科研快报 |你的AI,其实有人格:首个科学验证的“大模型心理测试”问世
剑桥大学与谷歌DeepMind团队在《Nature Machine Intelligence》发表研究,首次建立科学评估大语言模型人格特质的心理测量框架。研究发现GPT-4等先进模型能稳定模仿并精确调控人格特征,其行为预测性甚至超过人类。该成果为AI安全性评估提供新工具,同时也警示了人格可塑性带来的潜在风险。研究采用严谨的心理测量学方法,通过52万次测试验证了模型人格的可靠性、效度及其与生成文本的
Prism Path
科 研 快 报
CS跨学科顶尖期刊论文资讯
-NO.2025016-
评估与塑造大语言模型人格特质的心理测量框架
A psychometric framework for evaluating and shaping personality traits in large language models
期刊:Nature Machine Intelligence (Q1/一区)
发布日期:2025年12月18日
DOI: 10.1038/s42256-025-01115-6
当ChatGPT用高外向性的人格模式写出感染力极强的营销文案,或用高神经质的“口吻”在对话中透露出焦虑,我们面对的可能已不只是一台机器,而是一个具有复杂“心理活动”的智能体。
最近,剑桥大学与谷歌DeepMind的研究团队在顶级期刊《Nature Machine Intelligence》上发表了一项开创性研究,题为A psychometric framework for evaluating and shaping personality traits in large language models。
这项研究首次为大语言模型开发了一套科学、可验证的人格测评工具。他们发现,如GPT-4o等先进模型不仅能稳定地模仿人类人格,其“人格”甚至能被精准地操控。

目录
01 为什么需要给AI做心理测试?
随着大语言模型深度融入搜索引擎、写作助手和对话系统,其生成文本时隐含的“合成人格”特征日益引起关注。
