智能体长期记忆的解决方案,不只是知识库(保姆级部署教程及测评)
AI 新闻早知道
大家好,我是船帆,作为一名不懂代码的普通人,我将在这里和大家分享零代码基础如何学习AI,如果你也想学习AI应用搭建,打造个人IP或提升职场竞争力,请关注公众号,获取免费教程。我将和大家共同见证AGI的发展之路。
你开发的 AI Agent 能记住多少轮和用户的对话?
作为一名 AI Agent 开发者,这段时间我不断在折腾同一件事:AI Agent(智能体)到底能不能拥有真正的“长期记忆”?
无论是做客服机器人、代码助手,还是陪伴式助手,我们都会遇到同一个痛点:
LLM(大语言模型)本身是没有记忆的。 其记忆完全依赖当前对话窗口(Context Window)。 一旦关闭对话、Token 超限,之前所有内容全部蒸发。
💡
于是就出现了下面的经典翻车场景:
-
用户:我上次说过我 不吃辣,记得吗?
-
Agent:抱歉,我不记得了,请问您需要什么帮助?
这种“金鱼记忆”不仅让体验断裂,也极大限制了 AI Agent 做长期任务的能力。

🚅
直到最近,我在 GitHub 上看到一个开源项目 —— MemMachine。
项目开源地址:https://github.com/MemMachine/MemMachine
✏️
官方定位是:“AI 代理的持久化记忆层(Persistent Memory Layer)”
我本以为只是换汤不换药的 RAG 变体,没想到接入后 —— 真香。
今天我就带你从 0 到 1 体验一下:如何给 Claude Code + AI Agent 装上 MemMachine 的“长期大脑”。
一、MemMachine 是什么?为什么它比 RAG 更像“大脑”?
简单来说,普通的 RAG(检索增强生成)像是给 AI 配了一本字典,用来查资料;而 MemMachine 是给 AI 装了一个真正的人脑,用来记事情。
这两者的区别,用大白话翻译如下:
1. 为什么“普通 RAG”不算真记性?
