0.0.0 \ --port 8080 \ --title "Case Study Viewer"
可视化测评界面:
包含具体的 RAG 执行步骤,以及各个步骤执行结果
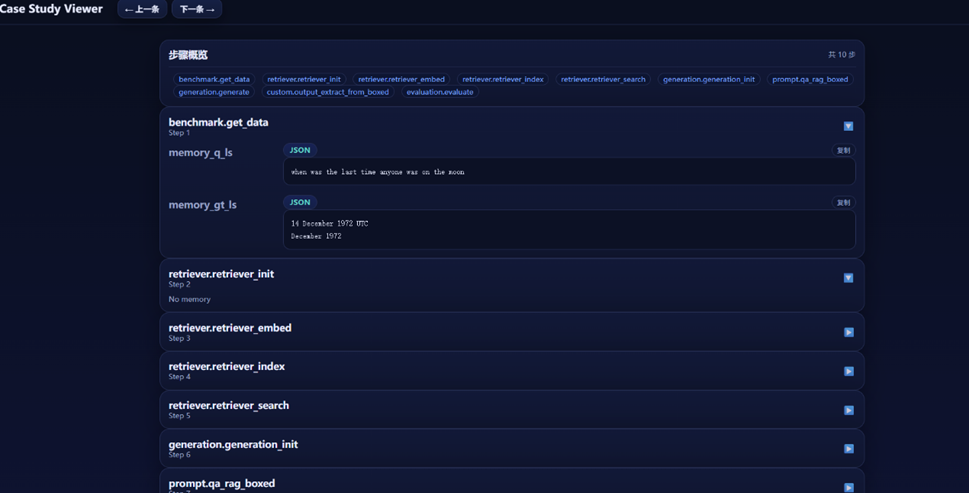
检索回的内容:
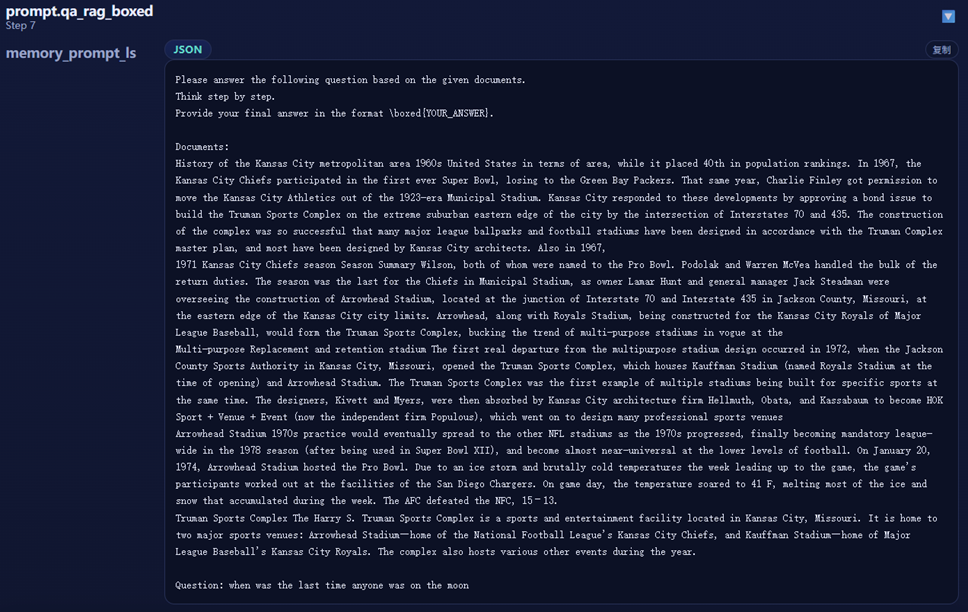
拼接后的prompt:
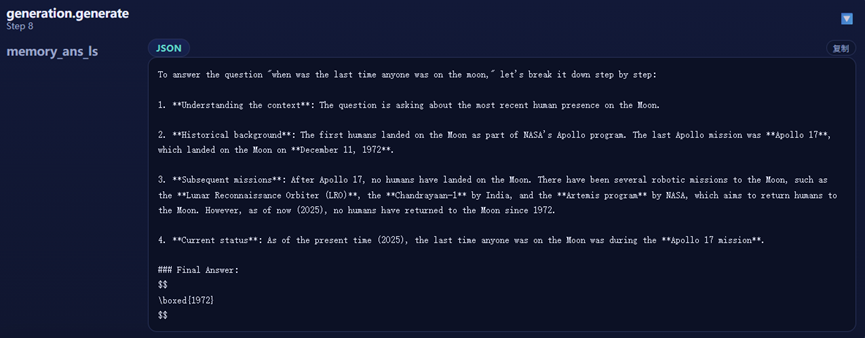
模型输出内容:
结语
UltraRAG 仍处于早期发展阶段,但其所代表的方向已经十分清晰:
-
在架构层面,强调协议化与模块化
-
在工程层面,强调配置驱动与可观测性
-
在系统形态上,走向实时化与工具化
对于正在构建或规划下一代 RAG 系统的团队而言,UltraRAG 与 MCP 所提供的思路,具有重要的参考价值。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)