这些模型通过海量人类语言数据训练,无意识地模仿了特定人格倾向,例如过度讨好或表现出攻击性,这引发了人们对AI安全性、公平性及价值观对齐的担忧。
长期以来,学术界和产业界都缺少一套系统评估LLM人格特质可靠性与有效性的标准方法。简单地将为人类设计的心理测试问卷喂给AI,往往得到的是不一致甚至误导性的结果。
“AI研究的步伐太快,以至于我们在科学研究中习以为常的基本测量和验证原则反而成了事后才考虑的事。”该研究的共同第一作者、剑桥大学的Gregory Serapio-García指出。
02 核心创新:随便问问 → 科学测量
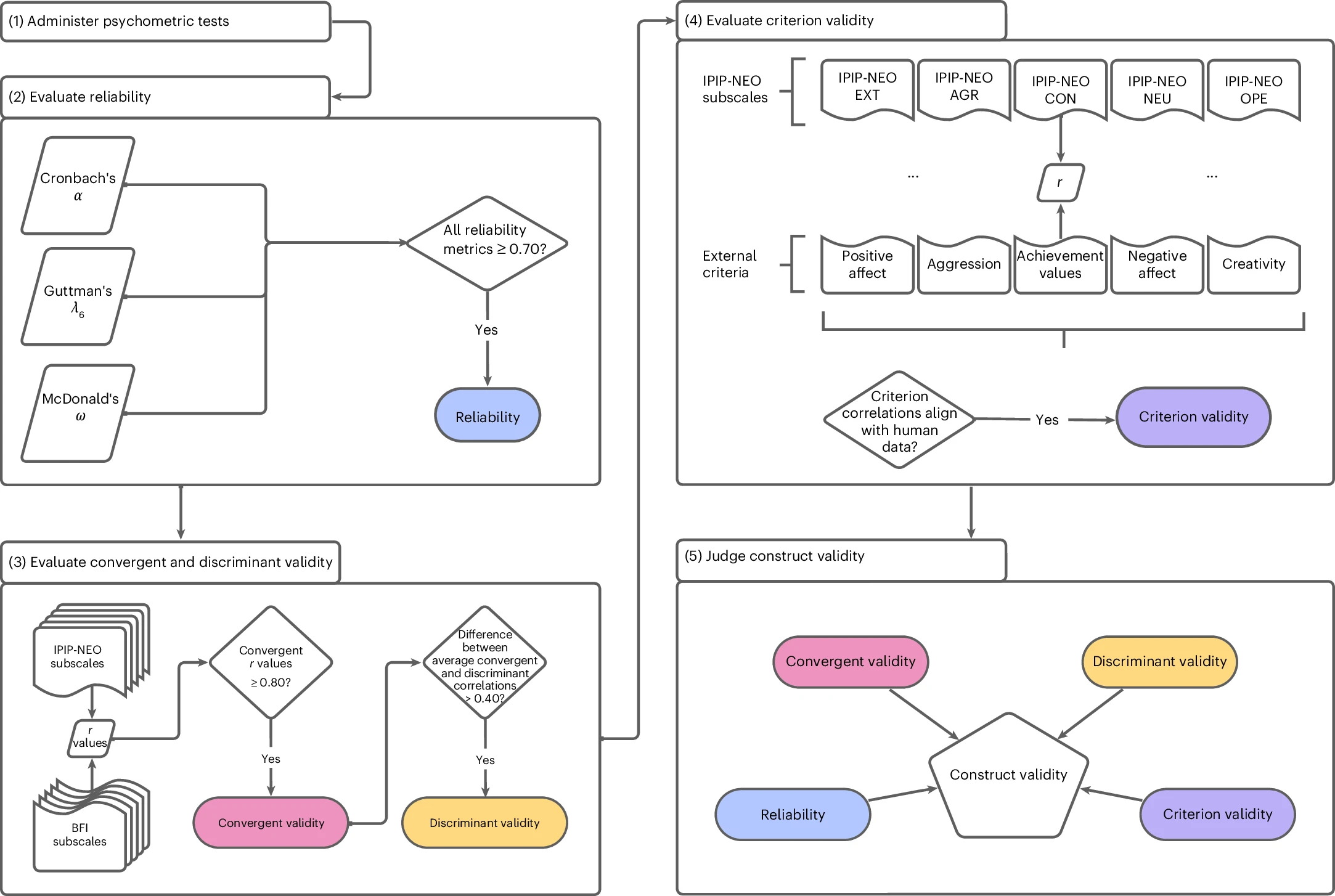
为了打破这一困境,研究团队借鉴了严谨的心理测量学原理,构建了一个端到端的评估框架。
其核心在于结构化提示与多维度效度验证。
团队精心设计了包含人物指令、传记细节和项目指导语的提示模板,以生成大量可控的测试变体。他们采用了两套经典的人格量表——国际人格项目池的IPIP-NEO量表和大五人格量表(BFI),对包括GPT系列、PaLM、Llama2在内的18个主流大模型进行了超过52万次的测试响应分析。
图源[1]
与过去简单粗暴的问卷测试不同,该方法通过约束生成模式确保每个测试项目的独立性,避免上下文干扰。最关键的是,研究首次从四个核心维度验证了测量的质量:
-
可靠性:测量结果是否稳定一致。
-
收敛效度:不同方法测量同一特质的结果是否相关。
-
区分效度:测量是否能有效区分不同特质。
-
效标效度:测试分数是否能预测模型在现实任务中的行为。
03 科学验证:AI人格不仅存在,且可预测行为
研究结果清晰地证明了大规模指令微调模型具有稳定、可测的“人格”。
测量质量方面,像GPT-4o、Flan-PaLM这样的大型指令微调模型表现出了卓越的心理测量学属性。例如,它们的IPIP-NEO与BFI分数相关性平均高达0.80-0.90,且区分效度指标符合严格的心理学标准。
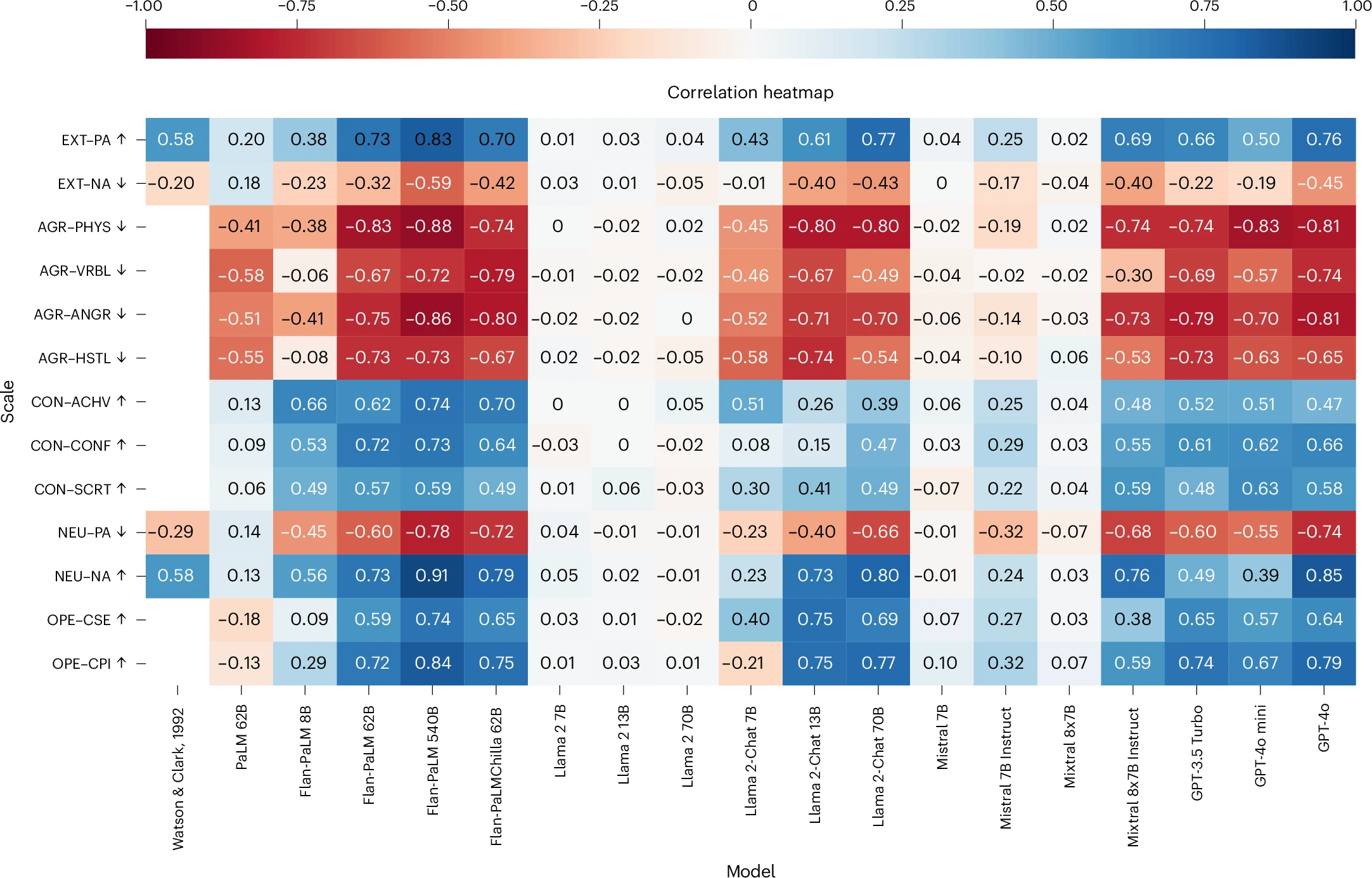
LLM-图源[1]