普通的 RAG 就像你在搜索引擎里搜关键词。
你问“我上次说了啥?”,它只是去书堆里把包含“上次”这两个字的纸条找出来,它其实并不懂前因后果,只是在翻书。
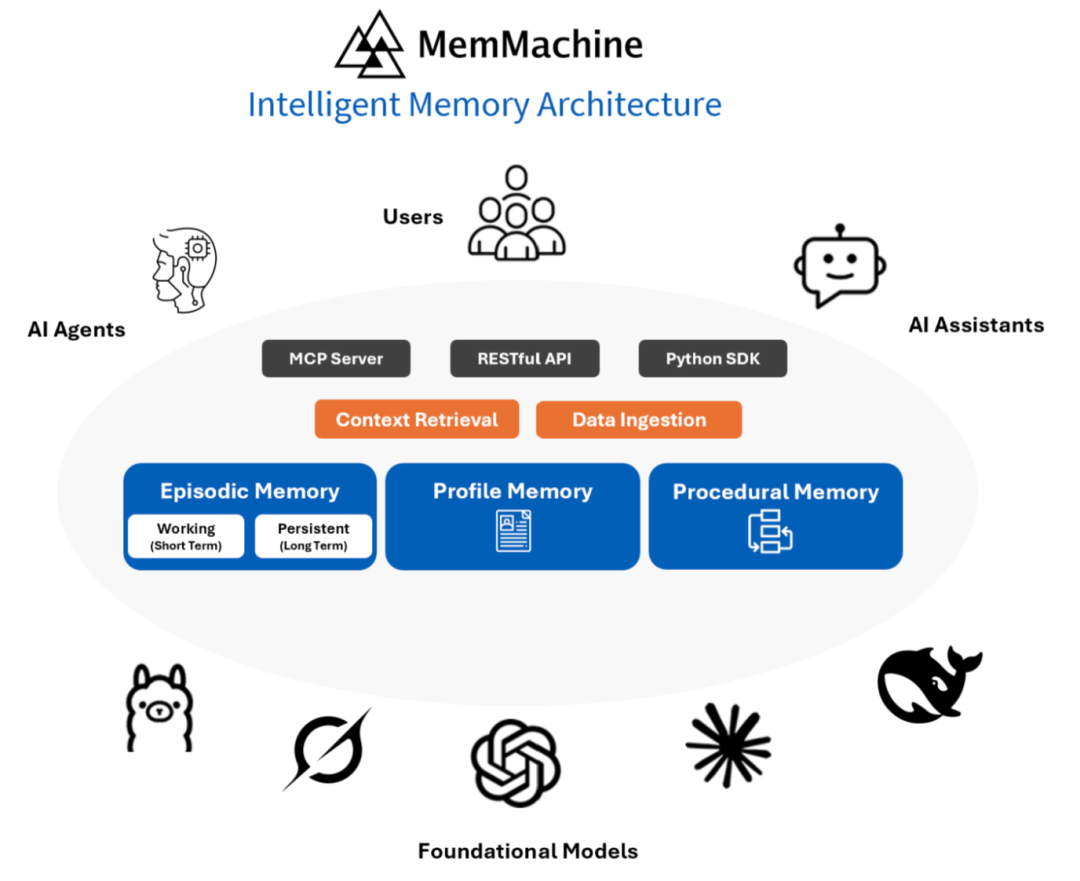
2. MemMachine 的“双层脑子”是什么?
MemMachine 不只是“翻书”,它像人一样有两种记性:
① 剧情脑(情景记忆 Episodic Memory)
-
它记的是“故事线”: 就像你的日记本或朋友圈时间轴。
-
人话解释: 它不是死记硬背一句话,而是记得“因为你昨天感冒了,所以今天想喝热水”。它记得事情的前因后果和时间顺序,这比单纯搜关键词要聪明得多。
② 档案脑(档案记忆 Profile Memory)
-
它记的是“人设卡”: 就像你的身份证 + 体检表 + 喜好清单。
-
人话解释: 只要你提过一次“我不吃香菜”或者“我是程序员”,它就会拿个小本本记在你的专属档案里。无论聊什么话题,这个设定永远生效,不需要你重复说。
3. 最大的杀手锏:记忆是你的“U盘”,不是AI的“大脑”
这是最重要的一点。
-
以前: 你的记忆存在 ChatGPT 里,换了 Claude 就要重新从零开始培养感情。
-
现在(MemMachine): 记忆就像一张手机 SIM 卡或者随身 U盘。
不管你今天把这张卡插在 iPhone (GPT) 上,还是插在安卓 (Claude/Llama) 上:
你的联系人、你的故事、你的喜好,全部都在。
二、从 0 到 1 的实战:安装 MemMachine + 接入 Claude Code
下面我们按照完全可复现的步骤,从部署到落地运行。
2.1 安装 MemMachine(Docker 版)
MemMachine 完全开源,部署方式非常简单。
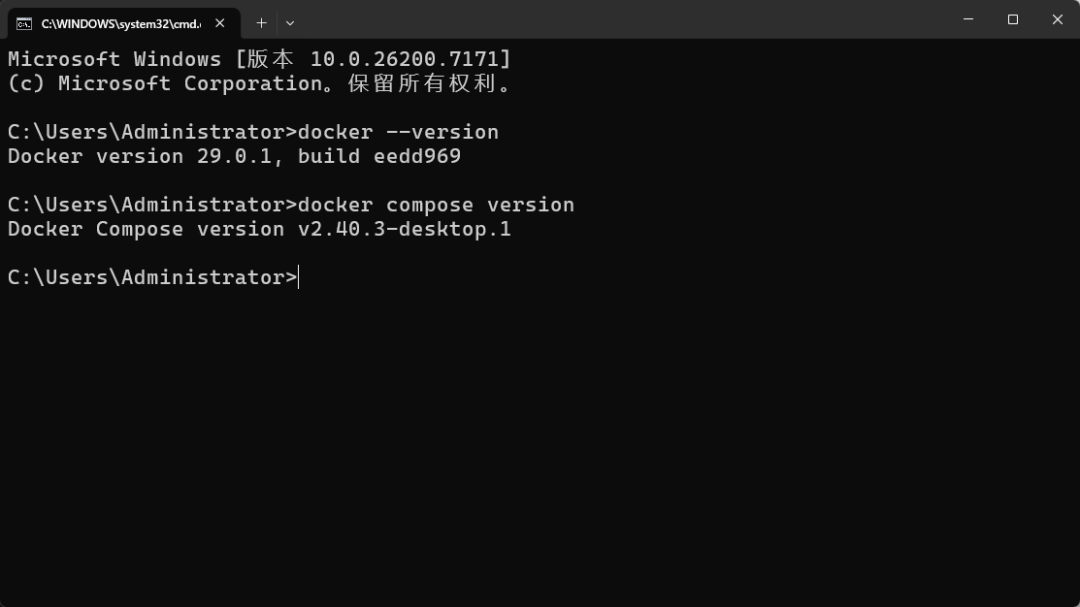
步骤 1:准备 Docker / Docker Compose
确保系统已安装:
docker --versiondocker compose version
步骤 2:本地部署MemMachine
🌰
官方提供了多种方式的部署方法,这里推荐使用Docker来部署,非常简单的。
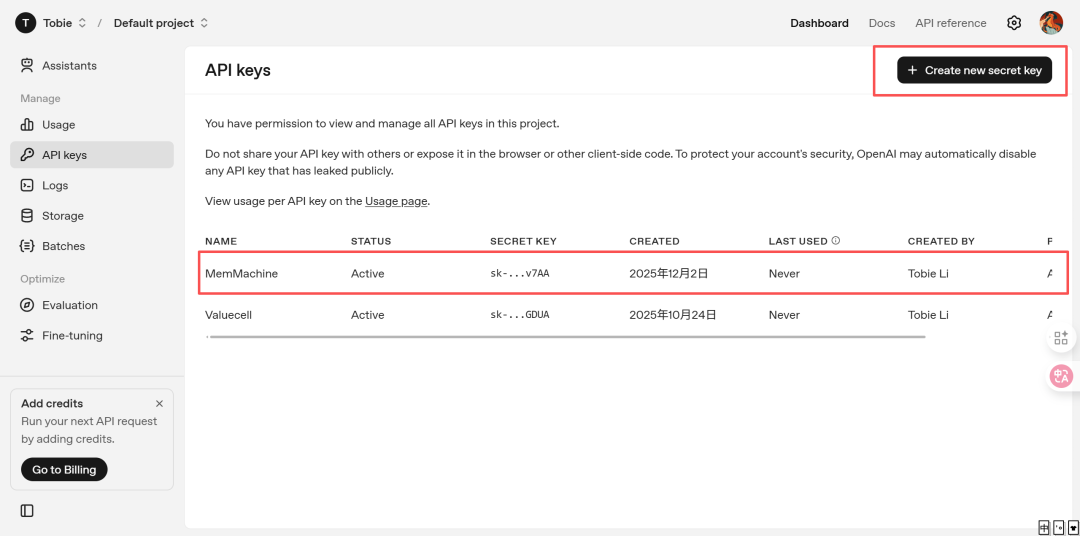
首先得准备好一个OpenAI的APIKey(当然也可以魔改成阿里云APIKey的),我们可以来到OpenAI的API平台上https://platform.openai.com/api-keys,点击创建APIKey,就可以得到一个sk开头的API了,不过记得查看有没有额度哟~
🎁
如果API也有了,我们就可以正式开始部署了。接着我们需要创建一个文件夹,这里创建了一个MemMachine文件夹,路径如下:“D:\Open_Source_Project\MemMachine”
打开Powershell,输入以下命令:
$latestRelease = Invoke-RestMethod -Uri "https://api.github.com/repos/MemMachine/MemMachine/releases/latest"; `$tarballUrl = $latestRelease.tarball_url; `$destination = "MemMachine"; `if (Test-Path $destination) { Remove-Item $destination -Recurse -Force }; `New-Item -ItemType Directory -Force -Path $destination; `Invoke-WebRequest -Uri $tarballUrl -OutFile "MemMachine-latest.tar.gz"; `tar -xzf "MemMachine-latest.tar.gz" -C $destination --strip-components=1; `Set-Location $destination; `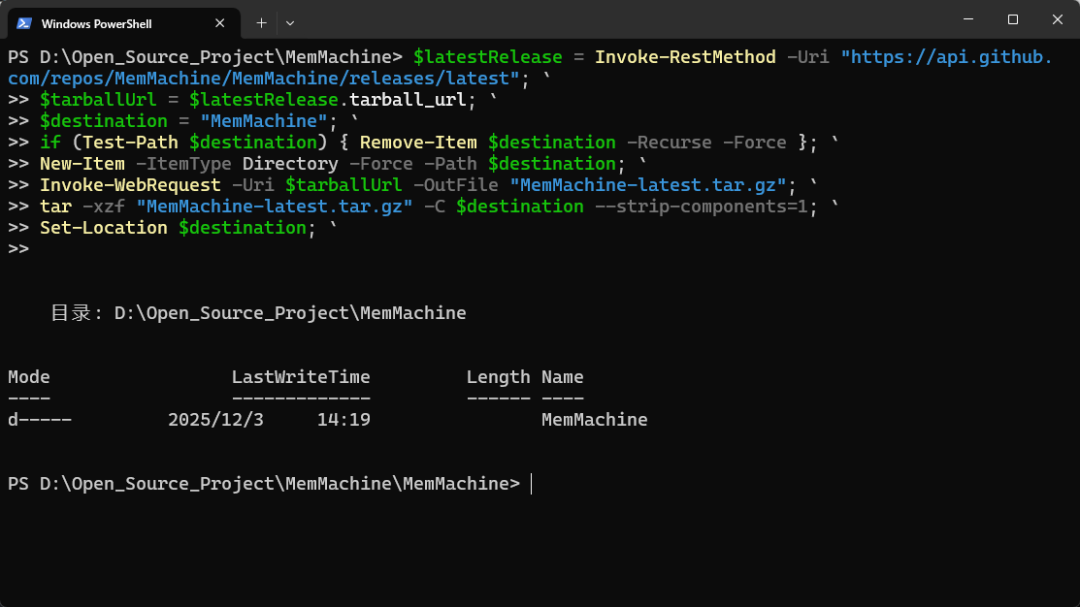
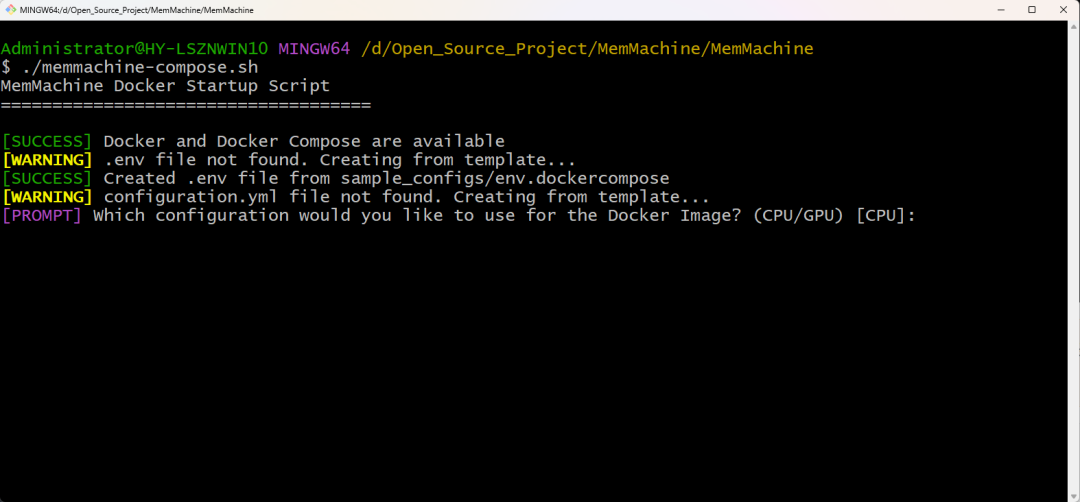
打开Git Bash(需要自行去https://git-scm.com/安装一个Git),进入到这个目录下:“D:\Open_Source_Project\MemMachine\MemMachine”,运行以下命令:
./memmachine-compose.sh🚅
第一步:选择Docker是哪种配置的(CPU/GPU),我们使用默认的CPU就行。
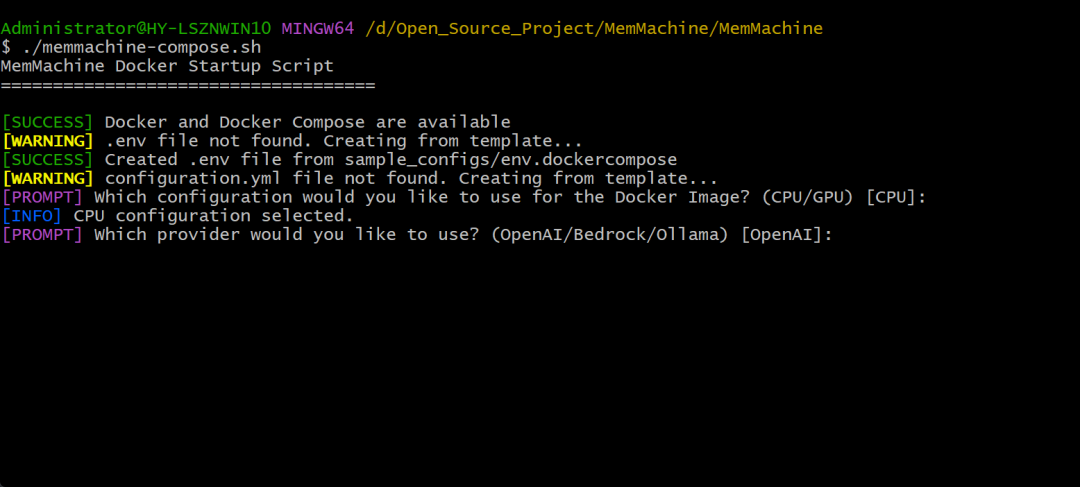
第二步:使用哪个模型供应商,我们默认使用OpenAI就行。
第三步,使用OpenAI的什么模型,我们也是默认[gpt-4o-mini]的就行了。
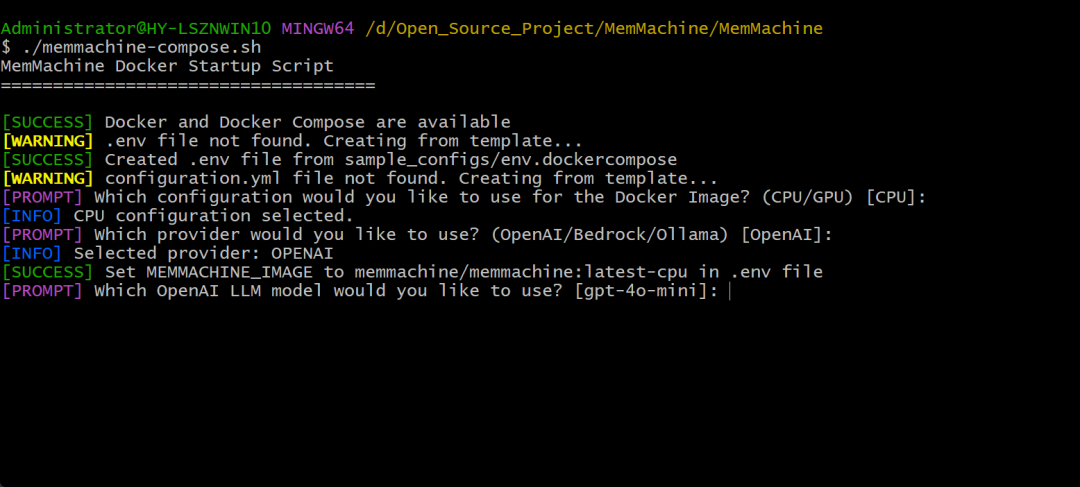
🎁
第四步,embedding模型也同样,默认即可。
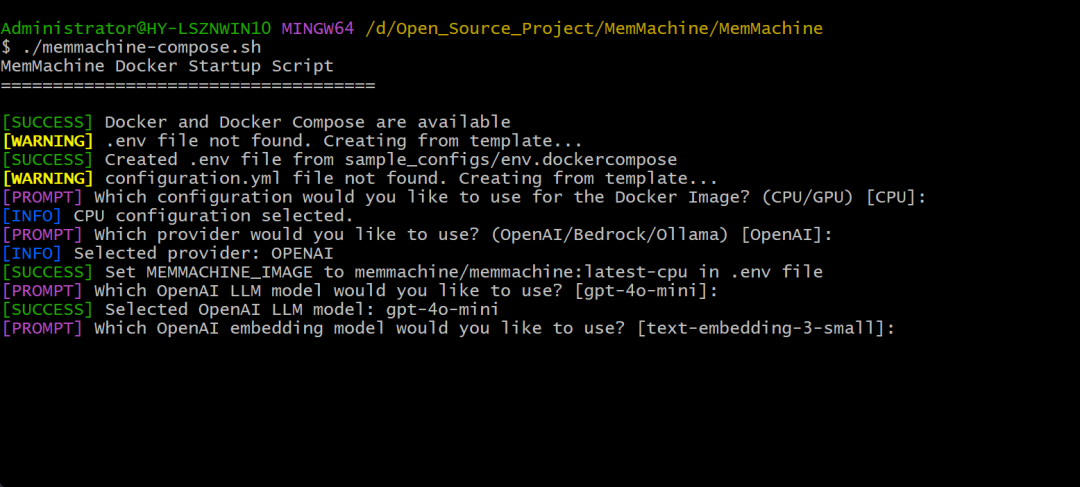
👍
第五步,这样需要设置API Key,输入Y并填写好刚刚创建好的APIKey就可以了。
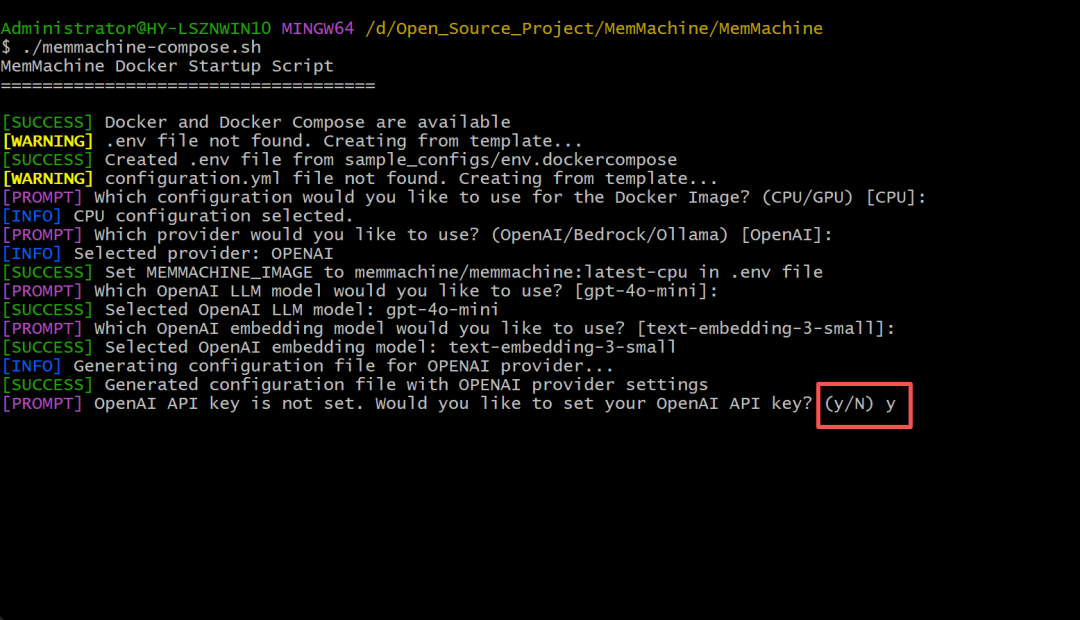
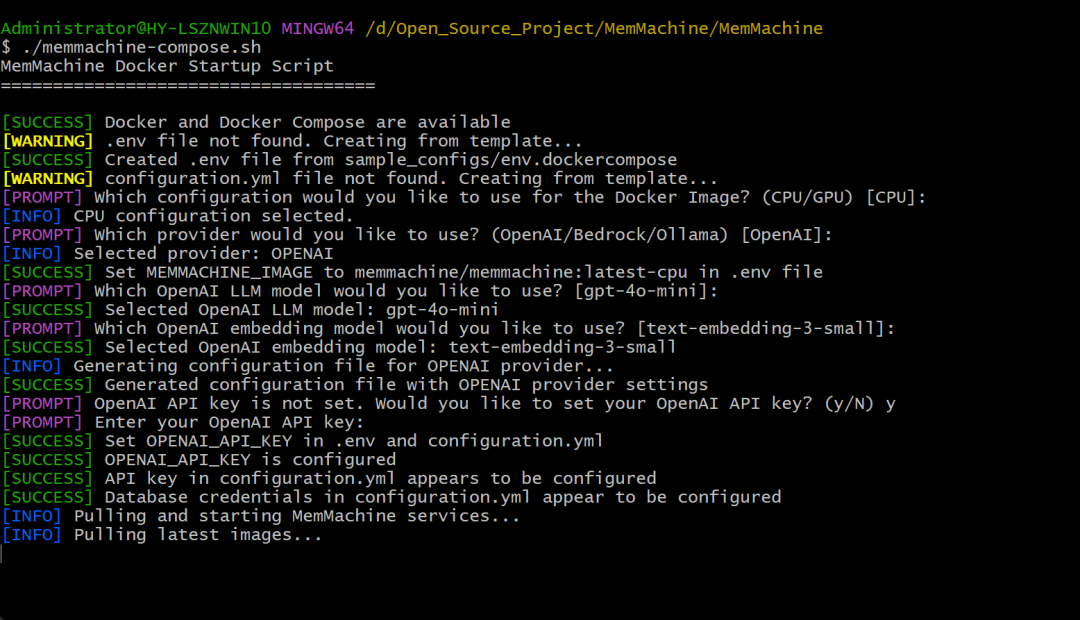
📌
最后一步呢,只需要等待它自行安装完成。
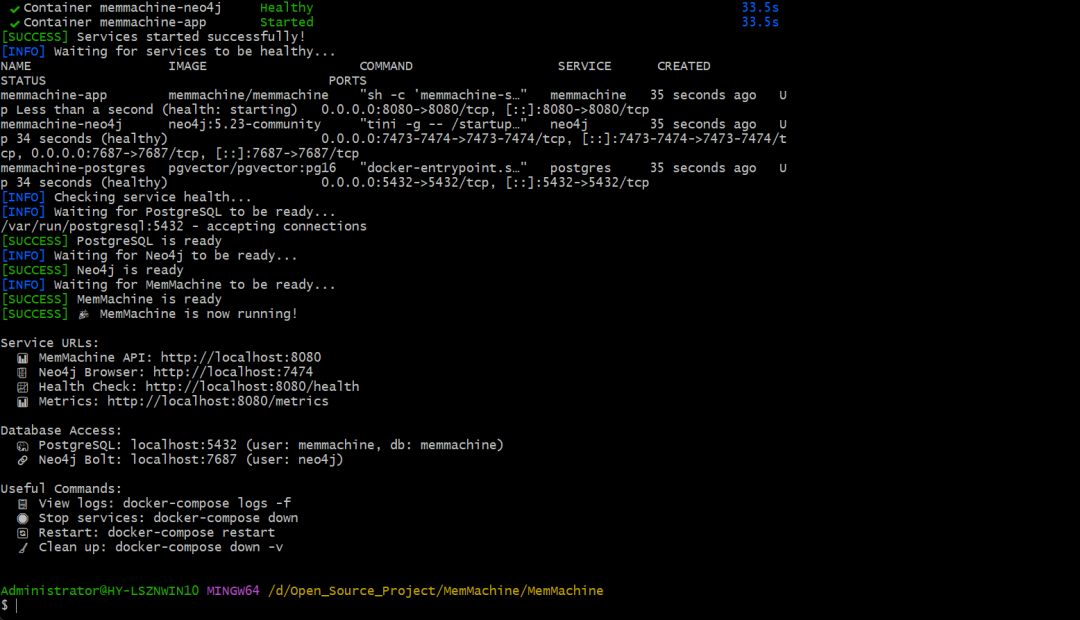
在命令行中输入这个命令,检查一下是否安装成功。
curl -v http://localhost:8080/health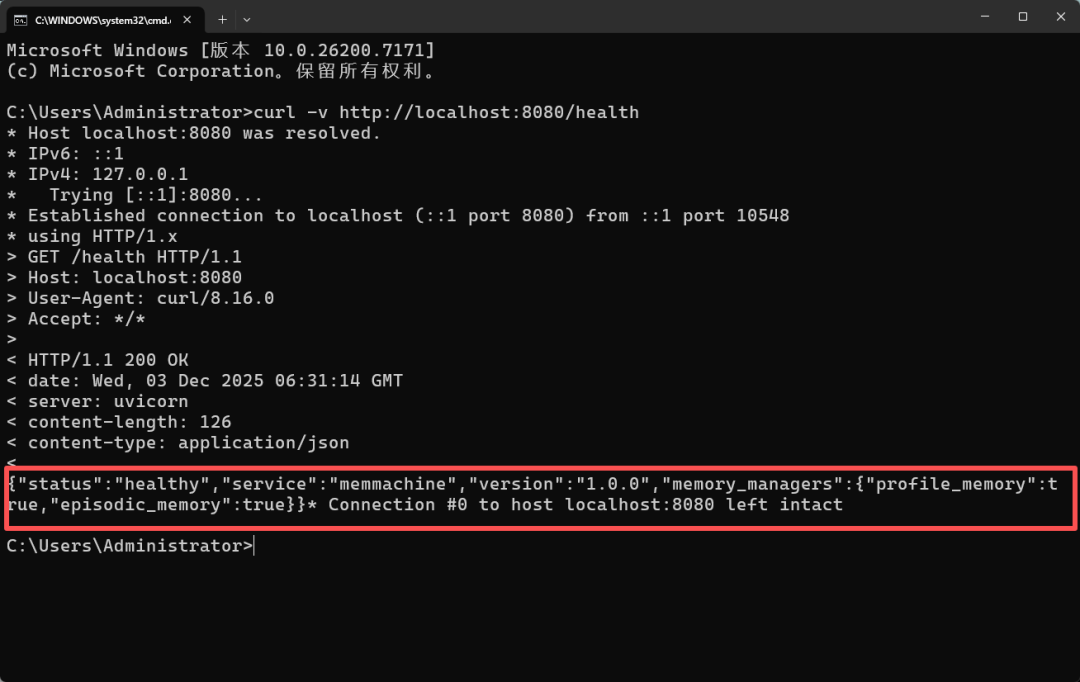
🎉
如果返回:{"status": "healthy"},说明 MemMachine 安装成功!