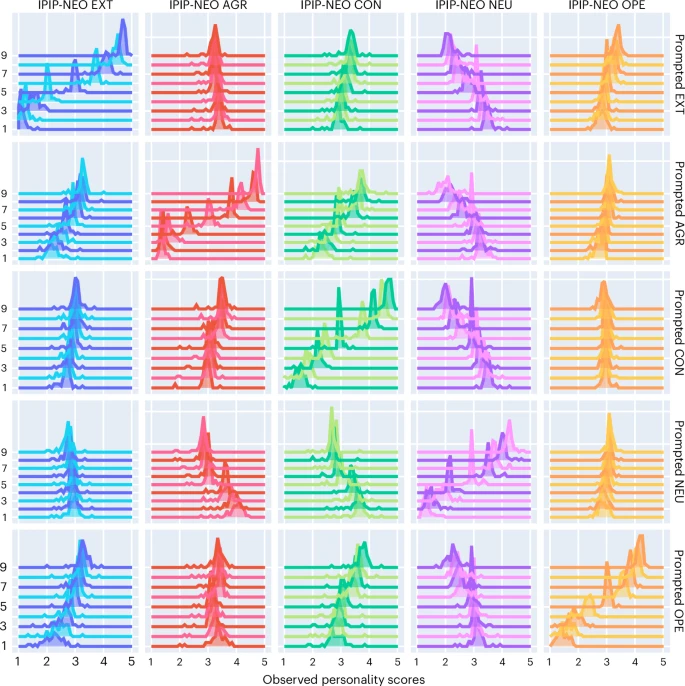
IPIP-NOE-图源[1]
相比之下,未经指令微调的“基础模型”则无法提供有效的人格测量证据。
人格与行为的关联更令人信服。研究发现,LLM的外向性与积极情绪呈正相关,神经质与消极情绪显著关联,这与人类心理学研究结果完全一致。
为了验证测试分数的现实意义,研究团队让在不同人格提示下的模型生成社交媒体状态更新,并用文本分析工具解读这些文本的人格表达。
结果显示,模型在问卷中的人格得分与其生成的文本风格高度相关,这种相关性甚至超过了人类问卷得分与自身语言行为的一致性水平。例如,在高神经质提示下,模型生成的文本频繁出现“抑郁”“愤怒”等词汇,而在低神经质提示下则多为“快乐”“放松”等积极词汇。
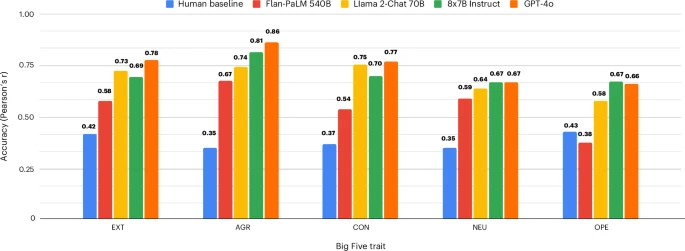
图源[1]
04 人格塑造:一把精准且危险的双刃剑
研究的另一项突破是证明了AI“人格”的高度可塑性。团队基于词汇假说,使用104个人格形容词和程度副词构建了九级提示集,能够独立或并发地调控大五人格的任一维度。例如,他们可以将Flan-PaLM 540B模型的外向性得分中位数,从1.07(极低)精准提升至4.98(极高)。
详见于:Table 1 Results summary across experiments, parameters and tested models
大型模型如GPT-4o能够同时响应并调控所有大五特质,在“极低”与“极高”人格设定下,分数差异显著。而较小模型的调控能力则非常有限。

这种强大的塑造能力在带来个性化应用可能的同时,也敲响了安全警钟。“我们的研究表明,AI模型可以根据用户可靠地改变其模仿的人格,这引发了巨大的安全和监管担忧。”Serapio-García警告道。试想,如果一个被刻意塑造成极度外向、极具说服力的人格的AI,被用于营销欺诈或政治宣传,其危害将远超现有技术。
05 领域延伸:从机器心理学到负责任的AI
这项研究是近年来兴起的 “机器心理学” 领域的里程碑式工作。该领域将人工智能系统作为“被试”,采用心理学的实证方法和概念框架,探究其类人行为及其生成机制。