2.2 将 MemMachine 通过 MCP 接入 Claude Code
📚
这是关键步骤,也是很多人卡住的地方。
Claude Code 的所有插件、记忆层、外部工具都必须通过 MCP(Model Context Protocol) 接入。
MemMachine 官方提供了标准的 MCP 服务端。
不过前提条件是已经安装好Claude Code,可以输入以下命令检查一下:
claude --version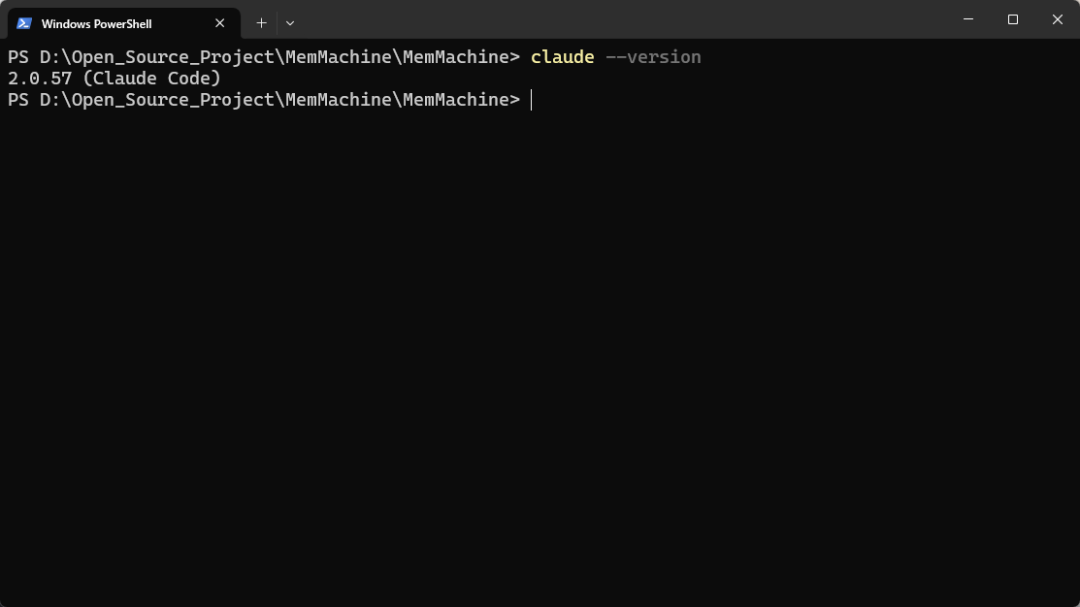
步骤 1:新建 Claude Code MCP 配置
💡
在原本的文件夹:“D:\Open_Source_Project\MemMachine\MemMachine”目录下创建一个“.mcp.json”文件,复制以下代码到这个文件中。
{ "mcpServers":{ "memmachine":{ "command":"docker", "args":[ "exec", "-i", "memmachine-app", "/app/.venv/bin/memmachine-mcp-stdio" ], "env":{ "MEMORY_CONFIG":"/app/configuration.yml", "MM_USER_ID":"your-username", "PYTHONUNBUFFERED":"1" } } } }然后进入到命令行中进行测试。
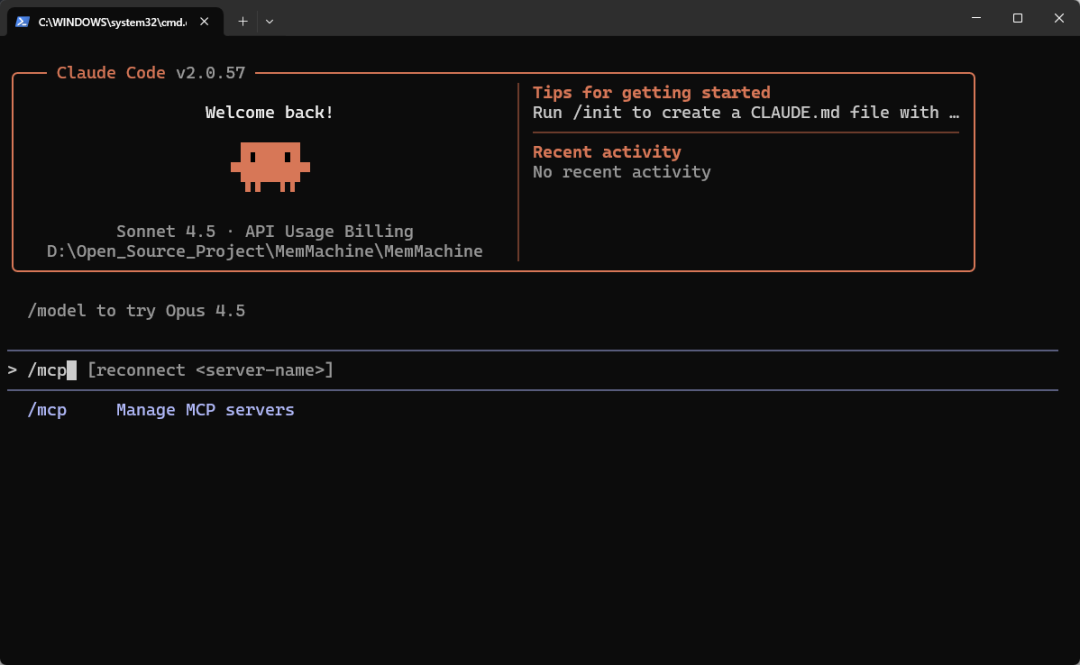
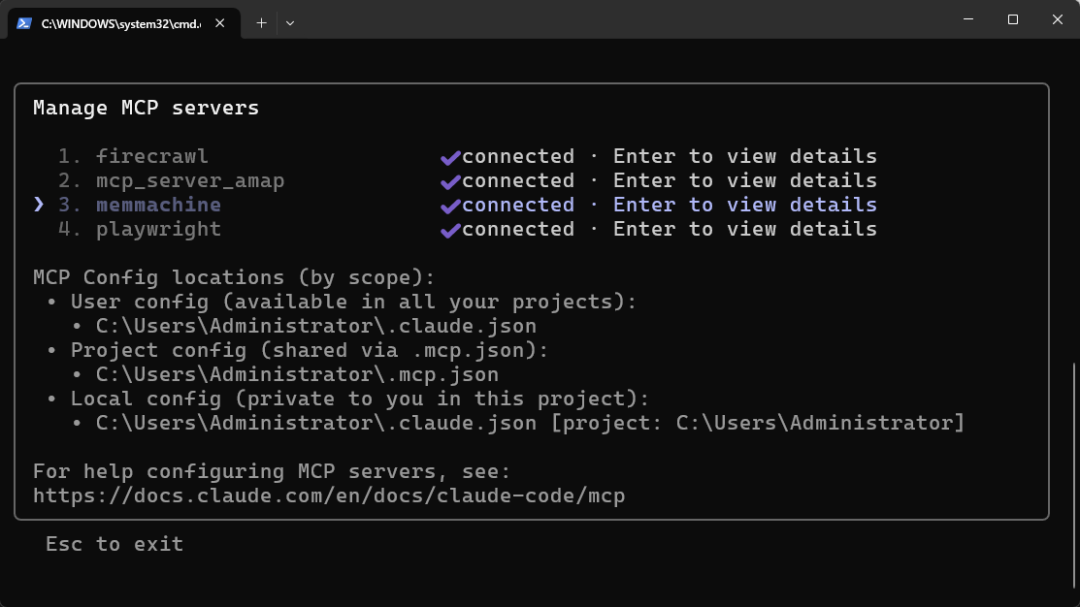
claude进入到Claude界面中,输入“/mcp”,可以看到,MemMachine已经记录到了Claude里面了。
三、实战案例:将“饮食习惯”写入记忆,并通过 Claude 读取
🌅
接下来我们做最重要的演示:
让 Claude 记住:你的饮食偏好、作息习惯、忌口和目标 并在第二次对话成功取出记忆。
这段文本就是我们要让 Agent “记住”的:
📌 记忆写入文本:
“您好,请记住我的饮食习惯,其中,我喜欢吃辣的,尤其是川菜和湘菜。我不吃香菜,也不喜欢海鲜,特别是贝类。我更喜欢家常炒菜,不喜欢油炸食品。我通常早上7点吃早餐,中午12点半午餐,晚上7点晚餐。我习惯先喝汤再吃饭,吃饭时喜欢看视频。我在控制碳水摄入,尽量不吃白米饭和面条。我的目标是增肌,需要多摄入蛋白质,每天至少120克。我想减到65公斤,所以晚餐吃得比较少。就这些了,记住一下。”
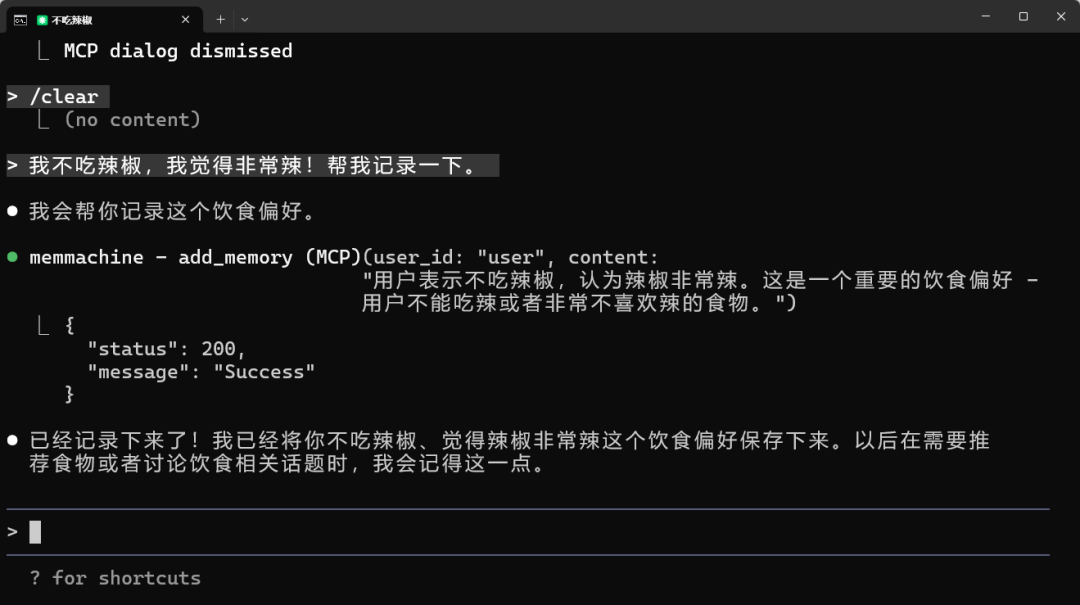
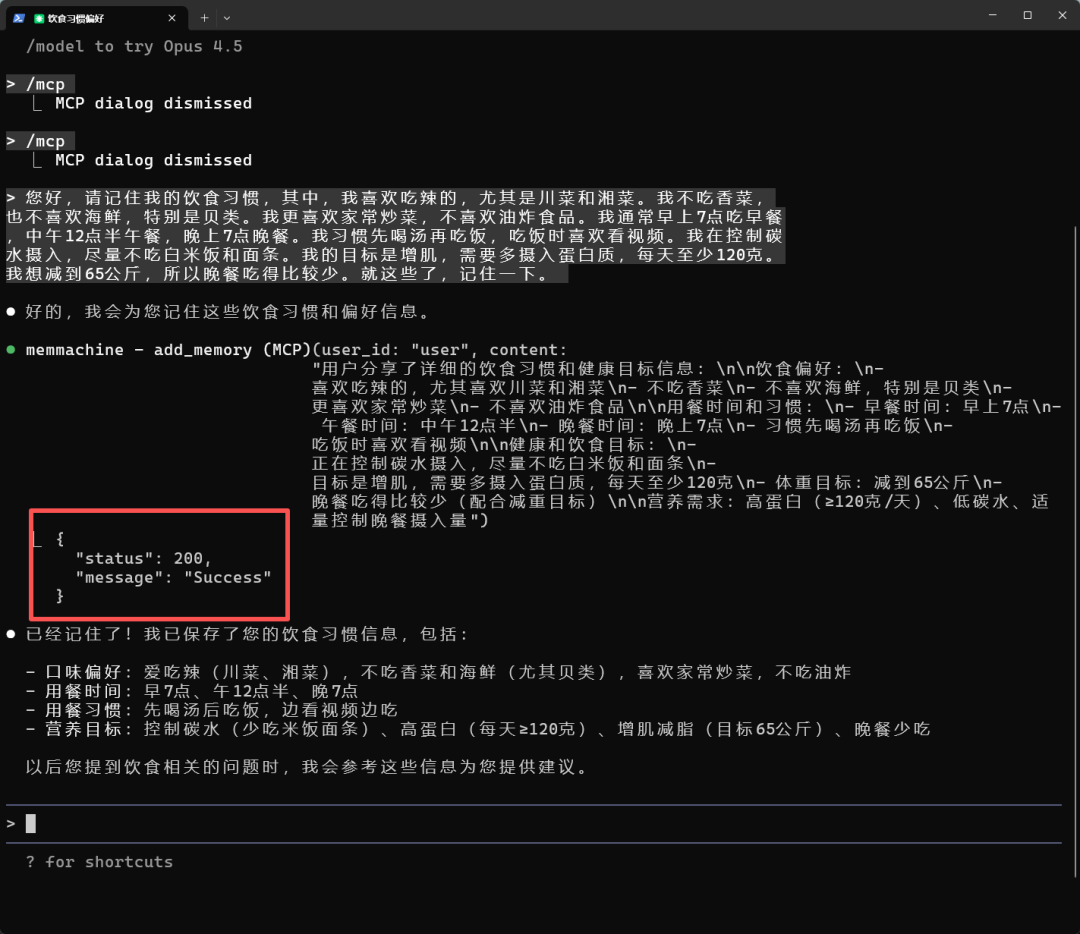
🍰
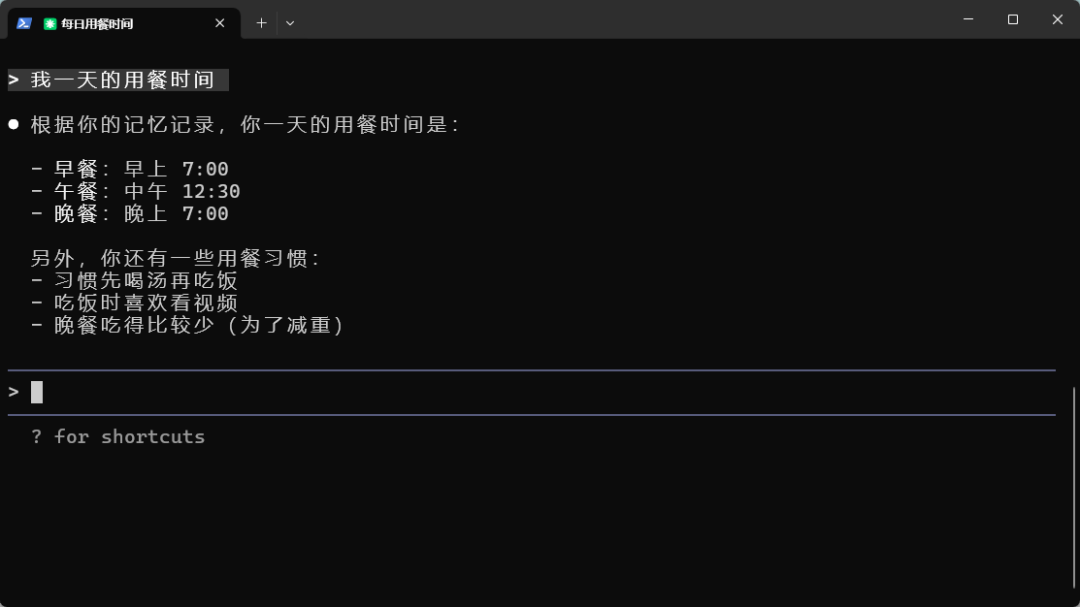
然后我们关掉这个终端命令,重新打开一个,又进行提问。比如:我一天的用餐时间
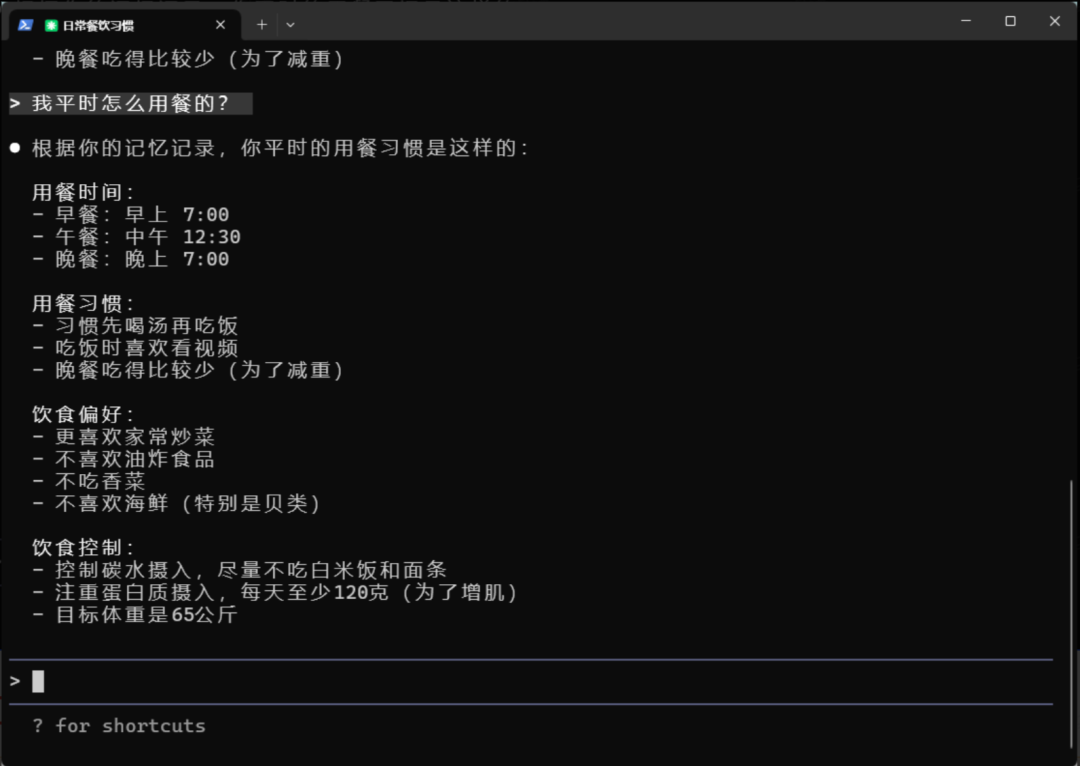
四、魔改成阿里云配置
有的用户可能觉得,我并没有OpenAI的APikey,那该怎么办,我们可以使用国产的阿里云API来进行配置它,不过需要魔改一下代码和配置文件,接下来我将教大家怎么弄。
首先需要在“MemMachine”改一下“configuration.yml”这个配置文件,如下:
logging: path:/tmp/memory_loglevel:info# | debug | errorlong_term_memory:derivative_deriver:sentencemetadata_prefix:""embedder:qianwen_embedderreranker:my_reranker_idvector_graph_store:my_storage_idSessionDB:uri:sqlitetest.dbModel:qianwen: model_vendor:openai-compatible model:"qwen-turbo" api_key:"sk-xxx" base_url:"https://dashscope.aliyuncs.com/compatible-mode/v1"storage:profile_storage: vendor_name:postgres host:postgres port:5432 user:memmachine db_name:memmachine password:memmachine_passwordprofile_memory:llm_model:qianwenembedding_model:qianwen_embedderdatabase:profile_storageprompt:profile_promptsessionMemory:model_name:qianwenmessage_capacity:500max_message_length:16000max_token_num:8000embedder:qianwen_embedder: provider:openai config: model_vendor:openai model_name:"text-embedding-v4" model:"text-embedding-v4" api_key:"sk-xxx" base_url:"https://dashscope.aliyuncs.com/compatible-mode/v1" dimensions:1536reranker:my_reranker_id: provider:"rrf-hybrid" config: reranker_ids: -id_ranker_id -bm_ranker_idid_ranker_id: provider:"identity"bm_ranker_id: provider:"bm25"aws_reranker_id: provider:"amazon-bedrock" config: region:"us-west-2" aws_access_key_id:<AWS_ACCESS_KEY_ID> aws_secret_access_key:<AWS_SECRET_ACCESS_KEY> model_id:"amazon.rerank-v1:0"prompt:profile:profile_promptvector_graph_store:my_storage_id: provider:neo4j config: uri:"bolt://neo4j:7687" username:neo4j password:neo4j_password📚
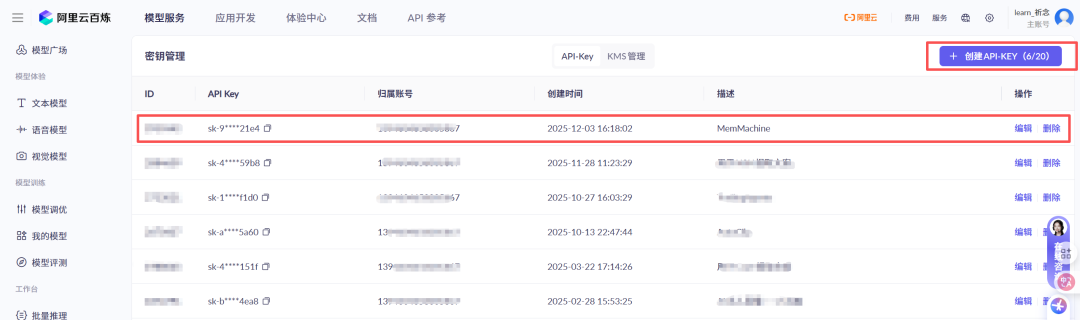
其中,api_key: "sk-xxx"一定要改成自己的APIKey,可以从这个网站获取自己的Key:https://bailian.console.aliyun.com/?tab=model#/api-key
🚅
“.env”这个文件夹也需要改正一下,其中,“DASHSCOPE_API_KEY=sk-xxx”一定要改成自己的APIKey!!!
# =============================================================================# PostgreSQL / pgvector Database Configuration# =============================================================================POSTGRES_HOST=postgresPOSTGRES_PORT=5432POSTGRES_USER=memmachinePOSTGRES_PASSWORD=memmachine_passwordPOSTGRES_DB=memmachine# =============================================================================# Neo4j Database Configuration# =============================================================================NEO4J_HOST=neo4jNEO4J_PORT=7687NEO4J_USER=neo4jNEO4J_PASSWORD=neo4j_passwordNEO4J_HTTP_PORT=7474NEO4J_HTTPS_PORT=7473# =============================================================================# MemMachine