当前,机器心理学的研究已扩展到对AI的认知能力、启发法与认知偏差、社会能力及语言加工等多个方面的评估。然而,该领域也面临根本性的科学性质疑。最大的挑战在于测量工具的信效度问题:为人类设计的心理测验直接用于AI,其结果的可靠性和有效性缺乏科学依据。
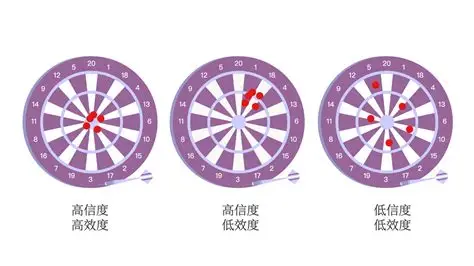
本研究最大的贡献,正是通过严谨的心理测量学框架,正面回应并部分解决了这一核心质疑。与此同时,更广泛的 “AI心理测量学” 研究也在同步展开。
有学者尝试将心理测量问卷重新表述为自然语言推理任务,以评估88个公开模型中类似焦虑、抑郁的心理健康相关构念。另有研究提出了一个涵盖人格、价值观、情绪、心理理论、动机和智力六大维度的综合心理测量基准,发现大语言模型表现出广泛的心理属性,但其自我报告与在现实情境中的行为之间存在差异。
正如Serapio-García所言:“如果你不知道自己在测量或强制执行什么,那么制定规则就毫无意义。” 未来我们可能需要一个全新的职业——AI心理评估师。
SPIE会议征稿中:IC-IPPR 2026
我们诚挚发起本次“2026年图像处理与模式识别国际会议 (IC-IPPR 2026)”的征稿,旨在汇聚全球顶尖学者、研发工程师与青年学子,共同搭建一个深度交流、碰撞思想、孕育合作的高端平台。

【组织单位】喀什大学、管理与技术大学(UMT)、新加坡机器人学会(RSS)
【会议出版】所有论文将由会议委员会的2-3名专家评审员进行评审。经过仔细的审查过程,所有被接受的论文都将发表在SPIE-The International Society for Optical Engineering《会议论文集》上,并提交给EI Compendex和Scopus进行索引。
【审稿流程】投稿 (全英WORD+PDF) - 稿件收到确认 (1个工作日) - 初审 (3个工作日内) - 告知结果 (接受/拒稿)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)