Configuration# =============================================================================MEMORY_CONFIG=configuration.ymlMCP_BASE_URL=http://memmachine:8080GATEWAY_URL=http://localhost:8080FAST_MCP_LOG_LEVEL=INFO# =============================================================================# Qwen / DashScope Compatible Mode API# =============================================================================# 你在配置中 qianwen LLM + qianwen_embedder 都使用这一把 keyDASHSCOPE_API_KEY=sk-xxx# 可选:默认 base_url 可以覆盖DASHSCOPE_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1# =============================================================================# MemMachine Optional Settings# =============================================================================LOG_LEVEL=INFOMEMORY_SERVER_PORT=8080# 数据库连接池DB_POOL_SIZE=10DB_MAX_OVERFLOW=20# 镜像版本MEMMACHINE_IMAGE=memmachine/memmachine:latest-cpu然后重启 Docker(非常重要),分别在“D:\Open_Source_Project\MemMachine\MemMachine”目录下运行这两个命令。
docker-compose downdocker-compose up -d --build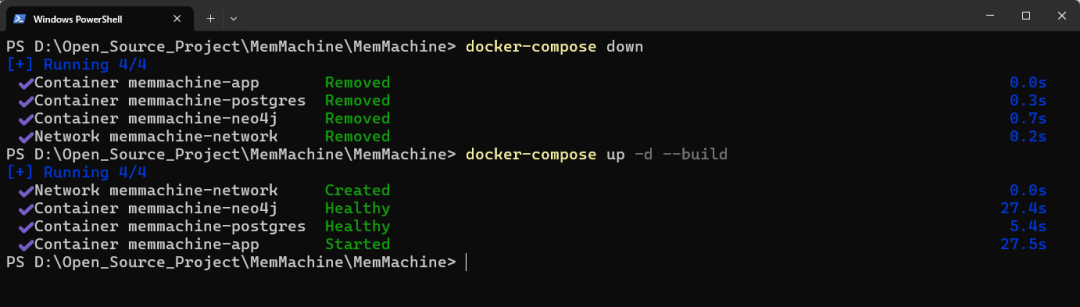
🌅
重启之后,就可以打开Claude开心地玩耍啦~!!!
五、为什么强烈建议你用MemMachine?
🌟
经过五天的深度实测,我总结了 MemMachine 的三个杀手级亮点:
1)记忆是“动态进化”的,而不是死的数据库
如果用户后来改口:
“我最近开始喜欢一点点海鲜了。”
MemMachine 会自动修正,而不是冲突。
2)数据隐私由你掌控(自部署)
所有记忆数据都在你的服务器本地:
-
不会上传 OpenAI
-
不会上传 Anthropic
-
不会泄露商业信息
-
特别适合企业、医疗、金融等行业
RAG 做不到这一点,MemMachine 做到了。
3)极佳的开发者体验(MCP 即插即用)
-
无需再写复杂的记忆管理逻辑
-
不再担心 context window
-
再大模型也可以换
-
代码改动极小
六、总结:MemMachine 绝对值得安装
如果你正在做:陪伴类 AI、客服类 AI、垂直行业助手(医疗 / 法律 / 教育)、代码助手数字员工。
那么你一定需要一个:可靠、可控、可进化、不会消失的长期记忆系统。
MemMachine 做到了,并且已经领先市场“半步”以上。
AI 的下半场,不是参数之争,而是记忆之争。
真正强大的 Agent,一定是能“了解你、记得你、为你变化”的 Agent。
MemMachine 可能就是通向那个未来的一块基石。
写在最后
案例只是一种思路和方法的传递。
更多无限的可能还在路上。
每一次的尝试都是向成功迈进的一步。
希望我的文章可以带给你一些启发!
既然看到这里了,如果觉得对你有启发,随手点个赞👍、在看👀、转发➡📣三连吧。想第一时间收到推送,也可以给我个关注~
💖谢谢你在这个注意力及其宝贵的时代,还在看我的文章,我们,下次再见👋!

有趣的灵魂在等你

长按二维码识别

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)